【 YOLO系列v1-v5 原理+代码解读+项目实践】
【 YOLO系列v1-v5 原理+代码解读+项目实践】
- 文前白话
-
- 深度学习目标检测基础知识
- 原理解析
-
- YOLO-V1
- YOLO-V2
- YOLO-V2增加的细节
- YOLO-V3
- YOLO-V3 改进细节
- YOLO-V4
- YOLO-V4 改进细节
- YOLO-V5
- 附录资料链接
-
-
- YOLO系列论文:
- 代码:
- 数据集下载:
-
- 源码解析
- 项目实践
文前白话
YOLO-(You Only Look Once) 是目前更加倾向于检测速度的检测方法,很多工程上得以应用,可满足实时性的检测。本篇系列的yolo学习从yolo1-yolo5,知晓基本的原理以及相关的代码解析。了解yolo1到yolo5都是不断被改进的过程。并附上相关的论文及相关代码链接,以备查看。
深度学习目标检测基础知识
深度学习经典检测算法的两类
- one-stage (单阶段) : YOLO 系列
一个cnn网络来提取特征,做个回归就结束了,输出结果。
- two-stage( 双阶段 ) : Faster-Rcnn 、 Mask-Rcnn 等系列
多了一个rpn(建议网络),添加预选框,将预选的结果再输送给下一步。
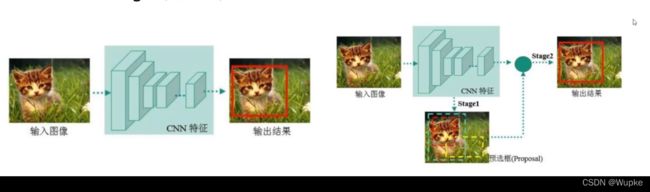
优缺点对比:
one-stage:
核心优势:速度快,适合做实时检测任务。
缺点: 通常检测效果不太好。
可以参看图的对比数据:
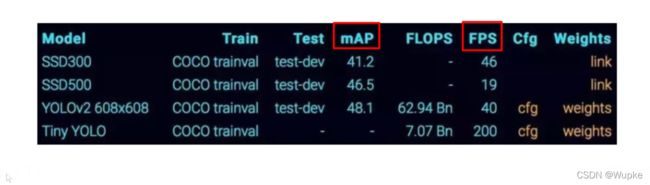
评价算法一般就看两个指标:
- FPS : 越大,速度越快
- mAP : 越大,检测效果越好
two - stage:
- 速度通常较慢(大概在5-6 FPS),但是检测的效果比较好。
- 实用的框架 MaskRcnn ,有兴趣可以了解。其结构框图如下:
检测的指标概念
-
MAP(Mean Average Precision)指标:综合衡量检测效果, 对求得的平均精确度(AveragePrecision),再对所有类别的平均精确度再求平均(mean Average Precision)
-
精度:预测值与真实值之间的比值
-
recall : 一张图中的检测目标存在多个时候,是否都检测到了
-
精度与 recall 是矛盾的存在
-
IOU:交集与并集的比值。如下图所示:

-
IOU 越高,效果越好。
-
准确率(Precision):
-
召回率(Recall),也叫查全率:
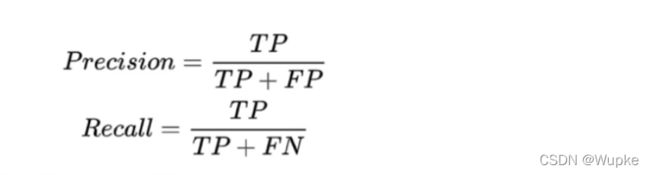
- 情景举例:

理解:TP、 FP(分开字母好理解:判断正误,判断为正例还是负例)
TP: (T,P)—> (判断正确,正例):正确判断为正例 (20)
FP: (F,P)—> (判断错误,正例):错误判断为正例 (30)
FN:(F,N)—> (判断错误,负例):错误判断为负例 (0)
TN:(T,N)—> (判断正确,负例):正确判断为负例 (100-50 = 50)
- 基于置信度阈值来计算时:

