机器学习-强化学习-深度学习
例:小人学走路-使用matlab深度强化学习
目的:使一个3关节(髋骨、膝盖、脚踝)小人学会沿直线走路。
方法:1、对于小人建模;2、使用3层人工神经网络训练小人走路;3、对于每次训练结果评估,奖惩神经网络调整权重。
演示了一个使用深度强化学习(deep deterministicpolicy Gradient,DDPG)算法控制仿人机器人运动的例子。采用Simscape多体系统对机器人进行了仿真™在训练过程中,控制策略是使用强化学习工具箱完成的。
在本视频中,概述Simulink模型强化学习的设置、培训和评估。首先,他介绍了如何为强化学习问题选择状态、动作和奖励函数。然后介绍了神经网络的结构和训练算法参数。最后,展示训练结果,并讨论了强化学习的优缺点。


environment:三轴机器人的行走,并作为神经网络的奖惩;
神经网络:输入当前人的足迹坐标,输出三轴转矩;

如何训练神经网络:除了实际控制人前进的神经网络“actor”,还有一个修正神经网络“critic”,用来估计“actor”网络的正确性并评价,给出奖励。

仿真环境matlab2019a,‘walking robot’模拟3D小人,'RL agent'为两个神经网络。

'calculate reward'功能框内部结构
使用m文件创建神经网络。
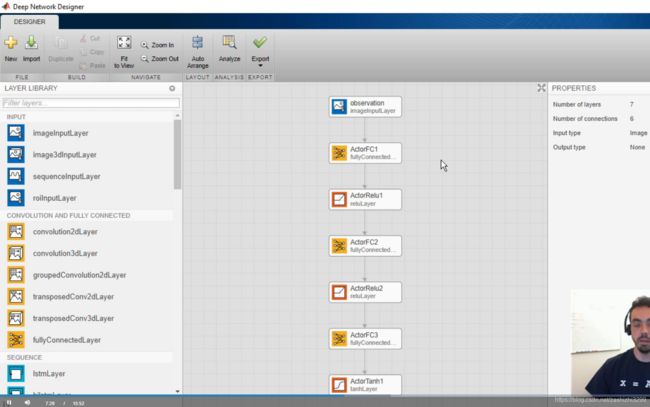
除了自己写m文件创建神经网络的方法,还以用图形界面形式创建,比如‘actor network’动作神经网络,用apps‘deep network designer’打开,自己创建的神经网络模型

开始仿真,训练神经网络,使小人自己学会沿直线走路。三个观察奖惩参数,蓝色点表示每次训练得到的奖惩,红色点表示平均奖惩(当红色线平稳表示奖惩平稳意味着小人走路平稳),绿色点表示估计的初始值?
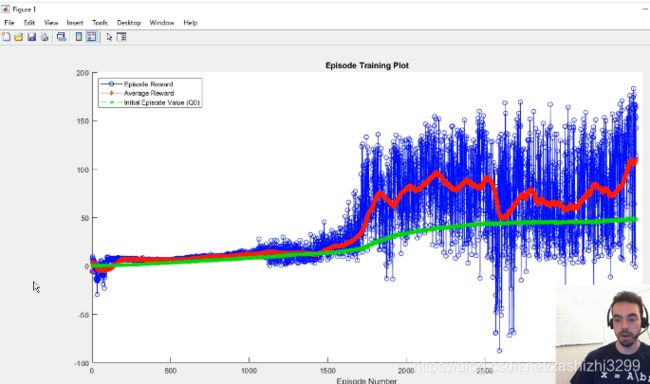
经过3500次训练后,小人学会走路。
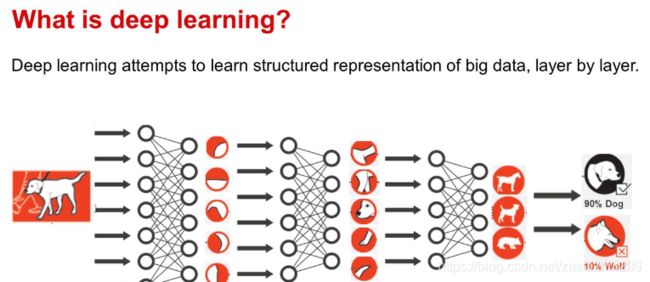
人工智能(包含)机器学习(包含)深度学习
人工智能:广义的使机器模拟人的行为
机器学习:机器从人类输入的经验数据中训练
深度学习:机器自我训练

发展历史:
控制论→人工神经网络→深度学习

更多的精准数据、GPU的计算能力提高、更复杂的神经网络,促进深度学习发展

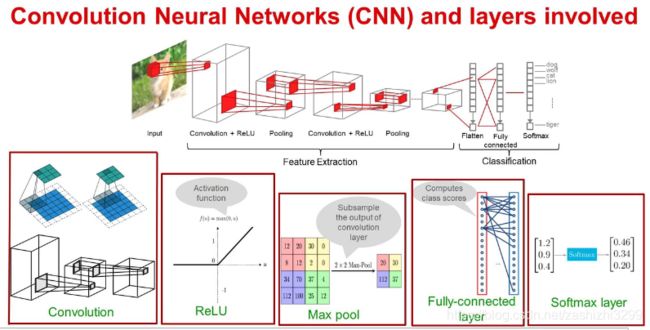
卷积神经网络CNN(Convolutional Neural Networks)
是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)”。
对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络 ;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求 。
学习工具和平台软件等
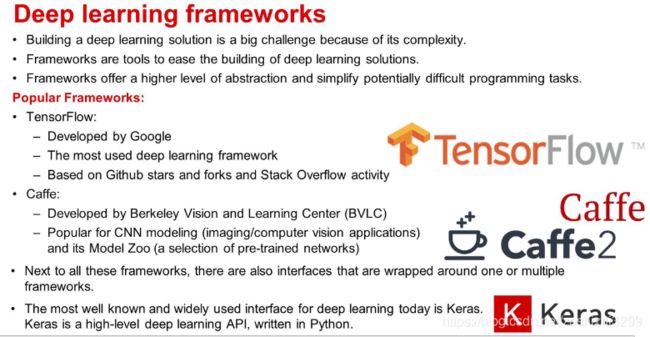
学习一般步骤
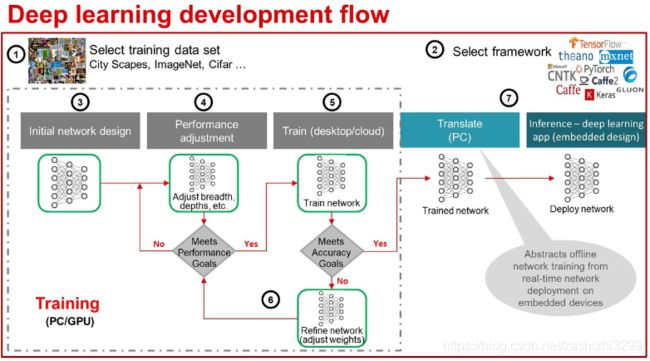
