手把手教你搭建一个深度网络模型:从输入层-激活函数-损失函数-优化方法-输出层-执行训练
手把手教你搭建一个深度网络模型:从输入层-激活函数-损失函数-优化方法-输出层-执行训练
我这几天遇到一个不错的范例,将的是一层一层教我们搭建一个神经网络,其实很多我接触过的伙伴对修改模型架构这块还是头疼。其实我么可以从简单的神经网络层开始,自己DIY每一层,对上手修改架构有帮助。这里用的是paddle框架,当然玩pytorch的朋友也别急着关掉,因为我这几天刷到的pytorch感觉和飞桨的这块几乎是非常相似。只是有点点表达不一样,其他都完全一样。甚至连编程习惯都非常一样。下面是来自PaddlePaddle FLuid深度学习入门与实战一书的案例。
深度神经网络模型的搭建步骤如下。
第1步,我们使用 Paddlepaddle来定义一个深度神经网络模型。这个深度神经网络模型非常简单,结构包括输入层、隐层1、隐层2、输出层,这个深度神经网络模型一共有3层,因为输入层不参与计算,所以不算入总层数。使用 fluid. data0函数定义一个输入层,指定输入层的名称、形状以及类型, shape的第1个参数是输入数据的批量大小,通常设置为None,这样可以自动根据输入数据的批量大小变动,通常深度神经网络模型的输入层都是 float32类型的。然后使用 fluidlayers.fc0函数定义两个隐层,指定大小为100,激活函数为ReLU,这样的隐层也称为全连接层,全连接层的大小是指定的神经元数量,使用激活函数是为了让深度神经网络模型更具有非线性。最后是一个输出大小为1的全连接层,也称为输出层,没有指定激活函数。通过上面的过程最终构建了一个线性回归网络模型,它属于深度神经网络模型。这里使用 fluid. data()函数定义的输入层类似于 fluid. ayers. create tensor0函数,也有 name属性,之后根据这个属性值来填充数据。
import numpy as np
import paddle.fluid as fluid
x=fluid.data(name='x',shape=[None,1],dtype='float32')
hidden=fluid.layers.fc(input=x,size=100,act='relu')
hidden=fluid.layers.fc(input=hidden,size=100,act='relu')
net=fluid.layers.fc(input=hidden,size=1,act=None)
创建深度神经网络模型之后,就可以从主程序中复制一个程序用于预测数据。复制程序的顺序是有要求的,因为当我们使用 Paddlepaddle函数定义深度神经网络模型和损失函数等训练模型所用到的计算时, Paddlepaddle都按照顺序把这些计算添加到主程序中,所以当我们定义深度神经网络模型结束之后,主程序中只有一个深度神经网络模型,并没有损失函数或者准确率函数等的计算,从这里复制的预测程序只有深度神经网络模型的输入和输出,而深度神经网络模型输出的预测结果正是预测程序所需的。
infer_program=fluid.default_main_program().clone(for_test=True)
第2步,定义深度神经网络模型的损失函数。首先需要使用 fluid.data0函数定义一个标签层,这个标签层可以理解为每组数据对应的真实结果。然后定义一个平方 差损失函数,使用的Paddlepaddle函数是 fluid.layers. square_error_cost()函数。损失是指单个样本的预测值与真实值的差,损失值越小,代表深度神经网络模型越好;如果预测值与真实值相等,就是没有损失。用于计算损失值的函数就称为损失函数。我们可以使用损失函数来评估深度神经网络模型的好坏。 Paddlepaddle提供很多损失函数,如交叉熵损失函数。因为本实例是一个线性回归算法,所以使用的是平方差损失函数。
因为 fluid.layers.square.error cost0函数求的是一个批量的损失值,所以可以使用 Paddlepaddle的 fluid. layers. mean函数对其求平均值。
y=fluid.data(name='y',shape=[None,1],dtype='float32')
cost=fluid.layers.square_error_cost(input=net,label=y)
avg_cost=fluid.layers.mean(cost)
第3步,定义训练使用的优化方法。优化方法可以在训练深度神经网络模型的过程中修改学习率的大小,可以使得学习率更有利于深度神经网络模型的收敛。这里使用的是随机梯度下降( Stochastic gradient Descent,SGD)优化方法。Paddlepaddle提供了大量的优化方法,除了本实例使用的SGD,还有 Momentum、Adagrad等,读者可以根据自己的需求使用不同的优化方法。在定义优化方法时,可以指定学习率的大小,学习率的大小也需要根据情况而定。当学习率比较大时,深度神经网络模型的收敛速度会很快,但是有可能达不到全局最优;当学习率太小时,会导致深度神经网络模型收敛得非常慢。
optimizer=fluid.optimizer.SGDOptimizer(learning_rate=0.01)
opts=optimizer.minimize(avg_cost)
第4步,创建一个执行器,我们同样使用CPU来进行训练。创建执行器之后,使用执行器来执行 fluid. default startup_ program0函数初始化参数。
place=fluid.CPUPlace()
exe=fluid.Executor(place)
exe.run(fluid.default_startup_program())
我们使用 Numpy定义一组数据,这组数据分别是输入层的数据x_data和标签层的数据 y data,这组数据有5个,相当于一个小的批量。这组数据是符合y=2*x+1的,但是程序并不知道这组数据是符合什么规律的。我们之后使用这组数据进行训练,看看强大的深度神经网络是否能够训练出一个拟合这个函数的深度神经网络模型。
x_data=np.array([[1.0],[2.0],[3.0],[4.0],[5.0]]).astype('float32')
y_data=np.array([[3.0],[5.0],[7.0],[9.0],[11.0]]).astype('float32')
第5天,开始训练深度神经网络模型。我们训练了100轮,随着训练的进行深度神经网络模型不断收敛,直到完全收敛,完全收敛的表现是损失值固定在一个值周围浮动变化。可根据深度神经网络模型训练的实际情况设置训练的轮数,直到深度神经网络模型完全收敛。关于 Executor.run()函数的参数在第2章已经介绍过,其中 program参数的值仍然是 fluid. default_ main_program函数,而feed参数是一个字典型参数,这次输出有两个值,分别是深度神经网络模型的输入层x和标签层y。 fetch_list参数的值是 avg_ cost,该参数可以让执行器在训练过程中输出深度神经网络模型的损失值,观察模型收敛情况。
