论文阅读Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
论文信息
题目
Sentence Embeddings using Siamese BERT-Networks
使用孪生BERT网络结构的句子嵌入
作者
Nils Reimers, Iryna Gurevych
论文水平
EMNLP 2019
其它
论文下载地址:https://arxiv.org/abs/1908.10084
该论文的相关代码已开源,github链接:sentence-transformers,sentenc-tansformers文档:官方文档
sentenc-tansformers非常好用,封装的很好,使用简单
Abstract
虽然BERT和RoBERTa在很多句子对形式的回归任务(例如文本语义相似度)上达到了SOTA效果,但是它们还存在一些缺点:在这些任务中,它们均需要将比较的两个句子都传入到模型中计算,计算开销过大。BERT模型在一个1W句子集合中,找出最相近的一个句子对,需要5千万次推断计算(约65小时)才能完成,所以BERT并不适合语义相似度搜索等任务。
在该论文中,作者提出了一个新的模型,Sentence-BERT(简称SBERT)。SBERT采用双重或三重BERT网络结构,具体结构介绍会在后文中详细介绍。如果使用的是基于RoBERTa模型,则改造后的模型简称为SRoBERTa。
通过SBERT模型获取到的句子embedding,可以直接通过cos相似度计算两个句子的相似度,这样就大大减少了计算量。因为在使用BERT模型进行句子间相似度的判断时,需要从句子集合中,选出两个句子进行组合,传入BERT中进行计算,而使用SBERT模型,只需要将集合中每个句子单独传入到模型中,得到每个句子的embeding,计算相似度只需要使用cos函数计算两两embeding的cos距离即可。因此,使用BERT/RoBERTa模型需要65h才能完成的寻找最相似句子对任务,SBERT模型完成仅需5s。
作者在一些STS任务和迁移学习任务上评估SBERT模型,该模型达到了新的SOTA水平。
Introduction
SBERT模型可以很好的从语义上表征一个句子,这使得语义越相似的句子在向量空间中的embeding向量距离越近。
这使得SBERT模型可以很好的完成一些BERT不适合完成的任务,例如:大规模语义相似度比较、聚类、通过语义搜索的信息检索等任务。
我们上面提到过,BERT判断两个句子语义是否相似,需要将两个句子拼起来传入到model里,不适合多句子相似度判断。如果从句子数量为n的集合中,找出最近似的两个句子,则需要n*(n-1)/2次比较,并且每次比较均需要传入到BERT模型中进行计算,这个开销是很大的。
目前的一个通用的方法是将语义相近的句子,映射到同一向量空间中相近的位置,通过一个向量来表征整个句子。
BERT惯用的表征一个句子的方式是取第一个[CLS] token的输出或所有输出取平均来表示一个句子,经过试验证明,这些方式经常会产生质量很差的embedding。
为了解决问题,作者提出了SBERT模型,SBERT模型输出的sentence embedding,可直接通过cos距离、欧式距离或曼哈顿距离就可计算出句子间相似度。
与其他的句子表征模型相比,SBERT在很多任务上都取得了SOTA。
Related Work
首先介绍了BERT,然后讨论了一些其他的句子表征模型,例如InferSent、 SkipThought、Universal Sentence
Encoder等,在后面的实验部分,也会与这些模型进行比较。
SBERT基于预训练的BERT改进后的模型,大大减少了训练所需的时间,SBERT经过不到20分钟的微调后,就已超越了很多其他的sentence embedding模型。
Model
SBERT模型采用三种pooling策略:CLS、MEAN、MAX,默认SBERT采用MEAN pooling 。
采用双重或三重网络结构对BERT/RoBERTa进行微调,更新模型参数,使得调整后的模型,产生的句子embedding可直接通过cos计算相似度。
实验的结构和目标函数:
- 分类目标函数Classification Objective Function:
将句子向量 u u u、 v v v、 ∣ u − v ∣ |u-v| ∣u−v∣拼接起来并乘以训练得到的权重 w t ∈ R 3 n × k w_t∈R^{3n×k} wt∈R3n×k。
o = s o f r m a x ( w t ( u , v , ∣ u − v ∣ ) ) o = sofrmax(w_t(u,v,|u-v|)) o=sofrmax(wt(u,v,∣u−v∣))
n表示句子向量的维度,k表示标签的个数。
结构如图1所示:

- 回归目标函数Regression Objective Function:
使用cos函数计算两个句子embeding的相似度,使用均方误差作为损失函数。
结构如图2所示:

- 三元组目标函数Triplet Objective Function:
给定一个句子 a a a,一个正例句子 p p p,一个负例句子 n n n。triplet loss微调网络使得句子 a a a与句子 p p p的距离比 a a a与句子 n n n的距离小,即句子 a a a的sentence embedding 更接近句子 p p p的sentence embedding。
loss function如下所示:
m a x ( ∣ ∣ s a − s p ∣ ∣ − ∣ ∣ s a − s n ∣ ∣ + ϵ , 0 ) max(||s_a-s_p||-||s_a-s_n||+\epsilon,0) max(∣∣sa−sp∣∣−∣∣sa−sn∣∣+ϵ,0)
s a 、 s p 、 s n s_a、s_p、s_n sa、sp、sn分别表示句子a、p、n的embeding, ϵ \epsilon ϵ参数的目的是为了保证 s p s_p sp到 s a s_a sa的距离至少比 s n s_n sn到 s a s_a sa的距离近 ϵ \epsilon ϵ。
在实验中,使用欧式距离并设置 ϵ = 1 \epsilon=1 ϵ=1。
Training Details
使用SNLI和Multi-Genre NLI数据集训练SBERT。
训练参数设置:
- batch-size:16
- Adam optimizer learning rate: 2e-5
- linear learning rate warm-up : 10% of training data
- pooling strategy: MEAN
Evaluation - Semantic Textual Similarity
在一些文本语义相似度任务(STS)评估SBERT表现。
使用cos相似度评估两个句子embeding的相似度,作者也尝试换成曼哈顿方式和欧式距离,实验结果表明,效果几乎相同。
Unsupervised STS
使用的数据集:STS tasks 2012 - 2016、STS benchmark、SICK-Relatedness。
这些训练集均提供0-5的标签,0表示两个句完全无关,5表示两个句子完全相同。
经过实验证明,Pearson相关性很不适合于评估STS任务。因此,使用Spearman相关性来评估。
实验结果如表1所示:
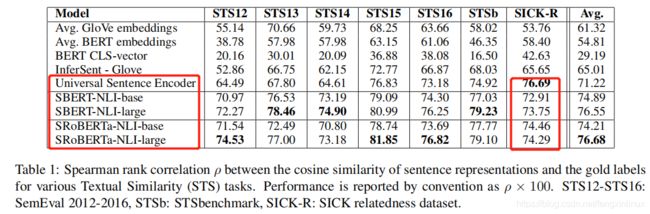
实验分析:
- 实验结果表明,BERT模型在该类任务上表现极差,结果比GloVe还低,也验证了前文所说的,BERT模型不适合应用于该类任务上。
- SBERT取得了很大的提高,但是仔细观察可以发现,SBERT在
SICK-R这个数据集上的表现不如Universal Sentence Encoder模型。这必须要自圆其说一波,作者解释如下:Universal Sentence Encoder模型在很多数据集上进行了训练,包括新闻,问答对等等,这些数据集内容更适合SICK-R,然而,SBERT仅在Wikipedia和NLI数据集上进行了预训练。 - 尽管RoBERTa相比于BERT在很多任务上变现更出色,但是在该文的实验中,这两个模型表现差别很小。
Supervised STS
使用的数据集:STS benchmark (STSb)
实验结果如表2所示:
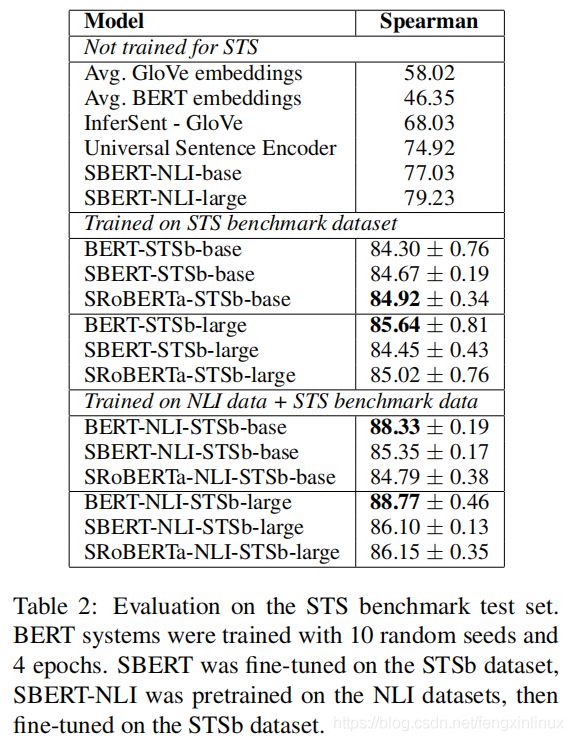
实验设置了两种不同的训练策略来比较结果:
1.只在STSb训练集上训练
2.现在NLI训练集上训练,再在STSb数据集上训练
实验分析:
- 实验结果证明,在SBERT模型上,第二种训练策略表现稍微更好一点,提高了1-2个点。
- 在BERT模型上,两种策略的影响较大,第二种策略提高了3-4个点。
- BERT 和 RoBERTa差异不大。
Argument Facet Similarity
使用的数据集:Argument Facet Similarity (AFS)
该数据集与STS数据集相比差异较大,STS数据通常是描述性的数据,而AFS数据是来自对话中的论据节选。
由于 Argument数据集的特殊性,很多方法在该数据集上表现很多差。
实验结果如表3所示:
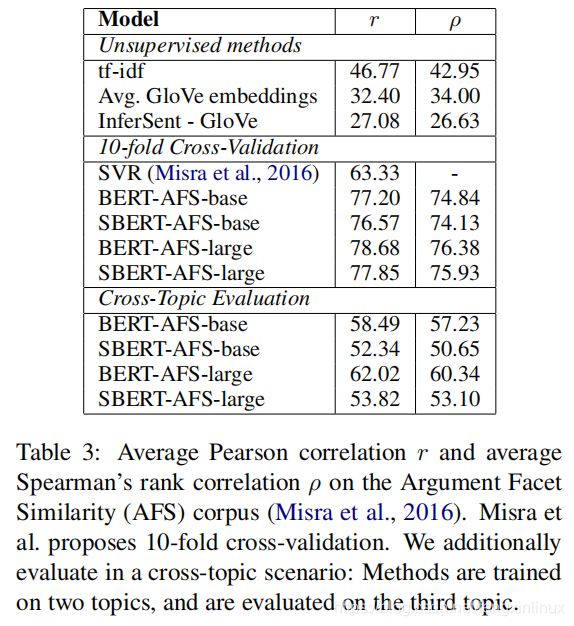
实验分析:
- tf-idf、GloVe、InferSent等模型在该数据集上表现很差,在10折交叉验证上SBERT表现与BERT接近,但是实际上还是比BERT差一点。。
- 在交叉主题评估上,SBERT的Spearman评分与BERT相差了7个点。原因是SBERT需要事先将未曾见过的具有相似的主张和理由的主题映射到向量空间中同一块区域,这个难度较大,然而BERT只需要逐一比较两个句子的单词差异。
Wikipedia Sections Distinction
使用训练集:Wikipedia
我们通过经验认为,来自同一章节或段落的句子间是比来自不同段落的句子更接近的,相似度更高。
因此,Wikipedia训练集将来自同一段的句子作为正例,来自不同段的句子作为负例。
实验结果如表4所示:

Evaluation - SentEval
使用数据集: SentEval
SentEval是一个用来评估句子embeding质量的工具。
SBERT设计的目的不是用于迁移学习任务,但是Sbert 在SentEval上数据集上表现也很出色,证明了Sbert在迁移学习任务上的性能。
作者在七种SentEval迁移任务上与其他的sentence embeding模型进行了比较:

实验结果如表5所示:
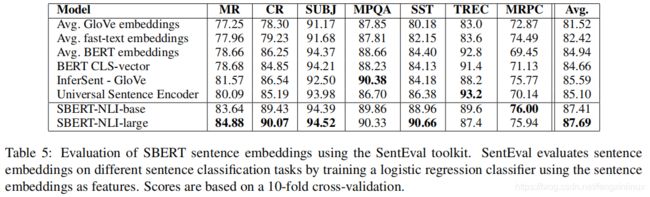
实验分析:
- 由实验结果可以看出,尽管SBERT的设计目的不在于迁移学习,但是SBERT在很多任务上都超过了其他SOTA sentence embeding模型。
- SBERT模型的句子表征可以很好的捕获情感信息,在所有的情感类分析任务上(MR,CR,SST)具有较大的提升。
- SBERT在TREC数据集上,表现不如Universal Sentence 模型,因为Universal Sentence 模型在QA数据集上进行的预训练,因此Universal Sentence 模型更适合于问题类型的分类任务。
- average/cls BERT embeding不适合用于cos、曼哈顿、欧式距离。
Ablation Study
消融实验,其实可以简单的理解为就是控制变量法,探寻模型各种设置的相对重要性。
作者主要进行了两个实验的探索,第一个为不同pooling策略的影响,第二个为对于分类目标函数,对两个句子向量的不同拼接方法的影响。
采用不同的随机种子测试10次并求得平均结果。
分类目标函数使用SNLI数据集训练,回归目标函数使用STS数据集训练,使用STS数据集作为验证测试。Concatenation拼接消融实验均采用mean pooling策略。
实验结果如表6所示:

实验分析:
- 对于分类目标函数的训练,pooling策略产生的性能差异很小,拼接策略影响非常大。
- 加入 u ∗ v u*v u∗v反而降低性能,最重要的元素是 ∣ u − v ∣ |u-v| ∣u−v∣。
- 对于回归目标函数,pooling策略影响较大,经测试,MAX pooling表现最差。
Computational Efficiency
在该部分,作者测试了SBERT的计算效率,并与其他模型就行了比较,所有模型统一使用STS数据集进行测试。
作者使用了一个减少padding tokens的计算开销策略:把长度相近的句子,放在一个mini-batch中,这样只需要按照所在mini-batch中最长句子长度进行填充,减少所需总填充token的个数与次数。
实验结果如表7所示:

实验分析:
- 在CPU上,SBERT比InferSent慢,是因为InferSent结构简单,使用单一Bi-LSTM,而BERT采用12层transformer。
- 然而,tansormer结构的优势在GPU上能够很好的发挥,在GPU上经过batch优化的SBERT速度性能超过了InferSent。
Conclusion
略