2种深度神经网络

CNN各层
深度学习的应用
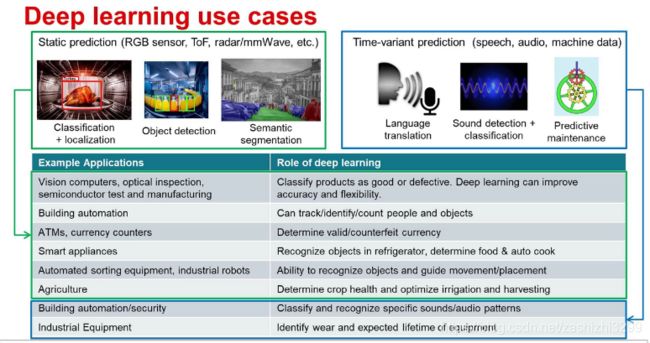
深度学习CNN/RNN在计算机视觉中的应用
历史
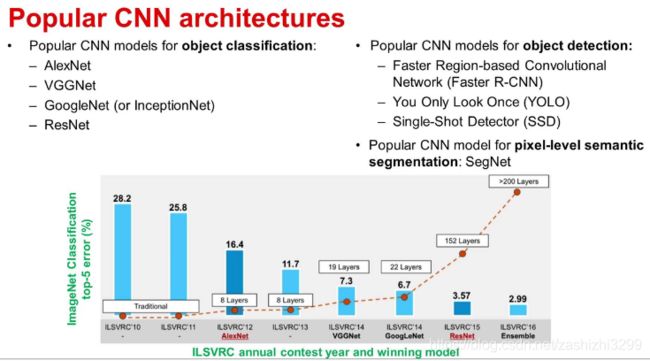
- AlexNet应该算第一个深度CNN;
- ZFNet采用DeconvNet和visualization技术可以监控学习过程;
- VGGNet采用小滤波器3X3去取代大滤波器5X5和7X7而降低计算复杂度;
- GoogleNet推广NIN的思路定义Inception基本模块(采用多尺度变换和不同大小滤波器组合,即1X1,3X3,5X5)构建模型;
- Highway Networks借鉴了RNN里面LSTM的gaiting单元;
- ResNet是革命性的工作,借鉴了Highway Networks的skip connection想法,可以训练大深度的模型提升性能,计算复杂度变小;
- Inception-V3/4用1X7和1X5取代大滤波器5X5和7X7,1X1滤波器做之前的特征瓶颈,这样卷积操作变成像跨通道(cross channel)的相关操作;
- DenseNet主要通过跨层链接解决vanishing gradient问题;
- SE-Net是针对特征选择的设计,gating机制还是被采用;
- Attention机制也是借鉴于LSTM,实现object-aware的context模型。
在具体应用领域也出现了不少成功的模型,比如
- detection问题的R-CNN,fast RCNN,faster RCNN,SSD,YOLO,RetinaNet,CornerNet
- segmentation问题的FCN,DeepLab,Parsenet,Segnet,Mask R-CNN,RefineNet,PSPNet,U-Net
- 处理激光雷达点云数据的VoxelNet,PointNet,BirdNet,LMNet,RT3D,PIXOR,YOLO3D
- 实现激光雷达和图像融合的PointFusion,RoarNet,PointRCNN,AVOD
- 做图像处理的DeHazeNet,SRCNN (super-resolution),DeepContour,DeepEdge
- 2.5 D视觉的MatchNet,DeepFlow,FlowNet
- 3-D重建的PoseNet,VINet,Perspective Transformer Net,SfMNet,CNN-SLAM,SurfaceNet,3D-R2N2,MVSNet
- 模型压缩精简的MobileNet,ShuffleNet,EffNet,SqueezeNet
图像/视频处理:
- 去噪/去雾/去模糊/去鬼影:encoder-decoder network的AR-CNN模型
- 增强/超分辨率(SR):Bilateral filter是很有名的图像滤波器
- 修补/恢复/着色:用于修补的基于GAN思想的Encoder-Decoder Network模型:
