Selective Kernel Networks
论文地址:https://arxiv.org/abs/1903.06586
在标准卷积神经网络(CNN)中,每层人工神经元的感受野被设计为相同的大小。神经科学界众所周知,视觉皮层神经元的感受野大小受到刺激的调节,这在构建CNN时很少被考虑。本文在CNN中提出了一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应调整其感受野大小。设计了一个称为选择性内核(SK)单元的构造块,其中,多个具有不同内核大小的分支使用softmax注意力进行融合,该注意力由这些分支中的信息引导。对这些分支的不同关注产生了融合层神经元有效感受野的不同大小。多个SK单元堆叠在一个称为选择性内核网络(SKNET)的深层网络中。
一、文章简介:
在这篇论文中,作者提出了一种非线性方法来聚合来自多个核的信息,以实现神经元的自适应RF大小。提出了一种“选择性核”(SK)卷积,它由三个操作符组成:分裂、融合和选择。分裂算子生成多条具有不同内核大小的路径,这些内核大小对应于神经元的不同RF大小。Fuse算子将来自多条路径的信息进行组合和聚合,以获得选择权重的全局和综合表示。选择算子根据选择权重聚合不同大小核的特征映射。
二、实现细节:
(一)、Selective Kernel Convolution
为了使神经元能够自适应地调整其RF大小,本文提出了一种自动选择操作,即在多个不同核大小的核之间进行“选择性核”(SK)卷积。具体来说,通过三个操作符实现SK卷积——分割、融合和选择,如下所示,其中显示了两个分支的情况。因此,在本例中,只有两个内核大小不同,但很容易扩展到多个分支的情况。
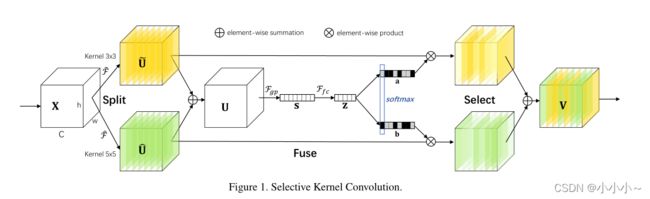
Split:
本分之内的卷积都是由高效的分组/深度卷积、批量标准化和ReLU函数按顺序组成的。为了进一步提高效率,将传统的5×5核卷积替换为3×3核的扩张卷积,扩张大小为2。
Fuse:
本文目标是使神经元能够根据刺激内容自适应地调整其RF大小。其基本思想是使用门来控制从多个分支到下一层神经元的信息流,这些分支携带不同规模的信息。 为了实现这一目标,需要整合所有分支的信息。首先通过元素求和融合多个(上图中的两个)分支的结果。
![]()
然后,通过简单地使用全局平均池化来嵌入全局信息,以生成通道相关的统计信息 S ∈ R C S∈ R^C S∈RC。具体而言,s的第c个元素是通过空间尺寸H×W收缩U来计算的:

此外,还有一个紧凑的功能部件 z ∈ R d × 1 z∈ R^{d×1} z∈Rd×1是为了实现精确和自适应选择的引导。这是通过一个简单的完全连接(fc)层实现的,通过降低维数来提高效率:
![]()
其中 δ δ δ是ReLU函数,B表示批次标准化, W ∈ R d × C W∈ R^{d×C} W∈Rd×C.为了研究d对模型效率的影响,使用缩减率r来控制其值:
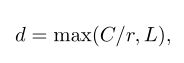
中L表示d的最小值
Select:
跨通道的软注意用于自适应地选择信息的不同空间尺度,这是由紧凑的特征描述符 z z z引导的。具体而言,在通道方向的数字上应用softmax操作符:
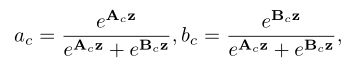
最终的特征图V是通过不同核上的注意权重获得的:
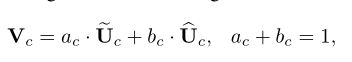
(二)、Network Architecture
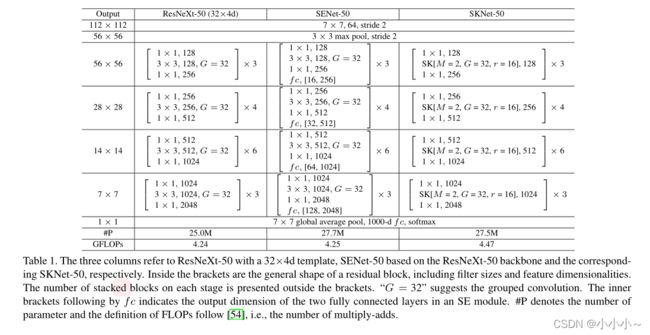
与ResNeXt类似,提议的SKNet主要由一堆重复的瓶颈块组成,称为“SK单元”。每个SK单元由1×1卷积、SK卷积和1×1卷积序列组成。一般来说,ResNeXt中原始瓶颈块中的所有大型内核卷积都被提议的SK卷积所取代,从而使网络能够自适应地选择合适的RF大小。由于SK在我们的设计中非常有效,与ResNeXt-50相比,SKNet-50只导致参数数量增加10%,计算成本增加5%。
在SK单元中,有三个重要的超参数决定SK卷积的最终设置:路径数M决定要聚合的不同内核的选择数,组号G控制每条路径的基数,以及控制fuse运算符中参数数量的缩减率r。我们将SK卷积SK[M,G,r]的一个典型设置表示为SK[2,32,16]。建议的SK卷积可应用于其他轻量级网络,例如MobileNet,ShuffleNet[,其中广泛使用3×3深度卷积。通过将这些卷积替换为SK卷积,我们还可以在紧凑的体系结构中获得非常吸引人的结果
