【Presto源码学习】ResourceGroups调度策略
文章目录
-
- 简单介绍
- 调度策略生效的场景
-
- queuedQueries
- eligibleSubGroups
- Resource group创建
- 根据schedulingPolicy创建相应的调度队列
-
- fair
- weighted
- weighted_fair
-
- IndexedPriorityQueue队列
- WeightedFairQueue队列
- query_priority
-
- SET语句设置priority
- JDBC设置priority
- Group的priority计算
- 小结
简单介绍
Presto目前支持对resource group配置不同的调度策略,来实现不同类型的调度,参考官方的文档:Resource Groups,相关内容如下所示:

可以通过schedulingPolicy配置项来为每个resource group配置相应的调度策略。从截图中可以看到,这个调度策略生效的场景有两种:
- How queued queries are selected to run;
- How sub-groups become eligible to start their queries;
也就是说,图中的四种调度策略会对这两种场景生效。单从文档描述来看,我们很难理解各种调度策略的具体机制,所以本文将结合代码来详细看下这几种调度策略是如何对上述两种场景生效的,本文的代码分析都是基于presto的0.260版本进行分析和梳理。
调度策略生效的场景
对于某个具体的resource group,presto使用的是InternalResourceGroup这个类来表示(root group使用的是其子类RootInternalResourceGroup)。我们在上面提到的两种调度策略生效的场景,实际就是对应了两个调度队列,分别是eligibleSubGroups和queuedQueries,相关代码如下所示:
private Queue eligibleSubGroups = new FifoQueue<>();
private TieredQueue queuedQueries = new TieredQueue<>(FifoQueue::new);
接着,我们就分别看下这两种场景的处理逻辑。
queuedQueries
这里对应的就是上面的“How queued queries are selected to run”这个场景。顾名思义,queuedQueries就是用来保存排队的查询。当一个查询提交到presto集群之后,C节点会首选筛选一个符合条件的group(如果该group不存在,则创建新的group,这个我们后面再介绍),然后再使用group来执行这个查询。相关调用栈如下所示:
submit(InternalResourceGroupManager.java):151
-createGroupIfNecessary(InternalResourceGroupManager.java)
submit(InternalResourceGroupManager.java):152
-run(InternalResourceGroup.java):339
--enqueueQuery(InternalResourceGroup.java):339
在run方法中,会判断查询是否可以执行,如果不能执行、并且允许排队的话,则将该查询入队到queuedQueries中。从上面可以看到,queuedQueries是一个TieredQueue类型的队列,这是一个分层队列,内部包含两个子队列:
final class TieredQueue implements UpdateablePriorityQueue {
private final UpdateablePriorityQueue highPriorityQueue;
private final UpdateablePriorityQueue lowPriorityQueue;
public boolean addOrUpdate(E element, long priority) {
return lowPriorityQueue.addOrUpdate(element, priority);
}
public boolean prioritize(E element, long priority) {
return highPriorityQueue.addOrUpdate(element, priority);
}
当使用addOrUpdate方法时,将对应的查询保存到了低优队列;调用prioritize方法,则将查询提交到了高优队列。出队的时候,则直接将高优和低优队列连接起来,返回第一个队列成员,详细代码这里不再展示。在enqueueQuery方法中,会将重试的查询放到高优队列,将新的查询放到低优队列,如下所示:
//InternalResourceGroup.enqueueQuery()
int priority = getQueryPriority(query.getSession());
if (query.isRetry()) {
queuedQueries.prioritize(query, priority);
} else {
queuedQueries.addOrUpdate(query, priority);
}
目前presto支持对某些特定错误的查询进行重试,具体可以参考QUERY_RETRY_LIMIT这个session属性,这里不再展开。
所以说,queuedQueries保存的就是提交到当前group上,由于资源、并发等限制,无法直接执行的查询。
eligibleSubGroups
这里对应的就是“How sub-groups become eligible to start their queries”这个场景。eligibleSubGroups是一个普通的Queue队列,保存的是这个group下所有eligible的sub-groups。这里我们通过一个典型的例子来理解下什么是eligible的group,简单画了一个流程图:
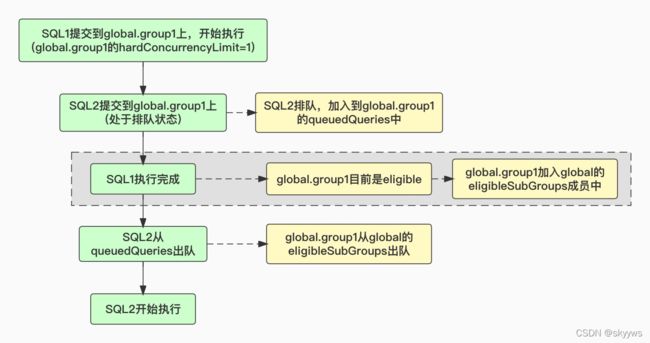
灰色虚线框的部分就是典型的获取eligible的sub-group的场景,相关的代码调用如下所示:
queryFinished(InternalResourceGroup.java):797
-updateEligibility(InternalResourceGroup.java):735
--isEligibleToStartNext(InternalResourceGroup.java)
-updateEligibility(InternalResourceGroup.java):736
--addOrUpdateSubGroup(InternalResourceGroup.java):898
---addOrUpdateSubGroup(InternalResourceGroup.java)
这里,isEligibleToStartNext()方法就是用来判断当前的这个group是否是eligible,我们看下其代码:
private boolean isEligibleToStartNext() {
synchronized (root) {
if (!canRunMore()) {
return false;
}
return !queuedQueries.isEmpty() || !eligibleSubGroups.isEmpty();
}
}
因此,我们可以知道,当group满足如下的条件:
- group可以执行查询,即新的查询过来不会排队;
- queuedQueries不为空或者其存在eligible的sub-groups;
那么就可以认为这个group是eligible的,然后将其加入到parent group的eligibleSubGroups队列中。
所以总结来看,这个eligibleSubGroups就可以理解为:当前group下,有一批eligible的sub-groups,需要按照指定的策略,来挑选一个sub-group,执行该sub-group中的sql。
Resource group创建
在服务启动的时候,presto内部没有创建任何的group。只有当sql提交之后,presto服务才会判断是否需要创建group。这里以官方文档Resource Groups中的demo为例:如果我们设置source为pipeline,user为presto,那么查询会被提交到global.pipeline.pipeline_presto队列上,对应的是如下的group和selector rule:
//sub group
{
"name": "pipeline_${USER}",
"softMemoryLimit": "50%",
"hardConcurrencyLimit": 5,
"maxQueued": 100
}
//selector
{
"source": ".*pipeline.*",
"group": "global.pipeline.pipeline_${USER}"
}
如果是服务刚启动,此时集群中是没有任何队列的。所以会先创建global,再创建global.pipeline,最后再创建global.pipeline.pipeline_presto。如果我们此时再使用其他用户提交,例如hive(source仍然是pipeline),那么就只需要创建global.pipeline.pipeline_hive即可,不需要再创建global和global.pipeline了。相关代码如下所示:
submit(InternalResourceGroupManager.java):151
-createGroupIfNecessary(InternalResourceGroupManager.java):311
--createGroupIfNecessary(InternalResourceGroupManager.java)
//InternalResourceGroupManager.createGroupIfNecessary()
private synchronized void createGroupIfNecessary(SelectionContext context, Executor executor) {
ResourceGroupId id = context.getResourceGroupId();
if (!groups.containsKey(id)) {
InternalResourceGroup group;
if (id.getParent().isPresent()) {
createGroupIfNecessary(new SelectionContext<>(id.getParent().get(), context.getContext()), executor);
//省略其余代码
这段代码主要就是通过递归,不断处理当前group的parent group,来完成相关group的创建,最终global、global.pipeline和global.pipeline.pipeline_presto这三个group就会被依次创建出来。其中,global是属于root group。
根据schedulingPolicy创建相应的调度队列
下面我们看一下具体group的创建和配置,这里我们主要关注不同调度策略下的调度队列创建,相关的代码调用如下所示:
submit(InternalResourceGroupManager.java):151
-createGroupIfNecessary(InternalResourceGroupManager.java):339
--configure(FileResourceGroupConfigurationManager.java):108
---configureGroup(AbstractResourceConfigurationManager.java):209
----setSchedulingPolicy(InternalResourceGroup.java):545