计算机视觉预处理2-D:计算机视觉需要图像预处理,比如特征提取,包括特征点,边缘和轮廓之类。特征点以前成功的就是SIFT/SURF/FAST之类,现在完全可以通过CNN形成的特征图来定义。边缘和轮廓的提取是一个非常tricky的工作,细节也许就会被过强的图像线条掩盖,纹理(texture)本身就是一种很弱的边缘分布模式,分级(hierarchical)表示是常用的方法,俗称尺度空间(scale space)。以前做移动端的视觉平台,有时候不得不把一些图像处理功能关掉,原因是造成了特征畸变。现在CNN这种天然的特征描述机制,给图像预处理提供了不错的工具,它能将图像处理和视觉预处理合二为一。
2.5-D计算机视觉部分(不是全3-D)。涉及到视差或者2-D运动的部分一般称为2.5-D空间。这个部分和前面的2-D问题是一样的,作为重建任务它也是逆问题,需要约束条件求解优化解,比如TV,GraphCut。一段时间(特别是Marr时代)计算机视觉的工作,就是解决约束条件下的优化问题。后来,随机概率和贝叶斯估计大行其事,约束条件变成了先验知识(prior)。像SVM, Boosting,Graphical Model,Random Forest,BP(Belief Propagation),CRF(Conditional Random Field),Mixture of Gaussians,MCMC,Sparse Coding都曾经是计算机视觉的宠儿,现在轮到CNN。可以说深度学习是相当“暴力”的,约束、先验知识统统扔一边,只要有图像数据就可以。
- 运动/光流估计:传统的方法包括局部法和全局法,这里CNN取代的就是全局法。
- 视差/深度图估计:深度图估计和运动估计是类似问题,唯一不同的是单目可以估计深度图,而运动不行。
- 视频去隔行/内插帧:Deinterlacing和Framerate upconversion视频处理的经典问题。基本传统方法都是采用运动估计和补偿的方法,俗称MEMC,所以归类为2.5-D。前面运动估计已经用深度学习求解了,现在这两个问题自然也是。
- 新视角图像生成:刚才介绍单目估计深度图的时候,其实已经看到采用inverse warping方法做新视角生成的例子,在IBR领域这里有一个分支叫Depth Image-based Rendering (DIBR)。和上个问题类似,采用深度图学习做合成图像,也属于2.5-D空间。在电视领域,曾经在3-D电视界采用这种方法自动从单镜头视频生成立体镜头节目。以前也用过机器学习,YouTube当年采用image search方法做深度图预测提供2D-3D的内容服务,但性能不好。
3-D,基于多视角(MVS)/运动(SFM)的重建,后者也叫SLAM。
这部分就是经典的计算机视觉问题:3-D重建。基本上可以分成两种路径:一是多视角重建,二是运动重建。多视角重建经典的方法MVS(multiple view stereo),就是多帧匹配,是双目匹配的推广,采用CNN来解决也合理。运动重建在机器人领域为SLAM,有滤波法和关键帧法两种,后者精度高,在稀疏特征点的基础上可以采用BA(Bundle Adjustment),著名的方法如PTAM,ORB-SLAM1/2,LSD-SLAM,KinectFusion(RGB-D),LOAM和Velodyne SLAM(LiDAR)等。如今SLAM已经成为AR产业的瓶颈。特征点匹配,帧间运动估计,Loop Closure检测这些模块都可以采用CNN模型解决,那么SLAM/SFM/VO就进入CNN的探索区域。
