记录:复现Pytorch搭建YoloV4Tiny目标检测平台
站在各位巨人的肩膀上,记录和整理。
参考:
1、https://github.com/bubbliiiing/yolov4-tiny-pytorch
2、睿智目标检测35——Pytorch搭建YoloV4-Tiny目标检测平台
3、Pytorch 搭建自己的YoloV4目标检测平台(Bubbliiiing 深度学习 教程)
4、可视化yolov4-tiny和yolov4网络结构图
5、关于YOLOv3的一些细节
6、【论文理解】理解yolov3的anchor、置信度和类别概率
7、史上最详细的Yolov3边框预测分析
8、深度学习小技巧-mAP精度概念详解与计算绘制(Bubbliiiing 深度学习 教程)
9、YOLO3输出张量解码过程
10、睿智的目标检测10——先验框详解及其代码实现
11、睿智的目标检测31——非极大抑制NMS与Soft-NMS
一、结果
先把结果跑通,了解步骤以及训练流程。
1 预训练权重预测
给这位博主一个star吧,他值得,b站和csdn博客同名。
https://github.com/bubbliiiing/yolov4-tiny-pytorch
- 下载预训练权重(yolov4_tiny_weights_voc.pth和yolov4_tiny_weights_coco.pth)。
- 下载权重放置于model data文件夹下。
- 检查yolo.py中的model_path和classes_path路径是否正确,以及是否一一对应。
- 例如,如果使用coco预训练权重,相应代码应是如下所示:
-“model_path” : ‘model_data/yolov4_tiny_weights_coco.pth’
- “classes_path” : 'model_data/coco_classes.txt’ - 在img文件夹放置sample.jpg图片。
- 运行predict.py,输入img/sample.jpg,会显示预测结果。
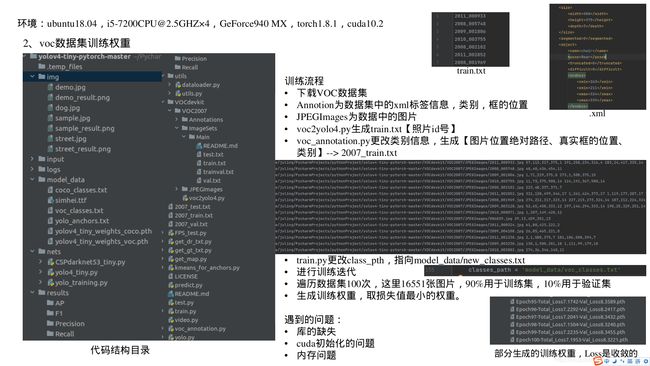
2 自己训练VOC数据集得到权重
需要知道:训练集和验证集的比例、各种txt的含义。
这里测试是用一张照片进行测试的,使用测试集进行批量测试会在MAP的绘制中介绍。
训练流程
- 下载训练集:VOC2007+2012训练集
链接: https://pan.baidu.com/s/16pemiBGd-P9q2j7dZKGDFA 提取码: eiw9 - VOC数据集格式
- Annotions(存放xml标签文件)
- ImageSets/Main(存放train.txt和trainval.txt)
- JPEGImages(存放数据集的照片) - 把下载好的VOC2007文件夹放入项目的VOCdevkit文件夹
- 运行VOC2007文件夹下的voc2yolo4.py,可以在ImageSets/Main得到4个txt文件
- 注意:voc2yolo4.py中设置trainval_percent=1,train_percent=1
- trainval_pecent=1表示该数据集所有照片用于训练和验证,至于划分训练和验证集的比例在train.py中会进行划分。train_percent不需要设置。
- 其中test.txt和val.txt是空的,训练不会用到。
- train.txt和trainval.txt中是数据集照片的id号。 - 运行项目根目录下的voc_annotation.py会生成2007_train.txt
