2019-CVPR 缺陷/瑕疵检测论文介绍及基于pytorch实现的代码
Segmentation-Based Deep-Learning Approach for Surface-Defect Detection的介绍和实现
- 本文介绍
- 论文解析
-
- 1. INTRODUCTION
- 2. Related Work
- 3. Segmentation network
-
- 3.1 决策网络
- 3.2 Learning
- 3.3 Inference
- 4. Segmentation and decision network evaluation
- 5. Experiments
-
- 5.1 Performance metrics
- 5.2 Implementation and learning detail
- 5.3 Segmentation and decision network
- 5.4 Contribution of the decision network
- 5.5 Required precision of the annotation
- 5.6 Comparison with the state of the art
- 5.7 Comparison with the proposed approach
- 代码实现
-
- 训练分割网络
- 训练决策网络
- 进行测试
Detection的介绍和实现)
本文介绍
“Segmentation-Based Deep-Learning Approach for Surface-Defect
Detection”是2019CVPR上发表的一篇用于电子转换器的表面裂缝检测的论文,本文提出了一个两阶段网络(分割网络+决策网络)用于检测的方法。
论文的示意图和整个流程如下:
 [注]:
[注]:
- 本博文第三部分代码实现是copy自github上 link,本博文对代码进行了详细的中文标注,可逐行进行学习。此外github上还有基于TF的实现,link
- 所有的资源(论文原文,原作者的代码,带中文注释的代码,所用数据集,都可在我的资源中进行免费下载(link)
论文解析
本文提出了一个基于分割的深度学习框架(只用很少的数据进行训练),用于表面异常的检测和分割——在表面裂纹检测方面很有用。
本文和商业软件进行了对比。大量实验也阐明了:所需的标注的精确度;训练样本的数量;所需的计算代价。
数据集:新建了一个数据集KolektorSDD。证实本文框架只用25-30个缺陷训练样本就能训练。
1. INTRODUCTION
实际背景中的术语:surface quality control
传统方式:用a hand-crafted rule-based approach或基于学习分类器(SVM,决策器,kNN)。用滤波,直方图,小波变换,形态学操作等处理手工特征。
深度学习:非常适用于灵活的产品线。现存的问题:需要多少注释数据?注释要精确到什么程度?训练数据少难以获得
本文:研究了一个深度方法(基于两阶段架构的深度卷积网络)用于表面裂缝检测。
数据集:自己提了一个新的数据集:Kolektor Surface-Defect Dataset (KolektorSDD)
2. Related Work
- Faghih-Roohi et al (2016):铁路表面缺点。RELU
- Chen and Ho (2016):基于OverFeat网络,在1.2 million图像上训练。SVM去学习分类器
- Weimer et al (2016):变深度的网络(5-11层)。6种合成缺点。能定位缺陷但无效
- Raˇcki et al (2018):10层的全卷积网络。RELU+BN。在分割网络顶端加了一个决策网络执行预图像分类——提升精确度
- Lin et al (2018):LEDNet。30000低分辨率的图像。基于AlexNet网络,移除了全连接层,用class-activation maps(定位缺陷)代替。
本文提出带分割网络和决策网络的两阶段设计——扩大感受野+增加网络捕获小细节的能力。用于实际数据,而不是合成数据
由于少量样本使网络设计的选择变得更加重要,因此本文评估了用两种不同的标准网络设计替换分段网络的效果,这两种标准网络设计通常用于语义分段,即使用DeepLabv3 +和U-NET
3. Segmentation network
-
分割网络:执行缺陷检测的像素级定位,用a pixel-wise loss有效的训练网络,将每个像素看作一个个体训练样本——增加训练样本的有效的个数和预防过拟合。
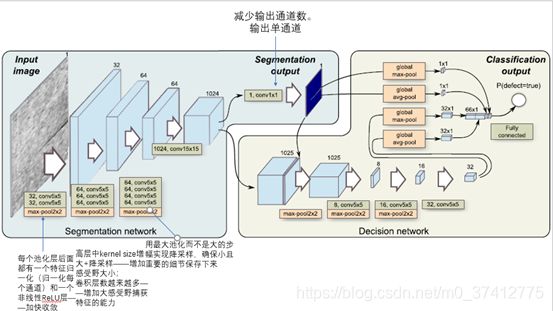
-
决策网络:执行二进制图像分类。在分割网络的顶部加一个网络,同时使用分割网络的输出和特征
3.1 分割网络
包含11个卷积层和3个池化层(每个都将分辨率降低2倍)。
3.1 决策网络
3.2 Learning
分割网络:作为a binary-segmentation problem学习,分类是在单个图像像素级别进行的。2个损失函数:MSE,交叉熵。权重:随机初始化
决策网络:损失函数—交叉熵。
两阶段学习(分割网络和决策网络分开训练——先训练分割网络,冻结其权重,训练决策网络。微调决策网络可避免过拟合(分割网络中大量的权重))。决策层的学习比分割层的学习更重要——GPU内存限制了batch size只有1/2 samples per batch当学习决策层时,但学习分割层时被认为时一个独立的训练样本,增加batch size by several folds.
