MobileNetV2: Inverted Residuals and Linear Bottlenecks(MobileNetV2)-论文阅读笔记
MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2论文阅读笔记
//2022.5.8下午12:35开始阅读
论文地址
MobileNetV2: Inverted Residuals and Linear Bottlenecks | IEEE Conference Publication | IEEE Xplore
论文目的
提出了一种新的移动端的网络架构模型,MobileNetV2网络。然后,作者还描述了SSDLite框架中使用这种新的网络进行目标检测的方法。最后,作者还演示如何使用DeepLabV3构建移动语义分段模型。
作者指出:本文提出来的网络基于倒置的残差结构,中间扩展层使用轻型纵深卷积来过滤作为非线性源的特征。作者还发现为了保护代表性的力量,去除狭窄层中的非线性非常重要。作者证明了上述网络架构设计方法的性能。
作者同时指出,上述方法将输入/输出域和转换表达性分离,提供了进一步对上述网络架构分析的可能性。作者在ImageNet、COCO、VOC数据集上进行了实验,比测试了精度,乘加操作数、实际延迟和参数数量之间的权衡。
个人总结
本文在MobilenNetV1网络的基础上,增加了线性瓶颈和反向残差设计,从而创造了MobileNetV2网络架构。然后,作者进一步对本文中提出来的线性瓶颈层和反向残差层的好处做了说明(反向残差模块和普通残差模块的区别在于:反向残差模块是中间维度大,两边维度小;而普通残差模块是中间维度小,两边维度大;)。
在MobileNetV1网络中在每个微结构结束之后使用ReLu激活,而在V2中将ReLu近似为线性转换,保持了低维空间中输入信息的完整性。下面是V1和MobileNetV2网络结构的对比展示。

