【Pytorch神经网络实战案例 】23 使用ImagNet的预训练模型识别图片内容

1 案例基本工具概述
1.1 数据集简介
Imagenet数据集共有1000个类别,表明该数据集上的预训练模型最多可以输出1000种不同的分类结果。
- Imagenet数据集是目前深度学习图像领域应用得非常多的一个领域,关于图像分类、定位、检测等研究工作大多基于此数据集展开。
- Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
- Imagenet数据集有1400多万幅图片,涵盖2万多个类别,其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
1.2 预训练模型
PyTorch中提供了许多在可以被直接加载到模型中并进行器的eNet数据集上训练好的模型,这些模型叫作预训练模型预测。
1.2.1 预训练模型简介
预训练模型都存放在PyTorch的torchvision库中。torchvision库是非常强大的PyTorch视觉处理库,包括分类、目标检测、语义分割等多种计算机视觉任务的预训练模型,还包括图片处理、锚点计算等很多基础工具。
1.2.2 预训练模型简介

2 代码实战
2.1 案例概述
实例描述,将ImageNet数据集上的预训练模型ResNet18加抗到内存,并使用该模型对图片进行分类预测。
2.2 代码实现:下载并加载预训练模型-----ResNetModel.py(第1部分)
from PIL import Image
import matplotlib.pyplot as plt
import json
import numpy as np
import torch
import torch.nn.functional as F
from torchvision import models,transforms # 引入torchvision库
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 1.1 下载并加载预训练模型:引入基础库,并使用torchvision库中的API下载模型。
# Tip:本例使用的中文标签总类别为1001类,索引值为0的类为None,代表未知分类;英文标签总类注意别为1000类,没有None类。
# 因为PyTorch中的模型是在英文标签中训练的,所以在读取中文标签时,还需要将索引值加1
model = models.resnet18(pretrained=True) # True代表要下载模型 ,返回一个具有18层的ResNet模型
model = model.eval()2.3 代码实现:加载标签并对输入数据进行预处理-----ResNetModel.py(第2部分)
# 1.2 加载标签并对输入数据进行预处理
labels_path = './models_2/code_01/imagenet_class_index.json' # 处理英文标签
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
def getone(onestr):
return onestr.replace(',','')
with open('models_2/code_01/中文标签.csv','r+') as f:
zh_labels = list(map(getone,list(f)))
print(len(zh_labels),type(zh_labels),zh_labels[:5]) # 显示输出中文标签
transform = transforms.Compose(
[
transforms.Resize(256), # 将输入图像的尺寸修改为256×256
transforms.CenterCrop(224), # 沿中心裁剪得224×224
transforms.ToTensor(),
transforms.Normalize( # 图片归一化参数:对图片按照指定的均值与方差进行归一化处理,必须要与模型实际训练的预处理方式一样。
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
]
)2.4 使用模型进行预测
2.4.1 代码操作概述
打开一个图片文件,并将其输入模型进行预测,同时输出预测结果。
2.4.2 代码实现:使用模型进行预测 -----ResNetModel.py(第3部分)
# 1.3 使用模型进行预测
# -------start-------- 将四通道中代表透明通道的维度A去掉,变为4通道的图片
def preimg(img): # 图片预处理函数:
if img.mode == 'RGBA': # 实现兼容RGBA格式的图片信息
ch = 4
print('ch',ch)
a = np.asarray(img)[:,:,:3]
img = Image.fromarray(a)
return img
im = preimg(Image.open('models_2/code_01/book.png')) # 载入图片
transforms_img = transform(im) # 调整图片大小
inputimg = transforms_img.unsqueeze(0) # 增加批次维度
# -------end-------- 将四通道中代表透明通道的维度A去掉,变为4通道的图片
output = model(inputimg) # 输入模型
output = F.softmax(output,dim=1) # 获取结果
# 从预测结果中取前3名
prediction_score , pred_label_idx = torch.topk(output,3)
prediction_score = prediction_score.detach().numpy()[0] # 获取结果概率
pred_label_idx = pred_label_idx.detach().numpy()[0] # 获得结果ID
predicted_label = idx_to_labels[str(pred_label_idx[0])][1]#取出标签名称
predicted_label_zh = zh_labels[pred_label_idx[0] + 1 ] #取出中文标签名称
print(' 预测结果:', predicted_label,predicted_label_zh,'预测分数:', prediction_score[0])2.5 预测结果可视化
2.5.1 可视化代码概述
将预测结果以图的方式显示出来。
2.5.2 代码实战:预测结果可视化-----ResNetModel.py(第4部分)
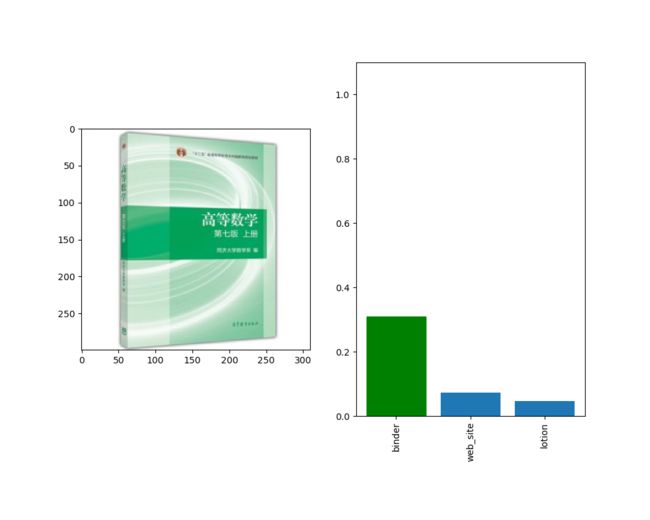
