用 pytorch 搭建一个残差网络(ResNet50)分类器(基于 kaggle 猫狗数据集)
这两天,一直想着找一个效果好点的模型来实现一下 kaggle 经典的猫狗分类器,kaggle 猫狗数据集以前也用自己搭建的 CNN 模型跑过,因为模型比较大,跑的比较慢,只跑了5轮,大概正确率在80%左右,效果一般般,当然模型也比较简单,只有6个卷积层2个最大池化层,1个均值池化层。昨天的时候,偶然看到经典的 ResNet 模型,就寻思着搭建一个 ResNet50 的模型,理论部分的话,我就搬运两个大佬的图,结合代码来看还是比较易懂的。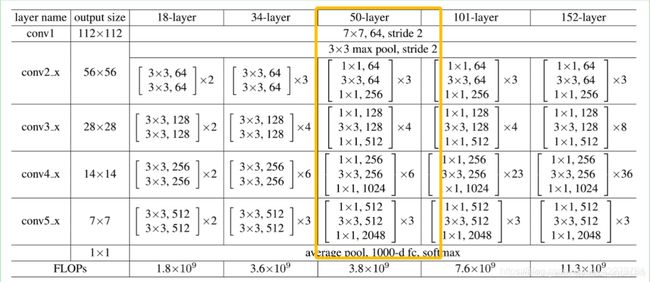
模型关键代码:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride = 1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes) # 数据归一化处理,使其均值为0,方差为1,可有效避免梯度消失
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes) # 数据归一化处理,使其均值为0,方差为1,可有效避免梯度消失
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4) # 数据归一化处理,使其均值为0,方差为1,可有效避免梯度消失
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.relu = nn.ReLU(inplace=True)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 遍历所有模块,然后对其中参数进行初始化
for m in self.modules(): # self.modules()采用深度优先遍历的方式,存储了net的所有模块
if isinstance(m, nn.Conv2d): # 判断是不是卷积
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n)) # 对权值参数初始化
elif isinstance(m, nn.BatchNorm2d): # 判断是不是数据归一化
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
# 当是 3 4 6 3 的第一层时,由于跨层要做一个步长为 2 的卷积 size会变成二分之一,所以此处跳连接 x 必须也是相同维度
downsample = nn.Sequential( # 对跳连接 x 做 1x1 步长为 2 的卷积,保证跳连接的时候 size 一致
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion)
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample)) # 将跨区的第一个要做步长为 2 的卷积添加到layer里面
self.inplanes = planes * block.expansion
for i in range(1, blocks): # 将除去第一个的剩下的 block 添加到layer里面
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50(pretrained=False):
'''Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
'''
model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=2)
# if pretrained: # 加载已经生成的模型
# model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
数据集加载:
import torch
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import os
from PIL import Image
# 初始化根目录
train_path = 'D:\\DeapLearn Project\\ResNet50\\CatDogData\\train\\'
test_path = 'D:\\DeapLearn Project\\ResNet50\\CatDogData\\test\\'
# 定义读取文件的格式
# 数据集
class MyDataSet(Dataset):
def __init__(self, data_path:str, transform=None):
super(MyDataSet, self).__init__()
self.data_path = data_path
if transform is None:
self.transform = transforms.Compose(
[
transforms.Resize(size=(224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
else:
self.transform = transforms
self.path_list = os.listdir(data_path)
def __getitem__(self, idx:int):
img_path = self.path_list[idx]
if img_path.split('.')[0] == 'dog':
label = 1
else:
label = 0
label = torch.as_tensor(label, dtype=torch.int64)
img_path = os.path.join(self.data_path, img_path)
img = Image.open(img_path)
img = self.transform(img)
return img, label
def __len__(self)->int:
return len(self.path_list)