3.3 Inference
网络输入:灰度图像;两种分辨率:1408512或704256
网络输出:1. A segmentation mask: 一个8*8组输入像素的缺陷的概率——所以输出分辨率被减少了8倍;2. [0,1]内的概率分数,代表在图像中异常出现的概率,由决策网络返回。
4. Segmentation and decision network evaluation
数据集: Kolektor surface-defect dataset (KolektorSDD)
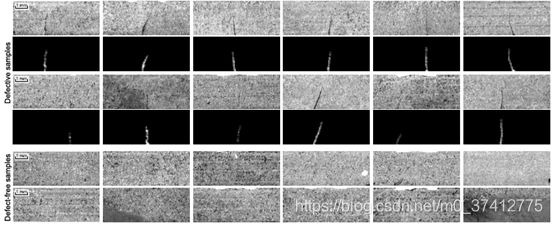
共399张,其中52张有缺陷/正样本图片(a detailed pixel-wise annotation mask)
注释精度:缺陷由不同类型的注释标注,有不同的精度。给出了共5种不同的注释精度。

5. Experiments
4组实验分别探索不同部分的影响。
- 5种注释精度
- 对分割网络的2类损失函数
- 2种输入图像的尺寸(full size + half size)
- 是否有90度的旋转
评级:将表面缺陷检测问题看作二值图像分类问题。进行逐图像的判断
5.1 Performance metrics
(a) average precision (AP), (b) number of false negatives
(FN) and © number of false positives (FP).
5.2 Implementation and learning detail
网络超参数设置
每代中训练样本任意选择,但为了维持平衡,偶数代从缺陷图片中任选一个,基数代中无缺陷图片中任选一个
网络最多训练6600steps, 在one fold中每个训练集有33个正样本,in each step正负样本的替换有100epochs,one epoch指所有的正样本至少被观察一次,正样本无所谓
5.3 Segmentation and decision network
不同实验设施的结果
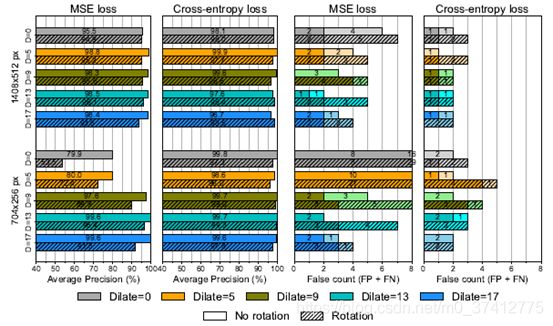
5.4 Contribution of the decision network
决策网络的消融实验
5.5 Required precision of the annotation
大的注释比精细的注释表现更好
探索了更粗糙的注释对算法AP的影响。
5.6 Comparison with the state of the art
和Cognex VIDI套件中的vidi red对比。
和DeepLabv3+, UNET进行对比。他们替换分割部分,并将决策部分换位逻辑回归。
5.7 Comparison with the proposed approach

三种方法总的对比结果
代码实现
如果要直接拿来跑,可分3步进行。1. 训练分割网络;2. 训练决策网络; 3, 进行测试。
【注】:因为决策网络和分割网络的代码极其相似,我就只对决策网络继续了超级详细的中文标注,分割网络的对照看就好。其他的文件(如models.py,dataset.py直接在我的资源中免费下载就好(link))
训练分割网络
################################################两阶段网络分割网络的训练####################################################
'''
两个网络训练时都是从train_NG(有缺陷)和train_OK(无缺陷)中交替选取一个batch的图片进行训练。
'''
from models import SegmentNet, DecisionNet, weights_init_normal
from dataset import KolektorDataset
import torch.nn as nn
import torch
from torchvision import datasets
from torchvision.utils import save_image
import torchvision.transforms as transforms
from torch.autograd import Variable
from torch.utils.data import DataLoader
import os
import sys
import argparse #命令行选项,参数,和子命令解析器。弄清楚如何从sys.argv解析出那些参数,自动生成帮助和使用手册,在用户传入无效参数时报出错误信息
import time #记录算法运行时间的模块
import PIL.Image as Image
#-----------------------------------------------------------------------------------------------------------------------
#---------------------------------------------设置参数--------------------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
parser = argparse.ArgumentParser() #创建参数解析器,i.e.创建ArgumentParser对象
parser.add_argument("--cuda", type=bool, default=True, help="number of gpu") #添加参数
parser.add_argument("--gpu_num", type=int, default=1, help="number of gpu")
parser.add_argument("--worker_num", type=int, default=1, help="number of input workers") #决定了有几个进程来处理data loading,0意味着所有的数据都会被load进主进程,超级慢
parser.add_argument("--batch_size", type=int, default=3, help="batch size of input") #一批数据的大小。一部分样本对权重进行一次反向传播的参数更新
parser.add_argument("--lr", type=float, default=0.0005, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient") #一阶梯度矩的衰减
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--begin_epoch", type=int, default=0, help="begin_epoch") #开始的epoch的值