# 1.4 预测结果可视化
#可视化处理,创建一个1行2列的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
fig.sca(ax1) #设置第一个轴是ax1
ax1.imshow(im) #第一个子图显示原始要预测的图片
#设置第二个子图为预测的结果,按概率取前3名
barlist = ax2.bar(range(3), [i for i in prediction_score])
barlist[0].set_color('g') #颜色设置为绿色
#预测结果前3名的柱状图
plt.sca(ax2)
plt.ylim([0, 1.1])
#竖直显示Top3的标签
plt.xticks(range(3), [idx_to_labels[str(i)][1][:15] for i in pred_label_idx ], rotation='vertical')
fig.subplots_adjust(bottom=0.2) #调整第二个子图的位置
plt.show() #显示图像结果输出:
3 代码总览ResNetModel.py
from PIL import Image
import matplotlib.pyplot as plt
import json
import numpy as np
import torch
import torch.nn.functional as F
from torchvision import models,transforms # 引入torchvision库
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 1.1 下载并加载预训练模型:引入基础库,并使用torchvision库中的API下载模型。
# Tip:本例使用的中文标签总类别为1001类,索引值为0的类为None,代表未知分类;英文标签总类注意别为1000类,没有None类。
# 因为PyTorch中的模型是在英文标签中训练的,所以在读取中文标签时,还需要将索引值加1
model = models.resnet18(pretrained=True) # True代表要下载模型 ,返回一个具有18层的ResNet模型
model = model.eval()
# 1.2 还在标签并对输入数据进行预处理
labels_path = './models_2/code_01/imagenet_class_index.json' # 处理英文标签
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
def getone(onestr):
return onestr.replace(',','')
with open('models_2/code_01/中文标签.csv','r+') as f:
zh_labels = list(map(getone,list(f)))
print(len(zh_labels),type(zh_labels),zh_labels[:5]) # 显示输出中文标签
transform = transforms.Compose(
[
transforms.Resize(256), # 将输入图像的尺寸修改为256×256
transforms.CenterCrop(224), # 沿中心裁剪得224×224
transforms.ToTensor(),
transforms.Normalize( # 图片归一化参数:对图片按照指定的均值与方差进行归一化处理,必须要与模型实际训练的预处理方式一样。
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
]
)
# 1.3 使用模型进行预测
# -------start-------- 将四通道中代表透明通道的维度A去掉,变为4通道的图片
def preimg(img): # 图片预处理函数:
if img.mode == 'RGBA': # 实现兼容RGBA格式的图片信息
ch = 4
print('ch',ch)
a = np.asarray(img)[:,:,:3]
img = Image.fromarray(a)
return img
im = preimg(Image.open('models_2/code_01/book.png')) # 载入图片
transforms_img = transform(im) # 调整图片大小
inputimg = transforms_img.unsqueeze(0) # 增加批次维度
# -------end-------- 将四通道中代表透明通道的维度A去掉,变为4通道的图片
output = model(inputimg) # 输入模型
output = F.softmax(output,dim=1) # 获取结果
# 从预测结果中取前3名
prediction_score , pred_label_idx = torch.topk(output,3)
prediction_score = prediction_score.detach().numpy()[0] # 获取结果概率
pred_label_idx = pred_label_idx.detach().numpy()[0] # 获得结果ID
predicted_label = idx_to_labels[str(pred_label_idx[0])][1]#取出标签名称
predicted_label_zh = zh_labels[pred_label_idx[0] + 1 ] #取出中文标签名称
print(' 预测结果:', predicted_label,predicted_label_zh,'预测分数:', prediction_score[0])
# 1.4 预测结果可视化
#可视化处理,创建一个1行2列的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
fig.sca(ax1) #设置第一个轴是ax1
ax1.imshow(im) #第一个子图显示原始要预测的图片
#设置第二个子图为预测的结果,按概率取前3名
barlist = ax2.bar(range(3), [i for i in prediction_score])
barlist[0].set_color('g') #颜色设置为绿色
#预测结果前3名的柱状图
plt.sca(ax2)
plt.ylim([0, 1.1])
#竖直显示Top3的标签
plt.xticks(range(3), [idx_to_labels[str(i)][1][:15] for i in pred_label_idx ], rotation='vertical')
fig.subplots_adjust(bottom=0.2) #调整第二个子图的位置
plt.show() #显示图像