深度学习边缘计算综述论文阅读笔记
文章《Convergence of Edge Computing and Deep Learning: A Comprehensive Survey》
这是一篇关于深度学习和边缘计算基础知识的综述,包含了深度学习DL的几种网络模型的介绍,边缘计算的基础知识的介绍,以及二者的结合,如何利用DL来发展边缘计算,如何用边缘计算发展DL,怎么在边缘计算的框架下进行DL的训练,DL在边缘上运行的预测结果怎么样,二者怎么更好融合形成智慧边缘(Intelligent Edge)和边缘智慧(Edge Intelligent)。涉及到的知识很多,也很碎。基本上看完知道这个名词是什么就可以了,要是深挖的话,还是要看这篇文章的引用的论文。
作者在文章最后还针对每一个部分,提出了当前的问题与思考,如果想做这个方向的话,还是要着重看这一下这个部分。文章内容比较多,我对一些重要的主干内容做了整理。
介绍部分
传统的深度学习训练过程需要把数据传到云端进行集中式的训练,会占据网络带宽资源,并且有效率和延时问题。深度学习结合边缘计算,在数据源附近的网络边缘提供深度学习服务,可以解决这样的问题。把深度学习集成到边缘计算的框架,动态地,自适应的进行边缘的管理和维护,是未来的发展方向。
而且,深度学习在物联网,智慧城市等应用场景下应用有限,原因:
1. 代价,需要占用网络带宽;2.延时,获取云服务时间延时大;3.可靠性,网络不稳定;4.隐私性,不安全;边缘计算可以解决这些问题
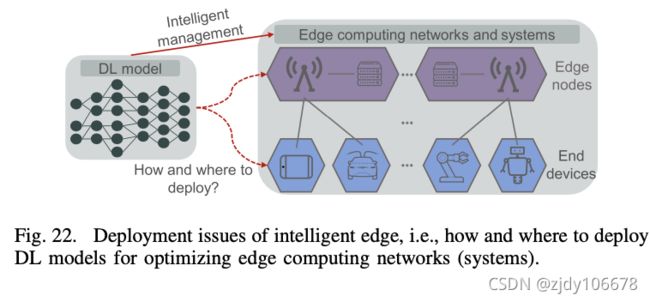
文章提出了两个概念,智慧边缘(Intelligent Edge)和边缘智慧(Edge Intelligent)。
边缘智能想尽可能的把深度学习计算从云端迁移到边缘,这样做有很多好处。智能边缘目的是把深度学习嵌入到边缘端的动态可适应管理和维护。
五个关键技术方向
-
综合使用Edge和DL,提供智能服务
-
DL在Edge的推理预测
-
为了发展DL的Edge,利用Edge思想,技术等来服务于DL的发展
-
在Edge端使用DL来训练模型,以完成特定的任务
-
使用DL技术,更大地促进Edge算力的充分使用
边缘计算基础
cloudlet和微小数据中心,雾计算,MEC(这些概念在上一篇博客介绍过了)
边缘节点(Edge node),微小云,雾节点,边缘服务器,MEC服务器
边缘终端(Edge device),移动设备,物联网设备
