CNN反向传播过程
反向传播过程是深度学习的核心所在,虽然现在很多深度学习架构如Tensorflow等,已经自带反向传播过程的功能。我们只需要完成网络结构的正向传播的搭建,反向传播过程以及参数更新都是由架构本身来完成的。但为了更好的了解深度学习的机理,理解反向传播过程的原理还是很重要的。
在学习完吴恩达的深度学习课程后,对浅层神经网络的反向传播有了一个很清楚的认识。但在课程中对于深层神经网络和卷积神经网络反向传播过程,只给出了反向传播的公式。并没有给出具体的推导过程,所以在这一块之前一直不是很明白。通过最近几天的研究算是大体弄明白了整个过程,接下来写一下自己的心得体会和理解。
深层神经网络的反向传播过程
首先,为了量化预测结果的好坏。我们使用损失函数这样一个评价指标,来衡量预测结果与真实标签值之间的误差情况。
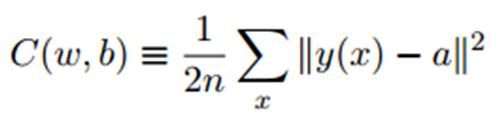
这里给出的是范数形式的损失函数,损失函数当然还可以有其他形式,例如交叉熵形式的等等。但损失函数的自变量都是网络结构中的参数,也就是说只与网络结构中的参数有关。
例如在这里w表示深层神经网络中所有权重参数的集合,b是每一层神经网络中的偏差,n是样本数量,x是神经网络的输入量,y是预测值,a是标签。前向传播过程: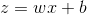 ,激活函数
,激活函数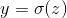 。
。
反向传播过程的推导与偏导数有关,并且都是基于链式法则进行的,接下来进行梯度下降法的推导:
1.首先是误差函数C关于输出层的L中每一个元素的偏导数:
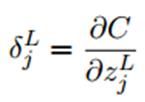
根据链式法则:
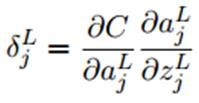
由于在前向传播过程中,激活函数
所以可以简化成:
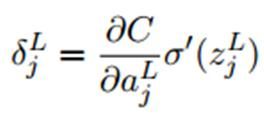
上式左边项为损失函数C关于输出层L激活值也就是预测值的偏导数。例如,如果损失函数C是二次项的形式,那么关于预测值的偏导数的值:
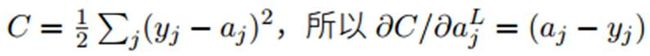
实际过程中这一项都是由损失函数决定的。
用矩阵形式来表示输出层L所有元素的偏导数:
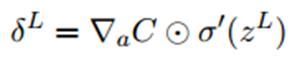
上式第一项是损失函数C关于预测值的梯度向量,中间这个运算符叫做哈达玛(Hadamard)乘积,用于矩阵或向量之间点对点的乘法运算:
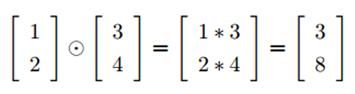
第二项是激活函数关于输出层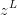 各元素导数构成的向量
各元素导数构成的向量
2.中间层各层的偏导数:
第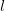 层第j个元素的偏导数:
层第j个元素的偏导数:
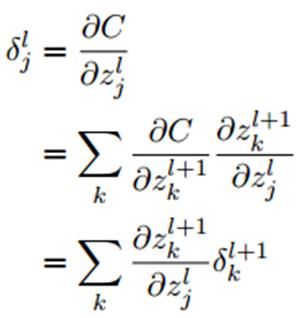
由于第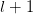 层中的k个输出值
层中的k个输出值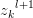 都含有
都含有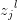 这一项,所以在第二行展开过程中根据函数求导法则,需要对的k个偏导数进行求和运算。
这一项,所以在第二行展开过程中根据函数求导法则,需要对的k个偏导数进行求和运算。
又由于:
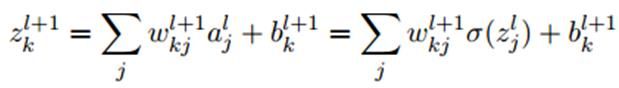
求中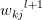 代表第层参数矩阵w的第k行第j列的元素
代表第层参数矩阵w的第k行第j列的元素
求导后得到:
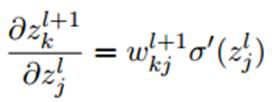
代入得到:
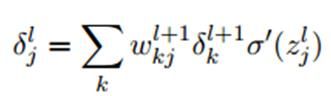
写成向量形式:
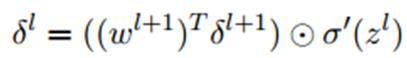
3.参数w及偏置b的偏导数:
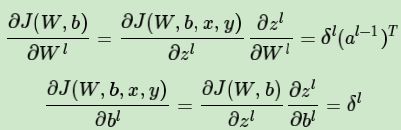
写成单个元素的形式:
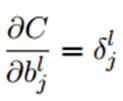
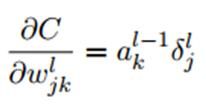
4.总结