- 标定:Calibration是计算机视觉的经典问题,摄像头作为传感器的视觉系统首要任务就是要确定自己观测数据和3-D世界坐标系的关系,即标定。摄像头标定要确定内参和外参。对于有多个传感器的视觉系统,比如深度测距仪,以前有Kinect RGB-D,现在有Velodyne激光雷达,它们相互之间的坐标系关系是标定的任务。外参数标定的完成帮助是校准数据,比如激光雷达的点云,RGB-D的深度图,还有摄像头的图像像素集,它们一定存在一个最佳匹配标准,这就可以通过数据训练NN模型来完成。而标定参数就是NN模型回归输出的结果。
- Visual Odometry(VO):VO视觉里程计属于SLAM的一部分,估计自身运动和姿态变化。VO是特斯拉的前Autopilot2.0负责人David Nister创立的,他之前以两帧图像计算Essential Matrix的“5点算法”而出名。
- SLAM (Mono, Stereo, RGB-D, LiDAR)/SFM:运动恢复结构是基于背景不动的前提,计算机视觉的同行喜欢SFM这个术语,而机器人敛域称之为SLAM。SLAM比较看重工程化的解决方案,SFM理论上贡献大。
- MVS:多视角重建经典的方法MVS(multiple view stereo)的传统方法可以分成两种:region growing和depth-fusion,前者有著名的PMVS,后者有KinectFusion,CNN模型求解MVS的方法就是基于此。
计算机视觉的高层:环境理解。
这部分是深度学习在计算机视觉最先触及,并展示强大实力的部分。
- 语义分割/实例分割(Semantic/Instance Segmentation):语义分割最早成功应用CNN的模型应该是FCN(Fully Convolution Network),由Berkeley分校的研究人员提出。它是一种pixel2pixel的学习方法,之后各种演变模型,现在都可以把它们归类于Encoder-Decoder Network。实例分割是特殊的语义分割,结合了目标检测,可以说是带有明确轮廓的目标检测,其代表作就是Mask R-CNN,何凯明。
- 检测/识别(特别例子:人脸):目标检测的开拓性工作应该是Berkeley分校Malik组出来的,即两步法的R-CNN(Region-based CNN),借用了传统方法中的Region Proposal。之后不断改进的有fast RCNN和faster RCNN。一步法的工作,有名的就是SSD(Single Shot Detection)和YOLO(You Only Look Once),期间何凯明针对one-stage和two-stage方法的各自优缺点引进一个Focal Loss,构建的新方法叫RetinaNet,而后来YOLO3基本也解决了精度低的弱点。ImageNet本身就是一个1000多种物体识别比赛,一般公布的是top 5的结果,最早精度低。CNN在ImageNet的发展史,就是它在图像识别的一段近5年的历史了。人脸识别,因为是对人脸的个体属性判别,所以这个课题应该算fine grained recognition。就好像对狗或者马这种动物继续判别它的品种,都是细分的。