CBNetV2论文的译读笔记
论文名称
CBNetV2: A Composite Backbone Network Architecture for Object Detection
摘要
如今性能最好的目标检测器在很大程度上依赖于骨干网络,其进步会带来一贯的性能提升,而这需要探索更有效的网络结构。在本文中,作者提出了新型可伸缩的主干网络架构,称为CBNetV2,使用“已有的”开源预训练主干网络并使用 pre-training fine-tuning范式构建高性能的检测器。特别的是,CBNetV2框架组合多个相同的主干网络,这些网络通过复合连接相连。具体来说,它融合了多个主干网络的高层和低层特征并逐步扩展其感受野葱而更加有效地实现目标检测。作者还给基于CBNet的检测其提出了一种更好的训练策略—— assistant supervision。CBNetV2对于检测器架构中使用不同主干网络或者head设计都据iyou很强的泛化能力。在复合的主干网络没有额外预训练的情况下,CBNetV2可以适应于不同的backbones(例如:基于CNN和基于Transformer),以及大多数主流检测器的head设计(例如:one-stage vs .two-stage、anchor-based vs. anchor-free-based)。实验结果表明,相较于单纯加大网络的深度和宽度,CBNetV2能够用一种效果更好、效率更高且资源优化的方式来,构建高性能的主干网络。值的注意的是,基于CBNetV2的DualSwin-L模型在COCO-test-dev上实现了59.4%-box-AP以及51.6%-mask-AP,这是在单模和单尺度测试模式下实现的,比Swin-L模型实现的SOTA结果(例如:57.7%-box-AP和50.2%-mask-AP)相比有显著的提升;并且本文模型的训练周期缩短了6倍。在使用多尺度测试的情况下,本文模型将当前最好的单模结果提升到一个全新的记录,60.1%-box-AP以及52.3%-mask-AP,且不需要额外的训练数据。代码开源在https://github.com/VDIGPKU/CBNetV2。
1 引言
目标检测是计算机视觉中基础任务之一,可广泛应用于自动驾驶、智能视频监控、遥感等。近些年来,得益于深度卷积神经网络【2_AlexNet】的蓬勃发展,目标检测算法取得了很大进展,并提出了许多优秀的检测模型,例如:SSD【3_SSD】, YOLO【4_YOLOv1】, Faster RCNN【5_FasterRCNN】, RetinaNet【6_RetinaNet】, ATSS【7_ATSS】, Mask R-CNN【8_MaskRCNN】, Cascade R-CNN【9_CascadeRCNN】等。
通常来说,在NN-based(Neural-Network-based)检测器中,主干网络用来提取用于检测物体的基本特征,并且其设计最初源于图像分类任务,会在ImageNet数据集上预训练【10_ImageNet_Database】。从直觉来看,主干网络提取的特征越具有代表性,检测模型的效果就会越好。为了获得更高的精度,主流检测模型会使用更深更宽的主干网络(例如:移动端模型【11_MobileNetv1, 12_Shufflenetv1】和ResNet【13_ResNet】,到ResNeXt【14_ResNeXt】和Res2Net【15_Res2Net】。近期,有工作针对基于Transformer【16_Transformer】的主干网络展开研究,并展示出较好的性能。总的来说,在大规模预训练主干网络(large backbone pretraining)的进步体现出目标检测正朝着更加高效的多尺度表示发展。
基于大规模预训练主干网络的检测模型结果十分优秀,受此启发,本文期望利用现有的精心设计的主干网络架构及其预训练权重,在构建高性能检测模型上取得进一步提升。一方面,设计全新的主干网络架构需要专家知识和大量的试错。另一方面,对一个全新主干网络(尤其是大型模型)在ImageNet上预训练需要大量的计算资源,这让使用预训练和微调范式来获取更好检测性能的成本较高。可供选择地是,可以从头开始开始训练检测模型来节省预训练成本,但是也许需要更多计算资源和训练技巧来训练模型【17_Rethink_Scratch】。