图片来自于:轻量级神经网络:MobileNetV1到MobileNetV3_人工智障之深度瞎学的博客-CSDN博客_mobilenetv3网络图
通过上图可知,V2网络相对于V1来说在DW层之前增加了PW层,目的是为了提高DW层输入前的维度大小,从而解决了V1网络中DW层输入时向量维度固定不变的问题。
此后,作者又说明本文中使用的线性瓶颈和反向残差改进可以对硬件物理内存提供改善。
作者又在ImageNet、COCO、PASCAL VOC 2012数据集上进行了实验:目标检测,语义分割等,最后对使用线性瓶颈和反向残差方法的特性又通过实验数据说明。
值得一提的是,在本文的附录部分,作者首先证明了线性瓶颈层为何可以保持低纬向量信息不变,然后又给出了MobileNetV2网络在PASCAL VOC 2012的验证数据集上进行语义分割的可视化结果(测试了单尺度输入和多尺度+左右翻转输入的方式)。
论文主要内容
1.介绍
首先作者指出了现代提高神经网络精度的代价是耗费了大量的计算资源,但是这些计算资源在移动端很难达到要求。本文提出的网络通过显著减少所需的操作和内存数量,同时保持相同的准确性,推动了移动定制计算机视觉模型的发展。
本文的主要贡献:带有线性瓶颈的反向残差层,该模块将低维压缩表示作为输入,首先将其扩展到高维,并使用轻型深度卷积进行过滤。特征随后通过线性卷积投影回低维表示。
带有线性瓶颈层的反向残差层好处:该模块可以在任何现代框架中使用标准操作有效地实现,并允许本文提出的模型使用标准基准在多个性能点上超越最先进的水平。此外,这个卷积模块特别适合移动设计,因为它允许通过从不完全具体化大的中间张量来显著减少推理过程中所需的内存占用。这减少了许多嵌入式硬件设计中对主内存访问的需求,这些设计提供了少量非常快速的软件控制高速缓存。
2.相关工作
近年来对于网络架构等方面的探索简介:作者接着介绍了近几年在对网络架构探索上的研究工作,例如ResNet等。同时,还介绍了在网络超参数优化、网络修剪、连通性学习上的探索工作,也有大量工作关注于改变内部卷积块的连接性结构,如:ShuffleNet和引入稀疏性等的工作中。作者说明了,将遗传算法和强化学习引入到网络架构的搜索当中,但是这样形成的网络结构非常复杂。
本文的关注点:如何开发出来能够使得神经网络更好运行的方法。本文的MobileNetV2基于V1提出来,在保持了原有V1网络架构的简单性等性能的基础上,提高了检测精度。
3. 准备、讨论和直觉
3.1深度可分离卷积
基本思想:其基本思想是用一个分解版本来代替一个完整的卷积算子,该版本将卷积分解为两个独立的层。第一层称为深度卷积,它通过对每个输入通道应用一个卷积滤波器来执行轻量级滤波。第二层是1×1卷积,称为逐点卷积,负责通过计算输入通道的线性组合来构建新特征。
深度可分离卷积是标准卷积层的替代品。根据经验,它们的工作原理几乎与常规卷积一样好,但成本仅为:
![]()
这是深度卷积方向和1×1点卷积方向的总和。与传统层相比,深度可分离卷积有效地减少了计算量,几乎是![]() 的一倍。MobileNetV2使用k=3(3×3深度可分离卷积),因此计算成本比标准卷积小8到9倍,但精度略有降低[27]。
的一倍。MobileNetV2使用k=3(3×3深度可分离卷积),因此计算成本比标准卷积小8到9倍,但精度略有降低[27]。
3.2 线性瓶颈层
考虑一个由n层Li组成的深层神经网络,每个层都有一个维数为hi×wi×di的激活张量。在本节中,我们将讨论这些激活张量的基本性质,我们将其视为具有di维度的hi×wi“像素”的容器。非正式地说,对于真实图像的输入集,我们说层激活集(对于任何层Li)形成了“感兴趣的流形”。长期以来,人们一直认为神经网络中感兴趣的流形可以嵌入低维子空间。换句话说,当我们观察深卷积层的所有单个d通道像素时,这些值中编码的信息实际上存在于某个流形中,而流形又可以嵌入到低维子空间2中。
乍一看,这样的事实可以通过简单地降低层的维度从而降低操作空间的维度来捕捉和利用。MobileNetV1[27]已经成功地利用了这一点,通过一个宽度乘数参数,有效地在计算和精度之间进行了权衡,并将其纳入了其他网络的高效模型设计中[20]。根据这种直觉,宽度乘数方法可以降低激活空间的维数,直到感兴趣的流形跨越整个空间。然而,当我们回忆起深层卷积神经网络实际上具有非线性的逐坐标变换时,这种直觉就崩溃了,比如ReLU。例如,应用于1D空间中的直线的ReLU会生成一条“光线”,与![]() 空间中一样,它通常会生成一条带有n个接头的分段线性曲线。
空间中一样,它通常会生成一条带有n个接头的分段线性曲线。
很容易看出,一般来说,如果层变换ReLU(Bx)的结果具有非零体积S,则通过输入的线性变换B获得映射到内部S的点,从而表明与全维输出相对应的输入空间部分仅限于线性变换。换言之,深度网络仅在网络的非零体积的输出领域部分具有线性分类器的能力。
另一方面,当ReLU崩溃通道时,不可避免地会丢失该通道中的信息。然而,如果我们有很多通道,并且激活流形中有一个结构,那么信息可能仍然保存在其他通道中。在补充材料中,我们表明,如果输入流形可以嵌入到激活空间的一个低维子空间中,那么ReLU变换可以保留信息,同时将所需的复杂性引入可表达函数集。
总而言之,我们强调了两个属性,它们表明感兴趣的流形应该位于高维激活空间的低维子空间中:1. 如果感兴趣的流形在ReLU变换后仍保持非零体积,则它对应于线性变换。2. ReLU能够保留关于输入流形的完整信息,但前提是输入流形位于输入空间的低维子空间中。
这两个见解为我们提供了优化现有神经结构的经验提示:假设感兴趣的流形是低维的,我们可以通过在卷积块中插入线性瓶颈层来捕捉这一点。实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏太多信息。在第6节中,我们从经验上证明,在瓶颈中使用非线性层确实会影响性能好几个百分点,进一步验证了我们的假设3。我们注意到,在[29]中报告了类似的报告,其中非线性被从传统残差块的输入中移除,从而提高了CIFAR数据集的性能。


3.3反向残差
瓶颈块看起来类似于剩余块,其中每个块包含一个输入,然后是几个瓶颈,然后是扩展[8]。然而,受瓶颈实际上包含所有必要信息的直觉启发,而扩展层仅作为伴随张量非线性变换的实现细节,我们直接在瓶颈之间使用快捷方式。

图3提供了设计差异的可视化示意图。插入快捷方式的动机类似于经典的剩余连接:我们希望提高梯度在乘法器层之间传播的能力。然而,反向设计的内存效率要高得多(详见第5节),而且在我们的实验中效果稍好一些。
瓶颈卷积的运行时间和参数计数。