for pass_id in range(100):
train_cost=exe.run(program=fluid.default_main_program(),
feed={x.name:x_data,y.name:y_data},fetch_list=[avg_cost])
print("pass:%d,Cost:%0.5f"%(pass_id,train_cost[0]))
以下就是在训练过程中输出的部分日志,从损失值来看,深度神经网络模型能够收敛而且收敛到一个非常好的状态。
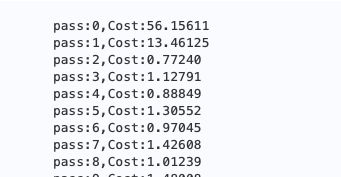
训练结束之后,定义了一个预测数据,使用这个数据作为x的输入,看看是否能够预测出与正确值相近的结果。这次 exe.run函数的 program参数值是我们从主程序中复制的预测程序 infer program, fetch list参数的值是深度神经网络模型的输出层,这样就可以把深度神经网络模型的预测结果输出。
test_data=np.array([[6.0]]).astype('float32')
result=exe.run(program=infer_program,
feed={x.name:test_data},fetch_list=[net])
print(":%0.5:f" % result[0][0][0])
以下是预测结果,上面定义的数据满足y=2*x+1的规律。所以当x为6时y应该是13,最后输出的这个结果已经非常接近13了,成功达到了我们的预期。
当x为6.0时,y为:12.91597
利用房价数据集对深度神经网络模型进行验证
上面的例子中我们使用了自己定义的数据, Paddlepaddle提供了很多常见的数据集。在下面的例子我们将会使用 Paddlepaddle提供的数据集并使用上面的深度神经网络模型进行训练。首先创建 uci_housing_linear.py文件,这次使用的是波士顿房价数据集( Boston Housing Data Set),这个数据集是学习线性回归算法最常用的数据集之一.
首先导入所需的依赖库,其中 paddle dataset. uci_ housing用于获取波士顿房价数据集。
import numpy as np
import paddle as paddle
import paddle.dataset.mnist as mnist
import paddle.fluid as fluid
from PIL import Image
然后定义深度神经网络模型、获取预测程序、定义损失函数、定义优化方法和创建执行器。这些步骤与上面的例子是一样的。
#定义一个简单的深度神经网络模型
x=fluid.data(name='x', shape=[None, 131, dtype= 'float32 ' )
hidden=fluid.layers.fc(input=x, size=100, act=' relu')
hidden=fluid.layers.fc(input=hidde,size=100, act='relu')
net=fluid.layers.fc(input-hidden, size=1, act=None)
#获取预测程序
infer_program=fluid.default_main_program().clone(for_test=True)
#定义损失函数
y= fluid.data(name='y', shape=[None, 1], dtype='float32')
cost=fluid.layers.square_error_cost(input=net,label=y)
#定义优化方法
optimizer=fluid.optimizer.SGDOptimizer(learning_rate=0.01)
opts=optimizer.minimize(avg_cost)
#创建一个使用CPU的执行器
place=fluid.CPUPlace()
exe=fluid.Executor(place)
exe.run(fluid.default_startup_program())
这次我们的数据集不是一下子全部“丢入”训练中,而是把它们分成一个个小批量数据,每个批量数据的大小我们可以通过 batch size进行设置,这里定义了训练和测试两个数据集。
train_reader=paddle.batch (reader=uci_housing.train (), batch_size-128
test _reader=paddle.batch (reader=uci_housing.test () ,batch_size=128)
接着定义数据输入的维度。在使用自定义数据的时候,我们是使用键值对方式添加数据的,但是我们调用API来获取数据集时,已经将属性数据和结果放在一个批量数据中了,所以需要使用 Paddlepaddle:提供的 fluid. Datafeeder0函数接收输入的数据, place参数指定是向GPU还是CPU中输入数据, feed list参数指定输入层。
feeder=fluid.Datafeeder(place=place, feed_list=[x,y])
接下来就开始训练,每一轮训练都会把数据集拆分为多个批量数据,每次训练一个批量数据,通过 feeder feed函数把数据加入训练中。
for pass id in range (300):
train cost= 0
fot batch_id, data in enumerate (train_reader ())
train _cost=exe.run(program=fluid.default_main_program(),
feed=feeder.feed (data),
fetch_list=[avg cost])
print("Pass:% d, Cost: %0.5f"% (pass_id, train_cost [0][0]))
以下是训练过程中输出的日志。
Pass:0,Cost:22.68169 Pass:1,Cost:282.92120 Pass:2,Cost:110.04783
Pass:3,Cost:66.75029 pass:4,Cost:19.97637 Pass:5,Cost:101.58493 Pass:6,Cost:16.02094 Pass:7,Cost:43.32439 Pass:8,Cost:20.95375 Pass:9,Cost:20.79462