- 运行之前,先检查代码中的classes列表,是不是对应voc的类别。
- 其中存放的信息:【图片位置绝对路径、真实框的位置、类别】 - 运行根目录下的train.py
- 运行之前首先检查其中的classes_path是否是model_data/voc_classes.txt
- 代码中的**model_path = “model_data/yolov4_tiny_weights_coco.pth”**我理解为在这个coco预训练权重的基础上进行训练的。
- val_split = 0.1即为数据集的90%用于训练,10%用于验证。 - 等待迭代100Epoch。
- 一个Epoch是遍历一次训练集,每迭代一次以后,会进行一次验证集的验证。
- 在log文件夹下会保存权值,好像是每个epoch保存2次,最后这个log文件夹里会有很多pth文件,取最后一个loss值最低的,代替之前的预训练权重进行预测。
- 每个pth文件20多M的样子,可以更改代码,少保存一些,减轻内存负担。
使用训练好的权重预测
- 检查yolo.py中的model_path和classes_path路径是否正确,以及是否一一对应。
相应代码应是如下所示:
-“model_path” : ‘log/Epoch100-Total_Loss7.1953-Val_Loss8.3221.pth’
- “classes_path” : 'model_data/voc_classes.txt’ - 在img文件夹放置sample.jpg图片。
- 运行predict.py,输入img/sample.jpg,会显示预测结果。

二、原理
跑通以后,了解算法原理。
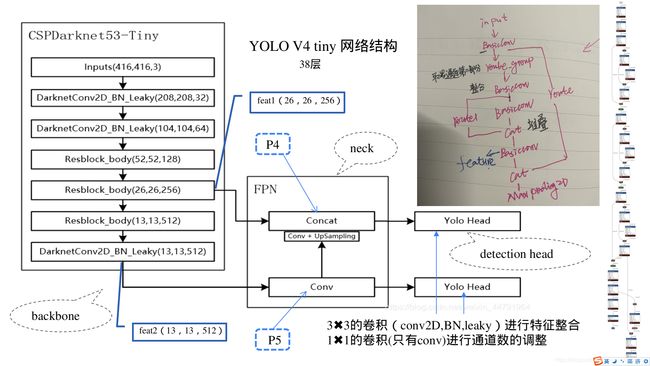
全部38层网络可视化:可视化yolov4-tiny和yolov4网络结构图
1 backbone
主干网络:CSPdarknet53 Tiny(用于特征提取)
具体的shape变化,请看代码注释。
- 照片输入尺寸:416×416×3
- 首先进行两次卷积【conv、bn、leakly relu】操作。
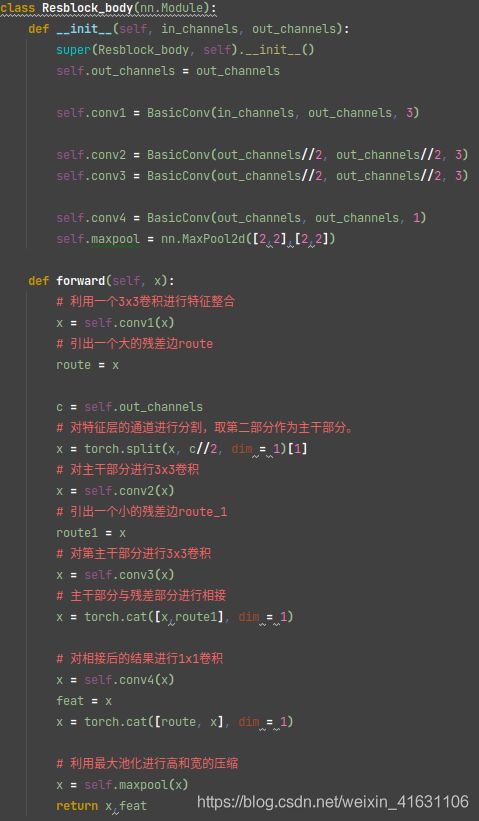
- 然后进行三次残差块(残差块中,池化会压缩图片宽和高,concat会使通道数翻倍)的操作。
- 再进行一次卷积【conv、bn、leakly relu】操作。
- 最后输出两个shape【feat2:(13,13,512)、feat1:(26,26,256)】,作为加强特征提取网络部分的输入。
CSPdarknet53 Tiny的2个特点
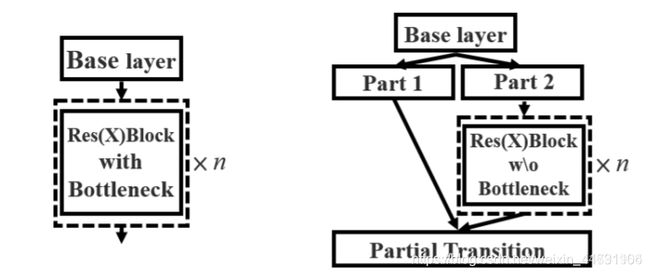
1、使用了CSPnet结构
- CSPnet就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分: 主干部分继续进行原来的残差块的堆叠;
- 另一部分则像一个残差边一样,经过少量处理直接连接到最后。 因此可以认为CSP中存在一个大的残差边。
2、进行通道的分割
- 在CSPnet的主干部分,CSPdarknet53_tiny会对一次3x3卷积后的特征层进行通道的划分,分成两部分,取第二部分。
- 利用主干特征提取网络,我们可以获得两个shape的有效特征层,即CSPdarknet53_tiny最后两个shape的有效特征层,传入加强特征提取网络当中进行FPN的构建。
