动手学深度学习-21 模型微调
模型微调的基本概念
(1)什么是模型微调?
Step 1 :假设我们的神经网络符合下面形式:
Y = W * X
Step 2 :现在我们要找到一个W, 使得当 输入X = 4 时,输出Y = 2,也就是希望W = 0.5:
2 = W * 4
Step 3: 首先对W 要进行初始化, 初始化的值服从均值为0,方差为1的分布,假设W初始化为0.2:
Y = 0.2 * X
Step 4 :当 输入X = 4 时, W = 0.2, 输出Y = 0.8, 这个时候实际值和目标值2的误差是1.2 :
1<-----0.8 = 0.2 * 4
Step 5 :1.2的误差经过反向传播去更新权值W,假如这次更新为W = 0.4,输出为1.6,与目标值的误差为0.4:
1<-----1.6 = 0.4 * 4
Step 6 : 可能经过十次或二十次反向传播,W 终于等于我们想要的0.5:
Y = 0.5 * X
Step 7 : 如果在更新模型最开始有人告诉你,W的值应该在0.48附近:
Y = 0.48 * X
Step 8 : 那么从最开始训练,你与目标值的误差就只有0.08了,那么可能只要一步或者两步,就能将w训练到0.5:
1<----1.92 = 0.48 * 4
总结: Step 7就是相当于给你一个预训练模型(Pre-trained model),Step 8 就是基于这个模型微调(Fine Tune)。相对于你从头开始训练(Training a model from scatch),微调为你省去大量计算资源和计算时间,提高了计算效率,甚至提高准确率。
其中,预训练模型指的是(1) 预训练模型就是已经用数据集训练好了的模型。(2) 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19, Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数。(3) 正常情况下,我们常用的VGG16/19等网络已经是他人调试好的 优秀网络,我们无需再修改其网络结构。
Imagenet数据集是是目前世界上图像识别最大的数据库。
(2) 为什么要微调? 卷积神经网络的核心是:(1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。(2)深层卷积层提取抽象特征,比如整个脸型。(3)全连接层根据 特征组合进行评分分类。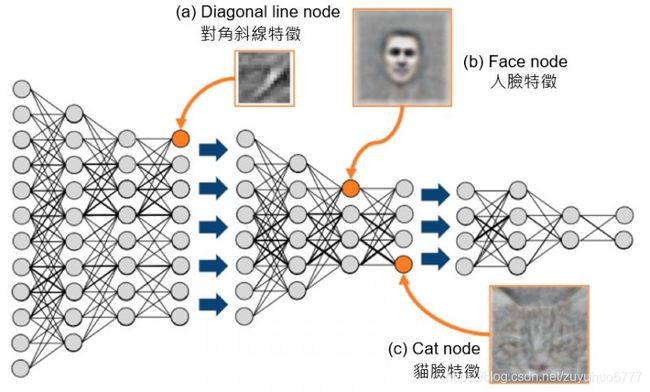
普通预训练模型的特点是:
用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
结论:
不做微调:
(1)从头开始训练,需要大量的数据,计算时间和计算资源。
(2)存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
使用微调:
(1)有效避免了上述可能存在的问题。(3) 什么情况下使用微调? (1) 你要使用的数据集和预训练模型的数据集相似,如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那 么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。 (2) 自己搭建或者使用的CNN模型正确率太低。 (3) 数据集相似,但数据集数量太少。 (4) 计算资源太少。
(4)不同数据集下使用微调
数据集1 - 数据量少,但数据相似度非常高:在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
数据集2 - 数据量少,数据相似度低 - 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相 似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
数据集3 - 数据量大,数据相似度低 - 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练 我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
数据集4 - 数据量大,数据相似度高 - 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的 初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。(5) 微调指导事项 (1) 通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的 网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网 络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。 (2) 使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使 初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。 (3) 如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕 捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
模型微调的基本概念
微调由以下4步构成。
1、在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。 2、创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。 3、为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。 4、在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。

当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
猫狗识别¶
接下来我们来实践一个具体的例子:猫狗识别。 我们将基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。
首先,导入实验所需的包或模块。torchvision的models包提供了常用的预训练模型。如果希望获取更多的预训练模型,可以使用使用pretrained-models.pytorch仓库。
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
from matplotlib import pyplot as plt
import os
import sys
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
import sys
sys.path.append('D:\\B站\\手把手教你学深度学习\\模型微调')#路径添加到系统的环境变量
data_dir='D:\\B站\\手把手教你学深度学习\\模型微调'
print(os.path.join(data_dir, 'data\\train'))
train_imgs = ImageFolder(os.path.join(data_dir, 'data\\train'))
test_imgs = ImageFolder(os.path.join(data_dir, 'data\\test'))
print(len(train_imgs))
print(len(test_imgs))
#output
D:\B站\手把手教你学深度学习\模型微调\data\train
20000
5000下面画出前10张正类图像【猫】和最后10张负类图像【狗】。可以看到,它们的大小和高宽比各不相同。
def show_images(imgs, num_rows, num_cols, scale=2):#显示num_rows*num_cols的图像
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j])
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axes
cats = [train_imgs[i][0] for i in range(10)]
dogs = [train_imgs[-i - 1][0] for i in range(10)]
show_images(cats + dogs, 2, 8, scale=1.8);