最终在setSchedulingPolicy函数中,会根据不同的policy创建不同的队列,如下所示:
//InternalResourceGroup.setSchedulingPolicy()
Queue queue;
TieredQueue queryQueue;
switch (policy) {
case FAIR:
queue = new FifoQueue<>();
queryQueue = new TieredQueue<>(FifoQueue::new);
break;
case WEIGHTED:
queue = new StochasticPriorityQueue<>();
queryQueue = new TieredQueue<>(StochasticPriorityQueue::new);
break;
case WEIGHTED_FAIR:
queue = new WeightedFairQueue<>();
queryQueue = new TieredQueue<>(IndexedPriorityQueue::new);
break;
case QUERY_PRIORITY:
// Sub groups must use query priority to ensure ordering
for (InternalResourceGroup group : subGroups.values()) {
group.setSchedulingPolicy(QUERY_PRIORITY);
}
queue = new IndexedPriorityQueue<>();
queryQueue = new TieredQueue<>(IndexedPriorityQueue::new);
break;
}
这里的queue和queryQueue,就分别对应了InternalResourceGroup中的eligibleSubGroups和queuedQueries这两个队列。接着继续看下各个策略对应的队列。
fair
默认的调度策略,就是典型的FIFO,没有任何的优先级考量。对于两个队列,都是使用了FifoQueue这个队列,FifoQueue的相关代码如下所示:
final class FifoQueue implements UpdateablePriorityQueue {
private final Set delegate = new LinkedHashSet<>();
public boolean addOrUpdate(E element, long priority) {
return delegate.add(element);
}
实际FifoQueue内部使用了一个Set来实现队列的出对和入队等相关操作,就是最基础的先进先出,对于addOrUpdate方法传入的priority参数,实际是没有起作用的。
weighted
对于weighted这个策略,两个调度队列使用的都是StochasticPriorityQueue这个类,主要的代码如下所示:
final class StochasticPriorityQueue implements UpdateablePriorityQueue {
private final Map> index = new HashMap<>();
// This is a Fenwick tree, where each node has weight equal to the sum of its weight
// and all its children's weights
private Node root;
private static final class Node {
private Optional> parent;
private E value;
private Optional> left = Optional.empty();
private Optional> right = Optional.empty();
private long tickets;
private long totalTickets;
private int descendants;
从注释上来看,这个StochasticPriorityQueue使用了Fenwick tree,也就是树状数组或二叉索引树,来实现队列的相关操作。这里有若干个成员变量,常见的parent、value等不多做介绍,主要有三个成员变量需要注意:
- tickets,可以理解为节点的权重,对于查询来说,这个值代表的就是query_priority;对于eligible的sub-groups来说,这个值代表的就是group的priority,关于group的priority计算,我们后面再介绍;
- totalTickets,该节点以及所有子节点的tickets总和;
- descendants,表示当前节点的孩子数,当add或者remove节点时,该值就会进行更新。需要注意的是,在插入新节点时,会根据左右子节点的descendants,来加入少的一边,保证树的平衡。
当对StochasticPriorityQueue队列进行入队时,就会构建以root为根节点的树,并且将group和对应的节点信息放到map中,作为索引。相关代码可以参考StochasticPriorityQueue.addOrUpdate()方法,这里不再展开。现在看下关键的出队操作,即如何挑选查询或者sub-group,主要流程如下所示:
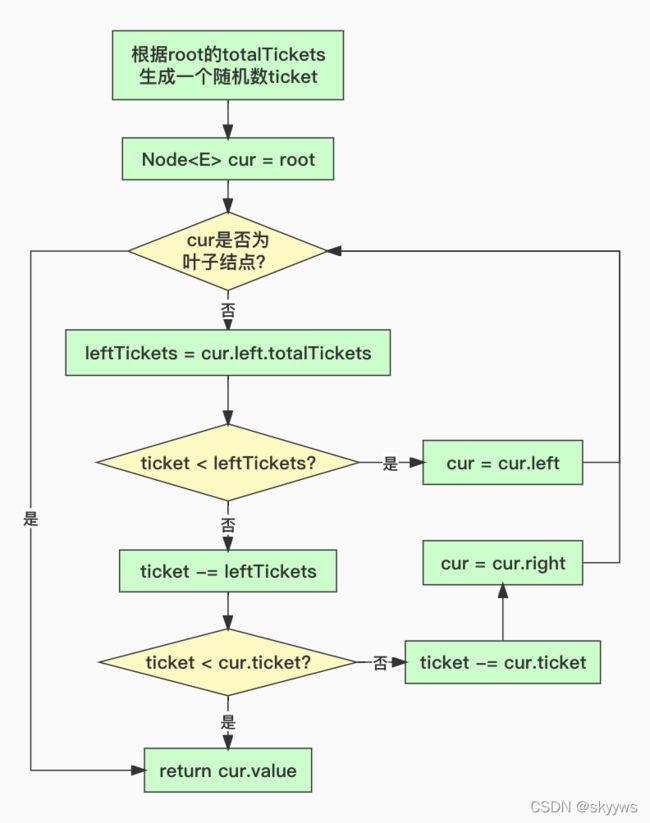
再结合官方的文档描述:
weighted: queued queries are selected stochastically in proportion to their priority, specified via the query_priority session property. Sub groups are selected to start new queries in proportion to their schedulingWeight.