train_ds = MyDataSet(train_path)
full_ds = train_ds
train_size = int(0.8*len(full_ds))
test_size = len(full_ds) - train_size
new_train_ds, test_ds = torch.utils.data.random_split(full_ds, [train_size, test_size])
# 数据加载
new_train_loader = DataLoader(new_train_ds, batch_size=32, shuffle=True, pin_memory=True, num_workers=0)
new_test_loader = DataLoader(test_ds, batch_size=32, shuffle=False, pin_memory=True, num_workers=0)
数据集要说明的一点就是,我的训练的数据集和校验的数据集都取自 kaggle 里面的训练集,前80%用来训练,后20%用来校验。
模型训练:
import torch
import time
import os
import matplotlib.pyplot as plt
import torch.optim as optim
import math
LR = 0.0005 # 设置学习率
EPOCH_NUM = 10 # 训练轮次
# 导入 定义的 ResNet50 和 导入的数据
from ResNet50 import resnet50
from dataload import new_train_loader, new_test_loader
def time_since(since):
s = time.time() - since
m = math.floor(s/60)
s -= m*60
return '%dm %ds' % (m, s)
model = resnet50()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
train_data = new_train_loader
test_data = new_test_loader
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
def train(epoch, loss_list):
running_loss = 0.0
for batch_idx, data in enumerate(new_train_loader, 0):
inputs, target = data[0], data[1]
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
loss_list.append(loss.item())
running_loss += loss.item()
if batch_idx % 100 == 99:
print(f'[{time_since(start)}] Epoch {epoch}', end='')
print('[%d, %5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 100))
running_loss = 0.0
return loss_list
def test():
correct = 0
total = 0
with torch.no_grad():
for _, data in enumerate(new_test_loader, 0):
inputs, target = data[0], data[1]
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, prediction = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (prediction == target).sum().item()
print('Accuracy on test set: (%d/%d)%d %%' % (correct, total, 100 * correct / total))
with open("test.txt", "a") as f:
f.write('Accuracy on test set: (%d/%d)%d %% \n' % (correct, total, 100 * correct / total))
if __name__ == '__main__':
start = time.time()
with open("test.txt", "a") as f:
f.write('Start write!!! \n')
loss_list = []
for epoch in range(EPOCH_NUM):
train(epoch, loss_list)
test()
torch.save(model.state_dict(), 'Model.pth')
x_ori = []
for i in range(len(loss_list)):
x_ori.append(i)
plt.title("Graph")
plt.plot(x_ori, loss_list)
plt.ylabel("Y")
plt.xlabel("X")
plt.show()
训练结果:
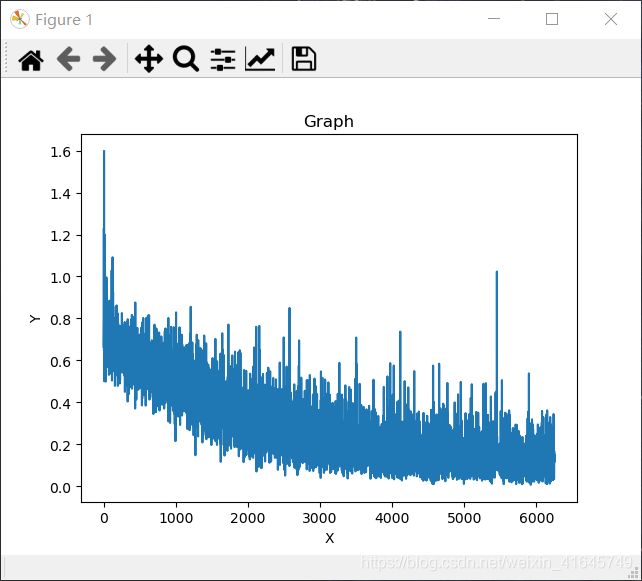
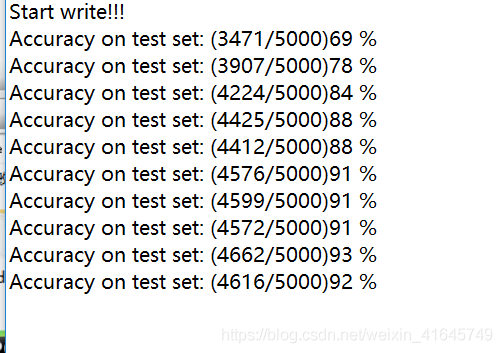
训练了10轮,最大正确率93%,第五轮正确率88%,比我之前搭建的模型正确率提高了8个百分点,可以看出来,ResNet50 训练出来的效果还是很不错的,等有时间了,可以提高跑的轮次,正确率应该还能提高。以上结果仅供参考,如果有哪位想自己跑的可以自己从kaggle里面做一个自己的数据集,或者可以私信或者邮件我,我给你发数据集。
参考文章:
彻底搞懂ResNet50
ResNet-50网络理解
工程GitHub:Github链接(帮忙点个星,谢谢了)
联系邮箱:[email protected]