pytorch 实现人脸检测与识别
pytorch + opencv 实现人脸检测与识别
- 准备工作
- 人脸检测
-
- opencv实现人脸检测
- 卷积神经网络 CNN 实现人脸检测
-
- 数据导入
- CNN模型训练
- 人脸检测
- 存在的问题
- 人脸识别
-
- 获取数据
- 模型训练
- 识别
- 存在的问题
- 总结
最近阅读了《Dive into Deep Learning》(动手学深度学习)这本书,根据所学的知识动手完成了人脸检测与识别。这篇博客主要是记录下自己在完成的过程中所用到的东西,以及遇到的问题。最后的效果如下图所示。

准备工作
- 环境配置
这里主要使用 pytorch 和 opencv - 人脸数据
可通过 benchmark 进行下载,也可下载我使用的人脸数据,链接如下。
链接:https://pan.baidu.com/s/1nwVy8Y7dvNFt4qWPQpaxfQ
提取码:face
人脸检测
人脸检测可通过opencv自带人脸特征数据进行检测,也可通过卷积神经网络进行检测。
opencv实现人脸检测
通过 opencv 实现人脸检测的代码很简单,只需要指定使用的人脸特征数据的路径即可。我使用的是 haarcascade_frontalface_alt2.xml。由于 opencv 读取的图片格式是BGR,可以将其转换为灰度图,提高人脸检测的速度。
import cv2
CADES_PATH = 'opencv-4.5.2/data/haarcascades_cuda/haarcascade_frontalface_alt2.xml'
def face_detect(img_path):
color = (0, 255, 0)
img_bgr = cv2.imread(img_path)
classifier = cv2.CascadeClassifier(CADES_PATH)
img_gray = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2GRAY)
facerects = classifier.detectMultiScale(img_gray)
if len(facerects) > 0:
for rect in facerects:
x, y, w, h = rect
if w > 200:
cv2.rectangle(img_bgr, (x, y), (x + w, y + h), color, 2)
cv2.imwrite('detect.png', img_bgr)
if __name__ == '__main__':
face_detect('wx.jpg')
最后通过 opencv 进行人脸检测的效果如下。

卷积神经网络 CNN 实现人脸检测
通过卷积神经网络进行人脸检测主要包括三个步骤:
1.将人脸数据读取成 pytorch 可训练的 tensor 张量类型,并对数据进行预处理;
2.搭建一个二分类网络,对人脸数据进行训练;
3.利用训练好的网络,对特定图片实现人脸检测任务;
数据导入
1.为每张图片建立标签,由代码中的 find_label(title) 函数实现;
2.将数据集每张图片的路径与其标签读取到一个列表里, 由 get_data(data_path) 函数实现;
3.通过 opencv 读取图片,读出来的数据类型是 numpy.ndarray;
def Myloader(path):
return cv2.imread(path)
4.通过transforms 模块对图片数据进行预处理,由于 opencv 读出来的数据类型是 numpy.ndarray,而 transforms 模块只能对 PIL 和 tensor 格式的数据进行处理,首先要将其转换成 PILImage;然后将图片统一成 224*224 的大小;最后归一化到 [-1:1];
transform = transforms.Compose([
transforms.ToPILImage(),
# transforms.RandomHorizontalFlip(p=0.5),
# transforms.RandomVerticalFlip(p=0.5),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化
])
5.重写 torch.utils.data.Dataset 的__getitem__(self, item) 方法,最后通过 torch.utils.data.DataLoader 将数据加载成迭代对象。
最终脚本文件:py_dataloader.py
import os
import cv2
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
def get_labels(labels):
"""Return text labels for the dataset."""
