复习Unity优化技巧
复习Unity优化技巧
- 一、引言
-
- 新的格局
- 有推荐的吗?
- 二、优化
-
- 第一章、优化图形性能
-
- 1、分析:
-
- A、GPU通常受填充率或者内存带宽制约。
-
- 填充率
- 渲染管线
- B、CPU 通常受到需要渲染的批次数的限制。
- C 、不太常见的瓶颈。
-
- a、GPU 有太多顶点需要处理。
- b、CPU 有太多顶点需要处理。
- c. 其他问题。
- 2、优化
-
- A、GPU:优化模型几何体
- B、GPU:光照性能
- C、GPU:纹理压缩和 Mipmap
- D、GPU:LOD(细节级别)和每层剔除距离
- E、GPU:实时阴影:
- F、GPU:编写高性能着色器的技巧
- E、CPU:优化方向:
- F、用于提高游戏运行速度的简单核对表
- 第二章、绘制调用批处理
-
- 1、基本概念
-
- A、UV
- B、光栅化
- C、渲染管道、主要步骤
- 2、分析
- 3、批处理的材质设置
- 4、动态批处理(网格)
- 5、动态批处理(粒子系统、线渲染器、轨迹渲染器)
- 6、静态批处理
- 7、提示
- 第三章、角色建模的性能优化
-
- 1、使用单个带蒙皮的网格渲染器
- 2、使用尽可能少的材质
- 3、使用尽可能少的骨骼
- 4、多边形数量
- 5、正向和反向动力学保持分离
-
- A、反向动力学(IK)
- 第四章、最佳实践指南
-
- 1、性能分析
- 2、内存分析
- 3、协程
- 4、资源审核
-
- A、代码审核(AssetPostprocessor )
- B、通用资源规则
-
- a、纹理
-
- (1)禁用 read/write enabled 标志
- (2)尽可能禁用 Mipmap
- (3)压缩所有纹理
- (4)实施合理的纹理大小限制
- b、模型
-
- (1)禁用 Read/Write enabled 标志
- (2)在非角色模型上禁用骨架
- (3)在动画模型上启用 Optimize Game Objects 选项
- (4)尽可能使用网格压缩
- (5)注意网格渲染器设置
- c、音频
-
- (1)适合平台的压缩设置
- (2)将音频剪辑强制设置为单声道
- (3)将音频剪辑强制设置为单声道
- (4)怎么选音频
- 5托管堆
-
- a、了解托管堆
- b、托管堆的工作原理及其扩展原因
- c、堆的主要问题
- d、基本的内存节省方法
-
- (1)集合和数组重用
- (2)闭包和匿名方法
- (3)IL2CPP 下的匿名方法
- (4)装箱 (Boxing)
- (5)字典和枚举
- (6)Foreach 循环
- (6)Unity 数组值 API
- (7)空数组重用
- 6字符串和文本
-
- a、区域约束与序数比对
- b、低效的内置字符串 API
- c、正则表达式
- d、XML、JSON 和其他长格式文本解析
-
- 方案 1:在构建时解析
- 方案 2:拆分和延迟加载
- 方案 3:线程
- 7、一般优化
-
- a、按 ID 寻址属性
- b、使用非分配物理 API
- c、与 UnityEngine.Object 子类进行 Null 比较
- d、矢量和四元数数学以及运算顺序
- e、内置 ColorUtility
- f、Find 和 FindObjectOfType
- g、调试代码和 [conditional] 属性
- 8、特别优化
-
- a、多维数组与交错数组
- b、粒子系统池
- c、更新管理器
- d、加载线程控制
- e、大批量对象移动和 CullingGroup
- f、减少方法调用开销
- g、简单属性
- h、简单方法
- 三、Shader
-
- 第一章、光照模型和实现
-
- 1、漫射(简单的兰伯特光照模型)
- 2、漫射环绕
- 3、卡通渐变 (Toon Ramp)
- 4、简单镜面反射
一、引言
又要找工作了,现在的公司项目组被砍了,很不幸,我也被砍了。那么久需要复习下,准备下阶段找工作了。于是,决定弄个文章来记录下。被砍是因为政策原因。并没有做什么违法的事情,跟公司性质有关系。
新的格局
不太想做游戏开发了,这一年多搞了Linux跟各种游戏开发软件结合,如Unity、Cocos、Electron,希望未来能找一个开发游戏但偏Linux方向的。
有推荐的吗?
欢迎大家在评论区告诉我。谢谢。
二、优化
按照Unity的官方文档来吧。不懂的加备注。
第一章、优化图形性能
1、分析:
A、GPU通常受填充率或者内存带宽制约。
填充率
是指图形处理单元在每秒内所渲染的像素数量,单位是MPixel/s(百万像素每秒)或者GPixel/s(十亿像素每秒)。像素的填充率等于显示核心的渲染管线数量×核心频率。
渲染管线
渲染管线(Rendering Pipeline)其实就是GPU渲染流程。你可以这样理解渲染,在一个三维坐标系下,给定一个视点(即摄相机),给定三维物体、光源以及照明模式、纹理等信息,如何绘制一幅呈现在视点画面中的二维图像的过程。
尝试解决办法:降低显示分辨率并运行游戏。如果显示分辨率降低后游戏运行更快,表明 GPU 填充率可能是限制因素。
B、CPU 通常受到需要渲染的批次数的限制。
尝试解决办法:检查 Rendering Statistics 窗口中的“batches”。渲染的批次越多,CPU 成本越高。
C 、不太常见的瓶颈。
a、GPU 有太多顶点需要处理。
可接受的能确保良好性能的顶点数量取决于 GPU 和顶点着色器的复杂程度。一般来说,移动端应不超过 100,000 个顶点。另一方面,即使有数百万个顶点,PC 也能管理到位,不过最好还是通过优化尽可能减少此数量。
b、CPU 有太多顶点需要处理。
这些顶点可能位于蒙皮网格、布料模拟、粒子或其他游戏对象和网格中。如上所述,通常较好的做法是在不影响游戏质量的情况下尽可能降低此数量。
c. 其他问题。
如果渲染在 GPU 或 CPU 方面不是问题,则可能在其他地方存在问题,例如在脚本或物理系统中。
2、优化
A、GPU:优化模型几何体
优化模型几何体有两个基本规则:
-
除非必要,否则不要使用三角形(尽量减少模型的三角面数和顶点数)
-
尽可能降低 UV 贴图接缝和硬边(双倍顶点)的数量
GPU优化: -
模型优化,尽量减少模型的三角面数和顶点数。
-
保持尽量少的材质数目,便于Unity进行批处理。
-
使用纹理图集(一张大贴图中包含多个子贴图)来替代一系列单独的小贴图。
-
使用代码操作材质时,尽量使用renderer.shareMaterial代替renderer.Material,因为后者的每一次改动都会创建一个新的材质。
-
使用Mip Map(Mip Map在贴图的Import Setting中设置),但同时会增加内存。
-
使用LOD,遮挡剔除(Occlusion culling)等技术。
-
光照优化,尽量使用烘培灯光,预先烘培好场景的Lightmap。控制灯光的数量并且谨慎使用产生实时阴影的光。
B、GPU:光照性能
速度最快的方案是始终创建根本不需要计算的光照。要做到这一点,使用光照贴图只需一次“烘焙”静态光照,而无需每帧计算。生成光照贴图环境的过程只比在 Unity 场景中放置光源稍久一点,但是:
- 运行速度要快得多(每像素 2 个光源的情况下,速度快 2–3 倍)
- 视觉效果要好得多,因为可以烘焙全局光照,使光照贴图显得更平滑
在许多情况下,可运用简单的技巧,无需添加多个额外的光照。例如,无需添加直接照入摄像机的光源来提供__边缘光照__效果,而是直接在着色器中添加专用的 Rim Lighting 计算(请参阅表面着色器示例以了解如何执行此操作)。
前向渲染中的光照
对于所有像素,动态光照会为每个受影响的像素增加渲染工作,可能导致对象在多个 pass 中被渲染。避免在性能较弱的设备(如移动端或低端 PC GPU)上使用多个__像素光照__来照射单个对象,应使用光照贴图实现静态对象的光照,而不是每帧计算其光照。每顶点动态光照可能会为顶点变换增加显著的工作量,因此尽量避免多个光源照射单个对象的情况。
避免组合距离足够远而需要受到不同像素光照影响的网格。使用像素光照时,每个网格必须渲染多次,因为只要发生像素光照就要进行渲染。如果组合两个相距很远的网格,则会增加组合对象的有效大小。照射该组合对象任何部分的所有像素光照在渲染期间都要考虑在内,因此需要创建的渲染 pass 的数量可能增加。通常情况下,为渲染组合对象而必须创建的 pass 数为每个单独对象的 pass 数之和,因此进行网格组合并不会获得任何好处。
在渲染过程中,Unity 会查找网格周围的所有光源,并计算出哪些光源对网格的影响最大。使用 Quality 窗口上的设置可修改多少个光源用于像素光照以及多少个用于顶点光照。每个光源根据它与网格的距离以及它的光照强度来计算其重要性;纯粹从游戏背景而言,有些光源比另一些光源更重要。鉴于此原因,每个光源都有 Render Mode 设置,可设置为 Important 或 Not Important__;标记为 Not Important__ 的光源具有较低的渲染开销。
示例:假设有一个驾驶游戏,玩家的汽车在黑暗中行驶,前照灯已打开。前照灯可能是游戏中视觉上最重要的光源,因此它们的 Render Mode 应设置为 Important。游戏中可能还有其他不太重要的光源,比如其他汽车的尾灯或远处的灯柱,这些光源不能通过像素光照来大幅改善视觉效果。这种情况下,可放心地将这些光源的 Render Mode 设置为 Not Important,从而避免将渲染能力浪费在无用之处。
通过优化每像素光照可以节省 CPU 和 GPU 工作量:CPU 的绘制调用将减少,而 GPU 要处理的顶点将减少,同时为所有其他对象渲染栅格化的像素也将减少。
C、GPU:纹理压缩和 Mipmap
使用压缩纹理可减小纹理的大小。这种做法可加快加载时间、减小内存占用并显著提高渲染性能。与未压缩的 32 位 RGBA 纹理所需的内存带宽相比,压缩纹理使用的内存带宽要小得多。
纹理 Mipmap
对于 3D 场景中使用的纹理,应始终启用 Generate mipmaps 选项。Mipmap 纹理使 GPU 能够为较小的三角形使用较低分辨率的纹理。这一点类似于纹理压缩可以帮助限制 GPU 渲染时传输的纹理数据量。
此规则的唯一例外是当已知纹理像素将 1:1 映射到渲染的屏幕像素时(与 UI 元素或在 2D 游戏中一样)。
D、GPU:LOD(细节级别)和每层剔除距离
剔除对象涉及使对象不可见。这是减轻 CPU 和 GPU 负载的有效方法。