三、消融实验
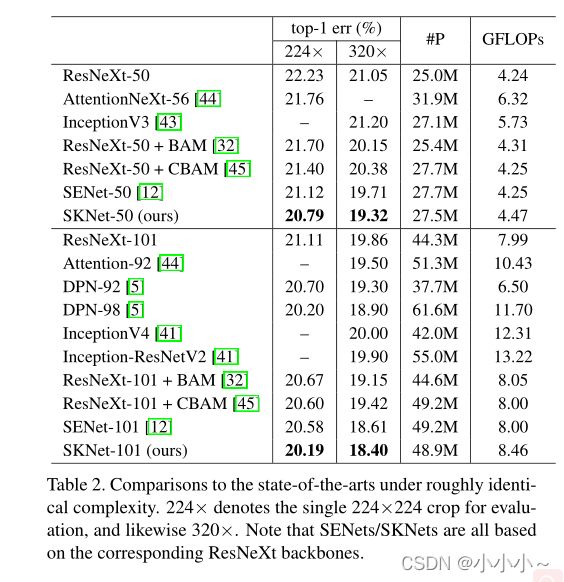
结果表明,在类似的预算下,与最先进的基于注意力的CNN相比,SKNET不断提高性能。值得注意的是,SKNet-50的性能比ResNeXt-101高出绝对0.32%,尽管ResNeXt-101的参数大60%,计算量大80%。与InceptionNets相比,SKNets的复杂度可与InceptionNets媲美或更低,其性能增益绝对值超过1.5%。
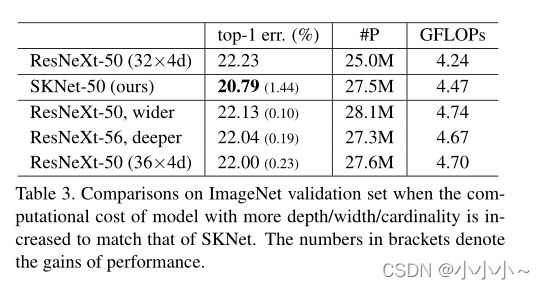
当模型更深入(从ResNeXt-50到ResNeXt-53为0.19%)或更宽(从ResNeXt-50到ResNeXt-50为0.1%)或基数稍大(从ResNeXt-50(32×4d)到ResNeXt-50(36×4d)为0.23%)时,改善幅度不大。相比之下,SKNet-50比ResNeXt-50获得1.44%的绝对改善,这表明SK卷积非常有效。

图中显示了三种体系结构,SK-26、SKNet-50和SKNet-101\Resnet、ResNeXts、DenseNets、DPNs和SENets。每个模型都有多个变体。可以看出,SKNET比这些模型更有效地利用参数。
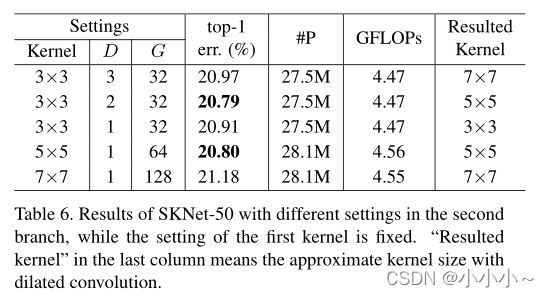
在SKNet-50的第一个内核分支中固定设置3×3滤波器,其膨胀率D=1,组G=32。在总体复杂度相似的约束下,有两种方法可以扩大第二个内核分支的RF:
1)在固定组数G的同时增加扩张D,
2)同时增加卷积核大小和组数G。上表显示,另一个分支的最佳设置是那些内核大小为5×5(最后一列)的分支,这比第一个大小为3×3的固定内核大。事实证明,使用不同的内核大小是有益的,我们将其归因于多尺度信息的聚合。有两种最佳配置:D=1的内核大小为5×5,D=2的内核大小为3×3,后者的模型复杂度略低。总的来说,具有各种膨胀的3×3核序列在性能和复杂度方面略优于具有相同RF(无膨胀的大核)的对应核序列。
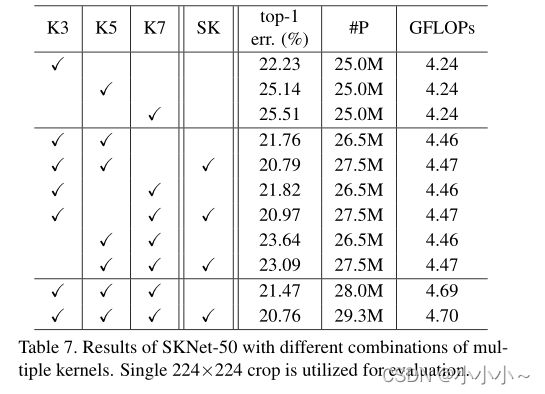
同时作者研究了不同大小卷积核组合的效果。有些核的大小可能大于3×3,并且可能有两个以上的核。为了限制搜索空间,作者只使用三种不同的核,称为“K3”(标准3×3卷积核)、“K5”(3×3卷积,扩展2到大约5×5核大小)和“K7”(3×3,扩展3到大约7×7核大小)。只考虑大内核(5×5和7×7)的扩展版本,G固定为32。如果下表中的“SK”被勾选,这意味着我们在同一行中勾选的对应内核中使用SK,否则只需将这些内核的结果(每个SK单元的输出为U)相加,作为一个简单的基线模型。
相关代码:
#被替换的3*3卷积
import torch.nn as nn
import torch
from functools import reduce
class SKConv(nn.Module):
def __init__(self,in_channels,out_channels,stride=1,M=2,r=16,L=32):
'''
:param in_channels: 输入通道维度
:param out_channels: 输出通道维度 原论文中 输入输出通道维度相同
:param stride: 步长,默认为1
:param M: 分支数
:param r: 特征Z的长度,计算其维度d 时所需的比率(论文中 特征S->Z 是降维,故需要规定 降维的下界)
:param L: 论文中规定特征Z的下界,默认为32
采用分组卷积: groups = 32,所以输入channel的数值必须是group的整数倍
'''
super(SKConv,self).__init__()
d=max(in_channels//r,L) # 计算从向量C降维到 向量Z 的长度d
self.M=M
self.out_channels=out_channels
self.conv=nn.ModuleList() # 根据分支数量 添加 不同核的卷积操作
for i in range(M):
# 为提高效率,原论文中 扩张卷积5x5为 (3X3,dilation=2)来代替。 且论文中建议组卷积G=32
self.conv.append(nn.Sequential(nn.Conv2d(in_channels,out_channels,3,stride,padding=1+i,dilation=1+i,groups=32,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