本文提出一种简单新颖的组合方法,在预训练微调范式下使用使用现有的预训练主干网络。不同于大多数已有方法关注于模块设计并且需要在 ImageNet 上预训练来增强特征表示,本文在无需额外预训练的情况下提高了现有主干网络的特征表示能力。如图1所示,所提出的解决方案称为 Composite Backbone Network V2 (CBNetV2),将多个相同的主干网络组合在一起。
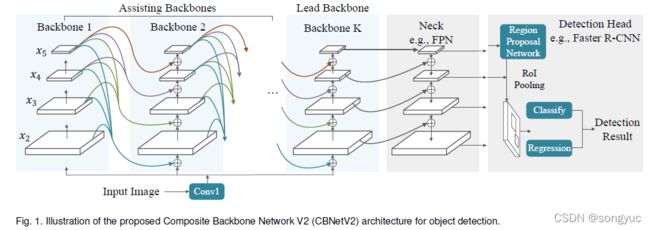
具体来说,多个并行的主干网络(称为 assisting backbones和 lead backbone)通过复合连接相连。在图1中,从左至右,assisting backbones中每个stage的输出流向流向其后续兄弟网络中并行和更浅层次的stage。最后,lead backbone的特征被传递给neck和检测头用来进行定位框回归和分类。相较于简单地将网络变深或变宽,CBNetV2融合了多个主干网络高层和浅层的特征并逐步扩展了感受野,从而实现更加高效的目标检测。可以看到,CBNetV2中每个集成的主干网络使用现有开源预训练的单个主干的权重来初始化(例如,Dual-ResNet50由ResNet50【13_ResNet】的权重来初始化,此权重可以在开源社区中获得)。除此之外,本文提出一种有效的训练策略,使用 assisting backbones提供监督信息,实现了比CBNetV1【1_CBNetv1】更高的检测精度,并且没有牺牲推理速度。
本文通过在MS-COCO基准【18_COCO】上实验证明了所提出框架的有效性。实验显示CBNetv2有很强的泛化能力,适用于不同主干网络和head设计构成的检测器架构,使得所训练的检测模型大幅度超越基于更大主干网络的模型。具体来说,CBNetv2可以用于多种主干网络(例如,从convolution-based【13_ResNet, 14_ResNeXt, 15_Res2Net】到Transformer-based【19_SwinTransformer】)。相较于原始的主干网,所提出的Dual-Backbone性能提升3.4%~3.5%AP,显示出CBNetV2的有效性。在可比较的模型复杂度下,Dual-Backbone仍然提升了1.1%~2.1%,这表明组合的主干网络比预训练后、更宽更深的网络更有效。除此之外,CBNetV2可以灵活地插入到主流检测器(例如,RetinaNet【6_RetinaNet】, ATSS【7_ATSS】, Faster RCNN【5_FasterRCNN】,Mask R-CNN【8_MaskRCNN】, Cascade R-CNN和 Cascade Mask R-CNN【9_CascadeRCNN】)中,并且这些检测器的性能都一致提升3%~3.8%AP,展示其对多种探测器head设计的强大适应性。值得注意的是,CBNetV2 提供了一项通用且资源友好的框架,来推动高性能检测器的峰值。在无需各种技巧的情况下,所提出的Dual-Swin-L在单模单尺度情况下,实现COCO-test-dev数据集59.4%boxAP和51.6%maskAP,超越了现有的SOTA结果(例如:由Swin-L取得的57.7%boxAP和50.2%maskAP),同时训练时长减少了6倍。在多尺度测试情况下,本文将现有最好的单模结果提高到新纪录60.1%boxAP和52.3%maskAP。
本文的主要贡献列举如下:
- 提出了一种通用、高效且高性能的框架,CBNetV2 (Composite Backbone Network V2),来构建用于目标检测的高性能主干网络,且不需要额外的预训练。
- 本文提出 Dense Higher-Level Composition(DHLC)方式和辅助监督,以在预训练微调范式下更有效地利用现有预训练权重进行目标检测。