在许多游戏中,在不影响玩家体验的情况下快速有效地执行此操作的方法是,相对于大对象,更激进地剔除小对象。例如,可让远处的小岩石和碎片不可见,而大型建筑物仍然保持可见。
有多种方式实现此目标:
- 使用细节级别系统
- 手动设置摄像机上的每层剔除距离
- 将小对象放入单独一层,并使用 Camera.layerCullDistances 脚本函数设置每层剔除距离
E、GPU:实时阴影:
实时阴影很不错,但它们对性能有很大影响,同时会增加 CPU 的绘制调用次数和 GPU 的处理量。
F、GPU:编写高性能着色器的技巧
不同的平台具有截然不同的性能;与低端移动端 GPU 相比,高端 PC GPU 在图形和着色器方面的处理能力要高得多。即使在单一平台上也是如此;快速的 GPU 比慢速的集成 GPU 快几十倍。
移动平台和低端 PC 上的 GPU 性能可能远低于开发机器上的 GPU 性能。建议手动优化着色器以减少计算和纹理读取,从而在低端 GPU 机器上获得良好的性能。例如,某些内置的 Unity 着色器具有速度快得多但存在一些限制或近似处理的“移动端”等效项。
以下是移动端和低端 PC 显卡的一些指导原则:
复杂的数学运算
超越数学函数(例如 pow、exp、log、cos、 sin、tan)都很消耗资源,所以尽量避免使用它们。如果可能,请尽量考虑使用查找纹理作为复杂数学计算的替代方法。
避免编写自己的运算(如 normalize、dot、inversesqrt)。Unity 的内置选项确保驱动程序可以生成好得多的代码。请记住,Alpha 测试 (discard) 运算通常会使片元着色器变慢。
浮点精度
虽然浮点变量的精度(float 与 half 与 fixed) 在桌面平台 GPU 上很大程度上会被忽略,但在移动端 GPU 上 对于获得良好性能非常重要。
有关着色器性能的更多详细信息,请参阅着色器性能页面。
E、CPU:优化方向:
为了在屏幕上渲染对象,CPU 需要做很多处理工作:确定哪些光源影响该对象,设置着色器和着色器参数,向图形驱动程序发送绘制命令,而图形驱动程序随后将准备发送到显卡的命令。
所有这种基于“每个对象”的 CPU 使用率都是非常消耗资源的,所以如果有很多可见对象,影响就会累加起来。例如,如果有一千个三角形,如果它们都在一个网格中,而不是每个三角形在一个网格中(这种情况下加起来就有 1000 个网格),则 CPU 处理起来就比较容易。两种方案的 GPU 成本非常相似,但 CPU 完成渲染一千个对象(而不是一个)的工作要高得多。减少可见对象数量。要减少 CPU 需要执行的工作量,请执行以下操作:
- 通过手动方式或使用 Unity 的绘制调用批处理将近处对象组合在一起。
- 通过将单独的纹理放入更大的纹理图集,在对象中使用更少的材质。
- 减少可能导致对象多次渲染的因素(例如反射、阴影和每像素光照)。
将对象组合在一起,使每个网格至少有几百个三角形,并使整个网格只使用一种材质。请注意,组合两个不共享材质的对象根本不会提高性能。需要多种材质的最常见原因是两个网格不共享相同的纹理;为了优化 CPU 性能,请确保组合的所有对象共享相同的纹理。
F、用于提高游戏运行速度的简单核对表
- 在针对 PC 平台进行构建时,保持顶点数量低于 200K 和 3M/帧(具体值取决于目标 GPU)。
- 如果要使用内置着色器,请从 Mobile 或 Unlit 类别中选取。这些类别也适用于非移动平台,但它们 - - 是更复杂着色器的简化和近似版本。
- 保持每个场景使用较少的不同材质,并尽可能在不同对象之间共享材质。
- 在非移动对象上设置 Static 属性以便允许内部优化,如静态批处理。
- 只有一个(最好是方向性的)pixel light 影响几何体(而不是有多个)。
- 烘焙光照而不是使用动态光照。
- 尽可能使用压缩纹理格式,并使用 16 位纹理而非 32 位纹理。
- 尽可能避免使用雾效。
- 如果复杂的静态场景具有大量遮挡,使用遮挡剔除减少可见几何体数量和绘制调用次数。设计关卡 - - 时注意遮挡剔除。
- 使用天空盒“伪造”远处的几何体。
- 使用像素着色器或纹理组合器来混合多个纹理而不是使用多 pass 方法。
- 尽可能使用 half 精度变量。
- 最大限度减少在像素着色器中使用复杂的数学运算,例如 pow、sin 和 cos。
- 每个片元使用更少的纹理。
第二章、绘制调用批处理
1、基本概念
A、UV
完整的说,其实应该是UVW(因为XYZ已经用过了,所以另选三个字母表示)。U和V分别是图片在显示器水平、垂直方向上的坐标,取值一般都是0~1,也 就是(水平方向的第U个像素/图片宽度,垂直方向的第V个像素/图片高度)。那W呢?贴图是二维的,何来三个坐标?嗯嗯,W的方向垂直于显示器表面,一般 用于程序贴图或者某些3D贴图技术(记住,确实有三维贴图这种概念!),对于游戏而言不常用到,所以一般我们就简称UV了。
B、光栅化
光栅化就是将一个图元转变为一个二维图像的过程,光栅化会根据三角形顶点的位置,来确定需要多少个像素点才能构成这个三角形。总的来说就是将几何信息转换成一个个的栅格组成的图像的过程,把顶点投影到屏幕空间进行渲染。
C、渲染管道、主要步骤
渲染管道是显示器上为了显示出图像而经过的一系列的必要操作,将几何物体从一个坐标系中变换到另一个坐标系中去。
主要步骤:本地坐标->视图坐标->光照->裁剪->投影->视图变换->光栅化
2、分析
要在屏幕上绘制游戏对象,引擎必须向图形 API(例如 OpenGL 或 Direct3D)发出绘制调用。绘制调用通常为资源密集型操作,图形 API 为每次绘制调用执行大量工作,从而导致 CPU 端的性能开销。此开销的主要原因是绘制调用之间的状态变化(例如切换到不同材质),而这种情况会导致图形驱动程序中执行资源密集型验证和转换步骤。
Unity 使用两种方法来应对此情况:
动态批处理:对于足够小的网格,此方法会在 CPU 上转换网格的顶点,将许多相似顶点组合在一起,并一次性绘制它们。
静态批处理:将静态(不移动)游戏对象组合成大网格,并以较快的速度渲染它们。
与手动合并游戏对象相比,内置批处理有几个好处;最值得注意的是,仍然可以单独剔除游戏对象。但是,也有一些缺点;静态批处理会导致内存和存储开销,动态批处理会产生一些 CPU 开销。
3、批处理的材质设置
- 只有共享相同材质的游戏对象才可一起接受批处理。因此,如果想要实现良好批处理,应在尽可能多的不同游戏对象之间共享材质。
- 如果两种相同材质仅在纹理上不同,可将这些纹理组合成单个大纹理。此过程通常称为纹理镶嵌。一旦纹理位于相同图集中,即可使用单个材质。
- 如果需要从脚本访问共享材质属性,必须注意,修改 Renderer.material 将创建该材质的副本。应改用 Renderer.sharedMaterial 来保留共享的材质。
- 阴影投射物即使材质不同,通常也可以在渲染时接受批处理。Unity 中的阴影投射物即使具有不同材质也可以使用动态批处理,只要阴影 pass 所需材质中的值相同即可。例如,许多板条箱可能使用具有不同纹理的材质,但是由于渲染纹理的阴影投射物不相关,所以在此情况下,它们可以一起接受批处理。
4、动态批处理(网格)
如果移动的游戏对象共享相同材质并满足其他条件,则 Unity 可自动在同一绘制调用中批处理这些游戏对象。动态批处理是自动完成的,无需您进行任何额外工作。
-
批处理动态游戏对象在每个顶点都有一定开销,因此批处理仅会应用于总共包含不超过 900 个顶点属性且不超过 300 个顶点的网格。
如果着色器使用顶点位置、法线和单个 UV,最多可以批处理 300 个顶点,而如果着色器使用顶点位置、法线、UV0、UV1 和切线,则只能批处理 180 个顶点。
注意:将来可能会更改属性数量限制。
这个地方为什么是300和180,按照900个顶点属性计算,900/(顶点位置、法线和单个 UV)=300。同样的,900/(顶点位置、法线、UV0、UV1 和切线)=180。 -
如果游戏对象在变换中包含镜像,则不会对这些对象进行批处理(例如,具有 +1 缩放的游戏对象 A 和具有 –1 缩放的游戏对象 B 无法一起接受批处理)。即分别拥有缩放尺度(1,1,1)和(2,2,2)的两个物体将不会进行批处理。统一缩放尺度的物体不会与非统一缩放尺度的物体进行批处理。使用缩放尺度(1,1,1)和 (1,2,1)的两个物体将不会进行批处理,但是使用缩放尺度(1,2,1)和(1,3,1)的两个物体将可以进行批处理。
DrawCall分析流程来分析一下:
1、渲染A,使用材质1
2、渲染B,使用材质1
3、渲染C,使用材质2
在这种情况下是2个DrawCall,在下面这种情况下,则是3个DrawCall
1、渲染A,使用材质1
2、渲染C,使用材质2
3、渲染B,使用材质1 -
即使游戏对象基本相同,使用不同的材质实例也会导致游戏对象不能一起接受批处理。例外情况是阴影投射物渲染。
-
带有光照贴图的游戏对象具有其他渲染器参数:光照贴图索引和光照贴图偏移/缩放。通常,动态光照贴图的游戏对象应指向要批处理的完全相同的光照贴图位置。
-
多 pass 着色器会中断批处理。
- 几乎所有的 Unity 着色器都支持前向渲染中的多个光照,有效地为它们执行额外 pass。“其他每像素光照”的绘制调用不进行批处理。
- 旧版延迟(光照 pre-pass)渲染路径会禁用动态批处理,因为它必须绘制两次游戏对象。
因为动态批处理的工作原理是将所有游戏对象顶点转换到 CPU 上的世界空间,所以仅在该工作小于进行绘制调用的情况下,才有优势。绘制调用的资源需求取决于许多因素,主要是使用的图形 API。例如,对于游戏主机或诸如 Apple Metal 之类的现代 API,绘制调用的开销通常低得多,通常动态批处理根本没有优势。
5、动态批处理(粒子系统、线渲染器、轨迹渲染器)
动态批处理在用于具有 Unity 动态生成的几何体的组件时,其工作方式与用于网格时不同。
- 对于每个兼容的渲染器类型,Unity 将所有可批处理的内容构建为 1 个大型顶点缓冲区。
- 渲染器设置材质状态以用于批处理。
- Unity 将顶点缓冲区绑定到图形设备。
- 对于批处理中的每个渲染器,Unity 将偏移更新到顶点缓冲区中,然后提交新的绘制调用。
在衡量图形设备调用的成本时,渲染组件时的最慢部分是材质状态的设置。相比之下,将不同偏移处的绘制调用提交到共享顶点缓冲区中的速度非常快。
这种方法与 Unity 在使用静态批处理时提交绘制调用的方式非常相似。
6、静态批处理