终端-边缘-云计算模式:由终端设备生成的计算强度较低的计算任务可以直接在终端设备上执行或卸载到边缘,从而避免了发送数据到云端带来的延时。对于计算密集型任务,将合理分割并分别发送到末端、边缘和云以执行,减少任务的执行延迟,同时确保结果的准确性。
边缘计算的AI硬件,GPU,FPGA,ASIC
边缘计算框架,对于配置复杂、资源需求密集的 DL 服务,具有先进卓越微服务架构的优势计算系统是未来发展方向。
KubeEdge(基于Kubernetes) 云与边缘之间的网络化、应用部署和元数据同步
OpenEdge 屏蔽计算框架和简化应用程序生成
Azure IoT Edge和EdgeX 在跨平台物联网设备上部署和运行 AI,设计用于将云智能传送到边缘。
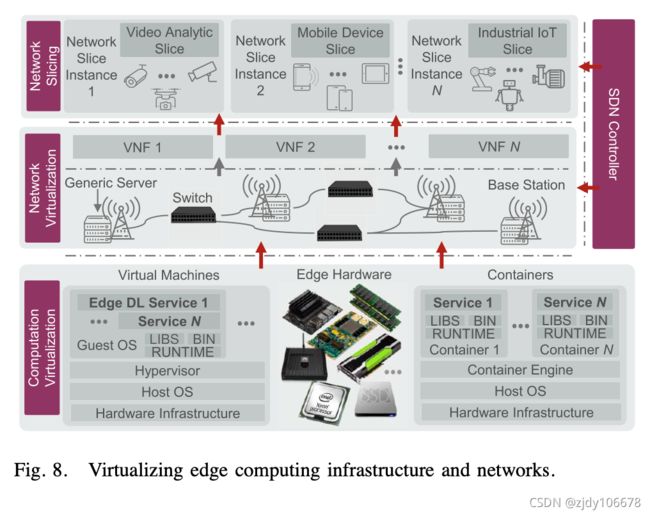
虚拟化技术:虚拟机和容器技术
网络功能虚拟化 (NFV) 通过将网络功能和服务与专用网络硬软件分离,使虚拟网络功能 (VNF) 能够在软件中运行。 -> 解决的是传统网络不够灵活
软件定义的网络 (SDN) 则通过三个关键创新 [72]实现服务快速部署、网络可编程性和多租赁支持: -> Edge DL需要高频段带宽、低延迟和动态网络配置。
1.控制与数据分离2.集中式可编程控制3.标准化应用程序编程界面
网络Slicing:网络切片是一种敏捷和虚拟的网络架构,是网络的高级抽象,允许在共同共享物理基础结构之上对多个网络实例进行加密,每个实体都针对特定服务进行了优化。
深度学习以及相关术语
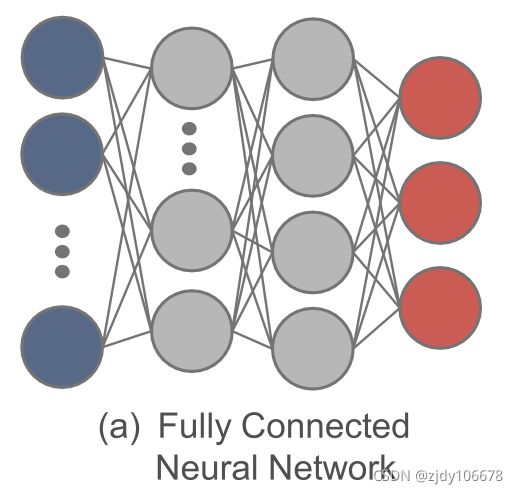
FCNNs 全连接的神经网络:FCNN 的每一层输出,即多层感知机都向前馈送到下一层。在连续的 FCNN 层之间,神经元 (细胞) 的输出(无论是输入细胞还是隐藏细胞)直接传递给下一层 ,由神经元直接传递和激活。FCNN 可用于功能提取和功能近似,但复杂度高、性能适中、收敛速度慢。
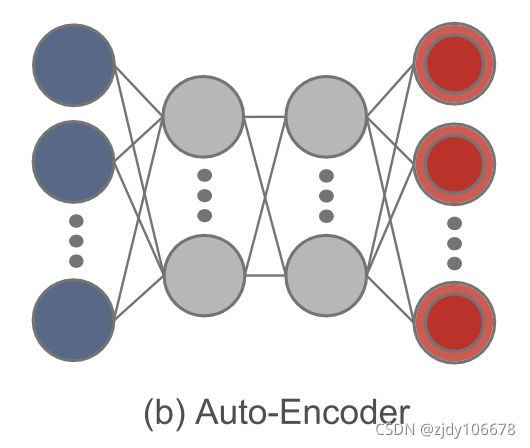
AE自动编码器:实际上是一叠两个 NN,以未经允许的学习方式复制输入到其输出中。第一个 NN 了解输入(编码)的代表性特征。第二个 NN 以这些功能为输入,并恢复匹配输入输出单元中原始输入的近似值,用于将身份函数从输入汇合到输出,作为最终输出(解码)。由于 AEs 能够学习输入数据的低维有用功能来恢复输入数据,因此它通常用于对高维数据 进行分类和存储。
