pytorch计算特定层的激活图和梯度,实现gradcam
这个方法不受模型的限制,自己训练好的模型都可以用它来获取cam热力图
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import models
from skimage.io import imread
from skimage.transform import resize
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = pretrainedmodels.resnet18(num_classes=1000, pretrained=None)
self.linear1 = nn.Linear(1000, 128)
self.linear2 = nn.Linear(128, classes)
self.ReLU = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.model1(x)
x2 = self.ReLU(x1)
x3 = self.linear1(x1)
x4 = self.ReLU(x3)
x5 = self.linear2(x3)
return x5
model = Net()
#for name, param in model.named_parameters():
# if param.requires_grad:
# print(name)
model = nn.DataParallel(model,device_ids = [0])
#model.to(device)
#加载模型的参数
model_path = '/mnt/code2022/MODEL/20.pt'
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
class GradCamModel(nn.Module):
def __init__(self):
super().__init__()
self.gradients = None
self.tensorhook = []
self.layerhook = []
self.selected_out = None
#PRETRAINED MODEL
self.pretrained = model
self.layerhook.append(self.pretrained.module.model1.layer4.register_forward_hook(self.forward_hook()))
for p in self.pretrained.parameters():
p.requires_grad = True
def activations_hook(self,grad):
self.gradients = grad
def get_act_grads(self):
return self.gradients
def forward_hook(self):
def hook(module, inp, out):
self.selected_out = out
self.tensorhook.append(out.register_hook(self.activations_hook))
return hook
def forward(self,x):
out = self.pretrained(x)
return out, self.selected_out
gcmodel = GradCamModel().to('cuda:0')
####读取图片####
c_path = '/mnt/cifar10/train/6/1.png'
img = imread(c_path) #'bulbul.jpg'
img = resize(img, (224,224), preserve_range = True)
img = np.expand_dims(img.transpose((2,0,1)),0)
img /= 255.0
mean = np.array([0.485, 0.456, 0.406]).reshape((1,3,1,1))
std = np.array([0.229, 0.224, 0.225]).reshape((1,3,1,1))
img = (img-mean)/std
inpimg = torch.from_numpy(img).to('cuda:0', torch.float32)
####计算输出和激活图#####
out, acts = gcmodel(inpimg)
acts = acts.detach().cpu()
print(acts.size())
loss = nn.CrossEntropyLoss()(out,torch.from_numpy(np.array([600])).to('cuda:0'))
loss.backward()
grads = gcmodel.get_act_grads().detach().cpu()
print(grads.size())
pooled_grads = torch.mean(grads, dim=[0,2,3]).detach().cpu()
print(pooled_grads.size())
for i in range(acts.shape[1]):
acts[:,i,:,:] += pooled_grads[i]
heatmap_j = torch.mean(acts, dim = 1).squeeze()
heatmap_j_max = heatmap_j.max(axis = 0)[0]
heatmap_j /= heatmap_j_max
print(heatmap_j.size())
heatmap_j = resize(heatmap_j,(224,224))
cmap = mpl.cm.get_cmap('jet',256)
heatmap_j2 = cmap(heatmap_j,alpha = 0.2)
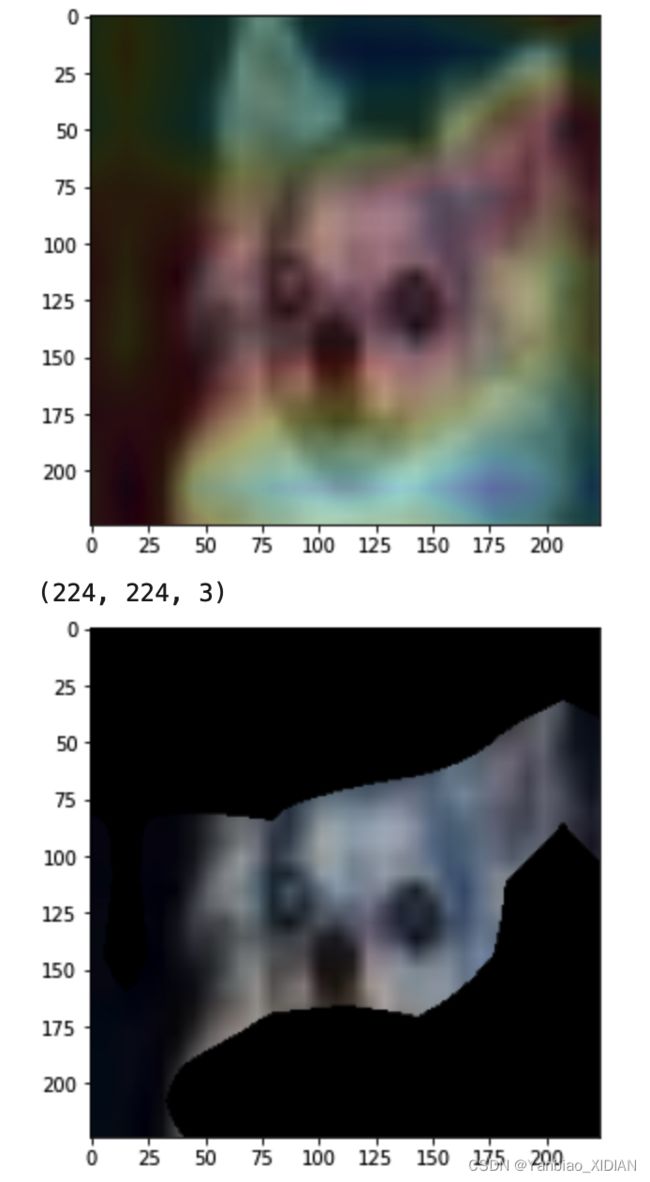
fig, axs = plt.subplots(1,1,figsize = (5,5))
axs.imshow((img*std+mean)[0].transpose(1,2,0))
axs.imshow(heatmap_j2)
plt.show()
heatmap_j3 = (heatmap_j > 0.75)
fig, axs = plt.subplots(1,1,figsize = (5,5))
print(((img*std+mean)[0].transpose(1,2,0)).shape)
hot = ((img*std+mean)[0].transpose(1,2,0))
hot[:,:,0] = hot[:,:,0]*heatmap_j3
hot[:,:,1] = hot[:,:,1]*heatmap_j3
hot[:,:,2] = hot[:,:,2]*heatmap_j3
axs.imshow(hot)
plt.show()