使用静态批处理,引擎可减少任何大小的几何体的绘制调用,但前提是它共享相同材质并且不移动。这种处理方式通常比动态批处理更高效(它不会在 CPU 上转换顶点),但是使用更多内存。
为了利用静态批处理,您需要显式指定某些游戏对象是静态对象且不会在游戏中移动、旋转或缩放。为此,请使用 Inspector 中的 Static 复选框,将游戏对象标记为静态。
在内部,静态批处理的工作原理是将静态游戏对象转换到世界空间并为它们构建一个共享的顶点和索引缓冲区。如果已启用 Optimized Mesh Data__(在 Player__ 设置中),则 Unity 会在构建顶点缓冲区时删除任何着色器变体未使用的任何顶点元素。为了执行此操作,系统会进行一些特殊的关键字检查;例如,如果 Unity 未检测到 LIGHTMAP_ON 关键字,则会从批处理中删除光照贴图 UV。然后,针对同一批次中的可见游戏对象,Unity 会执行一系列简单的绘制调用,每次调用之间几乎没有状态变化。在技术上,Unity 不会减少 API 绘制调用,而是减少它们之间的状态变化(这正是消耗大量资源的部分)。在大多数平台上,批处理限制为 64k 个顶点和 64k 个索引(OpenGLES 上为 48k 个索引,在 macOS 上为 32k 个索引)。
7、提示
当前,仅对网格渲染器、轨迹渲染器、线渲染器、粒子系统和精灵渲染器进行批处理。这意味着不会对蒙皮网格、布料和其他类型的渲染组件进行批处理。
渲染器仅与其他相同类型的渲染器一起接受批处理。
半透明着色器通常要求游戏对象按照从后到前的顺序进行渲染,从而实现透明性。Unity 首先按此顺序对游戏对象排序,然后尝试对它们进行批处理,但是因为必须严格满足顺序,所以这通常意味着可以实现比不透明游戏对象更少的批处理。
手动组合彼此接近的游戏对象可以是绘制调用批处理的极好替代方法。例如,一个带有大量抽屉的静态橱柜通常只需在 3D 建模应用程序中或者使用 Mesh.CombineMeshes 来组合成一个网格。
第三章、角色建模的性能优化
1、使用单个带蒙皮的网格渲染器
对于每个角色,仅使用单个蒙皮网格渲染器。Unity 使用可见性剔除和包围体更新来优化动画,这些优化仅在您将单个动画组件和单个蒙皮网格渲染器组合使用时才会生效。若使用两个蒙皮网格,模型的渲染时间大概会是单个网格的两倍,并且这样做很少能带来实际的意义。
2、使用尽可能少的材质
您同样应该尽可能减少每个网格上的材质数量。只有在需要为角色的不同的部分使用不同着色器(例如,眼睛的特殊着色器)时,您才应该考虑使用多种材质。其余大多数情况下,每个角色有两到三种材质就应该足够了。
3、使用尽可能少的骨骼
典型的桌面游戏中的骨骼层级视图大概拥有 15 到 60 根骨骼。骨骼的数量越少,性能就越好。在使用大约 30 根骨骼的情况下,桌面平台上可以获得极佳质量,移动平台上也能获得比较好的质量。理想情况下,移动设备游戏的骨骼数量应保持在 30 根以下,桌面游戏的骨骼数量也不要超出 30 根太多。
4、多边形数量
您应该使用的多边形数量取决于您需要达到的质量,以及您的目标平台。对于移动设备而言,每个网格 300 到 1500 个多边形就可以取得良好的效果,而对于桌面平台,理想的数量范围大约为 1500 到 4000。如果游戏经常会同屏内出现大量角色,那么您可能需要减少每个网格的多边形数量。
5、正向和反向动力学保持分离
在导入动画时,模型的反向动力学 (IK) 节点将被烘焙为正向动力学 (FK),因此 Unity 根本不需要 IK 节点。但是,如果它们留在了模型中,那么即使它们不影响动画,也会让 CPU 产生额外开销。您可以根据自己的偏好,删除 Unity 或建模工具中的冗余 IK 节点。理想情况下,应在建模期间保留单独的 IK 和 FK 层级视图,以便在必要时更轻松地删除 IK 节点。
A、反向动力学(IK)
反向动力学,就是子骨骼节点带动父骨骼节点运动。一般在模型制作的时候删除。导入Unity如何删除暂时没有找到方法。
第四章、最佳实践指南
1、性能分析
-[UnityAppController startUnity]
|- [UnityInitApplicationGraphics]
|- [UnityLoadApplication]
UnityInitApplicationGraphics 执行大量内部工作,例如设置图形设备和初始化 Unity 的大量内部系统。此外,它还初始化资源系统 (Resources system)。为此,它必须加载资源系统包含的所有文件的索引。
每个“Resources”文件夹中的每个资源文件 (1)(注意: 这仅适用于项目“Assets”文件夹中名为“Resources”的文件夹,以及这些“Resources”文件夹中的所有子文件夹。)都作为资源系统的数据。因此,初始化资源系统所需的时间与“Resources”文件夹中的文件数量呈线性关系。
UnityLoadApplication 包含加载并初始化项目的第一个场景的方法。它包括反序列化并实例化显示第一个场景所需的所有数据,例如编译着色器、上传纹理和实例化游戏对象。此外,第一个场景中的所有 MonoBehaviour 都在此时执行 Awake 回调。
这就意味着,如果在项目的第一个场景中的 Awake 回调中存在任何执行时间很长的代码,那么该代码可能会导致项目的初始启动时间的延长。解决此问题的方法是删除这些运行速度慢的代码,或者在应用程序生命周期的其他地方执行该代码。
2、内存分析
MemoryProfiler
3、协程
DelayedCallManager
4、资源审核
A、代码审核(AssetPostprocessor )
Unity Editor 中的 AssetPostprocessor 类可用于在 Unity 项目上强制执行某些最低标准。导入资源时将回调此类。要使用此类,应继承 AssetPostprocessor 并实现一个或多个 OnPreprocess 方法。重要的方法包括:
- OnPreprocessTexture
- OnPreprocessModel
- OnPreprocessAnimation
- OnPreprocessAudio
B、通用资源规则
a、纹理
(1)禁用 read/write enabled 标志
Read/Write enabled 标志使纹理在内存中保留两次:一次保存在 GPU 中,一次保存在 CPU 可寻址内存中(1)(注意: 这是因为大多数平台上从 GPU 内存回读的速度极慢。将纹理从 GPU 内存读入临时缓冲区以供 CPU 代码(例如 Texture.GetPixel)使用将是非常低效的)。在 Unity 中,默认情况下禁用此设置,但可能会无意中将其打开。
只有在着色器之外操作纹理数据时(例如使用 Texture.GetPixel 和 Texture.SetPixel API 时)才需要 Read/Write Enabled,否则应尽可能避免使用它。
(2)尽可能禁用 Mipmap
如果对象相对于摄像机具有相对不变的 Z 深度,则可禁用 Mipmap,这样将大约节省加载纹理所需的内存的三分之一。如果对象的 Z 深度会发生变更,则禁用 Mipmap 可能导致 GPU 上的纹理采样性能变差。
通常情况下,这对于 UI 纹理以及在屏幕上以恒定大小显示的其他纹理非常有用。
注意:这里为什么禁用Mipmap是大约节省三分之一。这是因为:Mipmap的原理是把一张贴图按照2的倍数进行缩小。直到1X1。也即使说,对于一张10241024的32位png(大小是4M,即102410244)来说,后续的大小是:
512512=1
256256=1/4
128128=1/16
6464=1/64
3232=1/256
1616=1/1024
88=1/4098
44=1/40984
22=1/409816
11=1/409864
这样算下来,约等于1.33333,儿1.33333/4也约等于1/3。因此有节约三分之一的说话。
(3)压缩所有纹理
使用适合项目目标平台的纹理压缩格式对于节省内存至关重要。
如果所选的纹理压缩格式不适合目标平台,Unity 会在加载纹理时解压缩纹理,这将消耗 CPU 时间和额外的内存。此问题在 Android 设备上最常见,因为此类平台通常因芯片组不同而支持截然不同的纹理压缩格式。
(4)实施合理的纹理大小限制
虽然很简单,但也很容易忘记调整纹理大小或无意中更改纹理大小导入设置。应确定不同类型纹理的合理最大值,并通过代码强制执行这些限制规则。
对于许多移动应用程序,2048x2048 或 1024x1024 足以满足纹理图集的要求,而 512x512 足以满足应用于 3D 模型的纹理的要求。
ETC2 主要是对于NPOT却是4的倍数的贴图有较大压缩,比如一个1920X1080RGB的Loading图,ETC压缩下不管用大小5.9M,ETC2下压缩为1M
ETC2支持透明度的,ETC1不支持,现在基本上所有的手机都支持ETC2了。
b、模型
(1)禁用 Read/Write enabled 标志
模型的 Read/Write enabled 标志与纹理的上述相应标志具有相同的工作原理。但是,模型在默认情况下会启用该标志。
如果项目在运行时通过脚本修改网格 (Mesh),或者如果网格用作 MeshCollider 组件的基础,则 Unity 会要求启用此标志。如果模型未在 MeshCollider 中使用并且未被脚本操纵,请禁用此标志以节省一半模型内存。
(2)在非角色模型上禁用骨架
认情况下,Unity 会为非角色模型导入通用骨架。如果模型在运行时实例化,则会导致添加 Animator 组件。如果模型没有通过动画系统进行动画处理,则会给动画系统增加不必要的开销,因为每帧都必须运行一次所有激活的 Animator。
在非动画模型上禁用骨架可以避免自动添加 Animator 组件,并防止可能无意中向场景添加不需要的 Animator。
(3)在动画模型上启用 Optimize Game Objects 选项
Optimize Game Objects 选项对动画模型有着显著的性能影响。禁用该选项后,Unity 会在每次实例化模型时创建一个大型变换层级视图来镜像模型的骨骼结构。此变换层级视图的更新成本很高,尤其是在附加了其他组件(如粒子系统或碰撞体)的情况下。它还限制了 Unity 通过多线程执行网格蒙皮和骨骼动画计算的能力。
如果需要暴露模型骨骼结构上的特定位置(例如暴露模型的双手以便动态附加武器模型),则可在 Extra Transforms 列表中将这些位置专门列入白名单。
