keras scikit
介绍(Introduction)
Keras is one of the most popular go-to Python libraries/APIs for beginners and professionals in deep learning. Although it started as a stand-alone project by François Chollet, it has been integrated natively into TensorFlow starting in Version 2.0. Read more about it here.
对于深度学习的初学者和专业人员,Keras是最受欢迎的Python图书馆/ API之一。 尽管它是由FrançoisChollet作为一个独立项目启动的,但从版本2.0开始,它已被本地集成到TensorFlow中。 在此处了解更多信息。
As the official doc says, it is “an API designed for human beings, not machines” as it “follows best practices for reducing cognitive load”.
正如官方文档所说,它是“为人类而不是机器设计的API ”,因为它“遵循了减少认知负担的最佳实践”。

One of the situations, where the cognitive load is sure to increase, is hyperparameter tuning. Although there are so many supporting libraries and frameworks for handling it, for simple grid searches, we can always rely on some built-in goodies in Keras.
肯定会增加认知负荷的一种情况是超参数调整。 尽管有很多支持它的库和框架来处理它,但是对于简单的网格搜索,我们始终可以依靠Keras中的一些内置功能。
In this article, we will quickly look at one such internal tool and examine what we can do with it for hyperparameter tuning and search.
在本文中,我们将快速查看一个这样的内部工具,并研究如何使用它进行超参数调整和搜索。
Scikit学习交叉验证和网格搜索 (Scikit-learn cross-validation and grid search)
Almost every Python machine-learning practitioner is intimately familiar with the Scikit-learn library and its beautiful API with simple methods like fit, get_params, and predict.
几乎每位Python机器学习从业人员都非常熟悉Scikit-learn库及其漂亮的API,并具有诸如fit , get_params和predict简单方法。
The library also offers extremely useful methods for cross-validation, model selection, pipelining, and grid search abilities. If you look around, you will find plenty of examples of using these API methods for classical ML problems. But how to use the same APIs for a deep learning problem that you have encountered?
该库还为交叉验证,模型选择,流水线和网格搜索功能提供了非常有用的方法。 如果四处看看,您会发现很多使用这些API方法解决经典ML问题的示例。 但是,如何针对遇到的深度学习问题使用相同的API?
One of the situations, where the cognitive load is sure to increase, is hyperparameter tuning.
肯定会增加认知负荷的一种情况是超参数调整。
当Keras与Scikit学习结合时 (When Keras enmeshes with Scikit-learn)
Keras offer a couple of special wrapper classes — both for regression and classification problems — to utilize the full power of these APIs that are native to Scikit-learn.
Keras提供了一些特殊的包装类(用于回归和分类问题),以利用Scikit学习固有的这些API的全部功能。
In this article, let me show you an example of using simple k-fold cross-validation and exhaustive grid search with a Keras classifier model. It utilizes an implementation of the Scikit-learn classifier API for Keras.
在本文中,让我向您展示一个示例,该示例将简单的k折交叉验证和详尽的网格搜索与Keras分类器模型一起使用。 它利用了Keras的Scikit-learn分类器API的实现。
The Jupyter notebook demo can be found here in my Github repo.
Jupyter笔记本演示可以在我的Github存储库中找到。
从模型生成功能开始 (Start with a model generating function)
For this to work properly, we should create a simple function to synthesize and compile a Keras model with some tunable arguments built-in. Here is an example,
为了使它正常工作,我们应该创建一个简单的函数来合成和编译带有一些内置可调参数的Keras模型。 这是一个例子
数据(Data)
For this demo, we are using the popular Pima Indians Diabetes. This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. So, it is a binary classification task.
对于此演示,我们使用流行的Pima Indians Diabetes 。 该数据集最初来自美国国立糖尿病与消化及肾脏疾病研究所。 数据集的目的是基于数据集中包含的某些诊断测量值来诊断预测患者是否患有糖尿病。 因此,这是一个二进制分类任务。
We create features and target vectors —
XandY我们创建特征和目标向量
X和YWe scale the feature vector using a scaling API from Scikit-learn like
MinMaxScaler. We call thisX_scaled.我们使用Scikit-learn的缩放API(如
MinMaxScaler缩放特征向量。 我们称其为X_scaled。
That’s it for data preprocessing. We can pass this X_scaled and Y directly to the special classes, we will build next.
数据预处理就是这样。 我们可以将X_scaled和Y直接传递给特殊类,接下来我们将进行构建。
Keras offer a couple of special wrapper classes — both for regression and classification problems — to utilize the full power of these APIs that are native to Scikit-learn.
Keras提供了一些特殊的包装类(用于回归和分类问题),以利用Scikit学习固有的这些API的全部功能。
KerasClassifier类 (The KerasClassifier class)
This is the special wrapper class from Keras than enmeshes the Scikit-learn classifier API with Keras parametric models. We can pass on various model parameters corresponding to the create_model function, and other hyperparameters like epochs, and batch size to this class.
这是Keras的特殊包装器类,而不是将Scikit-learn分类器API与Keras参数模型结合在一起。 我们可以将与create_model函数相对应的各种模型参数以及诸如纪元和批处理大小的其他超参数传递给此类。
Here is how we create it,
这是我们如何创建它,