text_labels = ['face', 'nonface']
return [text_labels[int(i)] for i in labels]
def Myloader(path):
return cv2.imread(path)
def get_data(data_path):
data = []
for file in os.listdir(data_path):
label = find_label(file)
image_path = os.path.join(data_path, file)
data.append([image_path, label])
return data
def find_label(title):
if 'faceimage' in title:
return 0
else:
return 1
class MyDataset(Dataset):
def __init__(self, data, transform, loader):
self.data = data
self.transform = transform
self.loader = loader
def __getitem__(self, item):
img_path, label = self.data[item]
img = self.loader(img_path)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
def load_data(batch_size):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化
])
path1 = 'face_data/training_data/faces'
data1 = get_data(path1)
path2 = 'face_data/training_data/1'
data2 = get_data(path2)
path3 = 'face_data/testing_data/faces'
data3 = get_data(path3)
path4 = 'face_data/testing_data/1'
data4 = get_data(path4)
train_data = data1 + data2
train = MyDataset(train_data, transform=transform, loader=Myloader)
test_data = data3 + data4
test = MyDataset(test_data, transform=transform, loader=Myloader)
train_data = DataLoader(dataset=train, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
test_data = DataLoader(dataset=test, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
return train_data, test_data
CNN模型训练
我这里使用的是残差网络,因为残差块的输入可以通过层间的残余连接更快地向前传播,可以训练出一个有效的深层神经网络,残差块的结构如下图所示。

最后我选择了 resnet18 模型,该模型使用 4 个由残差块组成的模块,每个模块有 4 个卷积层(不包括恒等映射的1×1卷积层),加上第一个7×7卷积层和最后一个全连接层,共有 18 层。具体的 pytorch 实现如下。
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 2))
最终模型训练的 jupyter notebook 文件:py_face_recognition.ipynb。采用的是随机梯度下降算法(SGD),也可采用其他算法(如 Adam),损失函数采用的交叉熵损失。
import torch
from torch import nn
from d2l import torch as d2l
from py_dataloader import load_data
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU (defined in Chapter 6)."""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 2))
lr, num_epochs = 0.1, 10
train_iter, test_iter = load_data(128)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
torch.save(net.state_dict(), 'face_SGD_224_resnet18.params')
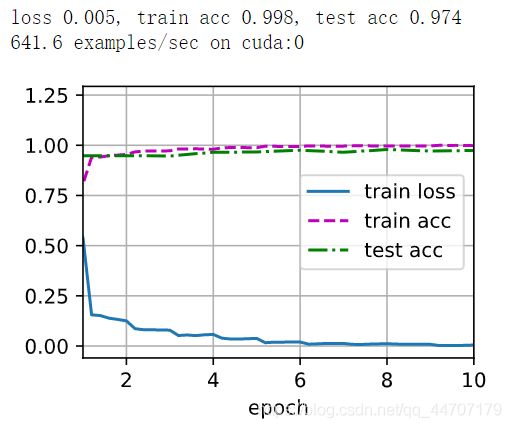
最后的训练结果如图
人脸检测
创建一个名为 resnet18.py 的文件,方便调用训练好的模型。
from torch import nn
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
def get_net():
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 2))
return net
def get_net_lf():
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 3))
return net
最后就是利用训练好的 resnet18 进行人脸检测,这里涉及到三个思想。
1.由于我们训练好的网络 resnet18 的输入是 224×224 的人脸,但是实际图片中的人脸大小不一定正好是 224×224 的,所以要对图片大小进行缩放变换;
2.然后将一个大小为 224×224 的矩形框在缩放后的图片上从左到右,从上到下滑动,计算每个位置存在人脸的概率;
3.最后得到的人脸框,可能不止一个,这是需要使用一个非极大值抑制的算法,将多余的框去掉,保留最好的。
最后的代码如下
import torch
import cv2
from torchvision import transforms
import numpy as np
from resnet18 import get_net
from d2l import torch as d2l
DEVICE = d2l.try_gpu() # 使用GPU计算
PARAMS_PATH = 'face_SGD_224_resnet18-3.params' # 网络参数
def face_detect(img_file, device=DEVICE):
gpu()
net = get_net()
net.load_state_dict(torch.load(PARAMS_PATH))
net.to(device)
scales = [] # 缩放变换比例
