MATLAB官方深度学习入门教程
MATLAB官方深度学习入门教程
- 使用预训练网络
-
- AlexNet
- 预测
- 管理图像数据集合
-
- 图像数据存储
- 准备输入图像并处理
- 迁移学习
-
- 准备训练数据
- 数据组织
- 数据增强
- 修改网络
- 执行训练
- 评估网络
使用预训练网络

AlexNet
%加载预定义的alexnet网络
deepnet=alexnet;
%预测输出图像,利用classify函数
%classify 函数默认输出网络打分最高的类。您可以使用 classify 的另一个输出参数来获得所有类的预测分数
%pred = classify(net,img)
pred1=classify( deepnet,img1)
pred2=classify(deepnet,img2)
pred3=classify(deepnet,img3)


%查看层属性
ly=deepnet.Layers
%索引层
%索引第一层
inlayer=ly(1)
%第一层大小
insz=inlayer.InputSize
%最后一层
outlayer=ly(end)
%输出层的 Classes 属性给出了训练的网络可预测的类别名称。
categorynames=outlayer.Classes
预测

%classify 函数默认输出网络打分最高的类。您可以使用 classify 的另一个输出参数来获得所有类的预测分数
%[pred,scrs] = classify(net,img)
[pred,scores]=classify(net,img)
pred;
max(scores);
%创建条形图
bar(scores)
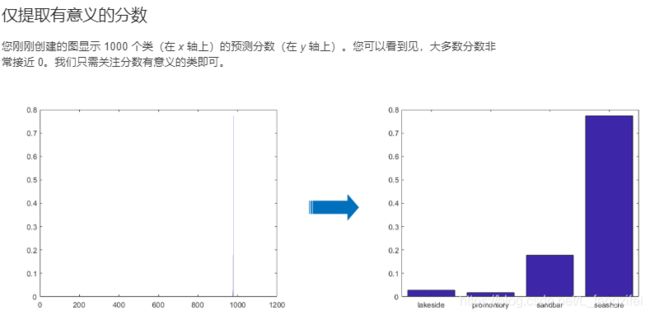
%创建一个逻辑数组 highscores,其中的值 1 (true) 对应于 scores 大于 0.01 的情况。
highscores=scores>0.01
bar(scores(highscores))
%使用逻辑索引和 xticklabels 函数为条形图添加对应的预测类名标签。类名的完整列表存储在变量 categorynames 中。
hold on
xticklabels(categorynames(highscores))
管理图像数据集合
图像数据存储
%您可以使用 imageDatastore 函数在 MATLAB 中创建一个数据存储,指定文件夹名称或文件名作为输入。您可以使用通配符(例如*)来指定多个文件。
%ds = imageDatastore('foo*.png')
%这将创建一个数据存储,该数据存储引用当前文件夹中名称以 foo 开头的所有 PNG 文件。
imds=imageDatastore('file*.jpg')
%提取文件名
fname=imds.Files
%您可以使用 read、readimage 和 readall 函数从数据存储手动导入数据:read 按顺序一次导入一个图像;readimage 导入单个特定图像;readall 将所有图像导入一个元胞数组中(每个图像位于一个单独元胞中)。
%I = readimage(ds,n)
%这会将数据存储 ds 中的第 n 个图像导入名为 I 的数组中。
%读入一整图像
img=readimage(imds,7)
%您可以在 CNN 函数(例如 classify)中使用图像数据存储来代替单个图像。
%preds = classify(net,ds)
%结果将是一个预测类数组,数据存储中的每个图像对应一个预测类。
preds=classify(net,imds)
image browser app 浏览整文件中的图像
image viewer 查看特定的图像
image tool 交互式的查看图像
准备输入图像并处理