- 本文提出的Dual-Swin-L实现了COCO数据集上单模单尺度结果的新纪录,比Swin-L训练周期缩短(6倍)。在多尺度测试条件下,本文的方法实现了在没有额外训练数据的情况下实现了最好的结果。
2 相关文献
目标检测。目标检测旨在输入图像中定位出一组预定义类别中的每个对象实例。随着CNN的快速发展,基于深度学习的目标检测器的流行范式是:主干网络(通常为分类设计并在ImageNet上预训练)从输入图像中提取基本特征,然后neck(例如:Feature Pyramid Network【21_FPN】)从主干网络提取的多尺度特征,之后检测head利用位置和类别信息预测物体的定位框。基于检测heads,通用目标检测可以被分成两个主要分支。第一个分支包含一阶段检测器例如,YOLO【4_YOLOv1】、SSD【3_SSD】、RetinaNet【6_RetinaNet】、NAS-FPN【22_NASFPN】和EfficientDet【23_EfficientDet】。另一个分支包含两阶段方法,例如,Faster RCNN【5_FasterRCNN】、FPN【21_FPN】、Mask R-CNN【8_MaskRCNN】、Cascade R-CNN【9_CascadeRCNN】和Libra R-CNN【24_LibraRCNN】。近期,学术界有研究已转向anchor-free检测器,部分原因是FPN【21_FPN】和Focal-Loss【6_RetinaNet】的出现,这些研究提出了更加简洁的端到端检测器。一方面,FSAF【25_FSAF】、FCOS【26_FCOS】、ATSS【7_ATSS】和GFL【27_GFL】使用基于中心点的anchor-free的方法改进了RetinaNet。另一方面,CornerNet【28_CornerNet】和CenterNet【29_Center_Keypoint_Triplets】使用基于关键点的方法检测目标的定位框。
最近,Neural Architecture Search(NAS)被用于自动搜索针对特定检测模型的架构。NAS-FPN【22_NASFPN】、NAS-FCOS【30_NASFCOS】和SpineNet【31_SpineNet】使用强化学习来控制架构采样以获得较好的结果。SM-NAS【32_SMNAS】使用进化算法和偏序修剪方法可以搜索检测器不同部分的最优组合。Auto-FPN【33_AutoFPN】使用基于梯度的方法来搜索最佳的检测器。DetNAS【34_DetNAS】和OPANAS【35_OPANAS】使用one-shot方法搜索对目标检测任务分别搜索高效的主干和neck部分。
除了以上基于CNN的检测器外,Transformer【16_Transformer】也被用于检测任务。DETR【36_DETR】通过结合CNN和Transformer编解码器,提出一种端到端的检测模型。SwinTransformer【19_SwinTransformer】提出一种通用的Transformer主干网络来降低计算复杂度,并且在目标检测方面取得了巨大的成功。
用于目标检测的主干网络。从AlexNet【2_AlexNet】开始,主流检测器开始探索更深更宽的主干网络,例如:VGG【37_VGG】、ResNet【13_ResNet】、DenseNet【38_DenseNet】、ResNeXt【 14_ResNeXt】和Res2Net【15_Res2Net】。通常,主干网络是为分类任务而设计的,于是,主干需要在ImageNet预训练而后在给定检测数据集上微调,或者在检测数据集上从头训练,这都需要许多计算资源并且难以optimize。最近,两项改进设计的网络,即:DetNet【39_DetNet】和FishNet【40_FishNet】,是专门为检测任务而设计。然而,它们仍然需要在分类数据上预训练,而后在检测数据上微调。Res2Net【15_Res2Net】在目标检测中实现了令人欣喜的结果,它在细粒度上表示多尺度特征并在每个网络阶段逐渐提升感受野范围。除了手动设计主干架构之外,DetNAS【34_DetNAS】使用NAS来搜索对目标检测任务更好的主干网络,从而降低了手工设计模型的成本。SwinTransformer【19_SwinTransformer】使用Transformer模块来构建主干网络,并取得了优秀的结果。