(4)尽可能使用网格压缩
启用网格压缩可减少用于表示模型数据不同通道的浮点数的位数。这样做可能导致精确度的轻微损失,在用于最终项目之前,美术师应评估这种不精确性的影响。
在给定压缩级别中使用的具体位数在 ModelImporterMeshCompression 脚本参考中有详细说明。
请注意,可对不同的通道使用不同级别的压缩,因此项目可选择仅压缩切线和法线,同时保持 UV 和顶点位置不压缩。
(5)注意网格渲染器设置
将网格渲染器添加到预制件或游戏对象时,请注意组件上的设置。默认情况下,Unity 会启用阴影投射和接收、光照探针采样、反射探针采样和运动矢量计算。
如果项目不需要这些功能中的一个或多个,请确保通过自动脚本关闭它们。添加网格渲染器的任何运行时代码也都需要处理这些设置。
对于 2D 游戏,在启用阴影选项的情况下意外地将网格渲染器添加到场景会为渲染循环添加完整的阴影 pass。通常情况下,这是对性能的浪费。
c、音频
(1)适合平台的压缩设置
应为音频启用与可用硬件匹配的压缩格式。所有 iOS 设备都包含硬件 MP3 解压器,而许多 Android 设备本身支持 Vorbis。
此外,应将未压缩的音频文件导入 Unity。Unity 在构建项目时总是会重新压缩音频。无需导入压缩的音频再重新压缩,这只会降低最终音频剪辑的质量。
(2)将音频剪辑强制设置为单声道
很少有移动设备实际配备立体声扬声器。在移动平台项目中,将导入的音频剪辑强制设置为单声道会使其内存消耗减半。此设置也适用于没有立体声效果的任何音频,例如大多数 UI 声音效果。
(3)将音频剪辑强制设置为单声道
尽量降低音频文件的比特率,以进一步节省内存消耗和构建的项目大小,但这种情况需要咨询音频设计师。
(4)怎么选音频
Load Type的各个选项:
- Compressed In Memory – 音频剪辑将存储在RAM中,播放时将解压缩,播放时不需要额外的存储
- Streaming –音频永久存在设备上(硬盘或闪存上) ,播放流媒体方式. 不需要RAM进行存储或播放。
- Decompress On Load – 未压缩的音频将存储在RAM中。这个选项需要的内存最多,但是播放它不会像其他选项那样需要太多的CPU电源。
长音频播放消耗大量内存,如果播放时不想在内存中进行解压,有两个选择:
- Load Type选“Streaming”, Compression Format 选”Vorbis",使用最少的内存,但需要更多的CPU电量和硬盘I/O操作;
- Load Type选“Compressed In Memory”, Compression Format 选”Vorbis",磁盘I/O操作被替换成内存的消耗,请注意,要调整“Quaility”滑块以减小压缩剪辑的大小,以交换音质,一般推荐70%左右。
其他情况的选择方式:
- 对于经常播放的和短的音频剪辑,使用“Decompress On Load”和“PCM或ADPCM"压缩格式。当选择PCM时,不需要解压缩,如果音频剪辑很短,它将很快加载。你也可以使用ADPCM。它需要解压,但解压比Vorbis快得多。
- 对于经常播放,中等大小的音频剪辑使用”Compressed In Memory“和”ADPCM“压缩格式,比原始PCM小3.5倍,解压算法的CPU消耗量不会像vorbis消耗那么多CPU。
- 对于很少播放并且长度比较短的声音剪辑,使用”Compressed In Memory"和”ADPCM“压缩格式,比原始PCM小3.5倍,解压算法的CPU消耗量不会像vorbis消耗那么多CPU。
- 对于很少播放中等大小的音频,使用”Compressed In Memory“ 和Vorbis压缩格式。这个音频可能太长,无法使用adpcm存储,播放太少,因此解压缩所需的额外CPU电量不会太多。
5托管堆
a、了解托管堆
许多 Unity 开发者面临的另一个常见问题是托管堆的意外扩展。在 Unity 中,托管堆的扩展比收缩容易得多。此外,Unity 的垃圾收集策略往往会使内存碎片化,因此可能阻止大型堆的收缩。
b、托管堆的工作原理及其扩展原因
“托管堆”是由项目脚本运行时(Mono 或 IL2CPP)的内存管理器自动管理的一段内存。必须在托管堆上分配托管代码中创建的所有对象(2)(__注意:__严格来说,必须在托管堆上分配所有非 null 引用类型对象和所有装箱值类型对象)。

在上图中,白框表示分配给托管堆的内存量,而其中的彩色框表示存储在托管堆的内存空间中的数据值。当需要更多值时,将从托管堆中分配更多空间。
垃圾回收器定期运行(3)(__注意:__具体运行时间视平台而定)。这时将扫描堆上的所有对象,将任何不再引用的对象标记为删除。然后会删除未引用的对象,从而释放内存。
至关重要的是,Unity 的垃圾收集(使用 Boehm GC 算法)是非分代的,也是非压缩的。“非分代”意味着 GC 在执行每遍收集时必须扫描整个堆,因此随着堆的扩展,其性能会下降。“非压缩”意味着不会为内存中的对象重新分配内存地址来消除对象之间的间隙。

上图为内存碎片化示例。释放对象时,将释放其内存。但是,释放的空间不会整合成为整个“可用内存”池的一部分。位于释放的对象两侧的对象可能仍在使用中。因此,释放的空间成为其他内存段之间的“间隙”(该间隙由上图中的红色圆圈指示)。因此,新释放的空间仅可用于存储与释放相同大小或更小的对象的数据。
分配对象时,请注意对象在内存空间中的分配地址必须始终为连续空间块。
这导致了内存碎片化这个核心问题:虽然堆中的可用空间总量可能很大,但是可能其中的部分或全部的可分配空间对象之间存在小的“间隙”。这种情况下,即使可用空间总量高于要分配的空间量,托管堆可能也找不到足够大的连续内存块来满足该分配需求。

但是,如果分配了大型对象,却没有足够的连续可用空间来容纳该对象(如上所示),Unity 内存管理器将执行两个操作。
首先,如果垃圾回收器尚未运行,则运行垃圾回收器。此工具会尝试释放足够的空间来满足分配请求。
如果在 GC 运行后,仍然没有足够的连续空间来满足请求的内存量,则必须扩展堆。堆的具体扩展量视平台而定;但是,大多数 Unity 平台会使托管堆的大小翻倍。
c、堆的主要问题
托管堆扩展方面的核心问题有两个:
- Unity 在扩展托管堆后不会经常释放分配给托管堆的内存页;它会乐观地保留扩展后的堆,即使该堆的大部分为空时也如此。这是为了防止再次发生大量分配时需要重新扩展堆。
- 在大多数平台上,Unity 最终会将托管堆的空置部分使用的页面释放回操作系统。发生此行为的间隔时间是不确定的,因此不要指望靠这种方法释放内存。
- 托管堆使用的地址空间始终不会归还给操作系统。
- 对于 32 位程序,如果托管堆多次扩展和收缩,则可能导致地址空间耗尽。如果一个程序的可用内存地址空间已耗尽,操作系统将终止该程序。
- 对于 64 位程序而言,地址空间足够大到可以运行时间超过人类平均寿命的程序,因此地址空间耗尽的这种情况极几乎不可能发生。
d、基本的内存节省方法
(1)集合和数组重用
使用 C# 的集合类或数组时,尽可能考虑重用或汇集已分配的集合或数组。集合类开放了一个 Clear 方法,该方法会消除集合内的值,但不会释放分配给集合的内存。
void Update() {
List<float> nearestNeighbors = new List<float>();
findDistancesToNearestNeighbors(nearestNeighbors);
nearestNeighbors.Sort();
// … 以某种方式使用排序列表 …
}
在为复杂计算分配临时“helper”集合时,这尤其有用。下面的代码是一个非常简单的示例:
在此示例中,为了收集一组数据点,每帧都为 nearestNeighbors List(列表)分配一次内存。将此 List 从方法中提升到包含类中是非常简单的,这样做避免了每帧都为新 List 分配内存:
List<float> m_NearestNeighbors = new List<float>();
void Update() {
m_NearestNeighbors.Clear();
findDistancesToNearestNeighbors(NearestNeighbors);
m_NearestNeighbors.Sort();
// … 以某种方式使用排序列表 …
}
在此版本中,List 的内存被保留并在多个帧之间重用。仅在 List 需要扩展时才分配新内存。
(2)闭包和匿名方法
使用闭包和匿名方法时需要注意两点。
首先,C# 中的所有方法引用都是引用类型,因此在堆上进行分配。通过将方法引用作为参数传递,可以轻松分配临时内存。无论传递的方法是匿名方法还是预定义的方法,都会发生此分配。
其次,将匿名方法转换为闭包后,为了将闭包传递给接收闭包的方法,所需的内存量将显著增加。
请参考以下代码:
List<float> listOfNumbers = createListOfRandomNumbers();
listOfNumbers.Sort( (x, y) =>
(int)x.CompareTo((int)(y/2))
);
这段代码使用简单的匿名方法来控制在第一行创建的数字列表的排序顺序。但是,如果程序员希望使该代码段可重用,很容易想到将常量 2 替换为局部作用域内的变量,如下所示:
List<float> listOfNumbers = createListOfRandomNumbers();
int desiredDivisor = getDesiredDivisor();
listOfNumbers.Sort( (x, y) =>
(int)x.CompareTo((int)(y/desiredDivisor))
);
匿名方法现在要求该方法能够访问方法作用域之外的变量状态,因此已成为闭包。必须以某种方式将 desiredDivisor 变量传递给闭包,以便闭包的实际代码可以使用该变量。
为此,C# 将生成一个匿名类,该类可保存闭包所需的外部作用域变量。当闭包传递给 Sort 方法时,将实例化此类的副本,并用 desiredDivisor 整数的值初始化该副本。
因为执行闭包需要实例化闭包生成类的副本,并且所有类都是 C# 中的引用类型,所以执行闭包需要在托管堆上分配对象。
通常,请尽可能在 C# 中避免使用闭包。应在性能敏感的代码中尽可能减少匿名方法和方法引用,尤其是那些每帧都需要执行的代码中。
(3)IL2CPP 下的匿名方法