parser.add_argument("--end_epoch", type=int, default=101, help="end_epoch") #共进行epoch代训练。所有数据被轮end_epoch次
parser.add_argument("--need_test", type=bool, default=True, help="need to test") #判断是否需要测试。若该网络只训练不测试,可将默认值改为false
parser.add_argument("--test_interval", type=int, default=1, help="interval of test") #测试的间隔。每隔test_interval个epoch后进行测试。默认值为10,也就是所有的数据每轮10次后进行一次测试
parser.add_argument("--need_save", type=bool, default=True, help="need to save")
parser.add_argument("--save_interval", type=int, default=1, help="interval of save weights")
parser.add_argument("--img_height", type=int, default=704, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
opt = parser.parse_args() #解析参数
print(opt) #打印解析的参数 Namespace(b1=0.5, b2=0.999, batch_size=2, begin_epoch=0, cuda=True, end_epoch=101, gpu_num=1, img_height=704, img_width=256, lr=0.0005, need_save=True, need_test=True, save_interval=10, test_interval=10, worker_num=4)
#opt是一个Namespace: 命名空间,从名称到对象的映射,避免名称冲突。
dataSetRoot = "./Data" #存储数据存放的路径
#-----------------------------------------------------------------------------------------------------------------------
#----------------------------------------------------构建网络-------------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
segment_net = SegmentNet(init_weights=True) #SegmentNet是从models中导入的,搭建的分割网络。
criterion_segment = torch.nn.MSELoss() #损失函数MSE作为分割网络的评价标准
if opt.cuda: #判断cuda是否可用
segment_net = segment_net.cuda() #将网络转化为gpu上调用
criterion_segment.cuda() #将损失函数转化为gpu上调用
if opt.gpu_num > 1: #gpu_num默认是1
segment_net = torch.nn.DataParallel(segment_net, device_ids=list(range(opt.gpu_num))) #多gpu运行
if opt.begin_epoch != 0: #默认是0
segment_net.load_state_dict(torch.load("./saved_models/segment_net_%d.pth" % (opt.begin_epoch))) #加载预训练好的模型
else:#第一次开始训练,就不能加载预处理的网络了。要先初始化权重
segment_net.apply(weights_init_normal) # 方法weights_init_normal是和类segment_net在同一模块中,调用时需要用.apply()
# 优化器的选择
optimizer_seg = torch.optim.Adam(segment_net.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) #betas是用于计算梯度以及梯度平方的运行平均值的系数,分别为一阶矩估计的指数衰减率,二阶矩估计的指数衰减率
#-----------------------------------------------------------------------------------------------------------------------
#----------------------------------------------------图像预处理-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
transforms_ = transforms.Compose([ #compose是pytorch中的图像预处理包,将多个步骤整合在一起
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC), #resize是把给定的图片resize到given size;Image.BICUBIC是对图像进行双三次插值,对图片的某些部分进行放大
transforms.ToTensor(), #转换一个PIL图像到tensor, PIL是python的第三方图像处理库。Image模块就是PIL的图像
])
transforms_mask = transforms.Compose([ #!!!!!!mask是什么?缺陷的监督标识吗
transforms.Resize((opt.img_height//8, opt.img_width//8)),
transforms.ToTensor(),
])
#-----------------------------------------------------------------------------------------------------------------------
#-----------------------------------------------------图像加载-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
trainOKloader = DataLoader( #trainOK数据集 都是全黑的图形 #DataLoader就是提供了一个可以迭代的数据集,用于一个batch一个batch的训练
