【AM-GCN】代码解读之utlis
前篇:
【AM-GCN】代码解读之初了解(一)
【AM-GCN】代码解读之主程序
导入库
import numpy as np
import scipy.sparse as sp
import torch
一、加载图特征load_graph
def load_graph(dataset, config):
featuregraph_path = config.featuregraph_path + str(config.k) + '.txt'
feature_edges = np.genfromtxt(featuregraph_path, dtype=np.int32)
fedges = np.array(list(feature_edges), dtype=np.int32).reshape(feature_edges.shape)
# fedges经验证是等同于feature_edges
fadj = sp.coo_matrix((np.ones(fedges.shape[0]), (fedges[:, 0], fedges[:, 1])), shape=(config.n, config.n), dtype=np.float32)
# 创建稀疏矩阵
fadj = fadj + fadj.T.multiply(fadj.T > fadj) - fadj.multiply(fadj.T > fadj)
nfadj = normalize(fadj + sp.eye(fadj.shape[0]))
struct_edges = np.genfromtxt(config.structgraph_path, dtype=np.int32)
sedges = np.array(list(struct_edges), dtype=np.int32).reshape(struct_edges.shape)
sadj = sp.coo_matrix((np.ones(sedges.shape[0]), (sedges[:, 0], sedges[:, 1])), shape=(config.n, config.n), dtype=np.float32)
sadj = sadj + sadj.T.multiply(sadj.T > sadj) - sadj.multiply(sadj.T > sadj)
nsadj = normalize(sadj+sp.eye(sadj.shape[0]))
nsadj = sparse_mx_to_torch_sparse_tensor(nsadj)
nfadj = sparse_mx_to_torch_sparse_tensor(nfadj)
return nsadj, nfadj
解析说明:
-
featuregraph_path=“…/data/acm/knn/c” +str(5) +“.txt”
-
np.genfromtxt:读取txt文件。(具体用法查看链接)
提醒:acm当是
.zip的压缩包的时候,上述路径featuregraph_path文件读取报错且用os.path.exists(featuregraph_path)判断不存在。此时,需要将压缩包解压即可。
feature_edges.shape=(7282, 2); struct_edges.shape=(26256,2)
结果展示:acm有3025个节点。txt每行表示graph中的edge的两个端点。
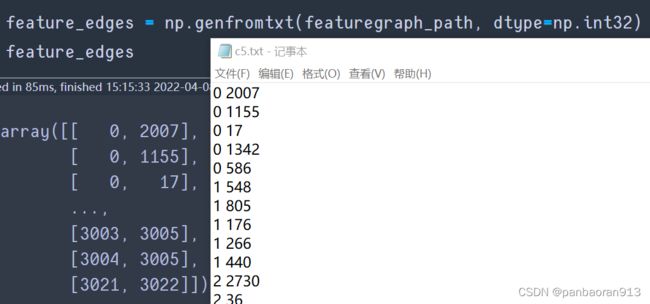
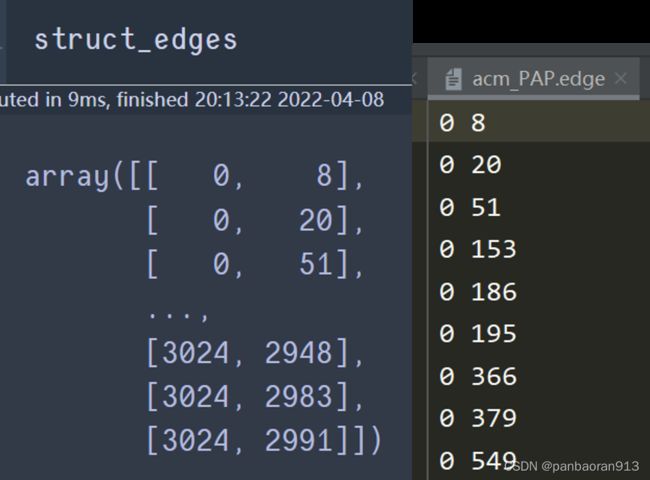
-
sp.coo_matrix((data, (row, col)), shape=(N, N))构造一个稀疏矩阵,行索引为row,列索引为col,对应位置的值为data,矩阵的大小为(N,N).这里的N =config.n =3025.提醒:这里生成的稀疏矩阵当转化为密集矩阵的时候,对角线元素为0,且为上三角的非对称矩阵。
优点: 转化快速,还能转化成CSR/CSC格式的稀疏矩阵。
缺点: 不支持切片和矩阵计算 -
fadj = fadj + fadj.T.multiply(fadj.T > fadj) - fadj.multiply(fadj.T > fadj)中的运算都是逐元素运算。multiply是逐元素乘法。 A ~ = A + A T ( A T > A ) − A ( A T > A ) \tilde{A} = A+ A^T(A^T>A)-A(A^T>A) A~=A+AT(AT>A)−A(AT>A)含义为,对于(i,j)位置的元素,如果 a ( j . i ) > a ( i . j ) a_{(j.i)}>a_{(i.j)} a(j.i)>a(i.j),则选择 a ( j . i ) a_{(j.i)} a(j.i),反之则选择 a ( i . j ) a_{(i.j)} a(i.j).在本次加载的数据可以看作上三角矩阵,但不是每个人的数据都是如此设置的。这其实是兼顾了不同类型数据而做出的处理。在本次20acm加载的数据中,其本质结果就是fadj未曾做出改变。 -