- PR 图: 考虑从0-1所有置信度阈值的预测值关系图
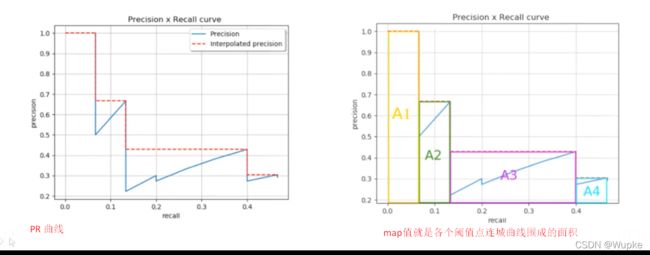
- MAP 值就是 PR 曲线围成的下方区域 的面积。(MAP实际就是综合考虑了精度和召回率的综合结果)
- 这里求解面积时候,取每一块区域的最大值。
原理解析
YOLO-V1
-
经典的 one- stage 方法:将检测问题转化为回归问题,只用一个CNN结构,广泛应用于视频进实时检测。
-
2015左右的网络检测参数对比:
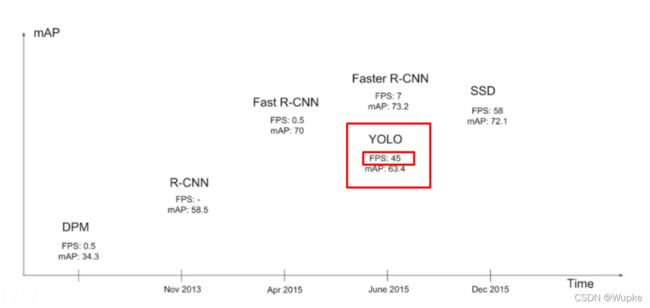
-
核心思想:
-
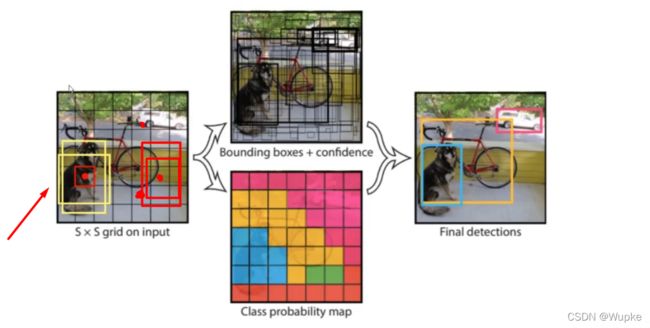
每一个点,产生两种候选框,如下图,然后做一个微调;并不是所有的候选框都做微调,只有置信度达到一定水平的候选框,有可能是检测的物体,才做微调,对IOU数值大的那个候选框,计算出:x,y,w,h 映射到原始图像中,预测结果图。
- YOLO-V1的网络架构:
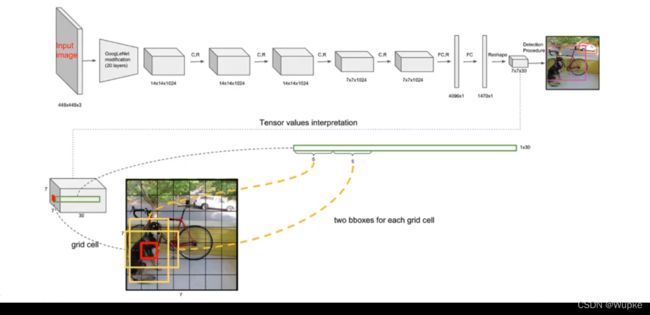
- 输入图像大小: 448×448×3
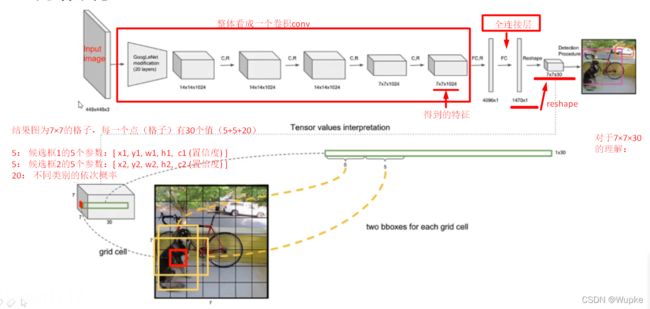
- 过程中的参数含义:
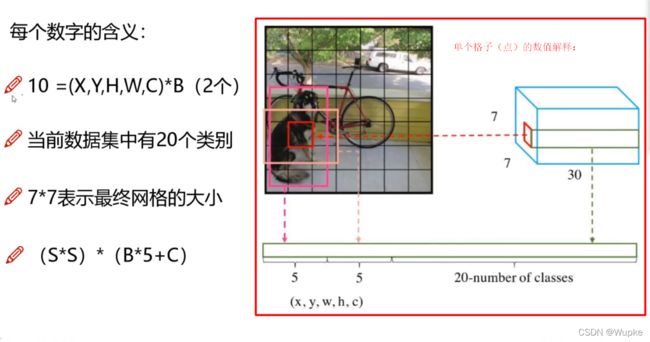
- 损失函数:
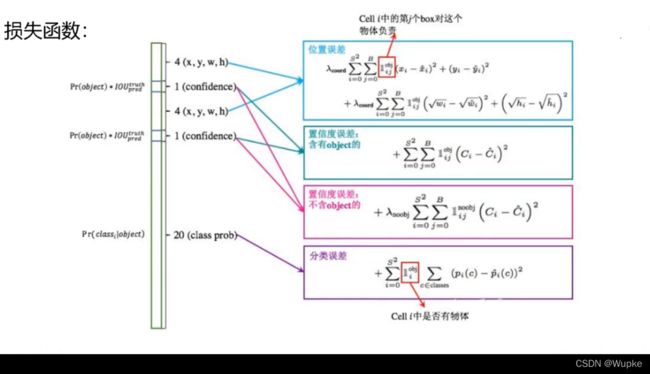
- ①涉及的预测的位置参数值与对应的损失函数描述:
x, y, w, h :
对应的损失函数要尽量减小预测值与真实值之间的差距。
函数公式中 x, y 是使用 平方差值 来描述,而对于 w, h 使用了根号,是为了检测小物体时候,减小偏移量小的时候对于小物体的的敏感度。

-
损失函数中的系数,是相应的权重。
-
②关于置信度的损失函数(与类别有关):
平方置信度与真实值之间的差异(分为不同的情况讨论:前景(要检测的物体)、背景(无目标处))- ③分类相关的损失函数:交叉熵损失函数
补充概念:
- 非极大值抑制:
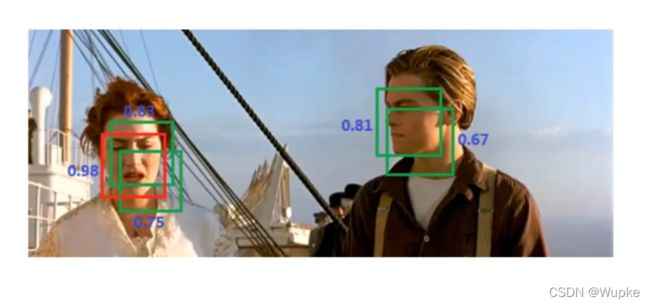
- 只取出保留 IOU 数值最大的框。
- YOLO-V1小结
- YOLO-V1 整体网络架构简单,检测速度快。
- 网络中,每个 cell 只预测一个类别,若物体的位置重合时,检测困难。
- 每个点只有两个候选框,小物体考虑的少,检测效果一般,多标签检测效果不好。
YOLO-V2
基于yolo-v1改进的细节,以及对应的改进后的map数值的提升对比:
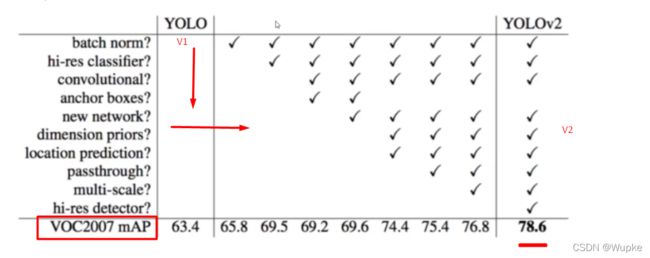
YOLO-V2增加的细节
-
1、卷积后加入 Batch Normalization (当前网络的标配)
-
网络的每一层的输入都做了归一化,收敛相对更加容易,处理后整体的网络提升2%的map值。
-
2、 采用更大的分辨率
-
V1训练时候采用的是224×224,测试时候采用448×448;
-
V2训练时候额外进行了10次 448×448 的微调,使得分类器的 mAP 提升了4%。