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Train_OK", isTrain=True), #KolektorDataset是从dataset.py中导入的类
batch_size=opt.batch_size, #参数设置中的默认值为2,指每个batch中有多少个样本
shuffle=False, #每个epoch开始时,是否对数据进行重新排序
num_workers=opt.worker_num, #参数设置中的默认值为4,这个参数决定了有几个进程来处理data loading,0意味着所有的数据都会被load进主进程,超级慢
#num_work的意义:值越大的优势:寻找batch的速度快(下一轮迭代的batch很可能已经在上/上上。。轮中加载好了;
# 缺点:内存开销大,加重CPU负担
# 根据经验值:自己电脑/服务器的cpu核心数)
)
trainNGloader = DataLoader( #trainNG数据集 有缺陷的图像
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Train_NG", isTrain=True),
batch_size=opt.batch_size,
shuffle=False,
num_workers=opt.worker_num,
)
testloader = DataLoader(
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Test", isTrain=False),
batch_size=1,
shuffle=True,
num_workers=opt.worker_num,
)
#-----------------------------------------------------------------------------------------------------------------------
#-----------------------------------------------------正式训练-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
if __name__ == "__main__":
time_start = time.time()
for epoch in range(opt.begin_epoch, opt.end_epoch): #begin_epoch参数设置中默认为0,end_epoch默认为101
iterOK = trainOKloader.__iter__() #这里返回的Namespace显示的数量和num_workers的值有关,类似于预加载的batch的数量。越多的话,寻找batch的速度越快,但对内存要求高
# 这里iterOK是一个multiProcessingDataLoaderIter:大小为iterOK文件夹中图片的数量/batchsize
#这样的访问方式返回的iterOK是一个基本的迭代器
#trainOKloader是由DataLoader创建的一个可迭代对象,使用iter()访问,不能用next()访问
#iter(dataloader)返回的是一个迭代器,然后可以用next访问
#也可以用for inputs, labels in dataloaders或for inputs,labels in enumerate(dataloader)进行可迭代对象的访问
#enumerate(dataloader)将数据一个batch一个batch地读取,这样labels[0]为数据,labels[1]为label
iterNG = trainNGloader.__iter__()
lenNum = min( len(trainNGloader), len(trainOKloader)) #len(trainNGloader)和len(trainOKloader)分别是trainOK,trainNG文件夹中图片的数量/batchsize
lenNum = 2*(lenNum-1) #计算一个epoch中总的batch的数量,i.e.几个批次
#因为每个batch进行训练时是从trainNGloader和trainOKloader中交替挑选数据的,所以总的batch次数是lenNum,他的计算方式是(最小的-1)*2
segment_net.train() #构建segment_net的训练实例,还没有真正开始训练
#--------------------------------------------挑选第i个batch的图片进行训练-------------------------------------------
for i in range(0, lenNum):
if i % 2 == 0: #i是偶数,从iterOK中选图片进行第i个batch的训练
batchData = iterOK.__next__() #batchData大小为batchsize=2,从trainOK文件夹中提取一个batch的图片对权重进行一次反向传播的参数更新
#batchData是一个字典类型,有两个键['img']和['mask']。分别是原始图像和标签,batchData["img"]输入网络后的结果与batchData["mask"]计算损失函数
#idx, batchData = enumerate(trainOKloader)
else : #i是奇数,从iterNG中选图片进行第i个batch的训练
batchData = iterNG.__next__() #从trainNG文件夹中提取一个batch的图片对权重进行一次反向传播的参数更新
#idx, batchData = enumerate(trainNGloader)
if opt.cuda:
img = batchData["img"].cuda() #img应该指的是原始输入的图片 batchData中包含2张图,一张img原图,一张mask标签吗?但是trainOK/trainNG中不是这样的啊
mask = batchData["mask"].cuda() #mask是img对应的label(标注出缺陷的图片)
else:
img = batchData["img"]
mask = batchData["mask"]
optimizer_seg.zero_grad()
rst = segment_net(img) #计算模型对img的输出结果,前馈传播
seg = rst["seg"] #seg是分割网络segment_net最后一层的输出(共5层)
loss_seg = criterion_segment(seg, mask) #criterion_segment是损失函数,是对segment的评价标准。 也就是说seg是分割网络逐像素计算出的结果(一张图片),mask是真实的缺陷结果还是说算法自己处理的结果????有监督or无监督???
