YOLOV5网络结构设计的思考
YOLOV5-5.0网络结构
由于某些要求的需要,我想重新学习一下YOLOv5,在这里做一个记录,可能有很多地方写的不对,还希望大家包涵。
文章目录
- YOLOV5-5.0网络结构
- Focus
- Bottleneck
- BottleneckCSP
- C3
- C3TR
- SPP
- Neck(FPN+PAN)
-
- FPN
- PAN
- BiFPN(似乎yolov5用它试验过,效果不佳?)
- 参考资料

Focus
focus是yolov5原创的一个结构,在网络刚开始使用,将图片分成四份,特征图的通道数不变,长宽各缩小一半。网络结构如下:
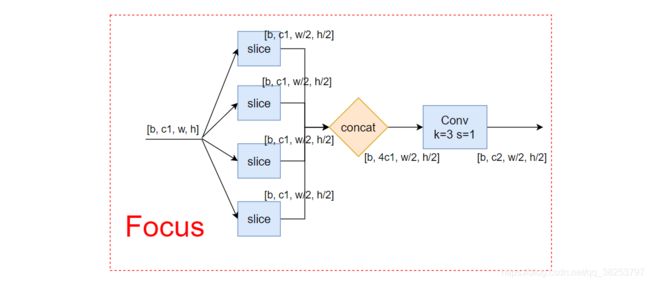
思考:引用大佬(默认指代同上)的一段话:从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,聚焦wh维度信息到c通道空,提高每个点感受野,并减少原始信息(图像的特征?)的丢失。这个组件并不是为了增加网络的精度的,而是为了减少计算量,增加速度(图像尺寸变小就可以得到图像相邻的四个位置,不理解?),图片引用知乎的DLing大佬

原来他不是单纯的缩小图片尺寸:将原始图像按照横纵坐标方向各做二倍间隔采样,由3x640x640,直接变成12x320x320,相当于下采样;作者在github中的issues中有回复:为了降低FLOPs,提升网络推理速度,从网络提取浅层特征的效果角度考虑,这种方式相当于对图像的原始特征进行了重排,但是信息并没有丢失,同时感受野提升了,而模块后面接的卷积模块可以提取特征。
总结:yolov5作者在github的issue回复:Focus的作用:减少层数,减少参数量,减少计算量,减少cuda内存占用,在mAP影响很小的情况下,提升推理速度和梯度反传速度。其中减少层数,减少参数量,减少计算量是指和YOLOV3对比,作者认为这样一个Focus层可以抵YOLOV3的3个卷积层。如下(引用知乎的DLing大佬):
Bottleneck
yolov5的Bottleneck和resnet的略微有点出入,两者的网络结构分别如下:
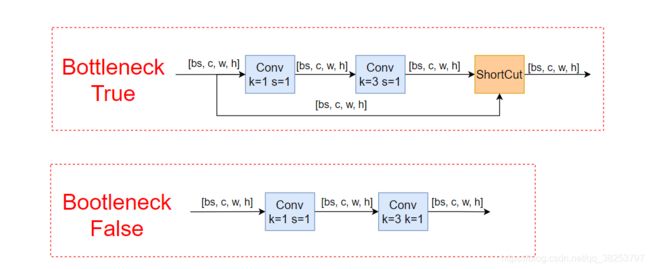
第一个1x1 conv用来降维,3x3 conv的用来增加通道数,残差分支中的1x1 conv用来做add,不改变输入的大小(注意这里使用的是add,不是concat),yolov5的Bottleneck相对于resnet来说少了一个1*1 的升维conv(是为了体现不同,还是?),当然,yolov5还自己实验了许多的激活函数:如SiLU、LeakRelu、PRelu、ACON-C等等
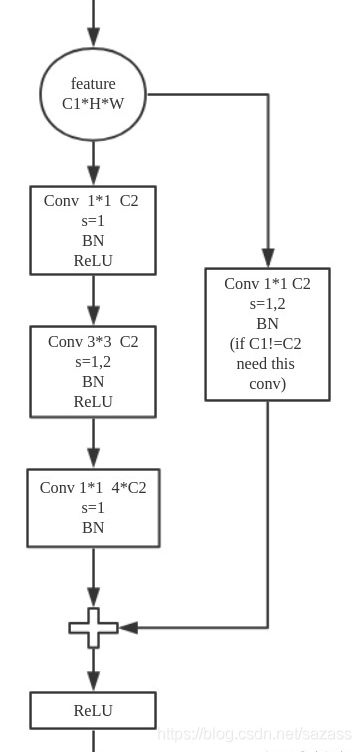
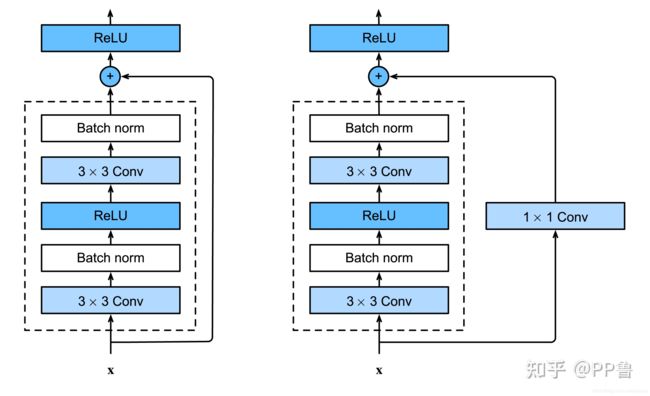
思考:Resnet设计的BasicBlock与bottleneck(结构如下图),BasicBlock用于层数不多的网络(resnet18、34),bottleneck用于层数较深的网络(resnet50、101、152)。bottleneck相对于BasicBlock:1×1卷积层在更深的网络中,可以用较小的参数量处理通道数很大的输入,使用1×1卷积层,参数量减少,并且深层网络中的残差基础块应该减少算力消耗,毕竟网络越深,对于算力的要求越高。(这是yolov5使用Bottleneck的原因?毕竟它也很深)
BottleneckCSP
yolov5将Bottleneck和CSP结构组合,CSP结构源于2019年的一篇文章:CSPNet: A New Backbone that can Enhance Learning Capability of CNN
CSP结构主要思想:在输入block(如Bottleneck)之前,将输入分为两个部分,其中一部分通过block进行计算,另一部分直接通过一个带卷积shortcut进行concat。
作用(作者观点):加强CNN的学习能力、减少内存消耗,减少计算瓶颈,现在的网络大多计算代价昂贵,不利于工业的落地。详情解说可参考大佬CSPNet论文复现。BottleneckCSP网络结构如下:

思考:yolov4也使用了CSPNet作为骨干网络,通过Bottleneck和CSP结构的有效组合,在yolov5中效果也确实不错(我想这得做了许多实验才得出的吧),CSP模块本身是一个轻量型的模块,速度也不错,符合YOLO历来的设计理念。
C3
YOLOv5 2020年5月出来后不断更新,不断实践,设计出C3模块用来替换BottleneckCSP模块。当然这是作者在COCO等特定数据集上进行实验得出的,如果大家要进行迁移,也可以考虑不替换。二者的网络结构如下:
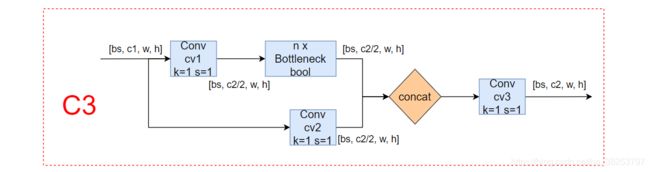

可以看出C3相对于BottleneckCSP模块,少了一个1x1 conv,同时撤掉了一个BN层和激活函数。
思考:作者在yolov5项目的updated result说:这样操作在YOLOV5X上模型参数量可以从89M下降到87.7M,推理时间从6.9ms下降到6.0ms,mAP从49.2提升到50.1—精简网络结构,减少计算量,降低模型推理时间,同时模型的性能没有下降(好像有道理喔)
C3TR
YOLOV5不断更新,不断升级,不是一个人所能成就的,这个模块好像就是另一位大佬设计的。transformer最初设计使用是在自然语言处理领域,后面发现在CV领域也效果不错(尽管它还存在一些问题:对设备算力要求较高、对于数据量需求大),所以它目前工业落地怕是还不行(我听说在工业界普遍所使用的模型一般落后于学术界两到三年,有道理吗?),到现在transformer可以说是盛行于CV界了,但目前感觉没啥用。C3TR模块代码设计如下(满船清梦压星河HK大佬的),其实作者是对Attention Is All You Need
:和An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(VIT)两篇论文的多头自注意力模块和位置编码进行应用。
# transformer
class TransformerLayer(nn.Module):
"""
Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
视频: https://www.bilibili.com/video/BV1Di4y1c7Zm?p=5&spm_id_from=pageDriver
https://www.bilibili.com/video/BV1v3411r78R?from=search&seid=12070149695619006113
这部分相当于原论文中的单个Encoder部分(只移除了两个Norm部分, 其他结构和原文中的Encoding一模一样)
"""
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
# 输入: query、key、value
# 输出: 0 attn_output 即通过self-attention之后,从每一个词语位置输出来的attention 和输入的query它们形状一样的
# 1 attn_output_weights 即attention weights 每一个单词和任意另一个单词之间都会产生一个weight
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
# 多头注意力机制 + 残差(这里移除了LayerNorm for better performance)
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
# feed forward 前馈神经网络 + 残差(这里移除了LayerNorm for better performance)
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
"""
Vision Transformer https://arxiv.org/abs/2010.11929