基本实现结构如表1所示。对于大小为h×w、扩展因子t和内核大小k的块(具有![]() 输入通道和
输入通道和![]() 个输出通道),所需的乘法相加总数为
个输出通道),所需的乘法相加总数为 ![]() 。与(1)相比,这个表达式有一个额外的项,因为我们确实有一个额外的1×1卷积,然而我们网络的性质允许我们利用更小的输入和输出维度。在表3中,我们比较了MobileNetV1、MobileNetV2和ShuffleNet之间每个分辨率所需的大小。
。与(1)相比,这个表达式有一个额外的项,因为我们确实有一个额外的1×1卷积,然而我们网络的性质允许我们利用更小的输入和输出维度。在表3中,我们比较了MobileNetV1、MobileNetV2和ShuffleNet之间每个分辨率所需的大小。
3.4信息流解释
我们的体系结构的一个有趣特性是,它在构建块的输入/输出域(瓶颈层)和层转换之间提供了一种自然的分离,层转换是一种将输入转换为输出的非线性函数。前者可以被视为网络在每一层的容量,而后者则被视为表现力。这与传统的卷积块(规则的和可分离的)形成对比,在传统的卷积块中,表达能力和容量都纠结在一起,是输出层深度的函数。
特别是,在我们的例子中,当内层深度为0时,由于快捷连接,底层卷积是身份函数。当展开比小于1时,这是一个经典的剩余卷积块[8,30]。然而,为了我们的目的,我们证明了大于1的膨胀比是最有用的。
这种解释使我们能够将网络的表现力与其容量分开进行研究,我们认为有必要进一步探索这种分离,以便更好地理解网络特性。
4.模型架构
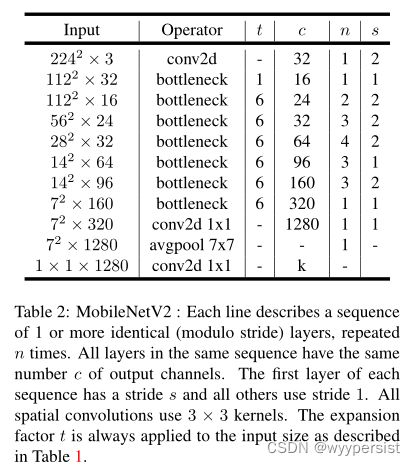
现在我们详细描述我们的架构。如前一节所述,基本构造块是带残差的瓶颈深度可分离卷积。该区块的详细结构如表1所示。MobileNetV2的体系结构包含初始的完全卷积层和32个滤波器,然后是表2中描述的19个剩余瓶颈层。我们使用ReLU6作为非线性,因为它在用于低精度计算时具有鲁棒性[27]。我们总是使用内核大小为3×3作为现代网络的标准,并在训练期间使用退出和批量标准化。
除了第一层,我们在整个网络中使用恒定的扩展速率。在我们的实验中,我们发现5到10之间的扩展速率会导致几乎相同的性能曲线,较小的网络使用较小的扩展速率会更好,较大的网络使用较大的扩展速率会更好。
在我们所有的主要实验中,我们使用了扩展因子6来表示输入张量的大小。例如,对于采用64个通道输入张量并产生128个通道张量的瓶颈层,中间扩展层则为64·6=384个通道。
超参数的权衡。正如[27]中所述,我们根据不同的性能点定制了我们的体系结构,使用输入图像分辨率和宽度倍增器作为可调超参数,可以根据所需的精度/性能权衡进行调整。我们的主要网络(宽度乘法器1224×224)的计算成本为3亿次乘法加和340万个参数。我们探讨了输入分辨率从96到224,宽度乘数从0.35到1.4的性能权衡。网络计算成本从7倍加法到5.85亿MADD不等,而模型大小在1.7M到6.9M的参数之间变化。
与[27]的一个小的实现差异是,对于小于1的乘法器,我们将宽度乘法器应用于除最后一个卷积层之外的所有层。这提高了小型机型的性能。