众所周知,设计和预训练一个新的鲁棒的主干网络需要大量的计算成本。作为替代方案,本文提出一种更加经济和高效的解决方案,可以构建一个更加强大针对目标检测的主干网络,即将多个相同的主干网络组合起来(例如:ResNet【13_ResNet】、ResNeXt【 14_ResNeXt】、Res2Net【15_Res2Net】和SwinTransformer【19_SwinTransformer】)。
Recurrent Convolution Neural Network。不同于CNN的前向结构,Recurrent CNN(RCNN)【20_RCNN】在每个卷积层中组合多个循环连接。这个属性增强了模型融合上下文信息的能力,这一点对目标检测十分重要。如图3所示,本文提出的Composite-Backbone-Network与展开的RCNN【20_RCNN】有些相似,但它们实际上区别很大。首先,如图3所示,CBNet并行stages之间的连接是单向的,但是RCNN中是双向的。其次,在RCNN中,不同时间步是的并行stages共享参数权值,然而在CBNet中,主干网络的并行stages是彼此独立的。除此之外,如果想使用RCNN作为检测器的主干网络,需要将其在ImageNet上预训练。相对而言,CBNet不需要额外的预训练,因其直接使用现有的预训练权重。
3 本文方法
本章节将详细地说明所提出的CBNetV2。章节3.1和章节3.2将分别描述CBNetV2的基本架构及其变体。章节3.3提出了针对基于CBNet检测模型的训练策略。章节3.4简要地介绍了剪枝策略。章节3.5总结了基于CBNetV2的检测框架。
3.1 CBNetV2架构
本文提出的CBNetV2由 K K K个相同的主干( K ≥ 2 K\geq2 K≥2)构成。具体的,本文将K=2的情况(如图3.a所示)称为Dual-Backbone(DB),K=3的情况称为Triple-Backbone(TB)。
如图1所示,CBNetV2架构包含两种主干:核心主干 B K B_K BK和辅助主干 B 1 , B 2 , . . . , B K − 1 B_1,B_2,...,B_{K-1} B1,B2,...,BK−1。每个主干包含 L L L个stages(通常 L = 5 L=5 L=5),每个stage由多个卷积层构成,同一个stage中特征图的尺寸相同。在主干网络中第 l l l个stage实现的非线性变换记为 F l ( ⋅ ) ( l = 1 , 2 , . . . , L ) F^l(\cdot)(l=1,2,...,L) Fl(⋅)(l=1,2,...,L)。
大多数经典的卷积神经网络会遵循将输入图像编码为多个中间特征的设计,并且这些层的分辨率会依次减小。 特别地,第 l l l个stage会以上一个stage的输出(记为 x l − 1 x^{l-1} xl−1)作为输入,其表达式如下:
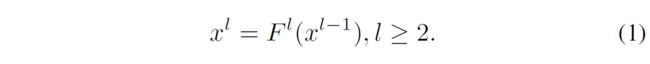
不同的是,本文使用了辅助主干 B 1 , B 2 , . . . , B K − 1 B_1,B_2,...,B_{K-1} B1,B2,...,BK−1来提升核心主干 B K B_K BK的表示能力。本文以stage-by-stage的形式将一个主干网的特征迭代到它的前辈中。因此,公式(1)可以写为:
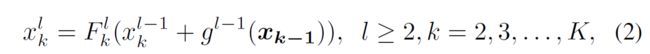