卷积神经网络的反向传播过程
由于CNN的运算过程与DNN不一样,所以CNN的反向传播过程也有所不同。
首先简单介绍一下CNN的计算过程:
(1)卷积运算过程
之后的反向传播的推导也需要用到这个图,记为图1
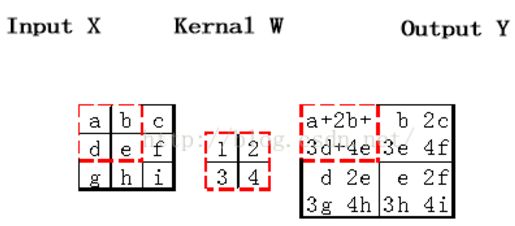
图1
图1描述的是CNN卷积核进行卷积的过程,卷积核与输入矩阵对应位置求积再求和,作为输出矩阵对应位置的值。如果输入矩阵inputX为M*N大小,卷积核为a*b大小,那么输出Y为(M-a+1)*(N-b+1)大小,这里假设步长为1。
(2)池化运算过程

上图所示的是最大池化,类似于卷积核在图片上的移动,这里是不断取核中4个值最大的那个值最为输出。平均池化与之类似,只不过输出的是四个位置的平均值。
(3)全连接层网络
全连接层的网络计算与之前DNN中的计算一样
CNN与DNN的不同
1.池化层在前向传播的时候,对输入进行了压缩,那么我们现在需要向前反向推导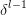 ,这个推导方法和DNN完全不同。
,这个推导方法和DNN完全不同。
2.卷积层是通过张量卷积,或者说若干个矩阵卷积求和而得的当前层的输出,这和DNN很不相同,DNN的全连接层是直接进行矩阵乘法得到当前层的输出。这样在卷积层反向传播的时候,上一层的递推计算方法肯定有所不同。
3.对于卷积层,由于W使用的运算是卷积,那么从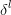 推导出该层的所有卷积核的W,b的梯度方式也不同。
推导出该层的所有卷积核的W,b的梯度方式也不同。
对于这三个问题,我们一个一个来解决
已知池化层的推导上一层的,这个过程一般称为upsample
假设池化的size为2*2,:
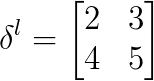
由于池化size为2*2,首先将size还原:
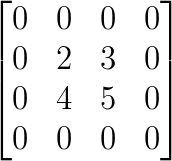
假设是最大池化,并且之前记录的最大值的位置为左上,右下,右上,左下。那么:
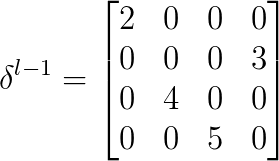
解释下为什么要这么做,在正向传播的时候,池化之前的四个最大值位置左上,右下,右上,左下,都以比例为1的系数传递到下一层。而其他位置对输出的贡献都为0,也就是说对池化输出没有影响,因此比例系数可以理解为0。所以在正向传播的过程中,最大值所在位置可以理解为通过函数f(x)=x传递到下一层,而其他位置则通过f(x)=0传递到下一层,并且把这些值相加构成下一层的输出,虽然f(x)=0并没有作用,但这样也就不难理解反向传播时,把的各个值移到最大值所在位置,而其他位置为0了。因为由f(x)=x,最大值位置的偏导数为1,而f(x)=0的偏导数为0。
如果平均池化,那么:
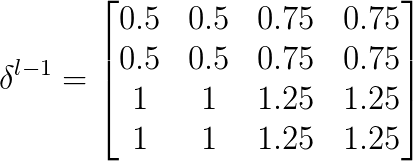
平均池化的话,池化操作的四个位置传递到下一层的作用可以等价为f(x)=x/4,所以在方向传播过程中就相当于把每一个位置的值乘1/4再还原回去。
所以由推导可以总结为:
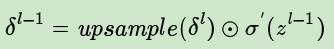
等式右边第一项表示上采样,第二项是激活函数的导数,在池化中可以理解为常数1(因为池化过程的正向传播过程中没有激活函数)。
已知卷积层的推导上一层的:
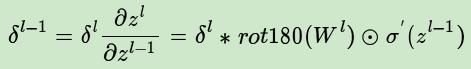
首先由链式法则:
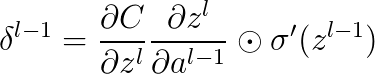
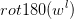 代表对卷积核进行翻转180°的操作,
代表对卷积核进行翻转180°的操作,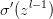 为激活函数的导数。这里比较难理解的是为什么要对卷积核进行180°的翻转。
为激活函数的导数。这里比较难理解的是为什么要对卷积核进行180°的翻转。
假设我们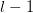 层的输出
层的输出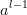 是一个3x3矩阵,第层的卷积核W是一个2x2矩阵,采用1像素的步幅,则输出
是一个3x3矩阵,第层的卷积核W是一个2x2矩阵,采用1像素的步幅,则输出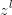 是一个2x2的矩阵。这里暂时不考虑偏置项b的影响。
是一个2x2的矩阵。这里暂时不考虑偏置项b的影响。
那么可得:
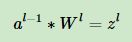
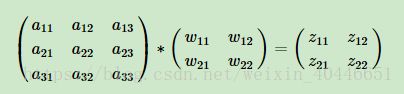
展开:

求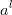 的梯度:
的梯度:
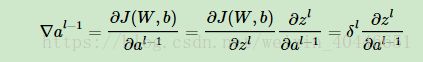
又由展开式:
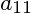 只与
只与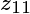 有关,并且系数为
有关,并且系数为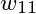 ,所以:
,所以:
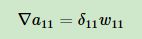
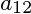 只与和
只与和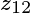 有关,并且系数分别为,
有关,并且系数分别为,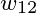 所以:
所以:

同理:
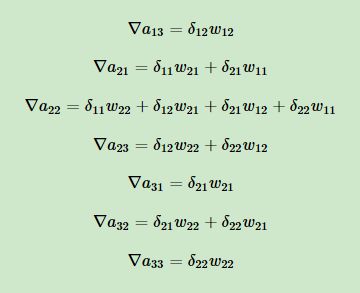
使用矩阵形式表示就是:
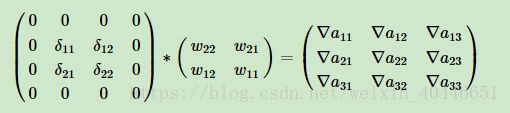
这就解释了为什么在反向传播时需要将卷积核进行180°的翻转操作了。
已知卷积层的推导w,b的梯度:
全连接层中的w,b的梯度与DNN中的推导一致,池化层没有w,b参数,所以不用进行w,b梯度的推导。
对于卷积层正向传播过程:
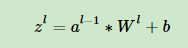
所以参数w的梯度:
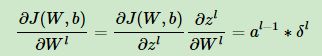
注意到这里并没有翻转180°的操作:
因为由之前的展开式:
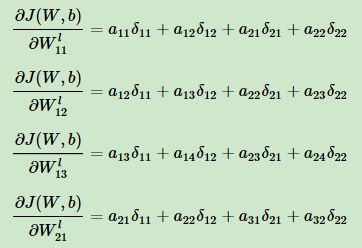
所以w的梯度:

这也就是没有进行翻转的原因。
b的梯度:
这里假设w=0,那么z=b,梯度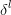 是三维张量,而b只是一个向量,不能像普通网络中那样直接和相等。通常的做法是将误差δ的各个子矩阵的项分别求和,得到一个误差向量所以这里b的梯度就是的各个通道对应位置求和:
是三维张量,而b只是一个向量,不能像普通网络中那样直接和相等。通常的做法是将误差δ的各个子矩阵的项分别求和,得到一个误差向量所以这里b的梯度就是的各个通道对应位置求和:
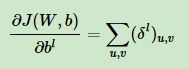
得到的是一个误差向量。
总结一下CNN的反向传播过程:
1 池化层的反向传播:
2 卷积层的反向传播
3 参数更新