Note, how we pass on our model creation function as the build_fn argument. This is an example of using a function as a first-class object in Python where you can pass on functions as regular parameters to other classes or functions.
请注意,我们如何将模型创建功能作为build_fn参数build_fn 。 这是在Python中将函数用作第一类对象的示例,您可以在其中将函数作为常规参数传递给其他类或函数。
For now, we have fixed the batch size and the number of epochs we want to run our model for because we just want to run cross-validation on this model. Later, we will make these as hyperparameters and do a grid search to find the best combination.
目前,我们已经确定了要运行模型的批次大小和时期数,因为我们只想在此模型上运行交叉验证。 稍后,我们将这些作为超参数,并进行网格搜索以找到最佳组合。
10倍交叉验证 (10-fold cross-validation)
Building a 10-fold cross-validation estimator is easy with Scikit-learn API. Here is the code. Note how we import the estimators from the model_selectionS module of Scikit-learn.
使用Scikit-learn API,构建10倍交叉验证估算器非常容易。 这是代码。 注意我们如何从Scikit-learn的model_selection S模块中导入估计量。

Then, we can simply run the model with this code, where we pass on the KerasClassifier object we built earlier along with the feature and target vectors. The important parameter here is the cv where we pass the kfold object we built above. This tells the cross_val_score estimator to run the Keras model with the data provided, in a 10-fold Stratified cross-validation setting.
然后,我们可以使用此代码简单地运行模型,在此传递我们先前构建的KerasClassifier对象以及特征和目标矢量。 这里的重要参数是cv ,我们在其中传递上面构建的kfold对象。 这会告诉cross_val_score估算器在10倍的分层交叉验证设置中使用提供的数据运行cross_val_score模型。

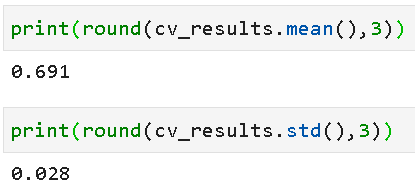
The output cv_results is a simple Numpy array of all the accuracy scores. Why accuracy? Because that’s what we chose as the metric in our model compiling process. We could have chosen any other classification metric like precision, recall, etc. and, in that case, that metric would have been calculated and stored in the cv_results array.
输出cv_results是所有准确度得分的简单Numpy数组。 为什么要准确性? 因为这就是我们在模型编译过程中选择的指标。 我们可以选择其他任何分类指标,例如精度,召回率等,在这种情况下,该指标应已计算并存储在cv_results数组中。
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])We can easily calculate the average and standard deviation of the 10-fold CV run to estimate the stability of the model predictions. This is one of the primary utilities of a cross-validation run.
我们可以轻松地计算出10倍CV运行的平均值和标准偏差,以估计模型预测的稳定性。 这是交叉验证运行的主要工具之一。
增强模型创建功能以进行网格搜索 (Beefing up the model creation function for grid search)
Exhaustive (or randomized) grid search is often a common practice for hyperparameter tuning or to gain insights into the working of a machine learning model. Deep learning models, being endowed with a lot of hyperparameters, are prime candidates for such a systematic search.
详尽的(或随机的)网格搜索通常是用于超参数调整或获得对机器学习模型工作的见解的常见实践。 拥有大量超参数的深度学习模型是此类系统搜索的主要候选者。
In this example, we will search over the following hyperparameters,
在此示例中,我们将搜索以下超参数,
activation function
激活功能
optimizer type
优化器类型
initialization method
初始化方法
batch size
批量
number of epochs
纪元数
Needless to say that we have to add the first three of these parameters to our model definition.
不用说,我们必须将这些参数的前三个添加到模型定义中。