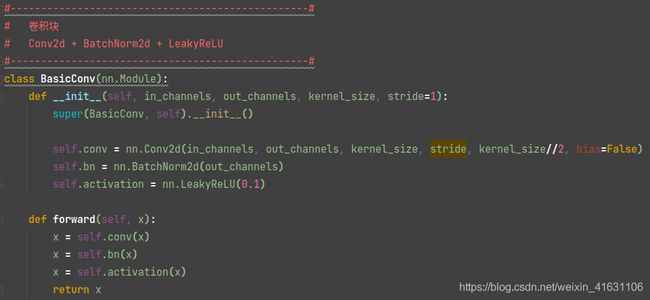
BasicConv对应结构图中的DarknetConv2D_BN_Leakly操作,包括卷积、批标准化、leakly激活函数。
通道输入为in_ch,通道输出为out_ch。
残差块结构:

残差块代码,残差块中,池化会压缩图片宽和高,concat会使通道数翻倍。
CSPdarknet53 tiny,可以验算一下shape是如何变化的。最后返回feat1和feat2的shape。

2 neck
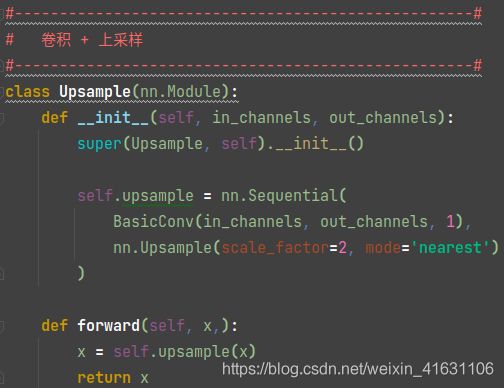
连接部分:FPN特征金字塔(用于特征融合)
FPN会将最后一个shape的有效特征层卷积后进行上采样,然后与上一个shape的有效特征层进行堆叠并卷积。
3 detection head
检测头:YOLO head(用于检测分类)
1、在特征利用部分,YoloV4-Tiny提取多特征层进行目标检测,一共提取两个特征层,两个特征层的shape分别为(26,26,256)、(13,13,512)。
2、输出层的shape分别为(13,13,75),(26,26,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,YoloV4-Tiny只有针对每一个特征层存在3个先验框,所以最后维度为3x25。
- 先验框:也叫anchor,后面介绍。
- 25的由来:x,y,w,h+confidence+num_classes即4+1+20=25,【框的位置参数,框的置信度,类别和】
yolo head包括一个3×3卷积(conv,BN,leakly)进行特征整合和一个普通1×1卷积(进行通道数的调整)
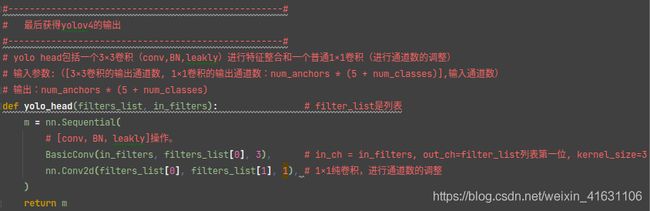
YoloBody包括FPN和yolo head两个部分。shape的变化写在如下注释中。


4 解码
yolo系列算法的核心思想:
- 对输入图片进行S*S的栅格化,图片中某个对象的中心点落在哪个cell中,那一个cell就负责预测这个对象。
- 最终输出维数: S * S * [B * (4 + 1 + num_classes)]
- yolo v1一个cell只能预测一个对象,如果有两个对象的中心点都落在同一个cell中,那么只能预测其中一个物体,针对这个物体,yolo v2以后的版本都加入了锚框这个概念,anchor的加入,可以有效解决这个问题。
- 比如有2个物体,有3个先验框。当有2个物体的中心都落在同一个cell中时,3个先验框中,与真实框的交并比(IOU)最大的那个先验框会负责预测第一个物体,与真实框的交并比(IOU)第二大的那个先验框会负责预测第二个物体,以此类推。
yolo v4 的tiny的特征层分别将整幅图分为13x13、26x26的网格,每个网格点负责一个区域的检测。
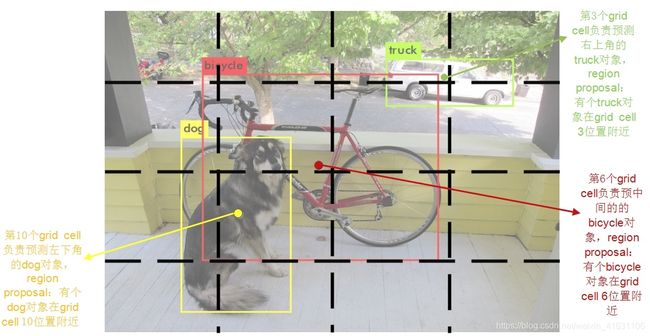
由yolo head我们可以获得两个特征层的预测结果,shape分别为(batch_size,13,13,75),(batch_size,26,26,75)的数据,对应每个图分为13x13、26x26的网格上3个预测框的位置【3*(4+1+20)=75】。但是这个预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。
特征层的预测结果对应着三个预测框的位置,先将其reshape一下,其结果为(N,13,13,3,25),(N,26,26,3,25)。