目前,通过查看 IL2CPP 所生成的代码得知,对System.Function 类型变量的声明和赋值将会分配一个新对象。无论变量是显式的(在方法/类中声明)还是隐式的(声明为另一个方法的参数),都是如此。
因此,使用 IL2CPP 脚本后端下的匿名方法必定会分配托管内存。在 Mono 脚本后端下则不是这种情况。
此外,由于方法参数的声明方式不同,将导致IL2CPP 显示出托管内存分配量产生巨大差异。正如预期的那样,闭包的每次调用会消耗最多的内存。
预定义的方法在 IL2CPP 脚本后端下作为参数传递时,其__分配的内存几乎与闭包一样多__,但这不是很直观。匿名方法在堆上生成最少量的临时垃圾(一个或多个数量级)。
因此,如果打算在 IL2CPP 脚本后端上发布项目,有三个主要建议:
- 最好选择不需要将方法作为参数传递的编码风格。
- 当不可避免时,最好选择匿名方法而不是预定义方法。
- 无论脚本后端为何,都要避免使用闭包。
(4)装箱 (Boxing)
装箱是 Unity 项目中最常见的非预期临时内存分配来源之一。只要将值类型的值用作引用类型就会发生装箱;这种情况最常发生在将原始值类型的变量(例如 int 和 float)传递给对象类型的方法时。
在下面非常简单的示例中,对 x 中的整数进行了装箱以便传递给 object.Equals 方法,因为 object 上的 Equals 方法要求将 object 作为参数传递给它。
int x = 1;
object y = new object();
y.Equals(x);
C# IDE(集成开发环境)和编译器通常不会发出关于装箱的警告,即使导致意外的内存分配时也是如此。这是因为 C# 语言的设计理念认为,小型临时分配可以被分代垃圾回收器和对分配大小敏感的内存池有效处理。
虽然 Unity 的分配器实际会使用不同的内存池进行小型和大型分配,但 Unity 的垃圾回收器“不是”分代的,因此无法有效清除由装箱生成的小型、频繁的临时分配。
在为 Unity 运行时编写 C# 代码时,应尽可能避免使用装箱。
识别装箱
装箱在 CPU 跟踪中显示为对某几种特定方法的调用,具体形式取决于使用的脚本后端。这些调用通常采用以下形式之一,其中 是其他类或结构的名称,而 … 是一些参数:
<some class>::Box(…)
Box(…)
<some class>_Box(…)
也可以通过搜索反编译器或 IL 查看器(例如 ReSharper 中内置的 IL 查看器工具或 dotPeek 反编译器)的输出来定位装箱。IL 指令为“box”。
(5)字典和枚举
装箱的一个常见原因是使用 enum 类型作为字典的键。声明 enum 会创建一个新值类型,此类型在后台视为整数,但在编译时实施类型安全规则。
默认情况下,调用 Dictionary.add(key, value) 会导致调用 Object.getHashCode(Object)。此方法用于获取字典的键的相应哈希代码,并在所有接受键的方法中使用,如:Dictionary.tryGetValue、Dictionary.remove 等。
Object.getHashCode 方法为引用类型,但 enum 值始终为值类型。因此,对于枚举键字典,每次方法调用都会导致键被装箱至少一次。
以下代码片段展示的一个简单示例说明了此装箱问题:
enum MyEnum { a, b, c };
var myDictionary = new Dictionary<MyEnum, object>();
myDictionary.Add(MyEnum.a, new object());
要解决此问题,则需要编写一个实现 IEqualityComparer 接口的自定义类,并将该类的实例指定为字典的比较器(__注意:__此对象通常是无状态的,因此可与不同的字典实例一起重复使用以节省内存)。
以下是上述代码片段 IEqualityComparer 的简单示例。
public class MyEnumComparer : IEqualityComparer<MyEnum> {
public bool Equals(MyEnum x, MyEnum y) {
return x == y;
}
public int GetHashCode(MyEnum x) {
return (int)x;
}
}
可将上述类的实例传递给字典的构造函数。
(6)Foreach 循环
在 Unity 的 Mono C# 编译器版本中,使用 foreach 循环会在每次循环终止时强制 Unity 将一个值装箱(__注意:__是在每次整个循环完整执行完成后将该值装箱一次,并非在循环的每次迭代中装箱一次,因此无论循环运行两次还是 200 次,内存使用量都保持不变)。这是因为 Unity 的 C# 编译器生成的 IL 会构造一个通用值类型的枚举器来遍历值集合。
此枚举器将实现 IDisposable 接口;当循环终止时必须调用该接口。但是,在值类型的对象(例如结构和枚举器)上调用接口方法需要将它们装箱。
请参考下面非常简单的示例代码:
int accum = 0;
foreach(int x in myList) {
accum += x;
}
以上代码通过 Unity 的 C# 编译器运行后将生成以下中间语言:
.method private hidebysig instance void
ILForeach() cil managed
{
.maxstack 8
.locals init (
[0] int32 num,
[1] int32 current,
[2] valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32> V_2
)
// [67 5 - 67 16]
IL_0000: ldc.i4.0
IL_0001: stloc.0 // num
// [68 5 - 68 74]
IL_0002: ldarg.0 // this
IL_0003: ldfld class [mscorlib]System.Collections.Generic.List`1<int32> test::myList
IL_0008: callvirt instance valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<!0/*int32*/> class [mscorlib]System.Collections.Generic.List`1<int32>::GetEnumerator()
IL_000d: stloc.2 // V_2
.try
{
IL_000e: br IL_001f
// [72 9 - 72 41]
IL_0013: ldloca.s V_2
IL_0015: call instance !0/*int32*/ valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>::get_Current()
IL_001a: stloc.1 // current
// [73 9 - 73 23]
IL_001b: ldloc.0 // num
IL_001c: ldloc.1 // current
IL_001d: add
IL_001e: stloc.0 // num
// [70 7 - 70 36]
IL_001f: ldloca.s V_2
IL_0021: call instance bool valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>::MoveNext()
IL_0026: brtrue IL_0013
IL_002b: leave IL_003c
} // .try 结束
finally
{
IL_0030: ldloc.2 // V_2
IL_0031: box valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>
IL_0036: callvirt instance void [mscorlib]System.IDisposable::Dispose()
IL_003b: endfinally
} // finally 结束
IL_003c: ret
} // 方法 test::ILForeach结束
} // test 类结束
最相关的代码是靠近底部的 finally { … } 代码块。callvirt 指令在调用 IDisposable.Dispose 方法之前先发现该方法在内存中的位置,并要求将枚举器装箱。
通常,应在 Unity 中避免使用 foreach 循环。原因不仅是这些循环会进行装箱,而且通过枚举器遍历集合的方法调用成本更高,通常比通过 for 或 while 循环进行的手动迭代慢得多。
请注意,Unity 5.5 中的 C# 编译器升级版本显著提高了 Unity 生成 IL 的能力。特别值得注意的是,已从 foreach 循环中消除装箱操作。因此,节约了与 foreach 循环相关的内存开销。但是,由于方法调用开销,与基于数组的等效代码相比,CPU 性能差距仍然存在。
(6)Unity 数组值 API
虚数组分配的一种更有害和更不明显的原因是重复访问返回数组的 Unity API。返回数组的所有 Unity API 每次被访问时都会创建一个新的数组副本。在不必要的情况下访问数组值 Unity API 是极不适宜的。
例如,下面的代码在每次循环迭代时都会虚化创建 vertices 数组的四个副本。每次访问 .vertices 属性时都会发生分配。
for(int i = 0; i < mesh.vertices.Length; i++)
{
float x, y, z;
x = mesh.vertices[i].x;
y = mesh.vertices[i].y;
z = mesh.vertices[i].z;
// ...
DoSomething(x, y, z);
}
通过在进入循环之前捕获 vertices 数组,无论循环迭代次数是多少,都可以简单地重构为单个数组分配:
var vertices = mesh.vertices;
for(int i = 0; i < vertices.Length; i++)
{
float x, y, z;
x = vertices[i].x;
y = vertices[i].y;
z = vertices[i].z;
// ...