在训练时,我们先从图像中裁剪出随机大小和随机高宽比的一块随机区域,然后将该区域缩放为高和宽均为224像素的输入。测试时,我们将图像的高和宽均缩放为256像素,然后从中裁剪出高和宽均为224像素的中心区域作为输入。此外,我们对RGB(红、绿、蓝)三个颜色通道的数值做标准化:每个数值减去该通道所有数值的平均值,再除以该通道所有数值的标准差作为输出。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])#标准化
train_augs = transforms.Compose([
transforms.RandomResizedCrop(size=224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
test_augs = transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
normalize
])
定义和初始化模型
我们使用在ImageNet数据集上预训练的ResNet-18作为源模型。这里指定pretrained=True来自动下载并加载预训练的模型参数。
#pretrained_net = models.resnet18(pretrained=True)
pretrained_net = models.resnet18(pretrained=False)
pretrained_net.load_state_dict(torch.load(os.path.join(data_dir,'resnet18-5c106cde.pth')))#直接加载预训练模型的参数print(pretrained_net.parameters())
print(type(pretrained_net.parameters()))
list(pretrained_net.parameters())##返回的是一个list 
#打印模型
print(pretrained_net) 
#打印源模型的成员变量fc。作为一个预训练模型,它将ResNet最终的全局平均池化层输出变换成ImageNet数据集上1000类的输出。
print(pretrained_net.fc)
#Linear(in_features=512, out_features=1000, bias=True) 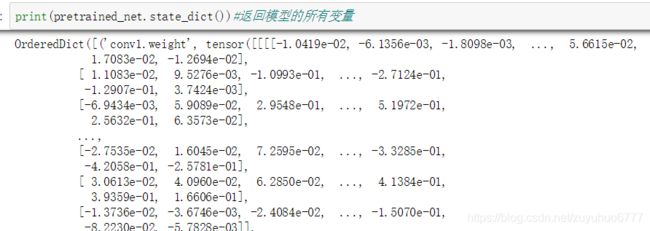
#可见此时pretrained_net最后的输出个数等于目标数据集的类别数1000。所以我们应该将最后的fc成修改我们需要的输出类别数
pretrained_net.fc = nn.Linear(512, 2)
print(pretrained_net.fc)
#Linear(in_features=512, out_features=2, bias=True)
此时,pretrained_net的fc层就被随机初始化了,但是其他层依然保存着预训练得到的参数。由于是在很大的ImageNet数据集上预训练的,所以参数已经足够好,因此一般只需使用较小的学习率来微调这些参数,而fc中的随机初始化参数一般需要更大的学习率从头训练。PyTorch可以方便的对模型的不同部分设置不同的学习参数,我们在下面代码中将fc的学习率设为已经预训练过的部分的10倍。
output_params = list(map(id, pretrained_net.fc.parameters()))# 返回的是parameters的 内存地址
feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters())
#feature_params 就是过滤 除最后一层全连接层的参数的其余参数,然后在优化器中为fc3层的参数单独设定学习率。
#参考链接:https://blog.csdn.net/jdzwanghao/article/details/90402577
lr = 0.01
optimizer = optim.SGD([{'params': feature_params},
{'params': pretrained_net.fc.parameters(), 'lr': lr * 10}],
lr=lr, weight_decay=0.001)
#参考链接;https://www.pytorchtutorial.com/docs/package_references/torch-optim/
#https://blog.csdn.net/jdzwanghao/article/details/90402577 给不同层分配不同的学习率微调模型
import time
def d2l_train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
def train_fine_tuning(net, optimizer, batch_size=128, num_epochs=5):
train_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'data\\train'), transform=train_augs),
batch_size, shuffle=True)#导入数据
test_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'data\\test'), transform=test_augs),
batch_size)
loss = torch.nn.CrossEntropyLoss()
d2l_train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
train_fine_tuning(pretrained_net, optimizer)
补充知识:加载部分预训练模型
resnet152 = models.resnet152(pretrained=True)
pretrained_dict = resnet152.state_dict()
"""加载torchvision中的预训练模型和参数后通过state_dict()方法提取参数
也可以直接从官方model_zoo下载:
pretrained_dict = model_zoo.load_url(model_urls['resnet152'])"""
model_dict = model.state_dict()
# 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
model.load_state_dict(model_dict)该章节的所有代码已经分享到群里:1039977800
【学习资料分享】
QQ群 1039977800
微信公众号 硬核的程序员
知乎 Xavier学长
B站 Xavier实验室

欢迎大家关注、点赞和评论奥