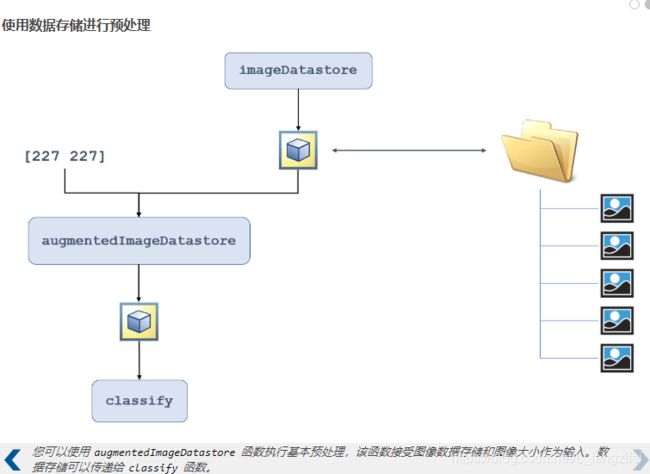
%创建数据存储
imds=imageDatastore('*jpg')
%增强的图像数据存储可以对整个集合图像执行简单的预处理。要创建此数据存储,请使用 augmentedImageDatastore 函数并将网络的图像输入大小用作输入。
%auds = augmentedImageDatastore([r c],imds)
auds=augmentedImageDatastore([227 227],imds)
%分类预测
preds=classify(net,auds)
%您可以使用 montage 函数来显示所有图像。
montage(imds)
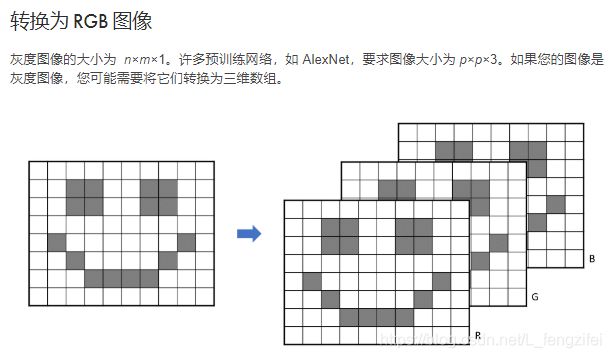
%在创建增强的图像数据存储时,可以通过设置 ColorPreprocessing 选项将这些图像转换为三维数组。
%auds = augmentedImageDatastore([n m],imds,'ColorPreprocessing','gray2rgb')
%这将复制灰度图像三次,以创建一个三维数组。如果 imgray 是表示灰度图像的矩阵,则处理后的图像将是表示彩色 (RGB) 图像的三维数组
%基于图像数据存储 imds 创建一个增强的图像数据存储。将图像预处理为 227×227×3。
auds=augmentedImageDatastore([227 227],imds,'ColorPreprocessing',"gray2rgb")
%注意与前面应该是相同的,这是估计是显示设置成了[227 227 3]

%默认情况下,imageDatastore 只在给定文件夹内查找图像文件。您可以使用 'IncludeSubfolders' 选项在给定文件夹的子文件夹中查找图像。
%ds = imageDatastore('folder','IncludeSubfolders',true)
flwrds=imageDatastore('Flowers/','IncludeSubfolders',true)
%分类预测
preds=classify(net,flwrds)
迁移学习