视频: https://www.bilibili.com/video/BV1Di4y1c7Zm?p=5&spm_id_from=pageDriver
https://www.bilibili.com/video/BV1v3411r78R?from=search&seid=12070149695619006113
这部分相当于原论文中的Encoders部分 只替换了一些编码方式和最后Encoders出来数据处理方式
"""
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding 位置编码
self.tr = nn.Sequential(*[TransformerLayer(c2, num_heads) for _ in range(num_layers)]) # encoder * n
self.c2 = c2 # 输出channel
def forward(self, x):
if self.conv is not None: # embedding
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2)
p = p.unsqueeze(0)
p = p.transpose(0, 3)
p = p.squeeze(3)
e = self.linear(p) # positional encoding
x = p + e # 将坐标编码加入到输入特征当中
x = self.tr(x) # encode * n
x = x.unsqueeze(3) # encoders结束 维度处理
x = x.transpose(0, 3)
x = x.reshape(b, self.c2, w, h)
return x
class C3TR(C3):
"""
这部分是根据上面的C3结构改编而来的, 将原先的Bottleneck替换为调用TransformerBlock模块
"""
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)
从yolov5的issue得知:其实刚开始就设计将C3TR只放在yolov5的backbone的最后一层,替换掉C3模块(这样FLOPS少一点,放置在主干末端的C3TR模块主要影响大对象,小对象可能不会受到过多影响,更好的提取全局信息)

接着作者在yolov5的backbone和head各个C3模块都尝试放置C3TR进行替换,发现除backbone最后一层(使用CUDA内存最少,为啥,因为这层feature map小?)外其余各层均出现CUDA OOM(显存不足)。因此作者认为可能最后一层是放置C3TR模块的较佳选择(不消耗太多资源、并影响整个head)
大佬也尝试了在transformer中加入droupout和droupout+act(最初的transformer本身也是用了droupout方法的),但似乎没有明显提升。
一次偶然,大佬尝试移除掉transformer中的LayerNorm layers,得到了一个令人惊喜的结果:

[email protected]有所提升,[email protected]:0.95似乎保持不变(C3TR放在backbone末端主要影响大对象检测,所以[email protected]可能会下降,[email protected]不变?)
最终就形成了这样一个C3TR模块(positional encoding位置编码:如果不加,可能transformer更适用于分类任务,加了位置信息后,更符合检测、定位任务?)
思考:作者加入transformer设计C3TR模块减少了FLOPS,其他可能也没啥了吧,只是单纯的想把transformer应用到yolo中来作为一个方便使用的模块备选?毕竟对于不同的数据集、不同的任务哪个模块孰强孰弱,不好区分,哪个用起来顺手哪个就棒棒的!
补充:transformer的多头自注意力是一种自注意力机制,注意力机制其实也是一个很大的课题,包括软注意力、硬注意力等等,亦或可分为通道注意力、空间注意力、混合注意力之类的,cv领域中一般应用的是软注意力,我这里例举一些比较出名的注意力机制:(yolov5肯定有人使用过,但作者似乎没做过实验?)