loss_seg.backward()
optimizer_seg.step()
#输出第epoch个Epoch中第batch次训练之后的损失函数
sys.stdout.write(
"\r [Epoch %d/%d] [Batch %d/%d] [loss %f]"
%(
epoch,
opt.end_epoch,
i,
lenNum,
loss_seg.item()
)
)
# -----------------------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------验证部分-------------------------------------------------------
# -----------------------------------------------------------------------------------------------------------------------
if opt.need_test and epoch % opt.test_interval == 0 and epoch >= opt.test_interval: #每隔test_interval次epoch之后进行测试。(默认值设置为10)
# segment_net.eval()
for i, testBatch in enumerate(testloader): #enumerate(dataloader)将数据一个batch一个batch地读取,这样labels[0]为数据,labels[1]为label
imgTest = testBatch["img"].cuda() #读取第i个测试集中的图片
rstTest = segment_net(imgTest) #输出测试结果
segTest = rstTest["seg"] #输出网络最后一层的结果
'''
#显示网络的输出结果
segTest = transforms.ToPILImage()(segTest[0])
segTest.show()
'''
save_path_str = "./testResultSeg/epoch_%d"%epoch #设置测试结果的存储路径
if os.path.exists(save_path_str) == False:
os.makedirs(save_path_str, exist_ok=True) #创建文件夹:testResultSeg及下面的子文件夹epoch_%d
#os.mkdir(save_path_str)
save_image(imgTest.data, "%s/img_%d.jpg"% (save_path_str, i)) #将第i张测试图片进行储存
save_image(segTest.data, "%s/img_%d_seg.jpg"% (save_path_str, i)) #将第i张测试图片的结果进行储存
segment_net.train()
# -----------------------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------储存网络-------------------------------------------------------
# -----------------------------------------------------------------------------------------------------------------------
if opt.need_save and epoch % opt.save_interval == 0 and epoch >= opt.save_interval:#每隔save_interval次epoch之后将参数进行存储。(默认值设置为10)
#segment_net.eval()
save_path_str = "./saved_models"
if os.path.exists(save_path_str) == False:
os.makedirs(save_path_str, exist_ok=True)
torch.save(segment_net.state_dict(), "%s/segment_net_%d.pth" % (save_path_str, epoch)) #将训练的参数进行存储
print("save weights ! epoch = %d"%epoch) #第epoch代训练结束后的权重已进行储存
#segment_net.train()
pass
time_end = time.time()
print("totally time", time_end-time_start)
训练决策网络
################################################两阶段网络决策网络的训练####################################################
from models import SegmentNet, DecisionNet, weights_init_normal
from dataset import KolektorDataset
import numpy as np
import torch.nn as nn
import torch
from torchvision import datasets
from torchvision.utils import save_image
import torchvision.transforms as transforms
from torch.autograd import Variable
from torch.utils.data import DataLoader
import os
import sys
import argparse
import time
import PIL.Image as Image
#-----------------------------------------------------------------------------------------------------------------------
#---------------------------------------------设置参数--------------------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
parser = argparse.ArgumentParser()
parser.add_argument("--cuda", type=bool, default=True, help="number of gpu")
parser.add_argument("--gpu_num", type=int, default=1, help="number of gpu")
parser.add_argument("--worker_num", type=int, default=4, help="number of input workers")
parser.add_argument("--batch_size", type=int, default=4, help="batch size of input")
parser.add_argument("--lr", type=float, default=0.001, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--begin_epoch", type=int, default=0, help="begin_epoch")
parser.add_argument("--end_epoch", type=int, default=61, help="end_epoch")
parser.add_argument("--seg_epoch", type=int, default=50, help="pretrained segment epoch")
parser.add_argument("--need_test", type=bool, default=True, help="need to test")
parser.add_argument("--test_interval", type=int, default=10, help="interval of test")
parser.add_argument("--need_save", type=bool, default=True, help="need to save")
parser.add_argument("--save_interval", type=int, default=10, help="interval of save weights")
parser.add_argument("--img_height", type=int, default=704, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
opt = parser.parse_args()
print(opt)
dataSetRoot = "./Data" # "/home/sean/Data/KolektorSDD_sean"
#-----------------------------------------------------------------------------------------------------------------------