最后一个维度中的25包含了4+1+20,分别代表tx、ty、th和tw、置信度、分类结果。yolo的解码过程就是将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用先验框和h、w结合,计算出预测框的长和宽。这样就能得到整个预测框的位置。
当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选。
这一部分基本上是所有目标检测通用的部分。不过该项目的处理方式与其它项目不同。其对于每一个类进行判别。
1、取出每一类得分大于self.obj_threshold的框和得分。 2、利用框的位置和得分进行非极大抑制。
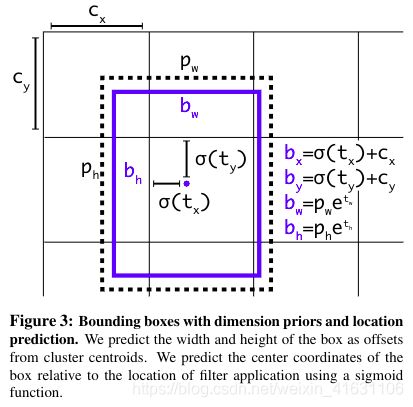
x偏移量:sigmoid(tx)、y偏移量:sigmoid(ty)。(Cx,Cy)为格子的左上角坐标。
Pw和Ph是先验框的宽度和高度。尺度缩放量:e^tw 和 e^th。
最终预测框的位置参数是bx,by,bw,bn,公式如上图。
步骤总结:原图尺寸4032×3024,输入尺寸为416×416
为了在特征图上确定预测框的大小和位置,将先验框缩小(416/13=32,416/26=16)倍。
在特征图上生成网格点,每个网格点的左上角坐标记为(grid_x,grid_y),根据输出张量确定预测框的位置和大小(4个公式)。
将预测框的x,y,w,h信息放大,放大(416/13=32、416/26=16)倍,然后在原图中显示。

代码实现
class DecodeBox(nn.Module):
def __init__(self, anchors, num_classes, img_size): # anchors维度是np.reshape(self.anchors,[-1,2])[self.anchors_mask[i]]
# anchors分为两列,索引是anchors_mask[i]
# num_classes是20,img_size维度是(416,416)
super(DecodeBox, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.img_size = img_size
def forward(self, input): # input = [1,75,26,26]或[1, 75, 13, 13]
#-----------------------------------------------#
# 输入的input一共有两个,他们的shape分别是
# batch_size, 75, 13, 13
# batch_size, 75, 26, 26
#-----------------------------------------------#
batch_size = input.size(0)
input_height = input.size(2)
input_width = input.size(3)
#-----------------------------------------------#
# 输入为416x416时,即img_size = 416×416
# stride_h = stride_w = 32、16、8
#-----------------------------------------------#