5.实现细节说明
5.1高效推理内存

反向剩余瓶颈层允许实现特别高效的内存,这对于移动应用程序非常重要。一个标准的高效率的使用tensorflow或caffe的推理实现,构建一个有向无环计算超图G,由表示运算的边和表示中间计算张量的节点组成。安排计算是为了最小化需要存储在内存中的张量总数。在最一般的情况下,它搜索所有可能的计算顺序∑(G),并选择最小化的一个。
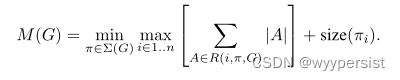
其中![]() 是连接到任何
是连接到任何![]() 的中间张量列表,|A |表示张量A的大小, size(i)是操作i期间内部存储所需的内存总量。
的中间张量列表,|A |表示张量A的大小, size(i)是操作i期间内部存储所需的内存总量。
对于只有平凡并行结构(如剩余连接)的图,只有一个非平凡的可行计算顺序,因此可以简化对计算图G进行推理所需的内存总量和界:
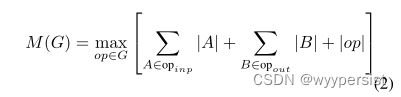
或者重申一下,内存量只是所有操作中组合输入和输出的最大总大小。在接下来的内容中,我们表明,如果我们将瓶颈剩余块视为单个操作(并将内部卷积视为一次性张量),内存总量将由瓶颈张量的大小决定,而不是瓶颈内部张量的大小(以及更大的张量)。
残差瓶颈块。
图3b中所示的瓶颈块运算符F(x)可以表示为三个运算符F(x)=[A◦ N◦ B] x,其中A是线性变换![]() , N是非线性的单通道变换:
, N是非线性的单通道变换:![]() ,而B又是输出域的线性变换:
,而B又是输出域的线性变换:![]() 。
。
对于我们的网络N=ReLU6◦ dwise◦ ReLU6,但结果适用于任何单通道转换。假设输入域的大小为| x |,输出域的大小为| y |,那么计算F(x)所需的内存可以低至![]() 。
。
该算法基于这样一个事实,即内张量I可以表示为t张量的串联,每个张量的大小为n/t,然后我们的函数可以表示为:

通过累加总和,我们只需要在内存中始终保留一个大小为n/t的中间块。使用n=t,我们最终必须始终只保留中间表示的一个通道。使我们能够使用这种技巧的两个约束是(a)内部变换(包括非线性和深度)是每通道的,以及(b)连续的非每通道运算符具有输入大小与输出的显著比率。对于大多数传统的神经网络,这样的技巧不会产生显著的改进。
我们注意到,使用t-way split计算F(X)所需的乘法-加法运算符的数量与t无关,但是在现有的实现中,我们发现用几个较小的矩阵乘法替换一个矩阵乘法会影响运行时性能,因为增加的缓存未命中情况的出现。作者发现,当t是2到5之间的一个小常数时,这种方法最有帮助。它显著降低了内存需求,但仍然允许人们利用深度学习框架提供的高度优化的矩阵乘法和卷积运算符所获得的大部分效率。特殊的框架级优化是否会导致运行时的进一步改进还有待观察。
6.实验
6.1ImageNet数据集分类
训练参数设置。我们使用TensorFlow[31]训练模型。我们使用标准的RMSPropOptimizer,衰变和动量都设置为0.9。我们在每一层之后使用批量标准化,标准重量衰减设置为0.00004。在MobileNetV1[27]设置之后,我们使用初始学习率0.045,每个历元的学习率衰减率为0.98。我们使用16个GPU异步工作者,批量大小为96。
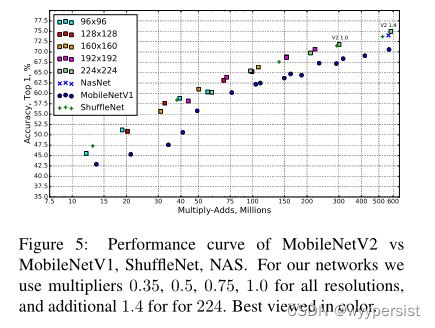
结果。我们将我们的网络与MobileNet v1、ShuffleNet和NASNet-A模型进行比较。表4显示了一些选定模型的统计数据,图5显示了完整的性能图。
6.2目标检测
我们评估并比较了MobileNetV2和MobileNetV1作为目标检测特征提取器[33]的性能,以及COCO数据集[2]上的单次激发检测器(SSD)[34]的改进版本。我们还将YOLOv2[35]和原始SSD(VGG-16[6]作为基本网络)作为基线进行了比较。我们不会将性能与其他架构(如更快的RCNN[36]和RFCN[37])进行比较,因为我们的重点是移动\实时模型。

SSDLite:在本文中,我们介绍了一种移动友好型常规SSD。在SSD预测层中,我们将所有规则卷积替换为可分离卷积(深度后为1×1投影)。这种设计与MobileNets的总体设计一致,并且被认为在计算效率上要高得多。我们将此修改版本称为SSDLite。与常规SSD相比,SSDLite显著减少了参数计数和计算成本,如表5所示。
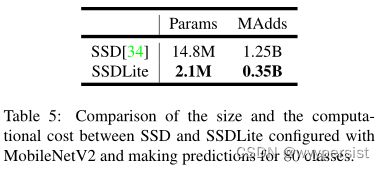
对于MobileNetV1,我们遵循[33]中的设置。对于MobileNetV2,SSDLite的第一层连接到第15层的扩展部分(输出步长为16)。第二层和其他SSDLite层连接在最后一层的顶部(输出步幅为32)。此设置与MobileNetV1一致,因为所有层都连接到相同输出步幅的功能图。
这两个MobileNet模型都使用开源TensorFlow对象检测API进行训练和评估[38]。两种模型的输入分辨率均为320×320。我们对mAP(COCO挑战指标)、参数数量和乘法加法数量进行了基准测试和比较。结果如表6所示。MobileNetV2 SSDLite不仅是最有效的模型,也是三种模型中最精确的。值得注意的是,MobileNetV2 SSDLite的效率高20倍,体积小10倍,但在COCO数据集上仍优于YOLOv2。