可以简单这样理解这种调度策略:以权重总和为上限生成随机数,按照从上往下,从左往右的顺序,找到一个权重小于该随机数的节点。查询的权重就是query_priority;eligible sub-groups的权重就是其priority,与schedulingWeight有关。
weighted_fair
对于weighted_fair策略,分别使用了两个不同的队列。eligibleSubGroups队列使用的是WeightedFairQueue,而queuedQueries用的是IndexedPriorityQueue,下面我们分别来看下这两个调度队列的特点。
IndexedPriorityQueue队列
queuedQueries使用的是这个IndexedPriorityQueue队列。这个队列按照查询的query_priority入队,构造相应的数据结构。出队的时候,严格按照query_priority选择高优的节点,相关代码如下所示:
final class IndexedPriorityQueue implements UpdateablePriorityQueue {
private final Map> index = new HashMap<>();
private final Set> queue = new TreeSet<>((entry1, entry2) -> {
int priorityComparison = Long.compare(entry2.getPriority(), entry1.getPriority());
if (priorityComparison != 0) {
return priorityComparison;
}
return Long.compare(entry1.getGeneration(), entry2.getGeneration());
});
private long generation;
private static final class Entry {
private final E value;
private final long priority;
private final long generation;
这里使用了TreeSet来保存具体的查询信息,按照priority和generation进行比较;index可以理解为索引,可以实现O(1)时间复杂度的contain和remove操作,效率比较高。这里的generation可以理解为插入的顺序,每次插入新的成员,都会将队列的当前generation赋值给节点,然后自增1,这个变量主要在出队时,用来比较priority相同的成员。
WeightedFairQueue队列
eligibleSubGroups使用的是WeightedFairQueue队列,与其他几个队列不同,在更新sub-groups到eligibleSubGroups队列的时候,如果是weighted_fair这种调度策略,即WeightedFairQueue队列,则使用schedulingWeight和runningQueries构造了一个Usage来作为权重:
private void addOrUpdateSubGroup(Queue queue, InternalResourceGroup group) {
if (schedulingPolicy == WEIGHTED_FAIR) {
((WeightedFairQueue) queue).addOrUpdate(group, new Usage(group.getSchedulingWeight(), group.getRunningQueries()));
}
//WeightedFairQueue.java
public static class Usage {
private final int share;
private final int utilization;
这里的share和utilization分别就对应了上面的schedulingWeight和runningQueries。我们接着看下WeightedFairQueue队列的内容:
final class WeightedFairQueue implements Queue {
private final Map> index = new LinkedHashMap<>();
private long currentLogicalTime;
private static final class Node implements Comparable> {
private final E value;
private final long logicalCreateTime;
private Usage usage;
这里同样使用了一个Node结构体用来保存具体的group信息和对应的Usage,currentLogicalTime变量作用与上面的generation类似。入队操作非常简单,就是根据group信息、Usage和currentLogicalTime构造Node,然后加入map中,同时currentLogicalTime自增。我们主要看下出队的操作:
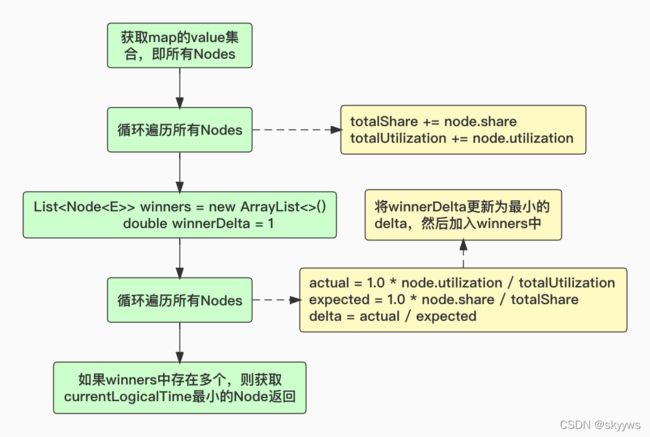
主要思路就是:获取每个节点utilization和share占总的比例,然后计算一个实际占比/期望占比的delta,取delta最小的节点,这里utilization代表runningQueries,可以理解为group实际使用的占比;而share代表schedulingWeight,可以理解为group预期的占比,最终相除就是实际/期望的delta。所以,结合weighted_fair策略的官方文档来看:
weighted_fair: sub-groups are selected based on their schedulingWeight and the number of queries they are already running concurrently. The expected share of running queries for a sub-group is computed based on the weights for all currently eligible sub-groups. The sub-group with the least concurrency relative to its share is selected to start the next query.