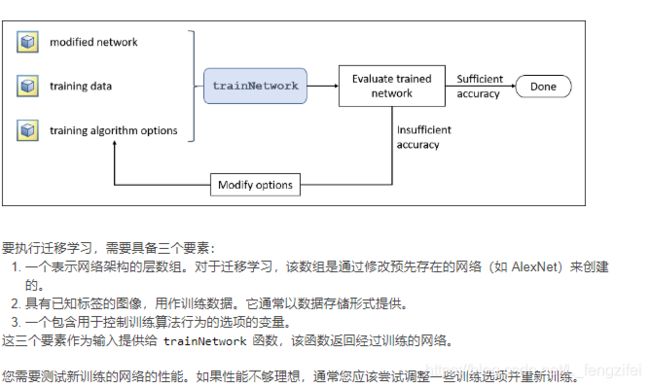
准备训练数据
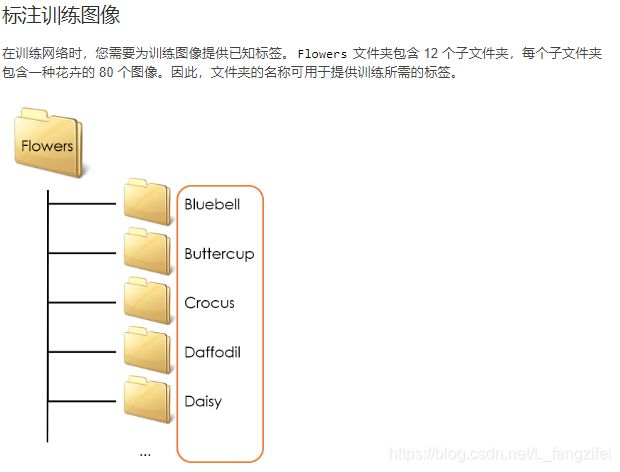
%训练所需的标签可以存储在图像数据存储的 Labels 属性中。默认情况下,Labels 属性为空。
%您可以指定 'LabelSource' 选项,让数据存储根据文件夹名称自动确定标签。
%ds = imageDatastore(folder,'IncludeSubfolders',true,'LabelSource','foldernames')
load pathToImages
flwrds = imageDatastore(pathToImages,'IncludeSubfolders',true);
flowernames = flwrds.Labels %此时为空
%重写
flwrds = imageDatastore(pathToImages,'IncludeSubfolders',true,'LabelSource',"foldernames")
%提取标签
flowernames=flwrds.Labels
数据组织
%您可以使用 splitEachLabel 函数将数据存储中的图像分成两个单独的数据存储。
%[ds1,ds2] = splitEachLabel(imds,p)
%比例 p(从 0 到 1 的值)表示 imds 中各标签对应的图像应纳入 ds1 中的比例。其余文件分配给 ds2。
%设置训练集为全部数据的60%
[flwrTrain,flwrTest]=splitEachLabel(flwrds,0.6)
%默认情况下,splitEachLabel 会保持文件有序。您可以通过添加可选的 'randomized' 标志来实现随机乱序。
%[ds1,ds2] = splitEachLabel(imds,p,'randomized')
%设置随机样本0.8
[flwrTrain,flwrTest]=splitEachLabel(flwrds,0.8,'randomized')

%当 p 是从 0 到 1 的值时,它解释为比例。图像会基于标签按比例进行拆分。您还可以指定每个标签的对应文件中要分配给 ds1 的确切数量。
%[ds1,ds2] = splitEachLabel(imds,n)
%这可确保 ds1 中的每个标签都有 n 个图像,即使这些类别并不都包含相同数量的图像。
%就是直接指定每个类别中的训练样本一致,而不是按每类样本中的比例,从而防止每类样本训练时数据量不一样
您还可以使用“验证”集来监控训练期间网络的性能。在本例中,您可以将数据分成三组:一组用于训练,一组用于训练期间的验证,一组用于最终网络的单独测试。尝试使用 splitEachLabel 将 Flowers 图像分成多组。使用多个 p 或 n 值作为输入,并请求相应数量的数据存储作为输出。
数据增强

修改网络
迁移学习时一般只需要修改最后几层,也就是分类神经网络层
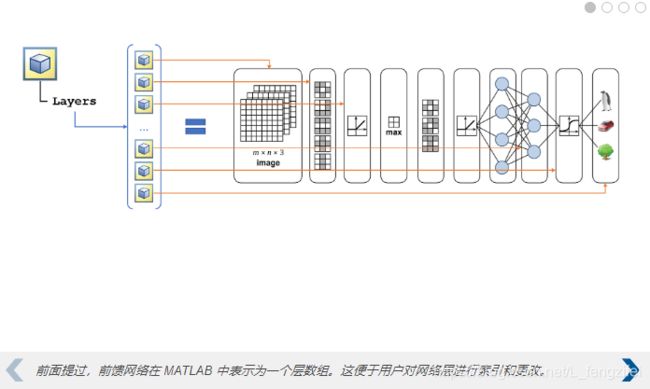



%fullyConnectedLayer 函数使用给定数量的神经元创建一个新的全连接层。
%fclayer = fullyConnectedLayer(n)
anet = alexnet;
layers = anet.Layers
fc=fullyConnectedLayer(12)
%您可以使用标准数组索引来修改层数组的单个元素。
%mylayers(n) = mynewlayer
layers(25)=fc