作者没有使用注意力机制的原因(作者原话):
![]()
是因为注意力机制对于落地所需的模型转换有一定的影响?
SE:SElayer
CBAM:CBAM
CA:CA(我听说一般使用注意力机制和时间序列网络LSTM之类的效果都不错,反正我目前用的感觉不太行!可能用的不对,大家如果要使用可以参照一些使用过注意力机制的:如这些设计注意力模块的肯定有做过很多比较、efficientnet系列、EfficientDet等
SPP
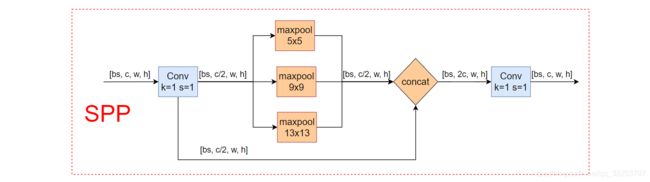
SPP空间金字塔池化网络结构来源于2014年的一篇论文:《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》,YOLO系列从yolov3开始都使用了,主要是为了将更多不同分辨率的特征进行融合,得到更多的信息。yolov5使用的SPP结构如下:
Neck(FPN+PAN)
yolov5刚出来应该是只有FPN(特征金字塔网络)的,后面又立马加上了PAN,为啥要用到FPN之类的呢?无奈它好用,这里我想讲一下它出现的原因(网络结构见最上面总图!!!)。
FPN
目标检测任务发展了许多年,像yolov1这种对图片使用卷积来提取特征,输出一个小尺度的特征图,最后回归出边框,可以称之为**‘单特征图检测’**;
多特征图检测(解决难以有效的识别出不同大小的目标问题):一个图片同样是经过卷积网络来提取特征,本来是经过多个池化层(也可为卷积)输出一个特征图,现在是经过多个池化层,每经过一个池化层(卷积)都会输出一个特征图,这样其实就提取出了多个尺度不同的特征图(举了个例子),FPN可以算一种多特征图检测,但并不是全部,如大名鼎鼎的SSD算法。
目标检测中对小物体检测很困难,因为卷积过程中,大物体的像素点多,小物体的像素点少,随着卷积的深入,大物体的特征容易被保留,小物体的特征越往后越容易被忽略,这是FPN产生重要的原因。网络结构如下:(看不明白没关系,这篇博文帮助您–FPN及其变体)
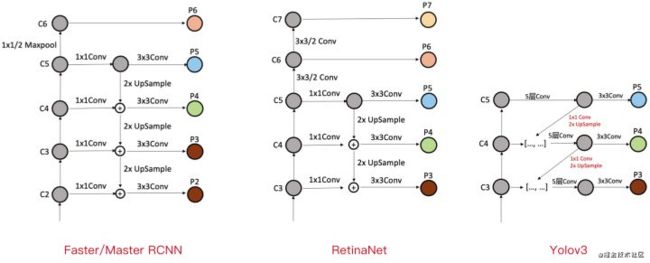
FPN:FPN结构将不同分辨率大小的特征图进行下采样,获得了一堆具有高语义内容的特征图(网络的深层通常具备较高的语义信息,较弱的定位信息,而浅层的feature map携带有较强的位置信息,和较弱的语义特征?),然后重新进行上采样,使得特征图的长宽重新变大,用大size的feature map去检测小目标,小size的去检测大目标。并不是只进行上采样,**因为这样上采样的结果对小目标的特征与信息也不明确了(**why?有点不理解),因此它将下采样中与上采样中长宽相同的特征层进行堆叠(注意:这里是add操作),这样可以保证小目标的特征与信息。、
P4可以学到来自C5更深层的语义,然后P3可以学到来自C4更深层的语义。因为对于预测精度来说,肯定是越深层的特征提取的越好,所以预测的越准确,但是深层的特征图尺度较小,通过上采样和浅层的特征图融合,可以强化浅层特征图的特征表述。----一句话FPN可以很好的融合不同尺寸大小的特征来适应不同大小的对象-高效的多尺度特征融合(好像有道理喔)
