sentence_transformers 语义搜索,语义相似度计算,图片内容理解,图片与文字匹配。
目录
介绍sentence_transformers 的实战代码:
语义相似度计算:
语义搜索
句子聚类,相似句子聚类
图片内容理解:图片与句子做匹配
介绍sentence_transformers 的实战代码:
SBERT官方帮助文档:www.sbert.net
sentence-transformer GitHub:https://github.com/UKPLab/sentence-transformers
Huggingface上预训练模型地址:https://huggingface.co/sentence-transformers
官网的介绍已经比较详细,更多具体的应用实例可以参考git上example,对于一些常用的应用,在这篇博客中也进行了整理。
sentence-transformer是基于huggingface transformers模块的,如果环境上没有sentence-transformer模块的话,只使用transformers模块同样可以使用它的预训练模型。在环境配置方面,目前的2.0版本,最好将transformers,tokenizers等相关模块都升级到最新,尤其是tokenizers,如果不升级的话在创建Tokenizer的时候会报错。
目前sentence-transformers一共公开了98个预训练模型。
如果是对称语义搜索问题(query和answer的长度相近,例如两句话比较语义相似度)则采用https://www.sbert.net/docs/pretrained_models.html#sentence-embedding-models中给出的预训练模型;
而如果是非对称语义搜索问题(query很短,但是需要检索出的answer是一篇比较长的文档),则采用https://www.sbert.net/docs/pretrained-models/msmarco-v3.html中给出的模型。
语义相似度计算:
模型自动下载,并在/root/.cache下创建缓存
model = SentenceTransformer('paraphrase-MiniLM-L12-v2')
model= SentenceTransformer('path-to-your-pretrained-model/paraphrase-MiniLM-L12-v2/')
如果是想加载本地的预训练模型,则类似于huggingface的from_pretrained方法,把输入参数换成本地模型的路径
我们使用的是 model = SentenceTransformer('paraphrase-MiniLM-L12-v2') 自动可以下载
from sentence_transformers import SentenceTransformer, util
# 模型自动下载,并在/root/.cache下创建缓存
model = SentenceTransformer('paraphrase-MiniLM-L12-v2')
# model= SentenceTransformer('path-to-your-pretrained-model/paraphrase-MiniLM-L12-v2/')
# 如果是想加载本地的预训练模型,则类似于huggingface的from_pretrained方法,把输入参数换成本地模型的路径
# 计算编码
sentence1 = '今天吃了苹果不错啊'
sentence2 = '前天吃了橘子很好吃'
sentence3 = '点个关注谢谢!!!'
embedding1 = model.encode(sentence1, convert_to_tensor=True)
embedding2 = model.encode(sentence2, convert_to_tensor=True)
embedding3 = model.encode(sentence3, convert_to_tensor=True)
# 计算语义相似度
cosine_score1_2 = util.pytorch_cos_sim(embedding1, embedding2)
cosine_score1_3 = util.pytorch_cos_sim(embedding1, embedding3)
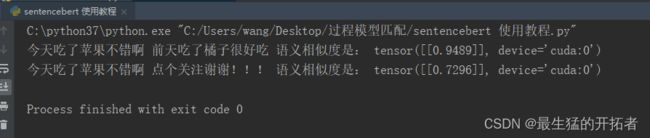
print(sentence1,sentence2,"语义相似度是:",cosine_score1_2)
print(sentence1,sentence3,"语义相似度是:",cosine_score1_3)结果:
今天吃了苹果不错啊 前天吃了橘子很好吃 语义相似度是: tensor([[0.9489]], device='cuda:0')
今天吃了苹果不错啊 点个关注谢谢!!! 语义相似度是: tensor([[0.7296]], device='cuda:0')
语义搜索
可以使用上边的句子进行 就是计算最相似的语句,可以自行编写
句子聚类,相似句子聚类
使用 kmeans 聚类
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
from random import sample
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from pylab import mpl
import warnings
warnings.filterwarnings("ignore")
import numpy as np
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
embedder = SentenceTransformer('paraphrase-MiniLM-L6-v2')
corpus = ['我喜欢吃苹果.',
'我吃了梨子',
'点个关注把',
'点个赞啊',
'楼主大帅哥',
'楼主对象大美女',
]
corpus_embeddings = embedder.encode(corpus)
tsne_model = TSNE(perplexity=2, n_components=2, init='pca', n_iter=2500, random_state=23)
# perplexity: 默认为30,数据集越大,需要参数值越大,建议值位5-50 , n_components=2 默认为2,嵌入空间的维度(嵌入空间的意思就是结果空间),别的参数估计不重要
new_values = tsne_model.fit_transform(corpus_embeddings)
x = []
y = []
for value in new_values:
x.append(value[0])
y.append(value[1])
plt.figure(figsize=(5,5)) # 定义画布大小
for i in range(len(x)):
plt.scatter(x[i], y[i], c='b')
plt.annotate(corpus[i],
xy=(x[i], y[i]),
xytext=(5, 2),
color='black', # 节点标签上的颜色
textcoords='offset points',
ha='right',
va='bottom')
plt.title("句子聚类显示图")
# plt.savefig("标准问图_weight.png")
plt.show()
num_clusters = 3
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i+1)
print(cluster)
print("")如图:相似的句子句子的表示是相近的


图片内容理解:图片与句子做匹配
首先给出图: 和 三个文字内容
'翘臀美女', '汽车', '飞机'
让图片与这三个内容做匹配 找到最相似的描述

from sentence_transformers import SentenceTransformer, util
from PIL import Image
#Load CLIP model
model = SentenceTransformer('clip-ViT-B-32')
#Encode an image:
img_emb = model.encode(Image.open('翘臀.jpg'))
#Encode text descriptions
text_emb = model.encode(['翘臀美女', '汽车', '飞机'])
#Compute cosine similarities
cos_scores = util.cos_sim(img_emb, text_emb)
print(['翘臀美女', '汽车', '飞机'])
print(cos_scores[0])可以看到 翘臀美女 的分数最高匹配到了这个图片

总而言之,sentence-transformer是一个非常好用的编码器,并且上述所用功能的原理都非常容易理解,在此基础上也可以根据自己的实际应用场景去开发一些具有创造性的功能。
参考:NLP实践——基于SBERT的语义搜索,语义相似度计算,SimCSE、GenQ等无监督训练_常鸿宇的博客-CSDN博客