其中, g l − 1 ( ⋅ ) g^{l-1}(\cdot) gl−1(⋅)表示复合连接,它接收辅助主干 B k − 1 B_{k-1} Bk−1的特征(记为 x k − 1 = { x k − 1 i ∣ i = 1 , 2 , . . . , L } \boldsymbol{x_{k-1}}=\left \{x_{k-1}^{i} \left|i=1,2,...,L\right.\right\} xk−1={xk−1i∣i=1,2,...,L})作为输入,以跟 x k l − 1 x_{k}^{l-1} xkl−1相同大小的特征作为输出。因此, B k − 1 B_{k-1} Bk−1的输出特征经过变换并贡献于 B k B_k Bk每个stage的输入。注意 x 1 1 , x 2 1 , . . . , x K 1 x_{1}^{1},x_{2}^{1},...,x_{K}^{1} x11,x21,...,xK1是权重共享的。
对于目标检测的任务,只有核心主干的输出特征 { x K i , i = 2 , 3 , . . . , L } \left\{x_{K}^{i},i=2,3,...,L\right\} {xKi,i=2,3,...,L}会被送入到neck部分,然后是 RPN/检测头;而辅助主干的输出会被传给其后续的兄弟网络。值得注意的是, B 1 , B 2 , . . . , B K − 1 B_1,B_2,...,B_{K-1} B1,B2,...,BK−1可以使用不同形式的主干网络架构(例如:ResNet【13_ResNet】、ResNeXt【 14_ResNeXt】、Res2Net【15_Res2Net】和SwinTransformer【19_SwinTransformer】),并从单个主干的预训练权重中直接初始化。
3.2 可能的复合形式
对于复合连接 g l ( x ) g^l(x) gl(x),接收来自辅助主干 x = { x i ∣ i = 1 , 2 , . . . , L } \boldsymbol{x}=\left \{x^i \left|i=1,2,...,L\right.\right\} x={xi∣i=1,2,...,L}作为输入,然后输出一个与 x l x^l xl(简化起见省略 k k k)相同大小的特征,本文提出了下列五种不同的复合形式。
3.2.1 同级合成(Same Level Composition, SLC)
一种直观而且简单的合成方式就是将主干中来自同一stage的输出特征融合在一起。如图2.a所示,SLC(Same Level Composition)操作可以用如下公式表示:
![]()
其中, w \mathbf{w} w表示 1 × 1 1\times1 1×1卷积层和一个BN层。
3.2.2 邻接升级合成(Adjacent Higher-Level Composition, AHLC)
受到特征金字塔网络(Feature Pyramid Networks)[21_FPN]的启发,top-down pathway空间上更粗糙、但语义更强的高层特征,来增强 bottom-up pathway的浅层特征。在之前的CBNetV1【1_CBNetv1】中,使用AHLC(Adjacent Higher-Level Composition),将前一个主干的相邻高一级stage的输出送到后一个主干中去(如图2.b中从左至右):
![]()
其中, U ( ⋅ ) \mathbf{U}(\cdot) U(⋅)表示上采样操作。
3.2.2 邻接降级合成(Adjacent Lower-Level Composition, ALLC)
与AHLC不同,这里引入了一种自下而上的路径将前一个主干相邻低一级stage的输出送入到下一个主干中去。这种ALLC(Adjacent Lower-Level Composition)的操作如图2.c所示,其公式为:
![]()
其中, D ( ⋅ ) \mathbf{D}(\cdot) D(⋅)表示下采样操作。
3.2.4 密集升级合成(Dense Higher-Level Composition, DHLC)
在DenseNet【38_DenseNet】中,每个layer会和之后所有的layers连接,以构建综合性的特征。受此启发,本文也在CBNetV2架构中使用了密集合成连接。DHLC的计算表达式如下:

如图2.d所示,当 K = 2 K=2 K=2时,模型会合成前一个主干中所有更高层stages的特征,并将它们加到后一个主干的低层stages上。