DoSomething(x, y, z);
}
虽然访问一次属性的 CPU 成本不是很高,但在紧凑循环内重复访问会使得 CPU 性能过热。此外,重复访问会导致托管堆出现不必要的扩展。
此问题在移动端极其常见,因为 Input.touches API 的行为与上述类似。项目包含以下类似代码是极为常见的,此情况下每次访问 .touches 属性时都会发生分配。
for ( int i = 0; i < Input.touches.Length; i++ )
{
Touch touch = Input.touches[i];
// …
}
当然,通过将数组分配从循环条件中提升出来,可轻松改善该问题:
Touch[] touches = Input.touches;
for ( int i = 0; i < touches.Length; i++ )
{
Touch touch = touches[i];
// …
}
但是,现在有许多 Unity API 的版本不会导致内存分配。如果能使用这些版本时,请尽量选择这种版本。
int touchCount = Input.touchCount;
for ( int i = 0; i < touchCount; i++ )
{
Touch touch = Input.GetTouch(i);
// …
}
将上面的示例转换为无分配的 Touch API 很简单:
请注意,为了节省调用属性的 get 方法的 CPU 成本,属性访问 (Input.touchCount) 仍然保持在循环条件之外。
(7)空数组重用
当数组值方法需要返回空集时,有些开发团队更喜欢返回空数组而不是 null。这种编码模式在许多托管语言中很常见,特别是 C# 和 Java。
通常情况下,从方法返回零长度数组时,返回零长度数组的预分配单例实例比重复创建空数组要高效得多(5)(__注意:__当然,在返回数组后调整数组大小时是个例外)
6字符串和文本
字符串和文本的处理不当是 Unity 项目中性能问题的常见原因。在 C# 中,所有字符串均不可变。对字符串的任何操作均会导致分配一个完整的新字符串。这种操作的代价相对比较高,而且在大型字符串上、大型数据集上或紧凑循环中执行时,接连不断的重复的字符串可能发展成性能问题。
此外,由于 N 个字符串连接需要分配 N–1 个中间字符串,串行连接也可能成为托管内存压力的主要原因。
如果必须在紧凑循环中或每帧期间对字符串进行连接,请使用 StringBuilder 执行实际连接操作。为最大限度减少不必要的内存分配,可重复使用 StringBuilder 实例。
a、区域约束与序数比对
在与字符串相关的代码中经常出现的核心性能问题之一是无意间使用了缓慢的默认字符串 API。这些 API 是为商业应用程序构建的,可根据与文本字符有关的多种不同区域性和语言规则来处理字符串。
例如,在美国英语区域设置下运行时,以下示例代码将返回 true,但在许多欧洲区域设置下,将返回 false (1)
注意: 从 Unity 5.3 和 5.4 开始,Unity 的脚本运行时始终在美国英语 (en-US) 区域设置下运行:
String.Equals("encyclopedia", "encyclopædia");
对于大多数 Unity 项目,上述代码完全没有必要。使用序数比对可将速度提高大约十倍,这种比较类型以 C 和 C++ 工程师熟悉的方式比较字符串:简单地比较字符串的每个连续字节,不考虑该字节所表示的字符。
切换至序数比对的方式非常简单,只需将 StringComparison.Ordinal 作为最终参数提供给 String.Equals:
myString.Equals(otherString, StringComparison.Ordinal);
b、低效的内置字符串 API
除了切换至序数比对以外,目前已知某些 C# String API 的效率极低,其中包括 String.Format、String.StartsWith 和 String.EndsWith。尽管 String.Format 难以替换,但低效率字符串比较方法很容易优化掉。
尽管 Microsoft 建议将 StringComparison.Ordinal 传递给任何不需要为本地化做调整的字符串比较,但 Unity 基准测试表明,相比自定义实现,该方法对性能的提升效果有限。
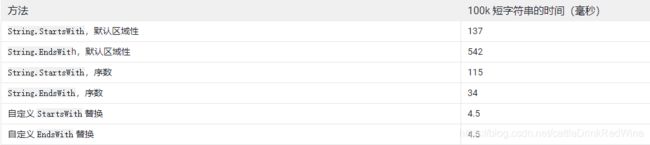
String.StartsWith 和 String.EndsWith 均可以替换为类似于以下示例的简单的手工编码版本。
public static bool CustomEndsWith(string a, string b) {
int ap = a.Length - 1;
int bp = b.Length - 1;
while (ap >= 0 && bp >= 0 && a [ap] == b [bp]) {
ap--;
bp--;
}
return (bp < 0 && a.Length >= b.Length) ||
(ap < 0 && b.Length >= a.Length);
}
public static bool CustomStartsWith(string a, string b) {
int aLen = a.Length;
int bLen = b.Length;
int ap = 0; int bp = 0;
while (ap < aLen && bp < bLen && a [ap] == b [bp]) {
ap++;
bp++;
}
return (bp == bLen && aLen >= bLen) ||
(ap == aLen && bLen >= aLen);
}
c、正则表达式
尽管正则表达式是匹配和操作字符串的强大方法,但它们可能对性能的影响极大。此外,由于 C# 库的正则表达式实现方式,即使简单的布尔值 IsMatch 查询也需要在底层分配大型瞬态数据结构。除非在初始化期间,否则这种瞬态托管内存波动都是不可接受的。
如果必须使用正则表达式,强烈建议不要使用静态 Regex.Match 或 Regex.Replace 方法,这些方法会将正则表达式视为字符串参数。这些方法即时编译正则表达式,并且不缓存生成的对象。
以下示例代码为无害的单行代码。
Regex.Match(myString, "foo");
但是,该代码每次执行时会产生 5 KB 的垃圾。通过简单的重构即可消除其中的大部分垃圾:
var myRegExp = new Regex("foo");
myRegExp.Match(myString);
在本示例中,每次调用 myRegExp.Match“只”产生 320 字节的垃圾。尽管这对于简单的匹配操作仍然代价高昂,但比前面的示例有了相当大的改进。
因此,如果正则表达式是不变的字符串字面值,通过将正则表达式传递为正则表达式对象构造函数的第一个参数来预编译它们,可显著提高效率。这些预编译的正则表达式之后会被重用。
d、XML、JSON 和其他长格式文本解析
解析文本通常是加载期间所发生的最繁重的操作之一。在某些情况下,解析文本所花费的时间可能超过加载和实例化资源所花费的时间。
此问题背后的原因取决于所使用的具体解析器。C# 的内置 XML 解析器极为灵活,但因此无法针对具体数据布局进行优化。
许多第三方解析器都是基于反射构建的。尽管反射在开发过程中是绝佳选择(因为它能让解析器快速适应不断变化的数据布局),但众所周知,它的速度非常慢。
Unity 引入了采用其内置 JSONUtility API 的部分解决方案,该解决方案提供了读取/发出 JSON 的 Unity 序列化系统接口。在大多数基准测试中,它比纯 C# JSON 解析器快,但它与 Unity 序列化系统的其他接口具有相同的限制:没有额外代码的情况下,无法对许多复杂的数据类型(如字典)进行序列化(2)(注意: 请参阅 ISerializationCallbackReceiver 接口,了解如何通过一种方法轻松添加必要的额外处理以便在 Unity 序列化过程中来回转换复杂数据类型)。
当遇到文本数据解析所引起的性能问题时,请考虑三种替代解决方案。
方案 1:在构建时解析
避免文本解析成本的最佳方法是完全取消运行时文本解析。通常,这意味着通过某种构建步骤将文本数据“烘焙”成二进制格式。
大多数选择使用该方法的开发者会将其数据移动到某种 ScriptableObject 衍生的类层级视图中,然后通过 AssetBundle 分配数据。有关使用 ScriptableObjects 的精彩讨论,请参阅 youtube 上 Richard Fine 的 Unite 2016 讲座。
该策略可实现尽可能高的性能,但只适用于不需要动态生成的数据。它适用于游戏设计参数和其他内容。
方案 2:拆分和延迟加载
第二种可行的方法是将必须解析的数据拆分为较小的数据块。拆分后,解析数据的成本可分摊到多个帧。在理想的情况下,可识别出为用户提供所需体验而需要的特定数据部分,然后只加载这些部分。
举一个简单的例子:如果项目为平台游戏,则没必要将所有关卡的数据一起序列。如果将数据拆分为每个关卡的独立资源,并且将关卡划分到区域中,则可以在玩家闯关到相应位置时再解析数据。
虽然这听起来不难,但实际上需要在工具编码方面投入大量精力,并可能需要重组数据结构。
方案 3:线程
如果数据完全解析成纯 C# 对象,并且不需要与 Unity API 进行任何交互,则可以将解析操作移至工作线程。
该方案在具有大量核心的平台上非常强大(3)(注意: iOS 设备最多有 2 个核心。大多数 Android 设备具有 2–4 个核心。该技术适用于针对电脑平台和游戏主机发布的项目。)但是,该方案需要仔细编程,以免产生死锁和竞态条件。
选择实现线程的项目通常使用内置的 C# Thread 和 ThreadPool 类(请参阅 msdn.microsoft.com)来管理其工作线程以及标准 C# 同步类。
7、一般优化
有多少原因导致性能问题,就有多少种不同的方式来优化代码。通常,强烈建议开发者在尝试应用 CPU 优化之前对其应用程序进行性能分析。不过,还是存在几种普遍适用的简易 CPU 优化方式。
a、按 ID 寻址属性
Unity 不使用字符串名称对 Animator、Material 和 Shader 属性进行内部寻址。为了加快速度,所有属性名称都经过哈希处理为属性 ID,实际上正是这些 ID 用于寻址属性。
因此,每当在 Animator、Material 或 Shader 上使用 Set 或 Get 方法时,请使用整数值方法而非字符串值方法。字符串方法只执行字符串哈希处理,然后将经过哈希处理的 ID 转发给整数值方法。
从字符串哈希创建的属性 ID 在单次运行过程中是不变的。它们最简单的用法是为每个属性名称声明一个静态只读整数变量,然后使用整数变量代替字符串。启动期间将自动进行初始化,无需其他初始化代码。
Animator.StringToHash 是用于 Animator 属性名称的对应 API,Shader.PropertyToID 是用于 Material 和 Shader 属性名称的对应 API。
b、使用非分配物理 API
在 Unity 5.3 及更高版本中,引入了所有物理查询 API 的非分配版本。将 RaycastAll 调用替换为 RaycastNonAlloc,将 SphereCastAll 调用替换为 SphereCastNonAlloc,以此类推。对于 2D 应用程序,也存在所有 Physics2D 查询 API 的非分配版本。
c、与 UnityEngine.Object 子类进行 Null 比较