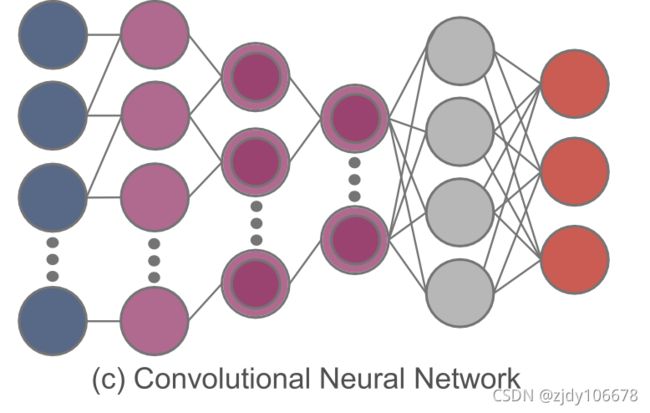
CNNs卷积神经网络:通过采用集合操作和一组不同的移动过滤器,CNN 抓住相邻数据块之间的相关性,然后对输入数据进行一个先后的更高层次的抽象。与 FCNN 相比,CNN 可以提取特征,同时降低模型的复杂性,从而降低过拟合的风险。
GAN对抗生成网络,源于博弈论。GAN 由生成器和歧视器组成。生成器的目标是通过故意在反馈输入单元中引入反馈来尽可能多地了解真实的数据分布,而歧视者则正确确定输入数据是来自真实数据还是生成器。这两位参与者需要不断优化他们在对抗过程中生成和区分的能力,直到找到纳什平衡 。
RNN循环神经网络,专为处理顺序数据而设计。RNN中的每个神经元不仅从上层接收信息,而且还从其自身的前一个通道接收信息。一般来说,RNN 是预测未来信息或恢复顺序数据缺失部分的自然选择。RNN的一个严重问题是梯度爆炸。
LSTM长短期记忆神经网络,通过添加门结构和定义明确的内存单元来改进RNN,可以通过控制(禁止或允许)信息流动来克服这个问题。
迁移学习 (TL): TL 可以将知识(如图 7(g)所示)从源域转移到目标域,以便在目标域 [85] 中实现更好的学习性能。通过使用 TL,大量计算资源学到的现有知识可以转移到一个新的场景中,从而加快培训过程并降低模型开发成本。
知识蒸馏(KD),可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。. 做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。
深度强化学习DRL:RL 的目标是使环境中的代理能够在当前状态下采取最佳操作,以最大限度地提高长期收益,其中代理的行为与环境状态之间的相互作用被建模为 Markov 决策过程 (MDP)。DRL 是 DL 和 RL 的组合,但它更注重 RL,旨在解决决策问题。DL的作用是利用DNN的强大表现能力来适应价值功能或直接策略,解决状态动作空间的爆炸性或连续状态动作空间问题。
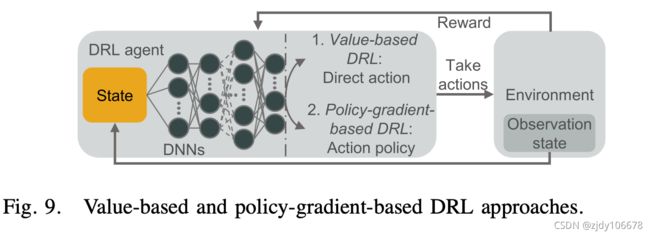
基于值的DRL:
DQL:使用 DNN 来适应动作值,成功地将高维输入数据映射到操作中
Double-DQL:高估计动作值的问题
Dueling-DQL:可以了解哪些状态是(或不是)有价值的,而不必了解每个状态下每个动作的效果。
