刷新ImageNet最高分!谷歌发布最强Transformer
点上方计算机视觉联盟获取更多干货
仅作学术分享,不代表本公众号立场,侵权联系删除
转载于:新智元
AI博士笔记系列推荐
周志华《机器学习》手推笔记正式开源!可打印版本附pdf下载链接
近日,谷歌大脑团队公布了Vision Transformer(ViT)进阶版ViT-G/14,参数高达20亿的CV模型,经过30亿张图片的训练,刷新了ImageNet上最高准确率记录——90.45%,此前的ViT取得的最高准确率记录是 88.36%,不仅如此,ViT-G/14还超过之前谷歌提出的Meta Pseduo Labels模型。
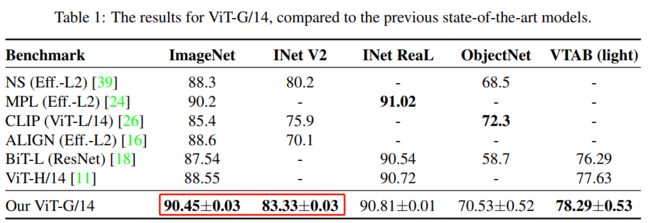
Vision Transformer模型的缩放规律
在多项基准测试中,ImageNet, ImageNet-v2和VTAB-1k,ViT-G/14的表现都刷新了记录。
例如,在几张照片的识别挑战中,准确率提高了五个百分点以上。研究人员随后训练了多个更微型的模型版本,以寻找架构的缩放规律(scaling law),结果观察到性能遵循幂律函数(power-law function),类似于用于NLP的Transformer模型。
2017年由谷歌首次引入的 Transformer 架构迅速成为最受欢迎的NLP深度学习模型设计,其中 OpenAI的GPT-3是最著名的。OpenAI 去年发布的一项研究描述了这些模型的缩放规则(Scaling rules)。
OpenAI 通过训练几个不同规模的可比模型,改变训练数据的数量和处理能力,开发了一个用于评估模型准确性的幂律函数。此外,OpenAI 发现更大的模型不仅性能更好,而且计算效率也更高。
与 NLP 模型不同,大多数SOTA的 CV 深度学习模型,采用的是卷积神经网络架构(CNN)。2012年, 一个CNN模型赢得了ImageNet竞赛,CNN因此声名鹊起。
随着Transformer最近在 NLP 领域的成功,研究人员已经开始关注它在视觉问题上的表现; 例如,OpenAI 已经构建了一个基于 GPT-3的图像生成系统。
谷歌在这个领域一直非常活跃,在2020年年底使用他们专有的 JFT-300M 数据集训练了一个600m 参数的 ViT 模型。

△ 去年10月,谷歌大脑团队发布了Vision Transformer(ViT)
而新的ViT-G/14模型使用 JFT-3B 预先训练,JFT-3B是升级版数据集,包含大约30亿张图片。
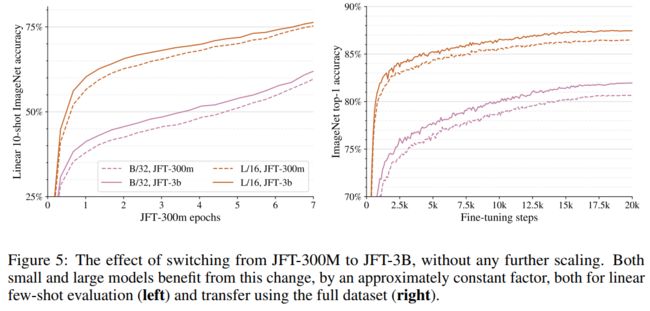
研究团队改进了 ViT 架构,增加了内存使用,使模型能够适应单个 TPUv3核心。研究人员在预先训练的模型上使用少量和微调的迁移学习来评估 ViT-G/14和其他较小模型的性能。这些发现被用来创建缩放规则,类似于 NLP 规则:
根据幂律函数,缩放更多的计算、模型和数据可以提高准确性;
在较小的模型中,准确性可能是一个障碍;
大型数据集有助于大型模型。
目前,ViT-G/14得分在 ImageNet 排行榜上排名第一。下面的八个得分最高的模型同样是由谷歌的研究人员创建的,而第十个模型来自Facebook。
作者团队

本次论文团队成员是此前发布ViT模型的4名成员,其中,第一作者是Xiaohua Zhai (翟晓华)。

https://sites.google.com/site/xzhai89/home
翟晓华目前是谷歌大脑研究员。研究领域为深度学习和计算机视觉。兴趣范围包括表征学习、迁移学习、自监督学习、生成模型、跨模态感知。
根据他的个人网站提供的信息,2009年,翟晓华本科毕业于南京大学,2014年取得北京大学计算机科学博士学位。
另外,论文作者Alexander Kolesnikov,同为谷歌大脑研究员,研究领域包括人工智能、机器学习、深度学习和计算机视觉。
毕业于奥地利Institute of Science and Technology Austria (IST Austria),博士论文为Weakly-Supervised Segmentation and Unsupervised Modeling of Natural Images(自然图像的弱监督分割和无监督建模)。

另一名作者Neil Houlsby(下图),研究领域为机器学习、人工智能、计算机视觉和自然语言处理。

第四名作者Lucas Beyer,是一名自学成才的黑客、研究科学家,致力于帮助机器人了解世界、帮助人类了解深度学习(本作者暂未找到图片)。
参考资料:
https://arxiv.org/pdf/2106.04560.pdf
https://www.marktechpost.com/2021/06/28/google-trains-an-ai-vision-model-with-two-billion-parameter/
-------------------
END
--------------------
我是王博Kings,985AI博士,华为云专家、CSDN博客专家(人工智能领域优质作者)。单个AI开源项目现在已经获得了2100+标星。现在在做AI相关内容,欢迎一起交流学习、生活各方面的问题,一起加油进步!
我们微信交流群涵盖以下方向(但并不局限于以下内容):人工智能,计算机视觉,自然语言处理,目标检测,语义分割,自动驾驶,GAN,强化学习,SLAM,人脸检测,最新算法,最新论文,OpenCV,TensorFlow,PyTorch,开源框架,学习方法...
这是我的私人微信,位置有限,一起进步!

王博的公众号,欢迎关注,干货多多
王博Kings的系列手推笔记(附高清PDF下载):
博士笔记 | 周志华《机器学习》手推笔记第一章思维导图
博士笔记 | 周志华《机器学习》手推笔记第二章“模型评估与选择”
博士笔记 | 周志华《机器学习》手推笔记第三章“线性模型”
博士笔记 | 周志华《机器学习》手推笔记第四章“决策树”
博士笔记 | 周志华《机器学习》手推笔记第五章“神经网络”
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(上)
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(下)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(上)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(下)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(上)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(下)
博士笔记 | 周志华《机器学习》手推笔记第九章聚类
博士笔记 | 周志华《机器学习》手推笔记第十章降维与度量学习
博士笔记 | 周志华《机器学习》手推笔记第十一章稀疏学习
博士笔记 | 周志华《机器学习》手推笔记第十二章计算学习理论
博士笔记 | 周志华《机器学习》手推笔记第十三章半监督学习
博士笔记 | 周志华《机器学习》手推笔记第十四章概率图模型
![]()
点分享
![]()
点收藏
![]()
点点赞
![]()
点在看