Mono 和 IL2CPP 运行时以特定方式处理从 UnityEngine.Object 派生的类的实例。在实例上调用方法实际上是调用引擎代码,此过程必须执行查找和验证以便将脚本引用转换为对原生代码的引用。将此类型变量与 Null 进行比较的成本虽然低,但远高于与纯 C# 类进行比较的成本。因此,请避免在紧凑循环中或每帧运行的代码中进行此类 Null 比较。
d、矢量和四元数数学以及运算顺序
对于位于紧凑循环中的矢量和四元数运算,请记住整数数学比浮点数学更快,而浮点数学比矢量、矩阵或四元数运算更快。
因此,每当交换或关联算术允许时,请尝试最小化单个数学运算的成本:
Vector3 x;
int a, b;
// 效率较低:产生两次矢量乘法
Vector3 slow = a * x * b;
// 效率较高:一次整数乘法、一次矢量乘法
Vector3 fast = a * b * x;
e、内置 ColorUtility
对于必须在 HTML 格式的颜色字符串 (#RRGGBBAA) 与 Unity 的原生 Color 及 Color32 格式之间进行转换的应用程序来说,使用来自 Unify Community 的脚本是很常见的做法。由于需要进行字符串操作,此脚本不但速度很慢,而且会导致大量内存分配。
从 Unity 5 开始,有一个内置 ColorUtility API 可以有效执行此类转换。应优先使用内置 API。
f、Find 和 FindObjectOfType
一般来说,最好完全避免在生产代码中使用 Object.Find 和 Object.FindObjectOfType。由于此类 API 要求 Unity 遍历内存中的所有游戏对象和组件,因此它们会随着项目规模的扩大而产生性能问题。
在单例对象的访问器对上述规则来说是个例外。全局管理器对象往往会暴露“instance”属性,并且通常在 getter 中存在 FindObjectOfType 调用以便检测单例预先存在的实例:
class SomeSingleton {
private SomeSingleton _instance;
public SomeSingleton Instance {
get {
if(_instance == null) {
_instance =
FindObjectOfType<SomeSingleton>();
}
if(_instnace == null) {
_instance = CreateSomeSingleton();
}
return _instance;
}
}
}
虽然这种模式通常是可以接受的,但必须注意检查代码并确保调用访问器时场景中不存在单例对象。如果 getter 没有自动创建缺失单例的实例,那么寻找单例的代码经常会重复调用 FindObjectOfType(通常每帧多次发生)并且会对性能产生不良影响。
g、调试代码和 [conditional] 属性
UnityEngine.Debug 日志记录 API 并未从非开发版中剥离出去,如果被调用,则会写入日志。由于大多数开发者不打算在非开发版中写入调试信息,因此建议在自定义方法中打包仅用于开发用途的日志记录调用,如下所示:
public static class Logger {
[Conditional("ENABLE_LOGS")]
public static void Debug(string logMsg) {
UnityEngine.Debug.Log(logMsg);
}
}
通过使用 [Conditional] 属性来修饰这些方法,Conditional 属性所使用的一个或多个定义将决定被修饰的方法是否包含在已编译的源代码中。
如果传递给 Conditional 属性的任何定义均未被定义,则会被修饰的方法以及对被修饰方法的所有调用都会在编译中剔除。实际效果与包裹在 #if … #endif 预处理器代码块中的方法以及对该方法的所有调用的处理情况相同。
有关 Conditional 属性的更多信息,请参阅 MSDN 网站:msdn.microsoft.com。.
8、特别优化
a、多维数组与交错数组
遍历交错数组通常比遍历多维数组更高效,因为多维数组需要函数调用。
注意:
- 声明为 type[x][y] 则为数组的数组而与 type[x,y] 不同。
- 使用 ILSpy 或类似工具检查通过访问多维数组生成的 IL 即可发现此情况。
在 Unity 5.3 中进行性能分析时,在三维 100x100x100 数组上进行 100 次完全顺序的迭代得出了以下时间,这些值是通过 10 遍测试获得的平均结果:

根据访问多维数组与访问一维数组的成本差异,可看出额外函数调用的成本,而根据访问交错数组与访问一维数组的成本差异,可看出遍历非紧凑内存结构的成本。
如上所述,额外函数调用的成本大大超过了使用非紧凑内存结构所带来的成本。
如果操作对性能影响较大,建议使用一维数组。在任意其余情况下,如果需要一个具有多个维度的数组,请使用交错数组。不应使用多维数组。
注意:
type[x][y] :交错数组
type[x,y]: 多维数组
b、粒子系统池
对粒子系统建池时,请注意它们至少消耗 3500 字节的内存。内存消耗根据粒子系统上激活的模块数量而增加。停用粒子系统时不会释放此内存;只有销毁粒子系统时才会释放。
从 Unity 5.3 开始,大多数粒子系统设置都可在运行时进行操作。对于必须汇集大量不同粒子效果的项目,将粒子系统的配置参数提取到数据载体类或结构中可能更有效。
需要某种粒子效果时,“通用”粒子效果池即可提供必需的粒子效果对象。然后,可将配置数据应用于对象以实现期望的图形效果。
这种方案比尝试汇集给定场景中使用的粒子系统的所有可能变体和配置会更具内存使用效率,但需要大量的工程努力才能实现。
c、更新管理器
在内部,Unity 会跟踪感兴趣的列表中的对象的回调(例如 Update、FixedUpdate 和 LateUpdate)。这些列表以侵入式链接列表的形式进行维护,从而确保在固定时间进行列表更新。在启用或禁用 MonoBehaviour 时分别会在这些列表中添加/删除 MonoBehaviour。
虽然直接将适当的回调添加到需要它们的 MonoBehaviour 十分方便,但随着回调数量的增加,这种方式将变得越来越低效。从原生代码调用托管代码回调有一个很小但很明显的开销。这会导致在调用大量每帧都执行的方法时延长帧时间,而且在实例化包含大量 MonoBehaviour 的预制件时延长实例化时间(注意: 实例化成本归因于调用预制件中每个组件上的 Awake 和 OnEnable 回调时产生的性能开销)。
当具有每帧回调的 MonoBehaviour 数量增长到数百或数千时,删除这些回调并将 MonoBehaviour(甚至标准 C# 对象)连接到全局管理器单例可以优化性能。然后,全局管理器单例可将 Update、LateUpdate 和其他回调分发给感兴趣的对象。这种方式的另一个好处是允许代码在回调没有操作的情况下巧妙地将回调取消订阅,从而减少每帧必须调用的大量函数。
性能上最大的节约来自于消除很少执行的回调。请考虑以下伪代码:
void Update() {
if(!someVeryRareCondition) { return; }
// … 某种操作 …
}
如果大量 MonoBehaviour 具有上述类似 Update 回调,则运行 Update 回调所使用的大量时间会用于原生和托管代码域之间的切换以便执行 MonoBehaviour之后再立即退出。如果这些类仅在 someVeryRareCondition 为 true 时订阅了全局更新管理器 (Update Manager),随后又取消了订阅,则可节省代码域切换和稀有条件评估所需的时间。
在更新管理器中使用 C# 委托
通常很容易想到使用普通的 C# 委托来实现这些回调。但是,C# 的委托实现方式适用于较低频率的订阅和取消订阅以及少量的回调。每次添加或删除回调时,C# 委托都会执行回调列表的完整拷贝。在单个帧期间,大型回调列表或大量回调订阅/取消订阅会导致内部 Delegate.Combine 方法性能消耗达到峰值。
如果频繁发生添加/删除操作,请考虑使用专为快速插入/删除(而非委托)设计的数据结构。
d、加载线程控制
Unity 允许开发者控制用于加载数据的后台线程的优先级。这一点对于尝试在后台将 AssetBundle 流式传输到磁盘时尤为重要。
主线程和图形线程的优先级都是 ThreadPriority.Normal;任何具有更高优先级的线程都会抢占主线程/图形线程的资源并导致帧率不稳,而优先级较低的线程则不会。如果任何线程与主线程具有相同的优先级,则 CPU 会尝试为这些线程提供相同的时间,在多个后台线程执行繁重操作(例如 AssetBundle 解压缩)的情况下,这通常会导致帧率卡顿。
目前,可在三个位置控制该优先级。
首先,资源加载调用(如 Resources.LoadAsync 和 AssetBundle.LoadAssetAsync)的默认优先级来自于 Application.backgroundLoadingPriority 设置。如文档所述,此调用还限制了主线程用于集成资源的时间(注意: 大多数类型的 Unity 资源都必须“集成”到主线程上。集成期间将完成资源初始化并执行某些线程安全操作。这包括编写回调调用(例如 Awake 回调)的脚本。请参阅“资源管理”指南以了解更多详细信息,从而限制资源加载对帧时间的影响。
其次,每个异步资源加载操作以及每个 UnityWebRequest 请求都返回一个 AsyncOperation 对象以监控和管理该操作。此 AsyncOperation 对象会显示 priority 属性,该属性可用于调整各个操作的优先级。
最后,WWW 对象(例如从 WWW.LoadFromCacheOrDownload 调用返回的对象)会显示threadPriority 属性。请务必注意,WWW 对象不会自动使用 Application.backgroundLoadingPriority 设置作为其默认值;WWW 对象总是被默认为 ThreadPriority.Normal。
值得注意的是,用于底层系统在处理解压缩和加载数据时,不同 API 之间存在差异。Resources.LoadAsync 和 AssetBundle.LoadAssetAsync 由 Unity 的内部 PreloadManager 系统进行处理,该系统可管理自己的加载线程并执行自己的速率限制。UnityWebRequest 使用自己的专用线程池。WWW 在每次创建请求时都会生成一个全新的线程。
虽然所有其他加载机制都有内置的排队系统,但 WWW 却没有。在大量经过压缩的 AssetBundle 上调用 WWW.LoadFromCacheOrDownload 会生成相同数量的线程,这些线程随后会与主线程竞争 CPU 时间。这很容易导致帧率卡顿。
因此,使用 WWW 来加载和解压缩 AssetBundle 时,最佳做法是为创建的每个 WWW 对象的 threadPriority 设置适当的值。
e、大批量对象移动和 CullingGroup
正如“变换操作”部分所述,由于需要传播更改消息,移动大型变换层级视图的 CPU 成本相对较高。但是,在实际开发环境中,通常无法将层级视图精简为少量的游戏对象。
同时,在开发中最好仅运行那些能维持游戏世界可信度的行为,并去掉那些用户不会注意到的行为;例如,在具有大量角色的场景中,较好的做法是仅对屏幕上的角色执行网格蒙皮和动画驱动的变换运动。对于屏幕上看不到的角色,消耗 CPU 时间来计算模拟它们的纯视觉元素是种浪费。
使用 Unity 5.1 中首次引入的 CullingGroup API 可以很好地解决这两个问题。