FPN结构对小尺寸目标检测更好(原因):
- FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息)
- 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息)(我觉得有道理)
PAN
每一个行之有效的网络结构都会被众多人关注,FPN因此产生了一系列的变体:PAN、NAS-FPN、BiFPN等等,PANet是18年的一篇CVPR,作者来自港中文,北大,商汤与腾讯优图,是第一个提出从下向上二次融合的模型,当然除此之外还有许多的二次融合的类似的结构。PAN结构如下:(看不懂?好好看,结合yolov5网络结构)

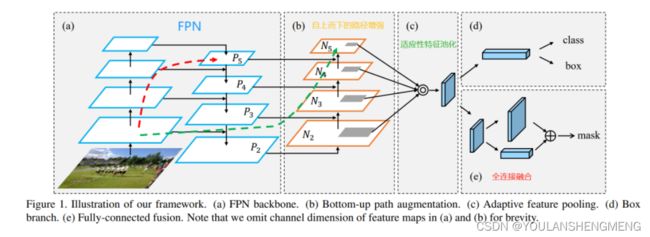
思考:PANet作者认为FPN中P5也间接得有了low-level特征图的特征,但是信息流动路线太长(按卷积层算),如 上图红色虚线 所示 (其中有 ResNet50/101很多卷积层 );而网络浅层特征信息对于实例分割(目标检测等)其实也非常重要,因此设计了如图所示的自下而上的路径增强的网络结构(层数不到10层,能较好地保留浅层特征信息)–(每一个设计的网络结构都讲的有道理!)
BiFPN(似乎yolov5用它试验过,效果不佳?)
BiFPN是2020年谷歌提出的EfficientDet模型中所应用的一种FPN变体,论文链接。网络结构如下:
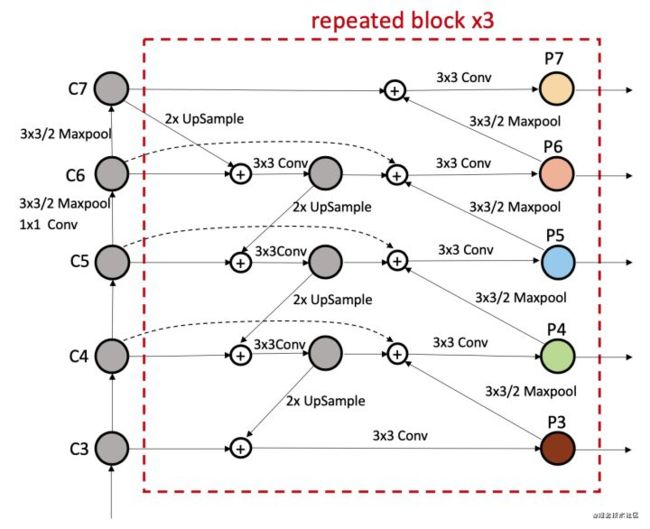
思考:不同于其他的FPN结构(不同尺度的特征融合时直接相加),但实际上它们对最后检测的贡献是不同的,所以作者希望网络来学习不同输入特征的权重,即 weighted feature fusion(给不同尺度的特征层设置不同大小的权重,相当于引入了注意力机制,并且研究对比了几种权重设置的方法),毕竟,不同的输入特征具有不同的分辨率,那它们对输出特征的贡献通常是不相等的(好像有道理喔),同时,减少了一些不必要的层的结点连接**。
总结:就我而言,无论是FPN、PANet、BiFPN亦或是其他,哪一个更强并不绝对,不同的任务、不同的数据集、不同的模型大家都可以尝试它们中的任何一个,哪一个顺手哪一个就棒棒哒!—推荐一个打比赛或者 实验自己想法比较快的框架(mmdetection-包含检测、分割、姿态估计等多种任务的集大成者)
未完待续!!!
参考资料
CSDN: 满船清梦压星河HK (我本文的图片大多使用这位大佬的,如有侵权,可联系删除):https://blog.csdn.net/qq_38253797/article/details/119684388
CSDN: 大黑山修道:
(https://chenlinwei.blog.csdn.net/article/details/116864275)
CSDN:Cai Yichao–CSP网络讲解
CSDN:常见特征金字塔网络FPN及其变体
CSDN:EfficientDet-BiFPN
CSDN:FPN及其变体讲解
CSDN:PANet网络讲解
知乎 DLing:https://www.zhihu.com/collection/768844598