人脸识别分人脸验证(face verification)和人脸确认(face identification):前者是指两个人是不是同一个人,1-to-1 mapping,而后者是确定一个人是一群人中的某个,1-to-many ampping。以前经常有报道机器的人脸识别比人强了,都是指前者,假如后者的话,那谁能像机器一样识别上万人的人脸数据库呢?一个完整的人脸识别系统,需要完成人脸检测和人脸校准(face alignment),而后者是需要人脸关键点(facial landmarks)的检测,也可以基于CNN模型来做。
- 跟踪(特别例子:人体姿态/骨架):目标跟踪是一个递推估计问题,根据以前的图像帧目标的信息推算当前目标的位置甚至大小/姿态。有一阵子,跟踪和检测变得浑为一体,即所谓tracking by detection,跟踪也可以看出一个目标分割(前后景而言)/识别问题。跟踪是短时(short term)邻域的检测,而一般的检测是长时(long term)大范围的检测。跟踪的困难在于目标的遮挡(分部分还是全部),背景复杂(相似目标存在),快速(fast)以及突变(agile)运动等等。比如,跟踪人脸,当转90度成侧脸时就会有以上这些问题。跟踪方法有一个需要区分的点,多目标还是单目标跟踪器。单目标不会考虑目标之间的干扰和耦合,而多目标跟踪会考虑目标的出现,消失以及相互交互和制约,保证跟踪各个目标的唯一性是算法设计的前提。跟踪目标是多样的,一般是考虑刚体还是柔体,是考虑单刚体还是铰接式(articulated),比如人体或者手指运动,需要确定skeleton模型。跟踪可以是基于图像的,或者激光雷达点云的,前者还要考虑目标在图像中大小的变化,姿态的变化,难度更大。基于以上特点,跟踪可以用CNN或者RNN模型求解,跟踪目标的描述本身就是NN模型的优势,检测也罢,分割或者识别也罢,都不是问题。运动特性的描述也可以借鉴RNN模型,不过目前看到的结果这部分不比传统方法好多少。
深度学习平台
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算。TensorFlow由谷歌开发和维护,拥有多个项目以及各类API。2015年开源。支持C和python。
几种流行的深度学习框架,例如TensorFlow,PyTorch,MXNet和CNTK。 尽管这些框架的优缺点还要取决于设计,互操作性可以减少重复的模型训练工作。
市面上已经有不少公司开发出各种深度学习硬件平台,比如Google TPU,Hisilicon NPU和Apple的Bonic,处理器供应商NVIDIA Turing和Intel NNP,服务提供商Amazon Inferentia和阿里巴巴的含光,甚至是创业公司的Cambricon和Graphcore。一般这些硬件可分为以下几类:1)具有软硬件协同设计的通用硬件; 2)完全为深度学习模型定制的专用硬件;3)受生物脑科学启发的类神经硬件。 举个例子,在通用硬件(CPU/GPU)添加特殊硬件组件以加速DL模型,如AVX512矢量单元和张量核。 Google TPU之类的专用硬件,设计专用集成电路(例如矩阵乘法引擎和高带宽内存)将性能和功耗效率提升到了极致。 在可预见的将来,深度学习硬件的设计将变得更加多样化。