self.global_pool=nn.AdaptiveAvgPool2d(output_size = 1) # 自适应pool到指定维度 这里指定为1,实现 GAP
self.fc1=nn.Sequential(nn.Conv2d(out_channels,d,1,bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=True)) # 降维
self.fc2=nn.Conv2d(d,out_channels*M,1,1,bias=False) # 升维
self.softmax=nn.Softmax(dim=1) # 指定dim=1 使得两个全连接层对应位置进行softmax,保证 对应位置a+b+..=1
def forward(self, input):
batch_size=input.size(0)
output=[]
#the part of split
for i,conv in enumerate(self.conv):
#print(i,conv(input).size())
output.append(conv(input)) #[batch_size,out_channels,H,W]
#the part of fusion
U=reduce(lambda x,y:x+y,output) # 逐元素相加生成 混合特征U [batch_size,channel,H,W]
print(U.size())
s=self.global_pool(U) # [batch_size,channel,1,1]
print(s.size())
z=self.fc1(s) # S->Z降维 # [batch_size,d,1,1]
print(z.size())
a_b=self.fc2(z) # Z->a,b 升维 论文使用conv 1x1表示全连接。结果中前一半通道值为a,后一半为b [batch_size,out_channels*M,1,1]
print(a_b.size())
a_b=a_b.reshape(batch_size,self.M,self.out_channels,-1) #调整形状,变为 两个全连接层的值[batch_size,M,out_channels,1]
print(a_b.size())
a_b=self.softmax(a_b) # 使得两个全连接层对应位置进行softmax [batch_size,M,out_channels,1]
#the part of selection
a_b=list(a_b.chunk(self.M,dim=1))#split to a and b chunk为pytorch方法,将tensor按照指定维度切分成 几个tensor块 [[batch_size,1,out_channels,1],[batch_size,1,out_channels,1]
print(a_b[0].size())
print(a_b[1].size())
a_b=list(map(lambda x:x.reshape(batch_size,self.out_channels,1,1),a_b)) # 将所有分块 调整形状,即扩展两维 [[batch_size,out_channels,1,1],[batch_size,out_channels,1,1]
V=list(map(lambda x,y:x*y,output,a_b)) # 权重与对应 不同卷积核输出的U 逐元素相乘[batch_size,out_channels,H,W] * [batch_size,out_channels,1,1] = [batch_size,out_channels,H,W]
V=reduce(lambda x,y:x+y,V) # 两个加权后的特征 逐元素相加 [batch_size,out_channels,H,W] + [batch_size,out_channels,H,W] = [batch_size,out_channels,H,W]
return V # [batch_size,out_channels,H,W]
"""
x = torch.Tensor(8,32,24,24)
conv = SKConv(32,32,1,2,16,32)
print(conv(x).size())
"""