%您可以使用 classificationLayer 函数为图像分类网络创建一个新输出层。
%cl = classificationLayer
%您可以通过单个命令来创建新层并用新层覆盖现有层:
%mylayers(n) = classificationLayer
layers(end)=classificationLayer
更新训练算法
%您可以设置哪些选项来控制网络训练?您可以使用 trainingOptions 函数来查看所选训练算法的可用选项。
%opts = trainingOptions('sgdm')
%这会创建一个变量 opts,其中包含“动量随机梯度下降”训练算法的默认选项。
%创建一个包含 SGDM 优化器的默认训练算法的变量 opts。
opts=trainingOptions('sgdm')
还可以使用其他训练算法。您可以尝试创建包含 Adam 优化器的训练选项的变量

%您可以在 trainingOptions 函数中使用名称-值对组指定任意数量的选项设置。
%opts = trainingOptions('sgdm','Name',value)
%创建一个包含 SGDM 优化器的默认训练算法选项的变量 opts,但 InitialLearnRate 选项除外,该选项应设置为 0.001。
opts=trainingOptions('sgdm',"InitialLearnRate",0.001)
执行训练



评估网络
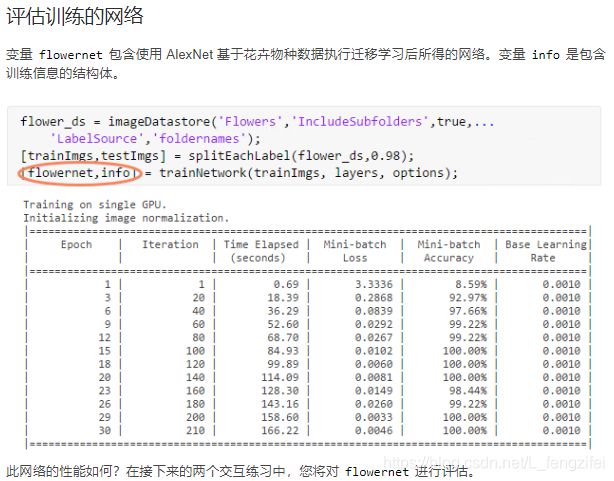
变量 info 是包含训练信息的结构体。TrainingLoss 和 TrainingAccuracy 字段包含网络在训练数据上进行每次迭代后达到的性能的记录

load pathToImages
load trainedFlowerNetwork flowernet info
%绘制训练损失图,该数据存储在 info 的 TrainingLoss 字段中
plot(info.TrainingLoss)
%创建数据存储
dsflowers = imageDatastore(pathToImages,'IncludeSubfolders',true,'LabelSource','foldernames');
[trainImgs,testImgs] = splitEachLabel(dsflowers,0.98);
%分类
flwrPreds=classify(flowernet,testImgs)
评估准确性
load pathToImages.mat
pathToImages
flwrds = imageDatastore(pathToImages,'IncludeSubfolders',true,'LabelSource','foldernames');
[trainImgs,testImgs] = splitEachLabel(flwrds,0.98);
load trainedFlowerNetwork flwrPreds
%通过提取 testImgs 数据存储的 Labels 属性,将测试图像的已知分类存储在名为 flwrActual 的变量中。
flwrActual=testImgs.Labels
numCorrect = nnz(flwrPreds==flwrActual)
fracCorrect=numCorrect/numel(flwrPreds)

%confusionchart 函数计算并显示预测分类的 confusion matrix。
%confusionchart(knownclass,predictedclass)
%混淆矩阵的 (j,k) 元素值用于统计网络将 j 类中的多少个图像预测为属于类 k。因此,对角线上的元素代表正确分类;非对角线上的元素代表误分类。
confusionchart(flwrActual,flwrPreds)
您已确定 flowernet 网络对测试数据的分类准确率为 92% (22/24)。您可以直观地看到,这两个误分类都预测为风信子,而它们实际上是番红花和鸢尾。您可以使用标准 MATLAB 数据分析技术来进一步研究这些误分类的图像。一种典型的方法是找到哪些文件包含误分类的图像,然后导入并查看这些图像(或其子集),看看是否有任何特征导致网络出现问题。
请注意,此示例所用训练图像与测试图像之比远高于实际情况中通常采用的比例。这是为了减少在这些交互练习中对测试图像进行分类所需的时间。在实践中,应尽可能保留足够的测试图像,以便测试结果可以代表网络的一般行为