#----------------------------------------------------构建网络-------------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
segment_net = SegmentNet(init_weights=True)
decision_net = DecisionNet(init_weights=True)
criterion_decision = torch.nn.MSELoss() #损失函数的设置
if opt.cuda:
segment_net = segment_net.cuda()
decision_net = decision_net.cuda()
#criterion_segment.cuda()
criterion_decision.cuda()
if opt.gpu_num > 1:
segment_net = torch.nn.DataParallel(segment_net, device_ids=list(range(opt.gpu_num)))
decision_net = torch.nn.DataParallel(decision_net, device_ids=list(range(opt.gpu_num)))
if opt.begin_epoch != 0:
# Load pretrained models
decision_net.load_state_dict(torch.load("./saved_models/decision_net_%d.pth" % (opt.begin_epoch)))
else:
# Initialize weights
decision_net.apply(weights_init_normal)
segment_net.load_state_dict(torch.load("./saved_models/segment_net_%d.pth" % (opt.seg_epoch))) # 加载预训练好的分割模型(储存在训练分割模型时建立的saved_models文件夹中)
optimizer_dec = torch.optim.Adam(decision_net.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) #优化器设置
#-----------------------------------------------------------------------------------------------------------------------
#----------------------------------------------------图像预处理-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
transforms_ = transforms.Compose([
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
#transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
transforms_mask = transforms.Compose([
transforms.Resize((opt.img_height//8, opt.img_width//8)),
transforms.ToTensor(),
#transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
#-----------------------------------------------------------------------------------------------------------------------
#-----------------------------------------------------图像加载-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
trainOKloader = DataLoader(
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Train_OK", isTrain=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.worker_num,
)
trainNGloader = DataLoader(
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Train_NG", isTrain=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.worker_num,
)
testloader = DataLoader(
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= transforms_mask, subFold="Test", isTrain=False),
batch_size=1,
shuffle=False,
num_workers=0,
)
#-----------------------------------------------------------------------------------------------------------------------
#-----------------------------------------------------正式训练-----------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
if __name__ == "__main__":
for epoch in range(opt.begin_epoch, opt.end_epoch):
iterOK = trainOKloader.__iter__() # 这里iterOK是一个multiProcessingDataLoaderIter:大小为iterOK文件夹中图片的数量/batchsize
#这样的访问方式返回的iterOK是一个基本的迭代器,用于一会一个batch一个batch地提取数据进行训练
iterNG = trainNGloader.__iter__()
lenNum = min( len(trainNGloader), len(trainOKloader))
lenNum = 2*(lenNum-1)
# ---------------------------------挑选第i个batch(一个epoch中共lenNum个batch)的图片进行训练---------------------------
for i in range(0, lenNum):
if i % 2 == 0:
batchData = iterOK.__next__()
gt_c = Variable(torch.Tensor(np.zeros((batchData["img"].size(0), 1))), requires_grad=False)#产生和batchData中一样大小的全0的tensor
'''
#显示batchData中第一张图片
a = batchData['img'][0]
a = transforms.ToPILImage()(a)
a.show()
'''
else :
batchData = iterNG.__next__()
gt_c = Variable(torch.Tensor(np.ones((batchData["img"].size(0), 1))), requires_grad=False)
if opt.cuda:
img = batchData["img"].cuda()
mask = batchData["mask"].cuda()
gt_c = gt_c.cuda()
else:
img = batchData["img"]
mask = batchData["mask"]
rst = segment_net(img) #分割网络对batchData的输出结果
f = rst["f"] #分割网络的第4层输出
seg = rst["seg"] #分割网络的第5层/最后一层输出
optimizer_dec.zero_grad()
rst_d = decision_net(f, seg) #决策网络的输出
# rst_d = torch.Tensor.long(rst_d)
loss_dec = criterion_decision(rst_d, gt_c) #决策网络输出和全0数据做损失函数,决策网络的输出应该越小越好
loss_dec.backward()
optimizer_dec.step()
sys.stdout.write(
"\r [Epoch %d/%d] [Batch %d/%d] [loss %f]"
%(
epoch,
opt.end_epoch,
i,
lenNum,
loss_dec.item()
)
)