-
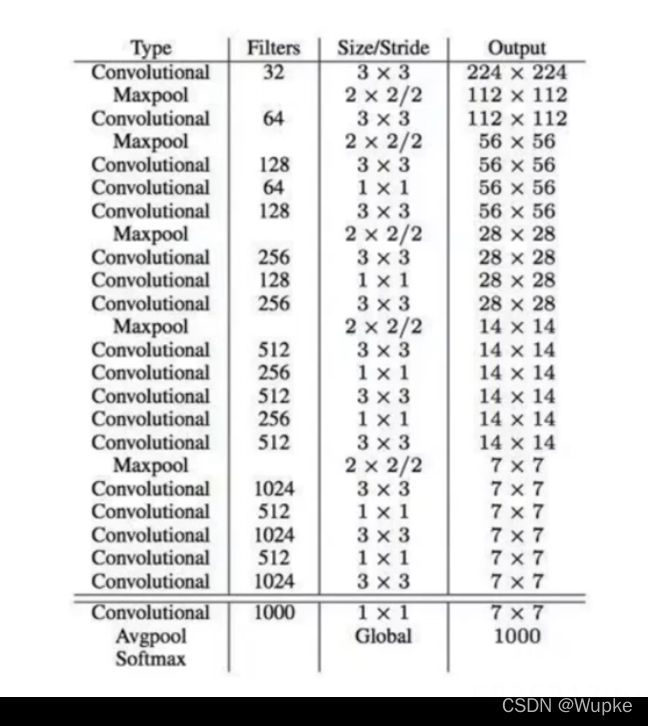
3、网络架构的改变
-
V2 使用DarkNet-19 , 实际的输入为416 × 416 ,没有全连接(FC)层 ,5次降采样(2**5=32)也就是把原始图片进行缩放32倍(w/32、h/32),得到的特征图结果(13×13);【全连接层容易过拟合,参数多,训练速度慢】
-
类似于V1中,直接把提取到的7×7×1024的图征图转为7×7×30 的结果图
-
使用的 1×1 的卷积,节省了很多参数。
-
一共19个卷积层。
-
输入224 × 224
-
4、聚类提取先验框
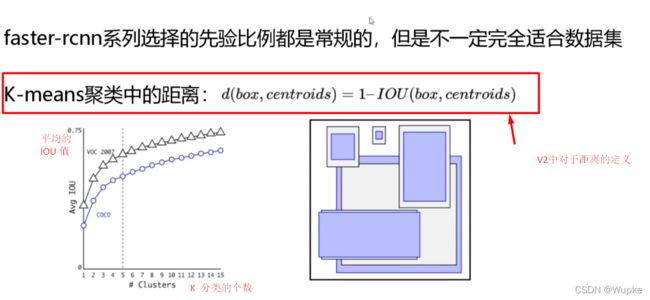
-
依据分类图,折中选取 K = 5 的情况,后续的 IOU 提升不明显。
-
所以,V2 中每个点 ( cell )有5个框,对应的 w,h 数值 就是个自举类中心点的w,h数值。
-
聚类图如上所示。
-
5、引入 Anchor Box
-
通过引入Anchor boxes, 使得预测的 box 数量更多(13×13 × n)
-
与faster-rcnn 系列不同的是,先验框不是直接按照长宽固定比给定的。
-
效果:

- 6、直接预测相对位置(Directed Located Prediction)
- V2中没有直接使用偏移量与先验框相加的方法(可能导致收敛问题,模型不稳定,训练飘离原图范围),而是选择相对grid cell 的偏移量
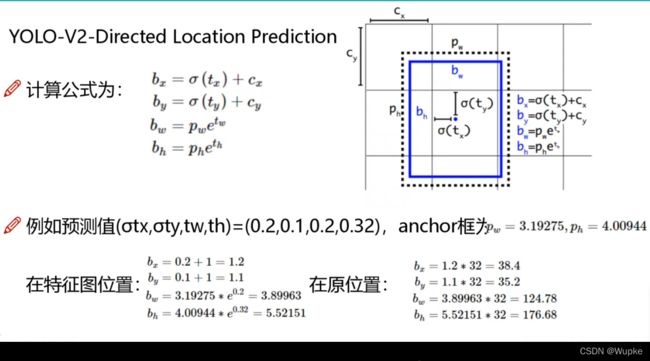
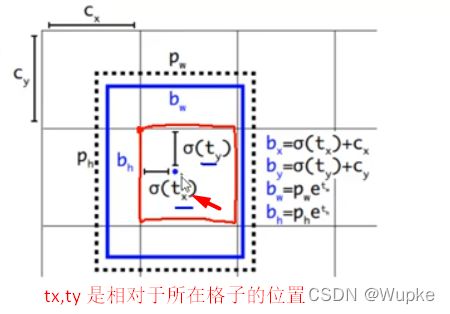
黑色框为先验框, 预测值:(tx)、(ty)、(tw)、(th)
signoid 函数在(-∞,+∞)之间的函数值都位于(0,1)之间。
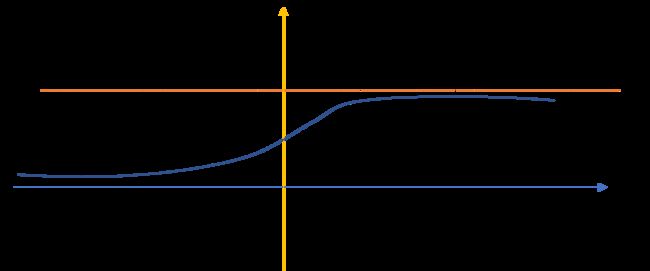
-
Cx, Cy 是中心点的实际的网格坐标位置。
-
anchor 框是基于原始图像等比例缩小的效果(原始的W,H,除以32(2**5)),Pw,Ph 是已知的。
-
再按照比例还原,就得到在原始图上的位置信息。
-
7、感受野
-
感受野的介绍:
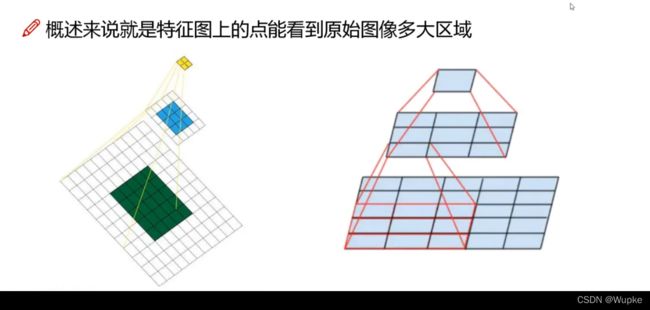
-
特征图上的点,理解为代表了原始图像上一部分区域的特征。
-
在最后一层的特征图上,一个特征图上的点,相当于原始输入图像上多大的一个区域,就是感受野的大小。
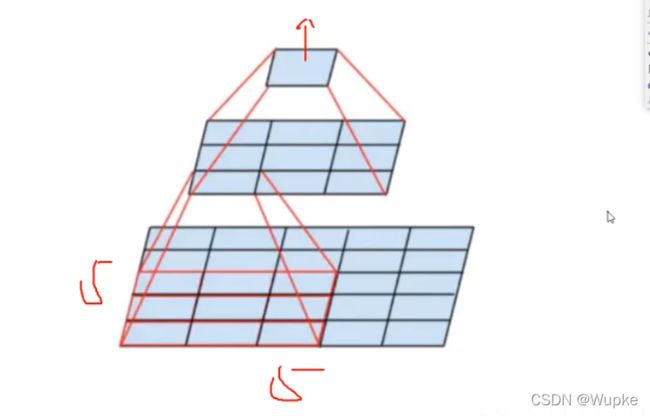
-
感受野越大,就可以涵盖原始图上比较大的物体特征(整体上的特征)。
-
理解:为啥不用大的卷积核一步到位,要用那么多小的卷积核,多次卷积:

-
8、 Fine -Graind-Featrures
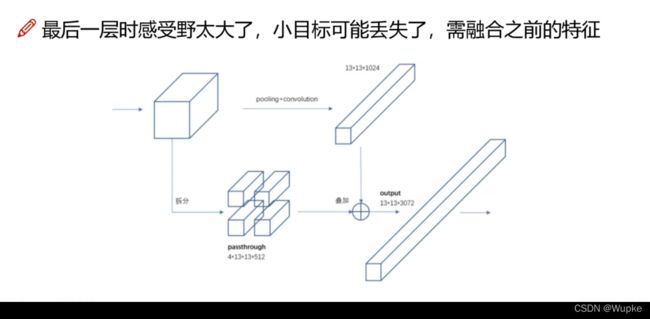
-
上图中的 13×13×3072 是怎么来的?
-
将最后一层特征图的前一层进行拆分,再融合最后一层得到的。使得小目标物体的特征不至于完全丢失。
-
9、-Multi-Scale 多尺度检测
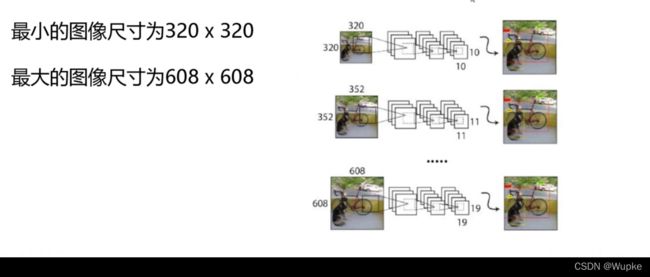
-
320, 352,608 都是可以整除 32 的 。
-
YOLO-V2小结:
-
相比于 V1 版本,检测性能更高、更快。
YOLO-V3
-
V3 版本主题的出发点是核心的网络架构,从网络架构出发,进行升级,更好的提取特征,针对于不同规模的物体(大、中、小),可以更好的检测,更适合小目标检测。
-
特征提取更加的细致,融入多持续特征图来预测不同规格的物体
-
先验框更加丰富,3种尺度,每种有 3 个规格,共 9 种
-
先验框:V1 有2种、 V2 有 5种 (聚类)
-
softmax 分类器改进,可预测多标签任务
-
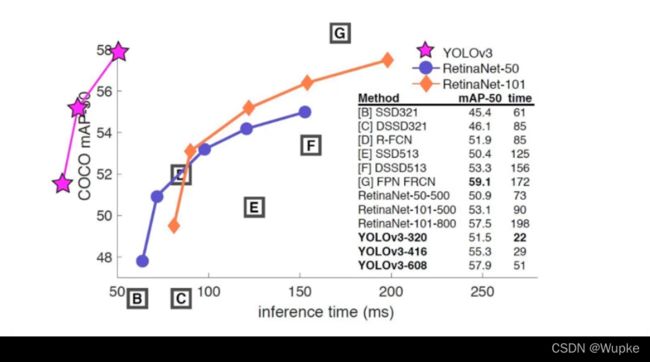
YOLO-V3 的性能于其他算法的对比示图:
YOLO-V3 改进细节
1、多尺度 (scale)
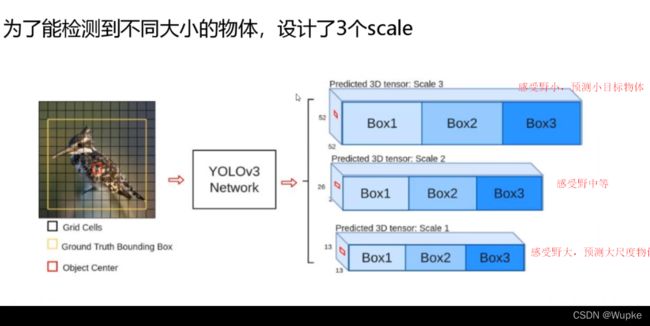
-
擅长个自的模块进行工作。
-
同时,感受野小的模块在预测的时候可以融合感受野大的特征图的信息特征,因为,感受野大的特征图包含的信息更加整体化。
-
13(老人) , 26(中年人) , 52 (年轻人) (图征图的点对应的感受野依次减小)
-
scale 变换的方法:
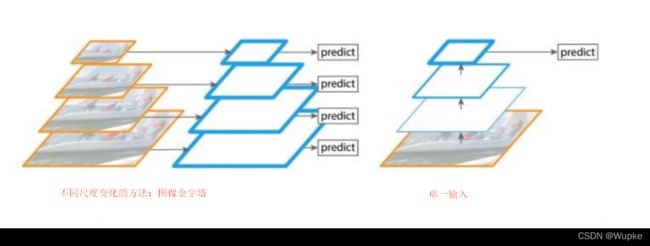
-
图像金字塔方法不适合yolo 系列, 多次输入不同尺寸,速度会慢;
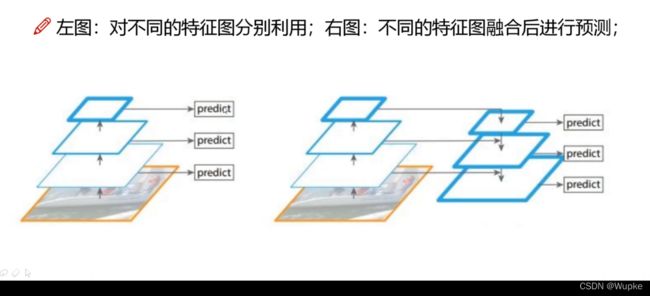
-
如何进行信息的融合 : 上采样 + 自身
-
残差连接 : 为了得到更好的特征信息
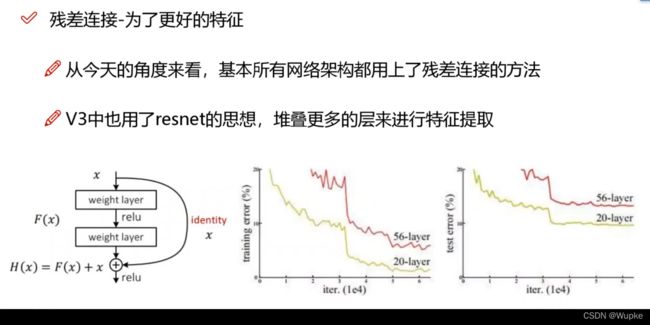
- VGG 网络中,卷积层越多,效果反而越差(实际上,卷积层越多,有效果好的,也有不好的存在)。
- 上图:经过残差处理,效果至少不比原来差:有用的卷积步骤加上,效果不好的,还是用原来的;效果好,卷积层就留着,不好,就不要了。
》》》YOLO-V3- 核心的网络架构:

-
核心网络架构的解析:
-
YOLO-V3 有三种 cell (网格)大小:13、26、52
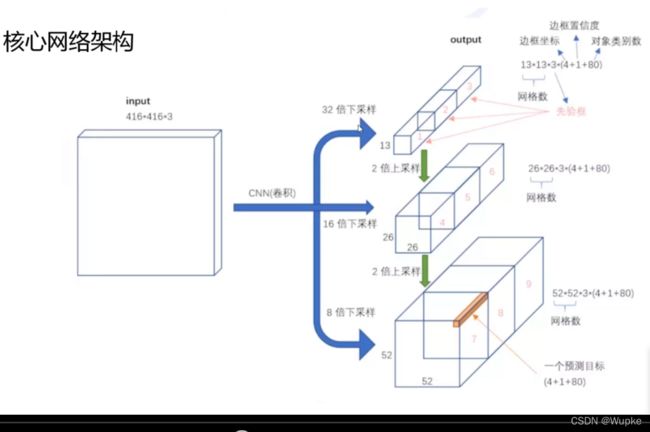
-
先验框:
-
YOLO-V3中的先验框有9中,但不是说每个点/格子(cell)都会产生9种框,而是进行了分类,依据特征图的感受野大小的不同,有针对性的进行预测。
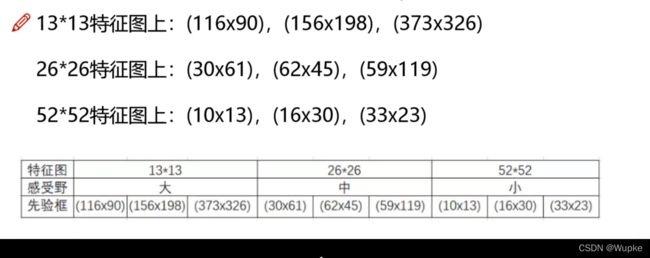
-
- 不同网格数下的先验框示例:

- 不同网格数下的先验框示例:
-
softmax 层替代
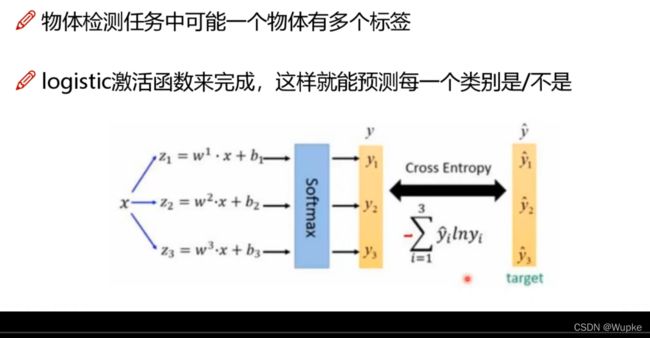
-
YOLO-V3 中对于多标签的目标,网络会对物体是不是属于某一类别分别都进行概率预测,一旦符合给定的阈值,就会将目标可能的标签全部输出。
-
YOLO-V3小结
相比于之前的两个版本,在网络结构上改进的细节上使得检测的效果更加好。
YOLO-V4
文末附有相关论文于代码地址。
-
YOLO-V4 论文中于其他网络的的参数对比:
-
V4作者变了,内容的精髓依旧。
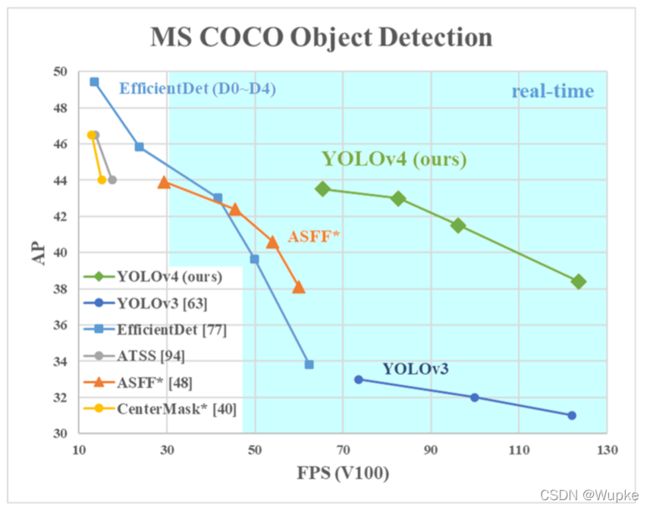
-
整体的创新改进不明显,主要是: 融合了当时多种优秀的内容进去(集百家所长),并结合许多的实验。
-
整体的网络架构:
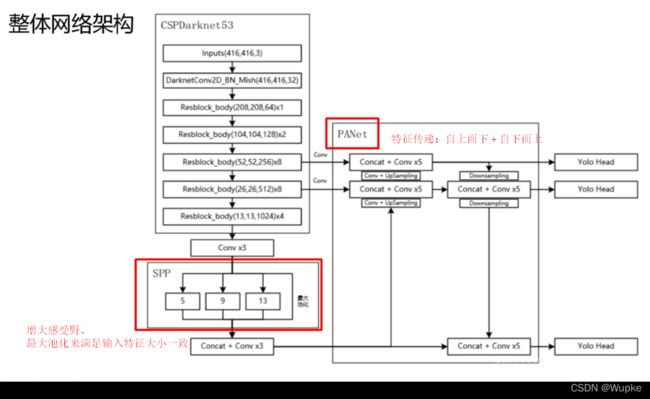
YOLO-V4 改进细节
YOLO-V4 的主要贡献:
- 单 GPU 的训练效果就很好,亲民, 个人使用也不用担心设备硬件问题
- 从数据层面和网络设计两个核心方法层面改进
- 开展 消融实验 (工作量巨大)。
- 实验也是用单 GPU 完成。
Bag of freebies (BOF)
- 只增加训练成本,但是可以显著提高检测的精度,并不影响推理速度。
- 数据增强措施:调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转等
- 网络正则化:Dropout、Dropblock等
- 类别不平衡
- 损失函数设计
在数据方面的改进:
- 1、马赛克数据增强:
调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转 - 参考其他论文处理方法:
- 图片拼接、图像随机局部遮挡、混合
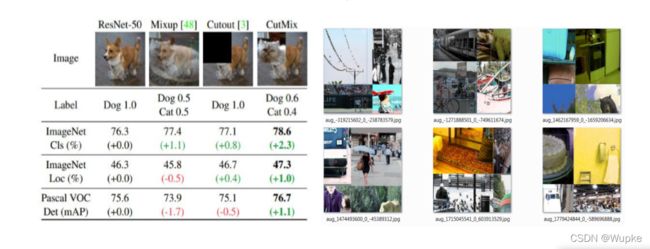
- 拼接操作,相当于 1 张顶 4 张,即是增大了bach 的大小,更适合单 GPU 训练。
- 2、Self-adversarial-training ( SAT )
 - 3、Dropblock
- 3、Dropblock
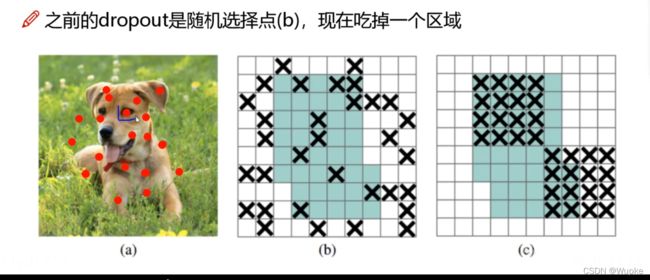
-
增加网络的学习难度,使得网络更好的学习数据的特征,提高泛化性,降低过拟合的风险。
-
4、Label Smoothing(标签平滑)
-
给出具体目标的分类程度:用[0.05, 0.95] 代替之前的 (0.1) 防止网络学习特征太绝对,轻易的过拟合(留有缓和余地)
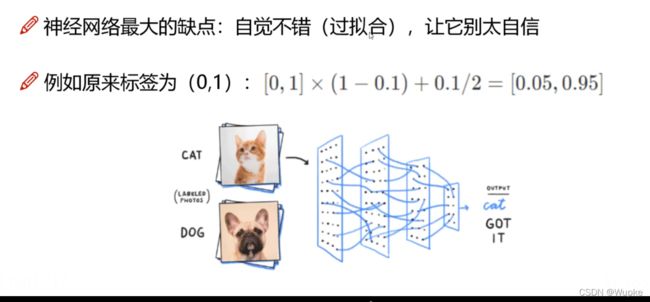
-
效果举例:
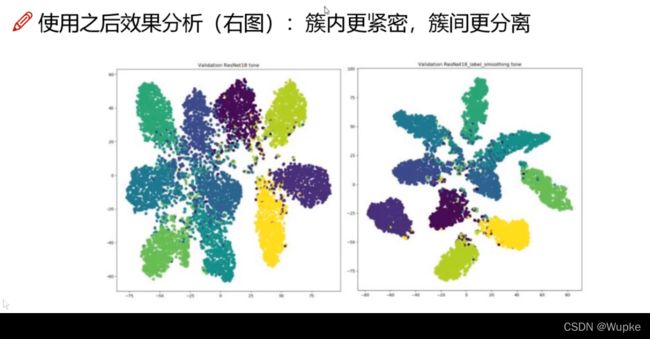
- 5、损失函数的定义:
- 一般的IOU 损失(或1-IOU)的定义:

存在的问题:
- 在没有相交的图中,则 IOU = 0 无法梯度计算(梯度消失)
- 且具有相同的 IOU 数值无法反映出实际的情况(如下图):
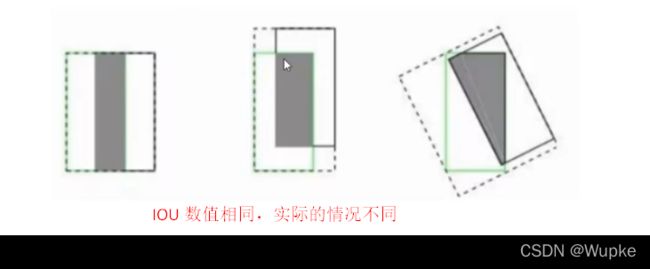
- 更新改进:G IOU

但是,当 真实框 与 预测框 重合时候,就无法区分效果了:
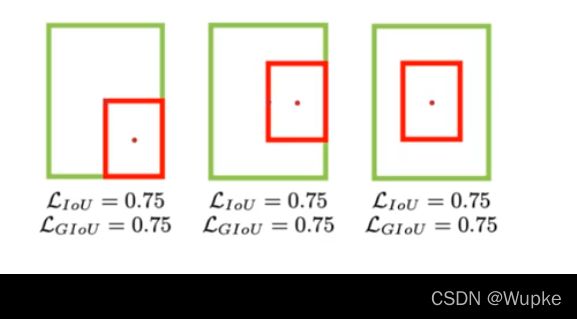
-
再更新改进:DIOU
-
引入距离的度量参数:(粗体 b 是对应框中心点 ,ρ平方,是欧式距离。)
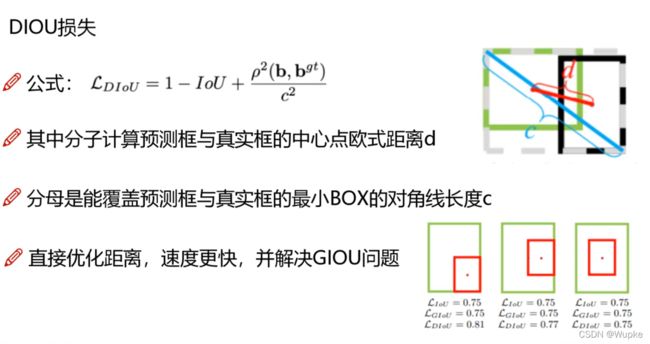
-
YOLO-v4 中使用的损失函数:
-
加入所检测物体的长宽比:

-
5、DIOU - NMS 筛选删除框

-
对比:soft-nms
-
将不符合的框进行降低数值(降低预测值),而不是直接剔除,查看图中的两匹马理解

在网络方面的改进
- 增加稍许推断代价,提高模型的精度;
- 改进网络细节,更好的提取特征
- 加入注意力机制、特征金字塔等
具体的:
-
6、SSPNet
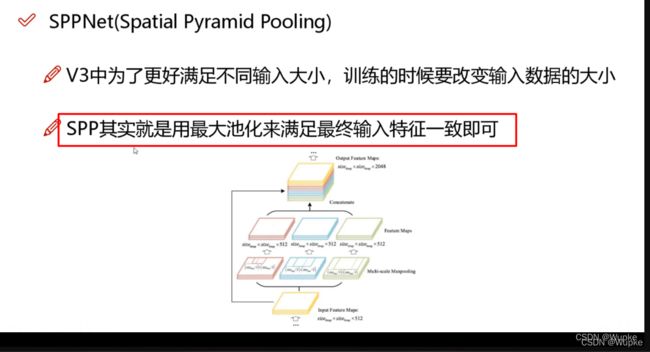
-
作用:增大感受野、最大池化来满足输入特征大小一致。
-
具体:满足不同的输入大小,不管输入是多大的都可以进行训练,都可将输出结果经过maxpling之后,在进行拼接时,保证将特征层大小处理为一致的,并增大感受野。
-
7、CSPNet (重要的细节改进)
-
拆分,不同的流程再拼接:使得特征与速度兼顾
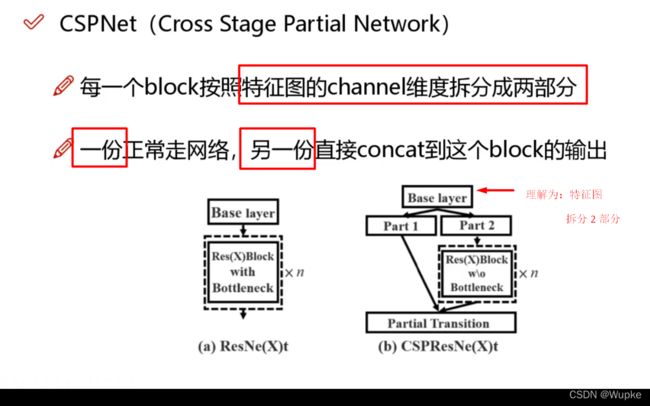
-
8、CBAM (注意力机制)
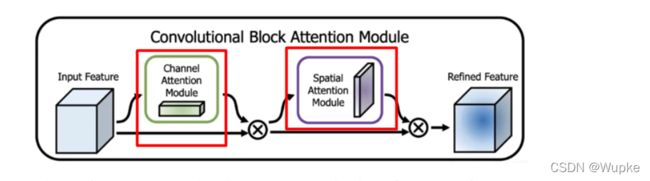
-
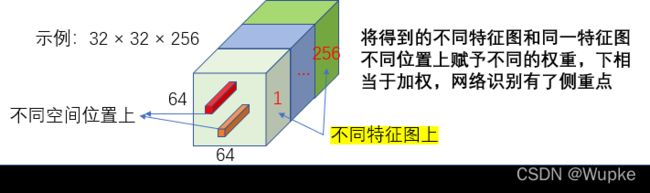
理解:给不同的 channel 进行重要性赋值,将得到的带有权重的 channel 特征图与原图像像乘,相当于给定一个权重。
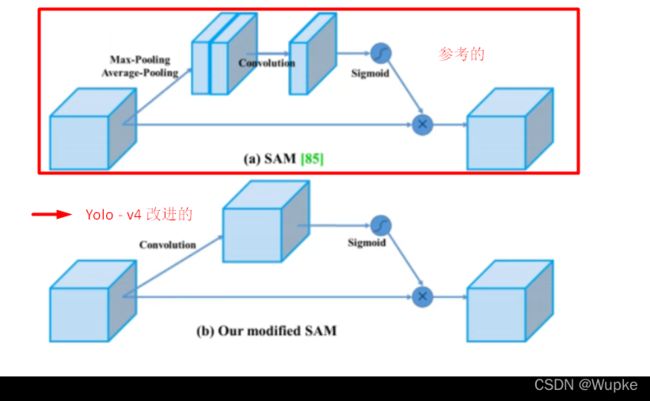
- yolo-v4 中添加的是空间位置注意力机制 ---- SAM
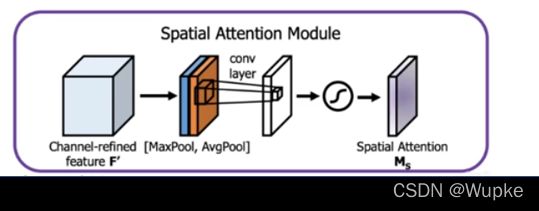
- 具体的注意力机制改进:
- 9、PAN
- 从FPAN 说起:(自顶向下的模式,将高层特征传递下来)
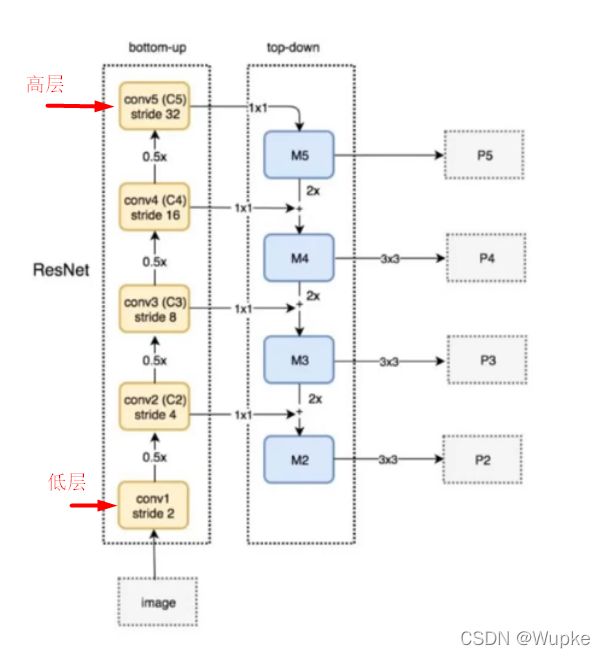
-
YOLO-V4 中直接在得到的 P2、P3、P4、P5 上自底往上走一遍。
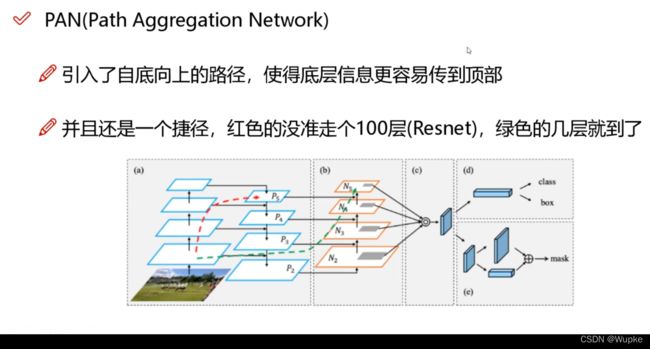
-
并改变了融合的方式:
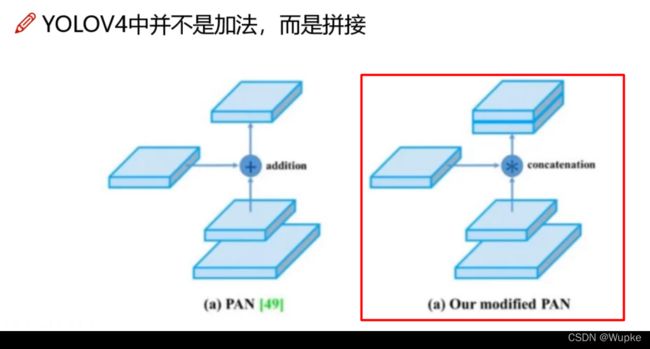
-
10、激活函数 : Mish
(允许在一定范围内,进行浮动)