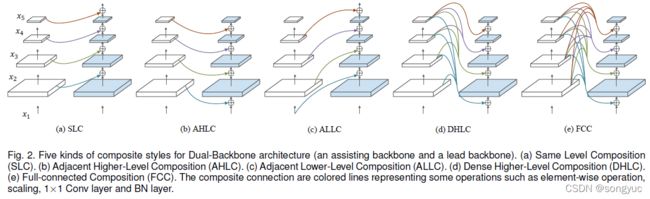
3.2.5 全连接合成(Full-connected Composition, FCC)
如图2.e所示,本文将前一个主干所有stages的特征合成起来输入到下一个主干的每一个stage中。与DHLC相比,FCC在low-high-level情况下将连接相加。FCC的计算表达式如下:
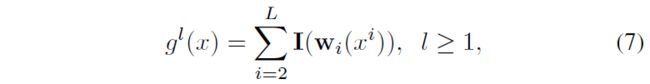
其中, I ( ⋅ ) \mathbf{I}(\cdot) I(⋅)表示尺度缩放,当 i > l i>l i>l时 I ( ⋅ ) = D ( ⋅ ) \mathbf{I}(\cdot)=\mathbf{D}(\cdot) I(⋅)=D(⋅)(下采样);当 i < l i
3.3 辅助监督
尽管提升网络深度常常会带来性能提升【13_ResNet】,它也会引入附加的优化难题,就像在图像分类任务中出现的情况【41_Relay_Backpropagation】。[42_GoogLeNet, 43_InceptionV3]引入中间层的辅助分类器来加快深度网络的收敛。在原始的CBNetV1中,尽管合成主干是并行的,后一主干(例如图4.a中的核心主干)通过与前一主干(例如图4.a中的辅助主干)的邻接连接加深了网络。
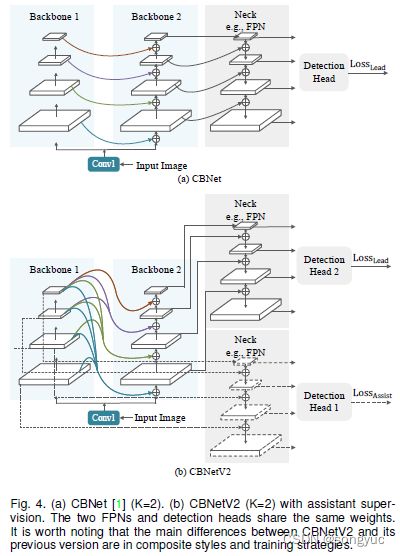
为了更好地训练基于CBNet的检测器,本文提出,使用辅助neck和检测头来生成辅助主干的初始结果,以提供额外的regularization。
本文监督训练CBNetV2的一个示例如图4.b所示,其中 K = 2 K=2 K=2。除了原始loss使用核心主干的特征来训练检测头1,其它的检测头2接受辅助主干的特征作为输入,产生辅助监督(assistant supervision)。注意检测头1和检测头2是权重共享的,就像两个necks一样。辅助监督有助于优化学习过程,同时核心主干对应的原始loss起最重要的作用。本文在损失函数中加入权值来平衡辅助监督,这里整个loss被定义为
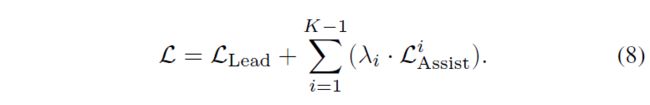
其中, L Lead \mathcal{L}_{\text {Lead}} LLead表示核心主干的损失, L Assist \mathcal{L}_{\text {Assist}} LAssist表示辅助主干的损失,以及 λ i \lambda_i λi表示第 i i i个辅助主干的损失权重。
在CBNetV2的推理阶段,本文停用了辅助监督分支而只使用核心主干的输出特征(图4.b)。
因此,辅助监督不会影响推理速度。
3.4 CBNetV2的剪枝策略
为了降低CBNetV2模型的复杂度,本文探究了在第 2 、 3 、 … … 、 K 2、3、……、K 2、3、……、K个主干上裁剪不同stages数量的可能性,而不是以一个整体合成这些主干(例如:将相同的主干添加到原来的主干上)。为了简化图示,本文在图5中展示当 K = 2 K=2 K=2时的情况。
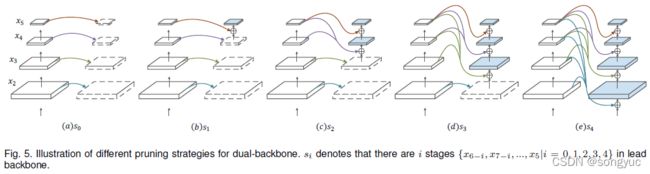
这里有五种对核心主干进行剪枝的方式。 s i s_i si表示在核心主干中有 i i i个stages( { x 6 − i , x 7 − i , . . . , x 5 ∣ i = 0 , 1 , 2 , 3 , 4 } \{x_{6-i}, x_{7-i},...,x_{5}|i=0,1,2,3,4\} {x6−i,x7−i,...,x5∣i=0,1,2,3,4}),之后被裁剪的stages会用第一个主干相同stages的特征来填充。细节部分请参见章节4.4.4。
3.5 使用CBNetV2的检测网络架构
CBNetV2可以被用于多种现成的检测器,且不需要对网络架构进行额外修改。在实践中,本文将核心主干连接到功能性网络上,例如:FPN[21_FPN]和检测head。用于目标检测时CBNetV2的推理流程如图1所示。
4 实验
本章通过广泛实验评测了本文所提出的方法。