# -----------------------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------验证部分-------------------------------------------------------
# -----------------------------------------------------------------------------------------------------------------------
if opt.need_test and epoch % opt.test_interval == 0 and epoch >= opt.test_interval:
for i, testBatch in enumerate(testloader):
imgTest = testBatch["img"].cuda()
rstTest = segment_net(imgTest)
fTest = rstTest["f"]
segTest = rstTest["seg"]
cTest = decision_net(fTest, segTest)
save_path_str = "./testResultDec/epoch_%d"%epoch
if os.path.exists(save_path_str) == False:
os.makedirs(save_path_str, exist_ok=True)
if cTest.item() > 0.5:
labelStr = "NG"
else:
labelStr = "OK"
save_image(imgTest.data, "%s/img_%d_%s.jpg"% (save_path_str, i , labelStr))
save_image(segTest.data, "%s/img_%d_seg_%s.jpg"% (save_path_str, i, labelStr))
# -----------------------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------储存网络-------------------------------------------------------
# -----------------------------------------------------------------------------------------------------------------------
if opt.need_save and epoch % opt.save_interval == 0 and epoch >= opt.save_interval:
save_path_str = "./saved_models"
if os.path.exists(save_path_str) == False:
os.makedirs(save_path_str, exist_ok=True)
torch.save(decision_net.state_dict(), "%s/decision_net_%d.pth" % (save_path_str, epoch))
print("save weights ! epoch = %d"%epoch)
pass
进行测试
from models import SegmentNet, DecisionNet, weights_init_normal
from dataset import KolektorDataset
import torch.nn as nn
import torch
from torchvision import datasets
from torchvision.utils import save_image
import torchvision.transforms as transforms
from torch.autograd import Variable
from torch.utils.data import DataLoader
import os
import sys
import argparse
import time
import PIL.Image as Image
#-----------------------------------------------------------------------------------------------------------------------
#---------------------------------------------设置参数--------------------------------------------------------------------
#-----------------------------------------------------------------------------------------------------------------------
parser = argparse.ArgumentParser()
parser.add_argument("--cuda", type=bool, default=True, help="number of gpu")
parser.add_argument("--test_seg_epoch", type=int, default=60, help="test segment epoch")
parser.add_argument("--test_dec_epoch", type=int, default=60, help="test segment epoch")
parser.add_argument("--img_height", type=int, default=704, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
opt = parser.parse_args()
print(opt)
dataSetRoot = "/home/sean/Projects/SegDecNet/Data" #这是原作者的文件路径,改成自己的文件路径
# ***********************************************************************
# Build nets
segment_net = SegmentNet(init_weights=True)
decision_net = DecisionNet(init_weights=True)
if opt.cuda:
segment_net = segment_net.cuda()
decision_net = decision_net.cuda()
if opt.dataSetRoot != 0:
# Load pretrained models
segment_net.load_state_dict(torch.load("./saved_models/segment_net_%d.pth" % (opt.test_seg_epoch)))
if opt.test_dec_epoch != 0:
# Load pretrained models
decision_net.load_state_dict(torch.load("./saved_models/decision_net_%d.pth" % (opt.test_dec_epoch)))
transforms_ = transforms.Compose([
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
#transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
testloader = DataLoader(
KolektorDataset(dataSetRoot, transforms_=transforms_, transforms_mask= None, subFold="Test", isTrain=False),
batch_size=1,
shuffle=False,
num_workers=0,
)
#segment_net.eval()
#decision_net.eval()
for i, testBatch in enumerate(testloader):
torch.cuda.synchronize()
imgTest = testBatch["img"].cuda()
with torch.no_grad(): #测试的时候梯度是不用更新的
rstTest = segment_net(imgTest)
fTest = rstTest["f"]
segTest = rstTest["seg"]
with torch.no_grad():
cTest = decision_net(fTest, segTest)
torch.cuda.synchronize()
if cTest.item() > 0.5:
labelStr = "NG" #认为他是有缺陷的图片
else:
labelStr = "OK" #认为他是无缺陷的图片
save_path_str = os.path.join(dataSetRoot, "testResult")
if os.path.exists(save_path_str) == False:
os.makedirs(save_path_str, exist_ok=True)
save_image(imgTest.data, "%s/img_%d_%s.jpg"% (save_path_str, i, labelStr))
save_image(segTest.data, "%s/img_%d_seg_%s.jpg"% (save_path_str, i, labelStr))