Then, we create the same KerasClassifier object as before,
然后,我们创建与之前相同的KerasClassifier对象,

搜索空间 (The search space)
We decide to make the exhaustive hyperparameter search space size as 3×3×3×3×3=243.
我们决定将穷举式超参数搜索空间的大小设置为3×3×3×3×3 = 243。
Note that the actual number of Keras runs will also depend on the number of cross-validation we choose, as cross-validation will be used for each of these combinations.
请注意,实际的Keras运行次数还取决于我们选择的交叉验证次数,因为交叉验证将用于这些组合中的每一个。
Here are the choices,
这是选择

That’s a lot of dimensions to search over!
要搜索的维度很多!

用Keras融合Scikit学习GridSearchCV (Enmeshing Scikit-learn GridSearchCV with Keras)
We have to create a dictionary of search parameters and pass it on to the Scikit-learn GridSearchCV estimator. Here is the code,
我们必须创建一个搜索参数字典,并将其传递给Scikit-learn GridSearchCV估计器。 这是代码,

By default, GridSearchCV runs a 5-fold cross-validation if the cv parameter is not specified explicitly (from Scikit-learn v0.22 onwards). Here, we keep it at 3 for reducing the total number of runs.
默认情况下,如果未明确指定cv参数(从Scikit-learn v0.22开始),则GridSearchCV会进行5倍交叉验证。 在这里,我们将其保持为3,以减少运行总数。
It is advisable to set the verbosity of GridSearchCVto 2 to keep a visual track of what’s going on. Remember to keep the verbose=0 for the main KerasClassifier class though, as you probably don't want to display all the gory details of training individual epochs.
建议将GridSearchCV的详细程度设置为2,以直观了解发生的情况。 但是请记住,要为主KerasClassifier类保留verbose=0 ,因为您可能不想显示训练各个时期的所有细节。
然后,就好了! (Then, just fit!)
As we all have come to appreciate the beautifully uniform API of Scikit-learn, it is the time to call upon that power and just say fit to search through the whole space!
众所周知,Scikit-learn的API统一统一,是时候使用这种功能了,只是说fit在整个空间中搜索!


Grab a cup of coffee because this may take a while depending on the deep learning model architecture, dataset size, search space complexity, and your hardware configuration.
抢一杯咖啡,因为这可能需要一段时间,具体取决于深度学习模型的架构,数据集的大小,搜索空间的复杂性以及您的硬件配置。
In total, there will be 729 fittings of the model, 3 cross-validation runs for each of the 243 parametric combinations.
总共将有729个模型拟合,对243个参数组合中的每一个进行3次交叉验证。
If you don’t like full grid search, you can always try the random grid search from Scikit-learn stable!
如果您不喜欢全网格搜索,可以随时尝试从Scikit-learn stable进行随机网格搜索!
How does the result look like? Just like you expect from a Scikit-learn estimator, with all the goodies stored for your exploration.
结果如何? 就像您对Scikit-learn估算器所期望的那样,所有的好东西都存储在您的探索中。

您可以如何处理结果? (What can you do with the result?)
You can explore and analyze the results in a number of ways based on your research interest or business goal.
您可以根据自己的研究兴趣或业务目标以多种方式探索和分析结果。
最佳精度的结合是什么? (What’s the combination of the best accuracy?)
This is probably on the top of your mind. Just print it using the best_score_ and best_params_ attributes from the GridSearchCV estimator.
这可能是您的首要任务。 只需使用GridSearchCV估算器的best_score_和best_params_属性进行打印best_score_ 。