-
后处理方法:

YOLO-V5
v5 版本没有对应的论文,实际是一个更加偏向于工程化的项目。侧重于工程应用。
YOLO-V5 相当于 v4 更加的工程化、效果更好,结构上相当于yolo-v4 的基础上没有什么变化。

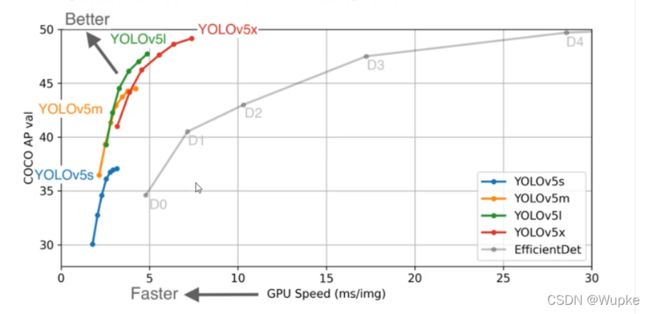
-
准备好相关的数据,直接使用官方代码,修改部分参数就可以在工程上使用。
-
下载好的工程文件内容:
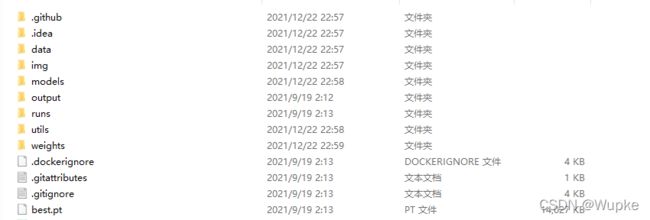
inference 文件夹保存的是测试/推断文件;
data:存放数据(可自制数据集)
runs :文件夹保存的是训练过程中的一些可视化结果、日志信息。
models 文件夹:模型文件与模型的配置文件
weighs : 权重模型文件以及训练好的权重文件 -
YOLO-V5 网络训练可视化工具引入:
-
工具netron(有网页版,也有app版本,网页版更省事)
-
网页版:https://lutzroeder.github.io/netron/.
-
具体的可以参考GitHub说明:
-
工具netron详情: https://github.com/lutzroeder/netron.

-
在model文件中的转换脚本文件:
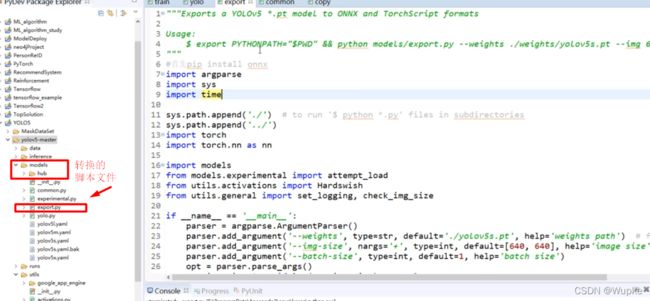
-
设置相关地址等参数。

-
展示效果:
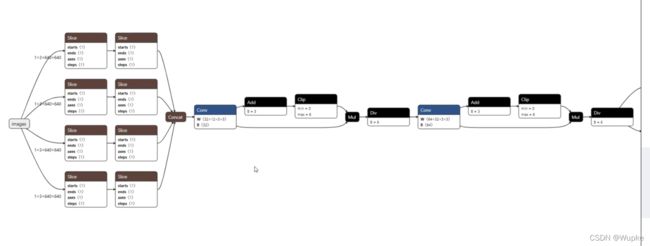
补充:
YOLO V5 与 YOLO V4 的理解补充
一文读懂YOLO V5 与 YOLO V4: https://zhuanlan.zhihu.com/p/161083602.
使用YOLO V5训练自动驾驶目标检测网络https://zhuanlan.zhihu.com/p/164627427.
附录资料链接
YOLO系列论文:
YOLO-V1论文地址 : https://arxiv.org/pdf/1506.02640.pdf .
YOLO-V2论文地址 : https://arxiv.org/pdf/1612.08242.pdf .
YOLO-V3论文地址 : https://arxiv.org/pdf/1804.02767.pdf.
YOLO-V4论文地址 : https://arxiv.org/pdf/2004.10934v1.pdf .
代码:
YOLO-V4 Github链接: https://github.com/AlexeyAB/darknet/.
YOLO-V5代码地址:
: https://github.com/ultralytics/YOLOv5.
-
YOLO-V5训练数据定义地址:
- https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data.
数据集下载:
检测类公开数据集下载地址: https://public.roboflow.com/.
源码解析
- 参考以YOLO-v3 版本的源码解读 : 【YOLO-v3 源码详细解读】.
项目实践
- 参考: 【基于YOLO-v3训练自己的数据与检测任务】.
- 包含数据集的制作与训练代码参数的更改说明。