不要直接操作场景中的一大群游戏对象,应该对系统进行更改以操作 CullingGroup 中的一群 BoundingSphere 的 Vector3 参数。每个 BoundingSphere 充当单个游戏逻辑实体的世界空间位置的表征,并在实体移动到 CullingGroup 主摄像机的视锥体附近/内部时接收回调。然后,可使用这些回调来激活/停用特定代码或组件(例如 Animator),从而控制那些仅应在实体可见时才需要运行的行为。
f、减少方法调用开销
C# 的字符串库提供了一个绝佳的案例研究,其中说明了向简单库代码添加额外方法调用的成本。在有关内置字符串 API String.StartsWith 和 String.EndsWith 的部分中,提到了手工编码的替换比内置方法快 10–100 倍,即使关闭了不需要的区域设置强制转换时也是如此。
这种性能差异的主要原因仅仅是向紧凑内循环添加额外方法调用的成本不同。调用的每个方法都必须在内存中找到该方法的地址,并将另一个帧推入栈。所有这些操作都是有成本的,但在大多数代码中,它们都小到可以忽略不计。
但是,在紧凑循环中运行较小的方法时,因引入额外方法调用而增加的开销可能会变得非常显著,甚至占主导地位。
请考虑以下两个简单方法。
示例 1:
int Accum { get; set; }
Accum = 0;
for(int i = 0; i < myList.Count; i++) {
Accum += myList[i];
}
示例 2:
int accum = 0;
int len = myList.Count;
for(int i = 0; i < len; i++) {
accum += myList[i];
}
这两个方法都在 C# 通用 List 中计算所有整数之和。第一个示例是更“现代的 C#”,因为它使用自动生成的属性来保存其数据值。
虽然从表面上看这两段代码似乎是等效的,但通过分析代码中的方法调用情况,可看出差异很明显。
示例 1:
int Accum { get; set; }
Accum = 0;
for(int i = 0;
i < myList.Count; // 调用 List::getCount
i++) {
Accum // 调用 set_Accum
+= // 调用 get_Accum
myList[i]; // 调用 List::get_Value
}
每次循环执行时都有四个方法调用:
- myList.Count 调用 Count 属性上的 get 方法
- 必须调用 Accum 属性上的 get 和 set 方法
- 通过 get 检索 Accum 的当前值,以便将其传递给加法运算
- 通过 set 将加法运算的结果分配给 Accum
- [] 运算符调用列表的 get_Value 方法来检索列表特定索引位置的项值。
示例 2:
int accum = 0;
int len = myList.Count;
for(int i = 0;
i < len;
i++) {
accum += myList[i]; // 调用 List::get_Value
}
在第二个示例中,get_Value 调用仍然存在,但已删除所有其他方法或不再是每个循环迭代便执行一次。
-
由于 accum 现在是原始值而不是属性,因此不需要进行方法调用来设置或检索其值。
-
由于假设 myList.Count 在循环运行期间不变化,其访问权限已移出循环的条件语句,因此不再在每次循环迭代开始时执行它。
这两个版本的执行时间显示了从这一特定代码片段中减少 75% 方法调用开销的真正优势。在现代台式机上运行 100,000 次的情况下:
- 示例 1 需要的执行时间为 324 毫秒
- 示例 2 需要的执行时间为 128 毫秒
这里的主要问题是 Unity 执行非常少的方法内联(即使有)。即使在 IL2CPP 下,许多方法目前也不能正确内联。对于属性尤其如此。此外,虚拟方法和接口方法根本无法内联。
因此,在源代码 C# 中声明的方法调用很可能最后在最终的二进制应用程序中产生方法调用。
g、简单属性
为了方便开发者,Unity 为数据类型提供了许多“简单”常量。但是,鉴于上述情况,必须注意这些常量通常作为返回常量值的属性。
Vector3.zero 的属性内容如下所示:
get { return new Vector3(0,0,0); }
Quaternion.identity 非常相似:
get { return new Quaternion(0,0,0,1); }
虽然访问这些属性的成本与它们周围的执行代码相比小的多,但它们每帧执行数千次(或更多次)时,可产生一定的影响。
对于简单的原始类型,请改用 const 值。Const 值在编译时内联 - 对 const 变量的引用将替换为其值。
**注意:**因为对 const 变量的每个引用都替换为其值,所以不建议声明长字符串或其他大型数据类型 const。否则,由于最终二进制代码中的所有重复数据,将导致不必要地增加最终二进制文件的大小。
当 const 不适合时,应使用 static readonly 变量。在有些项目中,即使 Unity 的内置简单属性也替换成了 static readonly 变量,使性能略有改善。
h、简单方法
简单方法比较棘手。如果能够在声明一次功能后在其他地方重用该功能,将非常有用。但是,在紧凑内部循环中,可能有必要打破美观编码规则,选择“手动内联”某些代码。
有些方法可能需要彻底删除。例如,Quaternion.Set、Transform.Translate 或 Vector3.Scale。这些方法执行非常简单的操作,可以用简单的赋值语句替换。
对于更复杂的方法,应权衡手动内联的性能提升与维护性能更高代码的长期成本之间的关系。
三、Shader
第一章、光照模型和实现
1、漫射(简单的兰伯特光照模型)
Diffuse =(LCMD)max(0,Dot(NL))
- LC(Light Color)是光照颜色和强度
- MD(Material Diffuse)是材质的漫反射颜色
- N(Normal)是表面法线向量
- L(Light)是光源的单位矢量
- max函数是为了防止法线和光源点乘结果为负,可防止物体被后面的光照照亮
Shader "Example/Diffuse Texture" {
Properties {
_MainTex ("Texture", 2D) = "white" {}
}
SubShader {
Tags { "RenderType" = "Opaque" }
CGPROGRAM
#pragma surface surf SimpleLambert
half4 LightingSimpleLambert (SurfaceOutput s, half3 lightDir, half atten) {
half NdotL = dot (s.Normal, lightDir);
half4 c;
c.rgb = s.Albedo * _LightColor0.rgb * (NdotL * atten);
c.a = s.Alpha;
return c;
}
struct Input {
float2 uv_MainTex;
};
sampler2D _MainTex;
void surf (Input IN, inout SurfaceOutput o) {
o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;
}
ENDCG
}
Fallback "Diffuse"
}
- half3 lightDir:是光线的方向
- half atten:表示光衰减的系数
- _LightColor0.rgb:光线的颜色(由Unity根据场景中的光源得到的,它在Lighting.cginc中有声明)
- s.Albedo:surf输出的颜色
这个简单的漫射光照模型使用了 LightingSimpleLambert 函数。它通过以下方式计算光照:计算表面法线和光线方向之间的点积,然后应用光衰减和颜色。
2、漫射环绕
...ShaderLab code...
CGPROGRAM
#pragma surface surf WrapLambert
half4 LightingWrapLambert (SurfaceOutput s, half3 lightDir, half atten) {
half NdotL = dot (s.Normal, lightDir);
half diff = NdotL * 0.5 + 0.5;
half4 c;
c.rgb = s.Albedo * _LightColor0.rgb * (diff * atten);
c.a = s.Alpha;
return c;
}
struct Input {
float2 uv_MainTex;
};
sampler2D _MainTex;
void surf (Input IN, inout SurfaceOutput o) {
o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;
}
ENDCG
...ShaderLab code...

3、卡通渐变 (Toon Ramp)
...ShaderLab code...
CGPROGRAM
#pragma surface surf Ramp
sampler2D _Ramp;
half4 LightingRamp (SurfaceOutput s, half3 lightDir, half atten) {
half NdotL = dot (s.Normal, lightDir);
half diff = NdotL * 0.5 + 0.5;
half3 ramp = tex2D (_Ramp, float2(diff)).rgb;
half4 c;
c.rgb = s.Albedo * _LightColor0.rgb * ramp * atten;
c.a = s.Alpha;
return c;
}
struct Input {
float2 uv_MainTex;
};
sampler2D _MainTex;
void surf (Input IN, inout SurfaceOutput o) {
o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;
}
ENDCG
...ShaderLab code...

4、简单镜面反射
以下示例显示了一个简单的镜面反射光照模型,类似于内置的 BlinnPhong 光照模型。
...ShaderLab code...
CGPROGRAM
#pragma surface surf SimpleSpecular
half4 LightingSimpleSpecular (SurfaceOutput s, half3 lightDir, half3 viewDir, half atten) {
half3 h = normalize (lightDir + viewDir);
half diff = max (0, dot (s.Normal, lightDir));
float nh = max (0, dot (s.Normal, h));
float spec = pow (nh, 48.0);
half4 c;
c.rgb = (s.Albedo * _LightColor0.rgb * diff + _LightColor0.rgb * spec) * atten;
c.a = s.Alpha;
return c;
}
struct Input {
float2 uv_MainTex;
};
sampler2D _MainTex;
void surf (Input IN, inout SurfaceOutput o) {
o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;
}
ENDCG
...ShaderLab code...