We did the initial 10-fold cross-validation using ReLU activation and Adam optimizer and got an average accuracy of 0.691. After doing an exhaustive grid search, we discover that tanh activation and rmsprop optimizer could have been better choices for this problem. We got better accuracy!
我们使用ReLU激活和Adam优化器进行了最初的10倍交叉验证,平均准确度为0.691。 经过详尽的网格搜索之后,我们发现tanh激活和rmsprop优化器可能是解决此问题的更好选择。 我们有更好的准确性!
将所有结果提取到DataFrame中 (Extract all the results in a DataFrame)
Many a time, we may want to analyze the statistical nature of the performance of a deep learning model under a wide range of hyperparameters. To that end, it is extremely easy to create a Pandas DataFrame from the grid search results and analyze them further.
很多时候,我们可能想分析各种超参数下深度学习模型性能的统计性质。 为此,从网格搜索结果创建Pandas DataFrame并进行进一步分析非常容易。

Here is the result,
结果是这样

视觉分析(Analyze visually)
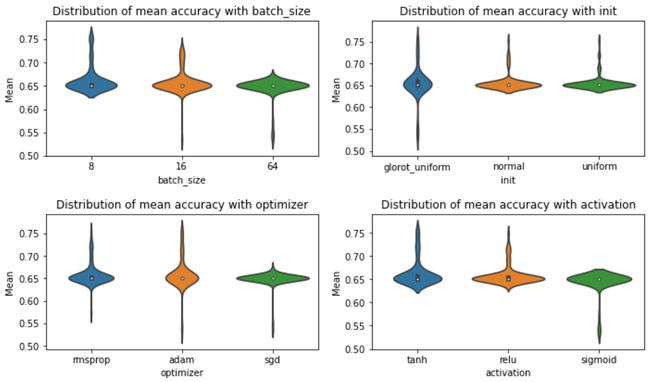
We can create beautiful visualizations from this dataset to examine and analyze what choice of hyperparameters improves the performance and reduces the variation.
我们可以从该数据集中创建漂亮的可视化效果,以检查和分析选择哪种超参数可以提高性能并减少变化。
Here is a set of violin plots of the mean accuracy created with Seaborn from the grid search dataset.
这是使用Seaborn从网格搜索数据集中创建的一组平均精度的小提琴图。
Here is another plot,
这是另一幅情节,

…it is extremely easy to create a Pandas DataFrame from the grid search results and analyze them further.
…从网格搜索结果中创建Pandas DataFrame并进行进一步分析非常容易。
总结和进一步的想法 (Summary and further thoughts)
In this article, we went over how to use the powerful Scikit-learn wrapper API, provided by the Keras library, to do 10-fold cross-validation and a hyperparameter grid search for achieving the best accuracy for a binary classification problem.
在本文中,我们介绍了如何使用Keras库提供的功能强大的Scikit-learn包装器API进行10倍交叉验证和超参数网格搜索,以实现二进制分类问题的最佳准确性。
Using this API, it is possible to enmesh the best tools and techniques of Scikit-learn-based general-purpose ML pipeline and Keras models. This approach definitely has a huge potential to save a practitioner a lot of time and effort from writing custom code for cross-validation, grid search, pipelining with Keras models.
使用此API,可以融合基于Scikit学习的通用ML管道和Keras模型的最佳工具和技术。 这种方法无疑具有巨大的潜力,可以节省从业人员编写交叉验证,网格搜索,使用Keras模型进行流水线定制代码的大量时间和精力。
Again, the demo code for this example can be found here. Other related deep learning tutorials can be found in the same repository. Please feel free to star and fork the repository if you like.
同样,此示例的演示代码可以在此处找到。 其他相关的深度学习教程可以在同一存储库中找到。 如果愿意,请随时为存储库加注星标和分叉。
You can check the author’s GitHub repositories for code, ideas, and resources in machine learning and data science. If you are, like me, passionate about AI/machine learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.
您可以同时查看作者的GitHub的库代码,想法,并在机器学习和数据的科学资源。 如果您像我一样对AI /机器学习/数据科学充满热情,请随时在LinkedIn上添加我或在Twitter上关注我。
翻译自: https://towardsdatascience.com/are-you-using-the-scikit-learn-wrapper-in-your-keras-deep-learning-model-a3005696ff38
keras scikit