对于该策略来说:
- eligible sub-groups挑选是结合了schedulingWeight和运行并发数,来计算一个实际占比/期望占比最小的节点;
- 查询挑选则是按照查询的query_priority,选择高优的查询。
query_priority
对于query_priority策略,两种调度队列用的也都是IndexedPriorityQueue。与weighted_fair一样,当queuedQueries使用IndexedPriorityQueue时,Entry中的priority对应的就是查询的priority;而当eligibleSubGroups使用IndexedPriorityQueue时,Entry中的priority对应的就是group的priority。这里我们再简单看下查询的priority设置。
SET语句设置priority
按照查询的priority来进行调度,我们可以通过session property来设置查询的priority,如下所示:
set session query_priority=10;
JDBC设置priority
除了直接使用set语句之外,我们也可以通过jdbc来设置查询的priority,如下所示:
String url = "jdbc:presto://ip:host/hive/tpch_parquet";
Properties properties = new Properties();
properties.setProperty("user", "presto");
Connection connection = DriverManager.getConnection(url, properties);
PrestoConnection pc = connection.unwrap(PrestoConnection.class);
//设置client tags和source
pc.setClientInfo("ClientTags", "test,dev");
pc.setClientInfo("ApplicationName", "app");
//设置session property,这里就是设置了priority
pc.setSessionProperty("query_priority", "5");
Group的priority计算
上面我们提到了,当使用weighted和query_priority两种调度策略时,eligibleSubGroups分别对应的是StochasticPriorityQueue和IndexedPriorityQueue,这两个调度队列的addOrUpdate方法都需要传入一个priority。这里我们看下group的priority是如何计算的。相关代码如下:
private void addOrUpdateSubGroup(Queue queue, InternalResourceGroup group) {
if (schedulingPolicy == WEIGHTED_FAIR) {
//省略部分代码
} else {
((UpdateablePriorityQueue) queue).addOrUpdate(group, getSubGroupSchedulingPriority(schedulingPolicy, group));
}
}
private static long getSubGroupSchedulingPriority(SchedulingPolicy policy, InternalResourceGroup group) {
if (policy == QUERY_PRIORITY) {
return group.getHighestQueryPriority();
} else {
return group.computeSchedulingWeight();
}
}
private long computeSchedulingWeight() {
if (runningQueries.size() + descendantRunningQueries >= softConcurrencyLimit) {
return schedulingWeight;
}
return (long) Integer.MAX_VALUE * schedulingWeight;
}
可以看到,这里主要分两种情况:
- 如果是QUERY_PRIORITY调度策略,则直接获取queuedQueries队列中的peek成员的query_priority,作为group的priority,详细代码可以参考getHighestQueryPriority方法;
- 如果是其他调度策略,则先判断当前的并发查询数是否超过了softConcurrencyLimit,是的话直接返回schedulingWeight;否则返回Integer.MAX_VALUE * schedulingWeight,表示将队列的优先级提高到很大。
小结
到这里关于调度策略的相关内容就基本已经梳理完毕了。这里我们简单总结下:本文主要分析了调度策略配置项schedulingPolicy生效的两种场景和具体的四种调度策略。生效的场景主要就是:1)如何挑选合适的sub-groups用于提交查询;2)如何选择排队的查询来执行。关于四种调度策略我们可以归纳如下:
| 调度策略 | 查询筛选 | eligible sub-groups筛选 |
|---|---|---|
| fair | FIFO | FIFO |
| weighted | 以query_priority为权重,按比例随机挑选 | 以group的priority(与schedulingWeight有关)为权重,按比例随机挑选 |
| weighted_fair | 按照query_priority挑选高优先级的查询 | 结合schedulingWeight和运行并发数,找到实际占比/期望占比最小的group |
| query_priority | 按照query_priority挑选高优先级的查询 | 按照group的priority(入队时,取queuedQueries队列的peek成员的query_priority)挑选高优先级的group |
简单来看,就是:1)如果我们需要严格按照query_priority来执行sql,那么需要选择weighted_fair或者query_priority策略;2)当我们想要通过schedulingWeight来控制多个group的优先执行顺序,可以选择weighted和weighted_fair策略。
由于ResourceGroups相关的代码内容非常多,很多细节处本文也没有涉及,后续有机会再继续深入研究。同时,由于presto缺乏相关的代码注释和commit message,文章中的所有观点,都是笔者本人基于代码分析得出来的,如有错误,欢迎指正。