由于硬件多样性,重要的工作就是如何将计算有效地映射。通用硬件对高度优化的线性代数库,例如BLAS库(MKL和cuBLAS)依赖比较多。以卷积运算为例,深度学习框架将卷积转换为矩阵乘法,然后在BLAS库中调用GEMM函数。此外,硬件供应商还发布了特别的优化库(例如MKL-DNN和cuDNN),包括正向和反向卷积、池化、规范化和激活等操作符。他们还开发了更高级的工具来进一步加快深度学习操作。例如,TensorRT支持图形优化(层融合)和基于大量优化GPU内核的低比特量化。专用硬件,则会提供类似的开发库。但是,过于依赖库无法有效利用深度学习芯片。
为解决这些依赖库和工具的缺点,减轻手动优化每个硬件运行模型的负担,深度学习社区诉诸于专门的编译器。已经有几种流行的编译器出现,例如TVM,Tensor Comprehension,Glow,nGraph和Tensorflow XLA(Accelerated Linear Algebra)。 编译器将深度学习框架描述的模型在各种硬件平台上生成有效的代码实现,其完成的模型定义到特定代码实现的转换将针对模型规范和硬件体系结构高度优化。具体来说,它们结合了面向深度学习的优化,例如层融合和操作符融合,实现高效的代码生成。此外,现有的编译器还采用了来自通用编译器(例如LLVM)的成熟工具链,对各种硬件体系结构提供了更好的可移植性。与传统编译器类似,深度学习编译器也采用分层设计,包括前端、中间表示(IR)和后端。但是,这种编译器的独特之处在于多级IR和特定深度学习模型实现优化的设计。深度学习编译器普遍采用的设计架构如图所示:

参考文献:
[1] Deep Reinforcement Learning for Walking Robots Video - MATLAB & Simulink https://ww2.mathworks.cn/videos/deep-reinforcement-learning-for-walking-robots--1551449152203.html
[2]【2019-2020完整合集】【官方】 MATLAB & Simulink 小迈步系列课程 人工智能/深度学习/系统仿真/行业规范 https://www.bilibili.com/medialist/play/ml1238052723/BV1xf4y1i73L?s_eid=PEP_webinarfromILM ![]()
[3] 深度学习在计算机视觉领域(包括图像,视频,3-D点云,深度图)的应用一览 - 知乎 https://zhuanlan.zhihu.com/p/55747295
[4] 神经网络深度学习简介 - 神经网络深度学习简介 http://edu.21ic.com/m/video/3408.html
[5] 基于Jacinto™TDA2x SoC和深度学习的实时mmWave和相机传感器融合系统设计 http://edu.21ic.com/m/video/3402.html
6、深度学习在计算机视觉领域(包括图像,视频,3-D点云,深度图)的应用一览 - 知乎 https://zhuanlan.zhihu.com/p/55747295
7、一篇关于深度学习编译器架构的综述论文 - 知乎 https://zhuanlan.zhihu.com/p/139552817
8、
9、
10、
11、
12、
13、
14、