stride_h = self.img_size[1] / input_height # h需要缩小的倍数:416/13=32、416/26=16
stride_w = self.img_size[0] / input_width # w需要缩小的倍数:416/13=32、416/26=16
#-------------------------------------------------#
# 此时获得的scaled_anchors大小是相对于特征层的
#-------------------------------------------------#
scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors]
#-----------------------------------------------#
# 输入的input一共有两个,他们的shape分别是
# batch_size, 3, 13, 13, 25
# batch_size, 3, 26, 26, 25
#-----------------------------------------------#
prediction = input.view(batch_size, self.num_anchors,
self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous()
#print('prediction.shape:',prediction.shape) # prediction.shape: torch.Size([1, 3, 13, 13, 25])
# prediction.shape: torch.Size([1, 3, 26, 26, 25])
# 25 = 【tx,ty,tw,th,conf,pred_cls】
# 先验框的中心位置的调整参数
x = torch.sigmoid(prediction[..., 0]) # x = sigmoid(tx)
y = torch.sigmoid(prediction[..., 1]) # y = sigmoid(ty)
# 先验框的宽高调整参数
w = prediction[..., 2] # w = tw
h = prediction[..., 3] # h = th
# 获得置信度,是否有物体
conf = torch.sigmoid(prediction[..., 4]) # conf
# 种类置信度
pred_cls = torch.sigmoid(prediction[..., 5:]) # pred_cls
#print('pred_cls.shape:',pred_cls.shape) # pred_cls.shape: torch.Size([1, 3, 13, 13, 20])
# pred_cls.shape: torch.Size([1, 3, 26, 26, 20])
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
#print('FloatTensor:',FloatTensor) # FloatTensor: anchor box
参考:关于YOLOv3的一些细节
也叫先验框(bounding box prior)。从训练集的所有ground truth box中统计出来的(使用k-means统计的),在训练集中最经常出现的几个box的形状和尺寸。
置信度(confidence)
[0,1]区间的值![]()