factor = 0.79
img = cv2.imread(img_file)
largest = min(2, 4000 / max(img.shape[0:2]))
scale = largest
mind = largest * min(img.shape[0:2])
while mind >= 224:
scales.append(scale)
scale *= factor
mind *= factor
total_box = []
for scale in scales:
scale_img = cv2.resize(img, (int(img.shape[1] * scale), int(img.shape[0] * scale)))
for box_img, box_pos in box_move(scale_img):
box_img = trans_form(box_img)
box_img = box_img.to(device)
prob = torch.softmax(net(box_img), dim=1)[0][0].data
if prob > 0.92:
x0, y0, x1, y1 = box_pos
x0 = int(x0 / scale)
y0 = int(y0 / scale)
x1 = int(x1 / scale)
y1 = int(y1 / scale)
total_box.append([x0, y0, x1, y1, prob])
total_box = nms(total_box)
for box in total_box:
x0, y0, x1, y1, prob = box
cv2.rectangle(img, (x0, y0), (x1, y1), (0, 255, 0), 2)
cv2.putText(img, str(prob.item()), (x0, y0), cv2.FONT_HERSHEY_PLAIN, 2, (0, 255, 0), 2)
cv2.imwrite('detect.png', img)
return 0
def box_move(img, row_stride=16, col_stride=16):
"""窗口滑动"""
h, w = img.shape[0:2]
cellsize = 224
row = int((w - cellsize) / row_stride) + 1
col = int((h - cellsize) / col_stride) + 1
for i in range(col):
for j in range(row):
box_pos = (j*row_stride, i*col_stride, j*row_stride+cellsize, i*col_stride+cellsize)
box_img = img[i*col_stride:i*col_stride+cellsize, j*row_stride:j*row_stride+cellsize]
yield box_img, box_pos
def trans_form(img):
transform = transforms.Compose([transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
img = transform(img)
img = img.unsqueeze(0)
return img
def nms(bounding_boxes, Nt=0.70):
"""非极大值抑制"""
if len(bounding_boxes) == 0:
return []
bboxes = np.array(bounding_boxes)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
scores = bboxes[:, 4]
areas = (x2 - x1) * (y2 - y1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序
order = np.argsort(scores)
picked_boxes = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11)
h = np.maximum(0.0, y22 - y11)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ious = intersection / np.minimum(areas[index], areas[order[:-1]])
left = np.where(ious < Nt)
order = order[left]
return picked_boxes
def gpu():
"""GPU预热"""
x = torch.randn(size=(100, 100), device=DEVICE)
for i in range(10):
torch.mm(x, x)
if __name__ == '__main__':
face_detect('wx.jpg')
实现的效果如图,可以看到实现效果比 opencv 要好,将两个人脸都检测到了。

存在的问题
通过 CNN 计算进行人脸检测比 opencv 慢很多,不知如何将缩放后的图片直接送入神经网络进行计算。
人脸识别
获取数据
想要进行人脸识别,首先要准备不同人的人脸数据,可以通过 opencv 读取电脑的摄像头实现。
import cv2
CADES_PATH = 'opencv-4.5.2/data/haarcascades_cuda/haarcascade_frontalface_alt2.xml'
def video_demo():
color = (0, 255, 0)
# 0是代表摄像头编号,只有一个的话默认为0
capture = cv2.VideoCapture(0, cv2.CAP_DSHOW)
classifier = cv2.CascadeClassifier(CADES_PATH)
i = 0
while True:
ref, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faceRects = classifier.detectMultiScale(gray)
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
if w > 200:
img = frame[y-10:y + h, x-10:x + w]
cv2.imwrite('data/train_data/yz_data/{}.png'.format(str(i)), img)
i += 1
# 显示图像
cv2.imshow('ss', frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
video_demo()
准备好数据后,接下来就是数据处理与导入,这与人脸检测部分一致,唯一不同就是图片标签的设置。