基于策略梯度的 DRL:策略梯度是另一种常见的策略优化方法,如深度决策策略梯度 (DDPG) [91]、异步优势演员-批评 (A3C) [92]、近似策略优化 (PPO) [93] 等。它通过不断计算策略预期奖励的梯度来更新政策参数,并最终收敛到最佳策略 [94]。因此,在解决 DRL 问题时,DNN 可用于参数化策略,然后通过策略梯度方法进行优化。
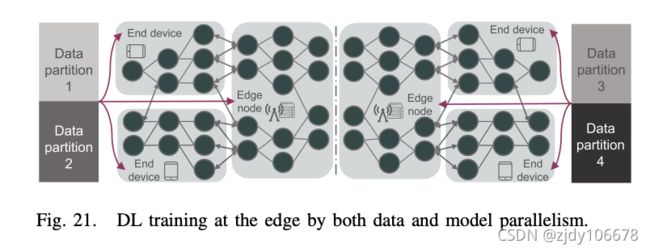
分布式深度学习训练:目前,集中培训DL模型耗时耗时和计算资源,阻碍了算法性能的进一步提高。尽管如此,分布式训练可以通过充分利用并行服务器来促进训练过程。数据并行和模型并行两种方式。
模型并行:首先将大型 DL 模型拆分为多个部分,然后提供数据样本,用于并行训练这些分段模型。这不仅能提高训练速度,还能应对模型大于设备内存的情况。训练大型 DL 模型通常需要大量的计算资源,甚至需要大量 CPU 来训练大型 DL 模型。为了解决这个问题,分布式 GPU 可用于模型并行训练 [99]。
数据并行:将数据划分为多个分区,然后分别与自己分配的数据样本同时训练模型副本。
DEEP LEARNING INFERENCE IN EDGE
A. 边缘 DL 模型的优化
DL 任务通常计算密集,需要大量内存。但在边缘,没有足够的资源来支持原始的大型DL模型。优化 DL 模型使其轻量化可以减少资源消耗。
B.DL模型细分
水平分割 DL 模型,即沿末端、边缘和云进行分区,是最常见的分段方法。
C.EEoI提前退出推理
EEoI是边缘网络中垂直协作的应用程序,它为在资源稀缺的终端设备上运行神经网络模型推断提供了一种有效的方法。
D.共享DL计算
EDGE COMPUTING FOR DEEP LEARNING
A.硬件
移动CPU,GPU,基于FPGA的解决方案
B.边缘 DL 的通信和计算模型
Integral Offloading(集成卸载);Partial Offloading(部分卸载);
vertical collaboration(垂直协作);horizontal collaboration(水平协作)
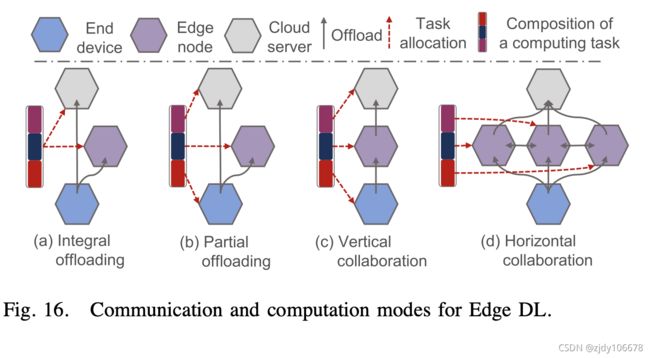
C. 自定义边缘 DL 框架
D.边缘 DL 的性能评估
DEEP LEARNING TRAINING AT EDGE
两种方案:
a.每个端设备根据本地数据训练模型,然后这些模型更新在边缘节点进行聚合。
b.边缘节点训练自己的本地模型,并交换和完善其模型更新,以构建一个全局模型。