nfadj = normalize(fadj + sp.eye(fadj.shape[0])),normalize()对矩阵进行归一化处理,spe.eye是单位矩阵。 N A = N ( A ) + E NA = N(A)+E NA=N(A)+E -
sparse_mx_to_torch_sparse_tensor(nsadj),查看附录B,是将稀疏矩阵转化为torch中的稀疏矩阵。
二、
def load_data(config):
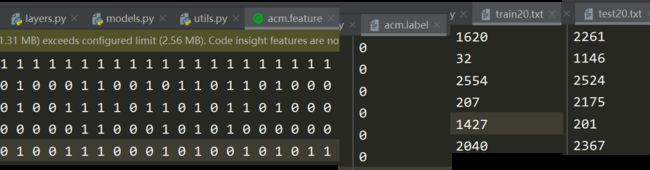
f = np.loadtxt(config.feature_path, dtype = float)
l = np.loadtxt(config.label_path, dtype = int)
test = np.loadtxt(config.test_path, dtype = int)
train = np.loadtxt(config.train_path, dtype = int)
features = sp.csr_matrix(f, dtype=np.float32) #对f这个ndarray生成csr_martix
features = torch.FloatTensor(np.array(features.todense()))
#features先转化为密集矩阵,再生成torch中的tensor
idx_test = test.tolist()
idx_train = train.tolist()
idx_train = torch.LongTensor(idx_train)
idx_test = torch.LongTensor(idx_test)
label = torch.LongTensor(np.array(l))
return features, label, idx_train, idx_test
解释说明:
| 参量 | 路径 | shape | 说明 |
|---|---|---|---|
| config.feature_path | ‘…/data/acm/acm.feature’ | (3025, 1870) | 特征向量,3025个node,每个node的特征维度为1870 |
| config.label_path | ‘…/data/acm/acm.label’ | (3025,) | 标签,对应3025个node |
| config.test_path | ‘…/data/acm/test20.txt’ | (1000,) | |
| config.train_path | ‘…/data/acm/train20.txt’ | (60,) |
f,l,test,train都是ndarray。原文件打开样貌为:
附录:调用的函数
本篇是对于上面函数中被调用的小函数的解析
A normalize()
标准化方法:逐行求和,每个元素除以行和
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1))#。sum(1)对axis=1求和同np.sum()类似-->求行和
r_inv = np.power(rowsum, -1).flatten() #数组元素求n次方-->求行和的倒数并拉平到一维数组(注:0的倒数为inf)
r_inv[np.isinf(r_inv)] = 0.#r_inv的inf值设置为0
r_mat_inv = sp.diags(r_inv)#将r_inv设置为对角线元素构成稀疏矩阵
mx = r_mat_inv.dot(mx)#.dot是矩阵乘法不是逐元素乘法
return mx
B.sparse_mx_to_torch_sparse_tensor()
sparse_mx是一个稀疏矩阵(sparse库),要转化为torch中的稀疏张量。
- sparse_mx转化为coo_matrix。因为它有row,col,data,shape四个属性
- 四个属性转化为torch的张量
- 通过torch.sparse.FloatTensor转化为torch中的稀疏张量
这个方法的缺点是不能构建 batch 的sparse tensor。
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
## sparse可能是csr_matrix,经tocoo()转化为coo_matrix
indices = torch.from_numpy(np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64)) #vstack列链接或者axis=1上拼接
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)