6.3语义分割
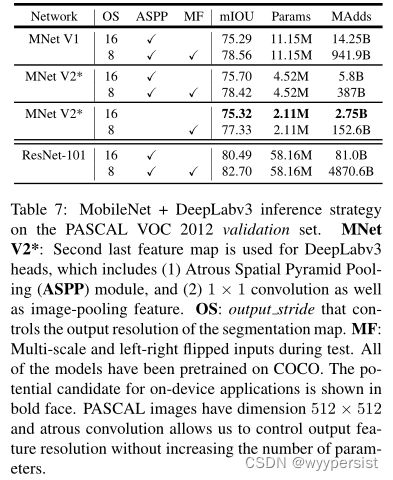
在本节中,我们比较了作为特征提取器使用的MobileNetV1和MobileNetV2模型与用于移动语义分割任务的DeepLabv3[39]。DeepLabv3采用Atrus卷积[40,41,42],这是一种明确控制计算特征图分辨率的强大工具,并构建了五个并行头,包括(a)Atrus空间金字塔池模块(ASPP)[43],其中包含三个具有不同Atrus速率的3×3卷积,(b)1×1卷积头,以及(c)图像级特征[44]。我们用输出步长表示输入图像空间分辨率与最终输出分辨率之比,这是通过适当应用阿托斯卷积来控制的。对于语义分割,我们通常使用输出步长=16或8来进行更密集的特征映射。我们在PASCAL VOC 2012数据集[3]上进行了实验,使用了[45]中的额外注释图像和评估指标mIOU。
为了建立一个移动模型,我们试验了三种设计变体:(1)不同的特征提取程序,(2)简化DeepLabv3头部以提高计算速度,(3)不同的推理策略以提高性能。我们的结果总结在表7中。我们观察到:(a)推理策略,包括多尺度输入和添加左右翻转图像,显著增加了MADD,因此不适合在设备上应用,(b)使用输出步幅=16比输出步幅=8更有效,(c)MobileNetV1已经是一个强大的特征提取程序,只需要大约4.9− MAdds比ResNet-101[8]少5.7倍(例如,mIOU:78.56 vs 82.70,MAdds:941.9B vs 4870.6B),(d)在MobileNetV2的第二个最后一层功能图上构建DeepLabv3磁头比在原始的最后一层功能图上更有效,因为第二个到最后一个功能图包含320个通道,而不是1280个,通过这样做,我们获得了类似的性能,但所需的操作比MobileNetV1对应设备少约2.5倍,(e)DeepLabv3磁头的计算成本很高,移除ASPP模块可以显著降低MADD,而性能只会略有下降。在表7的末尾,我们确定了一个潜在的设备上应用候选(粗体),它可以实现75.32%的mIOU,只需要275B个MADD。
6.4 消融研究
反向残差连接。残余连接的重要性已经被广泛研究[8,30,46]。本文报告的新结果是,快捷方式连接瓶颈的性能优于连接扩展层的快捷方式(参见图6b进行比较)。
线性瓶颈的重要性。线性瓶颈模型的功能严格低于非线性模型,因为激活始终可以在线性状态下运行,并适当改变偏差和比例。然而,我们在图6a中所示的实验表明,线性瓶颈改善了性能,为非线性破坏低维空间中的信息提供了支持。

7.总结和未来工作
我们描述了一个非常简单的网络架构,它允许我们构建一系列高效的移动模型。我们的基本建筑单元有几个特性,特别适合移动应用。它允许非常高效的记忆推理,并利用所有神经框架中的标准操作。
对于ImageNet数据集,我们的体系结构提高了各种性能点的技术水平。
对于目标检测任务,我们的网络在精确度和模型复杂度方面都优于COCO数据集上最先进的实时检测器。值得注意的是,我们与SSDLite检测模块相结合的架构比YOLOv2的计算量少20倍,参数少10倍。
在理论方面:提出的卷积块具有独特的特性,允许将网络表达能力(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这一点是未来研究的一个重要方向。