import os
from torchvision import transforms
from torch.utils.data import DataLoader
from py_dataloader import MyDataset, Myloader
def get_data(data_path):
data = []
for file in os.listdir(data_path):
label = find_label(data_path)
image_path = os.path.join(data_path, file)
data.append([image_path, label])
return data
def find_label(title):
if 'lf_data' in title:
return 2
elif 'syz_data' in title:
return 1
elif 'yz_data' in title:
return 0
def load_data(batch_size):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
path1 = 'data/train_data/lf_data'
data1 = get_data(path1)
path2 = 'data/train_data/syz_data'
data2 = get_data(path2)
path3 = 'data/train_data/yz_data'
data3 = get_data(path3)
path4 = 'data/test_data/lf_data'
data4 = get_data(path4)
path5 = 'data/test_data/syz_data'
data5 = get_data(path5)
path6 = 'data/test_data/yz_data'
data6 = get_data(path6)
train_data = data1 + data2 + data3
train = MyDataset(train_data, transform=transform, loader=Myloader)
test_data = data4 + data5 + data6
test = MyDataset(test_data, transform=transform, loader=Myloader)
train_data = DataLoader(dataset=train, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
test_data = DataLoader(dataset=test, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
return train_data, test_data
模型训练
这里我使用的也是 resnet18 网络,所以网路结构与训练的代码都与人脸检测部分一致,需要改动就是,网络结构最后一层的线性网络,我这里准备了三个人的数据,所以是3分类。
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 3))
识别
最后的识别实现比较简单,只需将 opencv 从摄像头读取到的人脸送入神经网络进行计算,就能知道这属于谁。
import cv2
import torch
from d2l import torch as d2l
from resnet18 import get_net_lf
from face_detect import gpu, DEVICE
from torchvision import transforms
CADES_PATH = 'opencv-4.5.2/data/haarcascades_cuda/haarcascade_frontalface_alt2.xml'
PARAMS_PATH = 'lf_SGD_224_resnet-3.params'
def trans_form(img):
transform = transforms.Compose([transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img = transform(img)
img = img.unsqueeze(0)
return img
def get_labels(label):
"""Return text labels for the dataset."""
text_labels = ['yz', 'syz', 'lf']
return text_labels[int(label)]
def video_demo():
gpu() # GPU预热
net = get_net_lf()
net.load_state_dict(torch.load(PARAMS_PATH))
net.to(DEVICE)
color = (0, 255, 0)
# 0是代表摄像头编号,只有一个的话默认为0
capture = cv2.VideoCapture(0, cv2.CAP_DSHOW)
classifier = cv2.CascadeClassifier(CADES_PATH)
while True:
ref, frame = capture.read()
img_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
faceRects = classifier.detectMultiScale(img_rgb)
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
if w > 200:
img = frame[y-10 : y+h, x-10 : x+w]
trans_img = trans_form(img)
trans_img = trans_img.to(DEVICE)
label = d2l.argmax(net(trans_img), axis=1)
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
cv2.putText(frame, str(get_labels(label)), (x + 100, y - 10), cv2.FONT_HERSHEY_PLAIN, 2, (0, 255, 0), 2)
# 显示图像
cv2.imshow('ss', frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
video_demo()
最后实现的效果就如开头所示。
存在的问题
1.模型的损失函数下降太快,导致模型在测试集的表现不好,不知道是不是准备的数据太少了;
2.不管是谁,标签设置为 0 的数据,在训练后,准确性是最高的。
总结
虽然最后还是完成人脸检测和识别的效果,但是还存在一些问题。希望这篇博客能给各位一些帮助,当然也希望有大佬能帮我解决心中疑惑。