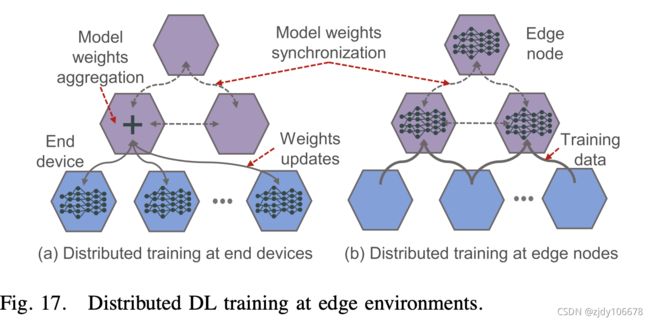
Vanilla Federated Learning at Edge(朴素联邦学习);Communication-Efficient FL(有效通信联邦学习);Resource-Optimized FL(资源优化联邦学习);Security-Enhance FL 增强安全联邦学习
DEEP LEARNING FOR OPTIMIZING EDGE
A. 自适应边缘缓存的 DL(缓存一部分内容到边缘服务器上)
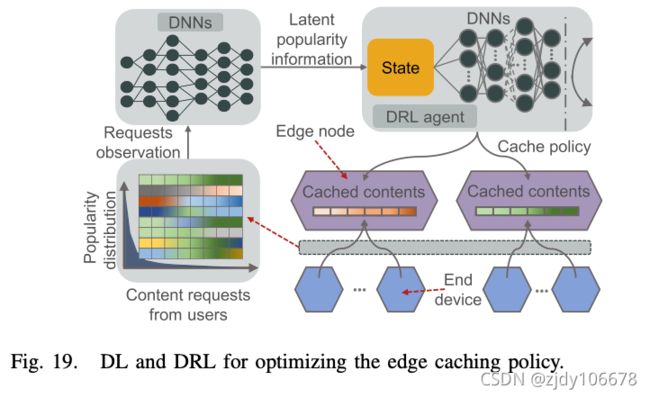
B. 用于优化边缘任务卸载的 DL
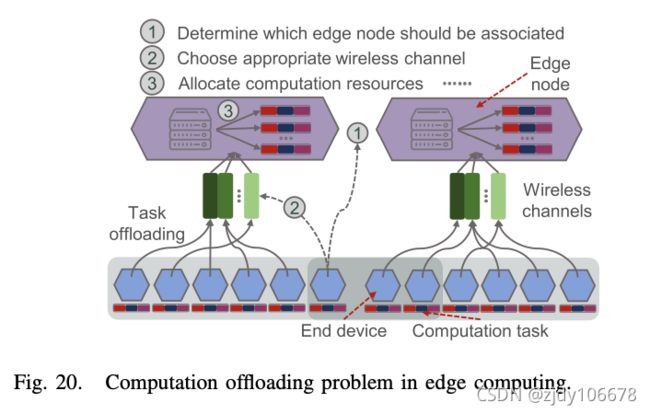
C. 边缘管理和维护 DL
边缘DL服务部署在蜂窝网络,需要在很多方面进行优化,比如在无线通信方面上使用DL
边缘安全
边缘设备更容易受到DDoS攻击(分布式拒绝服务攻击)此外,边缘设备应该使用DL方法识别出窃听和干扰攻击的特征,根据被攻击的类型选择合适的保护方案。
eavesdropping attack窃听攻击,也称为嗅探或窥探,依靠不安全的网络通信来访问设备之间传输的数据。为了进一步定义窃听,它通常发生在用户连接到流量未受保护或加密的网络并向同事发送敏感业务数据时。
jamming attack干扰攻击,攻击者故意在无线网络上传输干扰信号。因此,它降低了接收方的信号与噪声比,并中断了现有的无线通信。干扰攻击使用故意无线电干扰,使通信介质保持忙碌。
基于DRL的安全方案可以提供安全的计算卸载,来防御干扰攻击或者保护用户的定位以及使用习惯等隐私。边缘设备监测边缘节点的位置和攻击特性来决定安全协议的防护等级和关键参数。
基于DQL的安全方案,同样也可以解决一部分的攻击问题。
联合边缘优化
边缘计算能够迎合快速增长的智能设备,大量计算密集型和数据消耗型的应用的增长。然而,它同时使得未来的网络运营更加地复杂。为了管理如此局的网,需要联合边缘优化。
一些思考和讨论
文章在介绍DL和Edge技术的同时,也在理清这两个方向存在的挑战和潜在的错误方向。
A更多潜在的应用
边缘计算架构,接近用户,可以利用云形成混合游戏架构。此外,智能驾驶涉及语音识别、图像识别、智能决策等。分析交通流量,保证驾驶安全。
文章的大体内容就是这些,我也是在通过这篇文章扫盲,有些地方理解的不是很好,慢慢来吧,后面可能看多了这方面的文章,再回来看这篇文章的话会有新的理解,加油!