- 一重是代表当前box是否有对象的概率Pr(Object),注意,是对象,不是某个类别的对象,也就是说它用来说明当前box内只是个背景(backgroud)还是有某个物体(对象);
- 另一重表示当前的box有对象时,它自己预测的box与物体真实的box可能的IOU的值,注意,这里所说的物体真实的box实际是不存在的,这只是模型表达自己框出了物体的自信程度。
- Cij表示第i个grid cell的第j个bounding box的置信度。
对象条件类别概率(conditional classes probabilities)
[0,1]区间的值

损失函数、得分排序、非极大值抑制(NMS)
为了计算loss,输出特征图需要变换为(batch_size, grid_sizegrid_sizenum_anchors, 5+类别数量)的tensor,这里的5就已经是通过之前详细阐述的边框预测公式转换完的结果,即bx,by,bw,bh.对于尺寸为416×416的图像,通过三个检测层检测后,有[(2626)+(1313)]*3=2535个预测框,然后可以转为x1,y1,x2,y2来算iou,通过score排序和执行NMS去掉绝大多数多余的框,计算loss等操作了。
5 原图绘制
通过第四步,我们可以获得预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
6 评价指标
6.1 速度指标FPS(Frame Per Second)
- 每秒内可以处理的图片数量。
- 对比FPS,需要在同一硬件上进行,不同硬件的FPS不同。
- 另外也可以使用处理一张图片所需时间来评估检测速度
运行predict.py以后,进行图片的检测,然后直接运行FPS_test.py
这里检测1张图片的时间为27ms左右,即每秒大约可以处理36张图片。

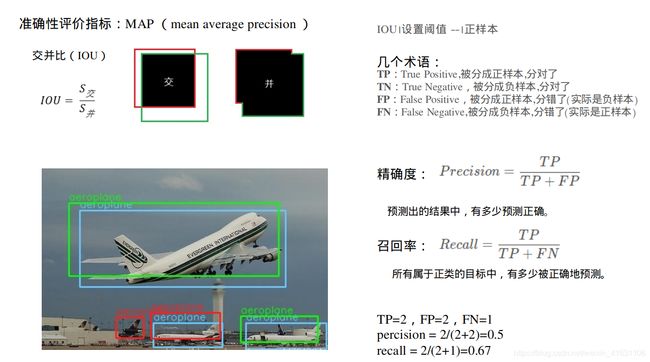
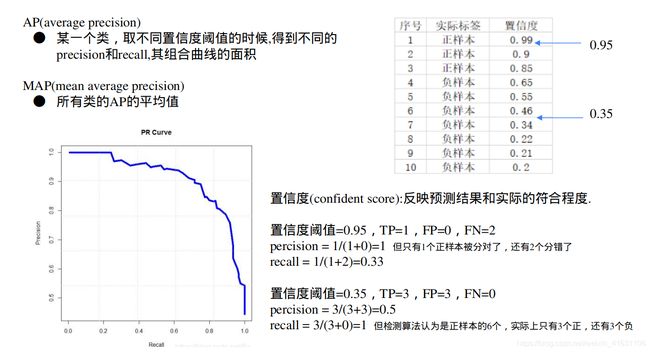
6.2 准确性指标MAP(Mean Average Precision )
6.2.1 MAP原理
参考:
深度学习小技巧-mAP精度概念详解与计算绘制(Bubbliiiing 深度学习 教程
睿智的目标检测20——利用mAP计算目标检测精确度
6.2.2 增加测试集,绘制MAP
1、下载测试集
VOC2007测试集:
链接: https://pan.baidu.com/s/1BnMiFwlNwIWG9gsd4jHLig 提取码: dsda
2、将测试集放到VOCdevkit文件夹下,并改名为VOCdevkit_test以示区分,注意改了名字,测试时代码路径就也要改成对应的。
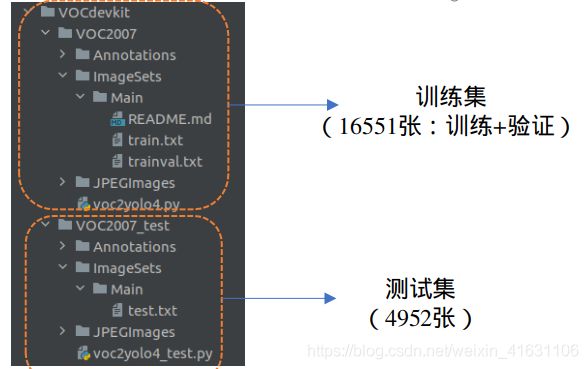
3、具体设置
- voc2yolo4_test.py中的trainval_percent改为0,表示当前的数据集全部用于测试。之后会生成test.txt,里面是存放测试集照片的id号。
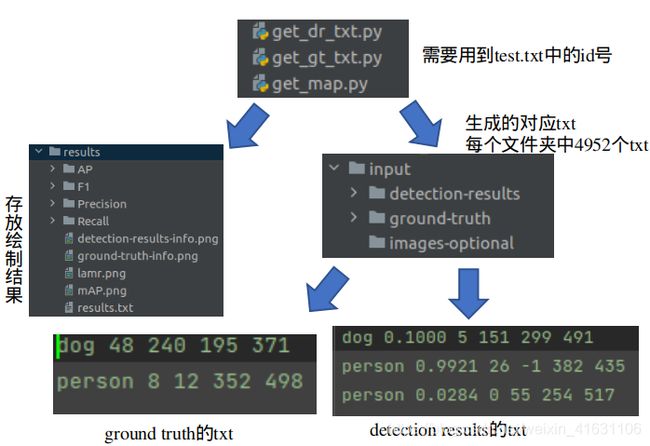
- 运行get_dr_txt.py,获得检测结果的txt
- 运行get_gt_txt.py,获得ground truth的txt
- 运行get_map.txt,获得result文件夹,内含MAP结果等。
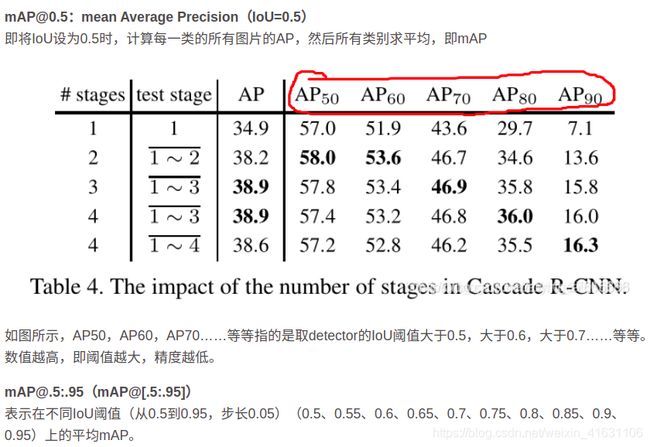
6.2.3 [email protected]的含义