R语言进行模型重要性指标绘图
我们通常见到部分文章建立模型后建立一个变量的重要性可视化图,意思是哪个变量对模型的影响更加重要。后台有粉丝问我,这种建立模型后的变量重要性可视化图怎么做。


今天我们来通过R语言演示一下,可以做可视化模型的R包很多,我们先来演示一下ingredients包,这个包的特点是做起来相对好做,支持许多模型。我们通过使用我们的早产数据(公众号回复:早产数据,可以获得该数据)来演示一下,我们先导入R包和数据,
library("DALEX")
library("ingredients")##可视化包
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
bc <- na.omit(bc)

这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数bwt 新生儿体重数值。我们先把分类变量转成因子
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$low<-factor(bc$low)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
建立回归方程
fit<-glm(low ~ age + lwt + race + smoke + ptl + ht + ui + ftv,
family = binomial("logit"),
data = bc)
对方程进行解释,主要就是把数据的结果变量和其他变量分开
explain_titanic_glm <- explain(fit,
data = bc[,-2],
y = bc[,2])
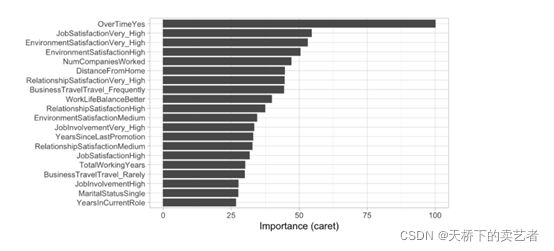
生产图片数据并绘图,这里没注意ID这个指标也放进来了
fig<- feature_importance(explain_titanic_glm, B = 1)
plot(fig)

由上图可以看出ui和age是影响早产的两个重要指标。
接下来我们来做一个cox回归的,要使用到,R的tornado包,这个包也是能做logistic回归
二分类数据的,如果使用我们刚才的数据就是
gtest <- glm(low ~ age + race + smoke + ptl + ht + ui + ftv, data=bc, family=binomial(link="logit"))
gtestreduced <- glm(low ~ 1, data=bc, family=binomial(link="logit"))
imp <- importance(gtest, gtestreduced)
plot(imp)

好了,有点扯远了,使用我们的乳腺癌数据
library(foreign)
library(survival)
bc <- read.spss("E:/r/test/Breast cancer survival agec.sav",
use.value.labels=F, to.data.frame=T)
bc$histgrad<-as.factor(bc$histgrad)
bc$er<-as.factor(bc$er)
bc$pr<-as.factor(bc$pr)
bc$ln_yesno<-as.factor(bc$ln_yesno)
names(bc)
bc <- na.omit(bc)
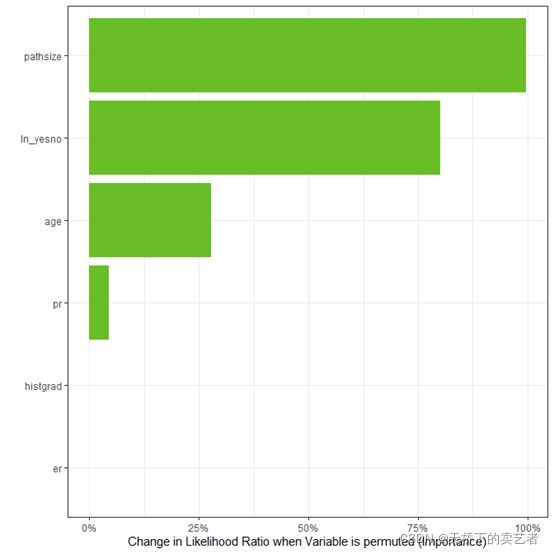
建立回归方程并绘图
model_final <- survival::survreg(survival::Surv(time, status) ~ age + histgrad+pathsize+ er + pr + ln_yesno,
data = bc,dist = "weibull")
imp <- importance(model_final, bc, nperm = 500)
plot(imp)
接下来绘制多元线性回归,就使用我们的臭氧数据把
library(foreign)
be <- read.spss("E:/r/test/ozone.sav",
use.value.labels=F, to.data.frame=T)

数据中有七个变量,ozon每日臭氧水平为结局变量,Inversion base height(ibh)反转基准高度,Pressure gradient (mm Hg) 压力梯度(mm Hg),Visibility (miles) 能见度(英里),Temperature (degrees F) 温度(华氏度),Day of the year日期,vh我也不知道是什么,反正就是一参数,这里所有的变量都是连续的。
建立方程
fit <- lm(ozon ~ vh +ibh+temp+dpg, data=be)
绘图
fitreduced <- lm(ozon ~ 1, data=be)
imp <- importance(fit, fitreduced)
plot(imp)

Tornado包还可以进行LASSO回归,随机森林等重要变量的可视化,自己试试把。
