对抗网络之PG-GAN,无条件下生成更真实的人脸图像[3]
1. 介绍
GAN在2015年DCGAN[1]论文提出之后,开始迅速的被关注和被应用到各个领域。比较有影响力的应用,比如Image translation; Image Inpainting; Face image manipulation 以及 Semi-supervised learning等。当然作为当前最有竞争力的生成模型,相对于VAE, GAN虽然不稳定,相对于PixelCNN, GAN虽然没有提供明确的likelihood, 但是GAN在较短的训练之后就可以生成及其真实的样本。生成更加真实的样本在GAN领域也是一个研究的热点。就像刚才提到了,GAN能火,一方面就是因为DCGAN生成的质量很高的64x64 像素的样本。也只有当样本能达到一定真实度的时候,GAN本身才可能被关注,以及应用到Image transformation[5]。
我们将GAN分为两类,一类是无条件下的生成;另一类自然是基于条件信息的生成。之所以要分开,是因为基于条件本身可以作为一个优化,一般来说,把无条件的GAN加上条件会提高样本的质量。无条件下的样本生成,可以关注以下论文:
[1]DCGAN(https://arxiv.org/abs/1511.06434)
[2]WGAN(https://arxiv.org/abs/1701.07875)
[3]LS-GAN(https://arxiv.org/abs/1611.04076)
[4]WGAN-GP(https://arxiv.org/abs/1704.00028)
以及今天要讲解的PG-GAN: PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION.
从DCGAN到PG-GAN,在我的测试下,生成的人脸质量变得越来越高。尤其是PG-GAN。一个过程化生成,在celebA-hq数据集下生成1024x1024 的及其真实的样本,要知道WGAN-gp生成128x128已经相当困难而且质量得不到保证。那么PG-GAN是如何生成如此惊人的样本的呢?
2. 理解PG-GAN
2.1 论文给出的1024的样本

Figure: 第一行为生成样本;第二行为真实样本
PG-GAN的生成样本质量是惊人的,但是PG-GAN并不是完美的。后面会提到它的一些缺点。
对PG-GAN的一句话总结就是: 过程化的生成方式使得生成高质量,高分辨率的样本成为了可能,使用的一些trick即使没有太多的启发性,但是在本文中却出奇的有效。
2.2 PG-GAN中过程化训练
PG-GAN可以生成1024 pixels的样本,很明显,使用单纯的GAN,建立从latent code 到 1024x1024 pixels样本的映射网络G,肯定是很难工作的。
过程化的训练方式也就是不采用一步到位,而是先试着生成低分辨率或者低质量的图像,然后不断地增加分辨率或者细节。我将过程化的训练方式分为两种: 一种是不改变网络的;一种是需要改变的。
不改变网络:意味着网络结构不变,所以肯定是建立从latent code 到1024的映射,但是训练数据是从低质量的样本开始,然后不断地增加细节,当然我们需要把训练数据先下采样都要resize到 1024。PG-GAN是属于第二种情况,也就是网络结构先从 4x4的生成,然后不断地给D和G添加层,然后最终输出1024x1024的。
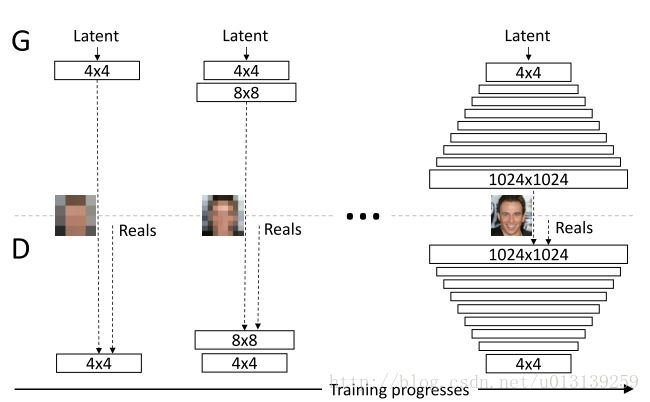
Figure:过程化的训练方式
这种改变网络,过程化生成的方式是一个符合人类直觉,而且很容易想到的。但是PG-GAN能达到如此惊人的效果是和它的一些trick及细节处理分不开的。
2.3 PG-GAN的trick的作用
为了确保完全理解这篇论文,我使用tensorflow复现了PG-GAN。在celebA数据集上训练,生成的64x64的样本质量也是相当好的。Github地址:
https://github.com/zhangqianhui/PGGAN-tensorflow
下面是我的实验结果: 
Figure: 生成(Left); 真实(右边)
下面说下PG_GAN的几个trick:
(1) Transition process.
当加倍分辨率训练的时候,作者提出了一个平滑的转换过程,增加了一个fade-in阶段。这个阶段对稳定训练具有最重要的意义。 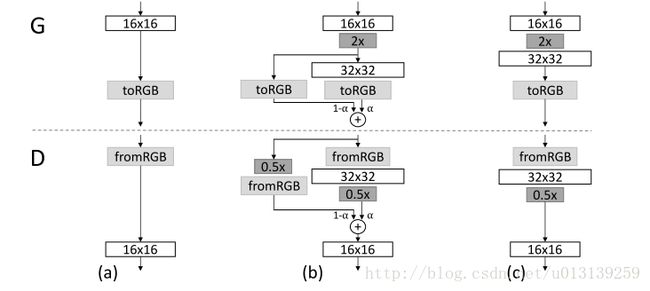
Figure: 增加的阶段使得分辨率的提高平滑过渡
这个αα的值是从 0到1 的变化。当αα为0的时候,相当于Figure (a),当αα为1的时候,相当于Figure(c)。所以,在转换过程中,生成样本的像素,是从 16x16到 32x32转换的。同理,作者对真实样本也做了类似的平滑过渡,也就是,在这个阶段的某个训练batch。真实样本是:
X=X16pixel∗(1−α)+X32pixel∗αX=X16pixel∗(1−α)+X32pixel∗α
总的来说,平滑的过渡阶段稳定了训练。在我的实验中,如果不使用此trick,除了训练不稳定,样本的质量也极大的降低。
(2) Minibatch discrimination 的改进
对于GAN的生成,样本的多样性也是一个很重要的指标。Improved GAN[6]提出的Inception-scores其中之一就是测量的生成样本的多样性。如果生成的样本基本相似,GAN被认为遭受到Model collapse 问题。GoodFellow 对 mode Collapse是这样定义的:
Mode collapse is a problem that occurs when the generator learns to map several different input z values to the same point. 按照Goodfellow的说法,mode collapse或多或少都会存在,即使生成整体上有差异,但是局部纹理或者颜色没啥变化的时候,GAN可以认为是遭受到轻微的Mode collapse问题。
Improved GAN 论文认为当GAN 塌陷到single mode的时候,D的梯度应该是都有相近的方向。本身D的判断模型本身并没有任何约束去告诉G生成不相似的样本。相反,当G遭受mode collapse问题时候,D可能认为样本是更加真实的。
那么该如何解决这个问题?
我们知道,判别器D本身是测量生成样本是真实样本的可能性,如果可以把衡量多样性的度量加到判别器中某层去影响判别器的判别,那么应该就可以使得G能够得到更多样化的梯度方向。
Improved GAN提出了Minibatch discrimination(MD)基本就是按照这个思路去缓解Mode collapse 问题的。PG-GAN提出了Minibatch standard deviation(MSD) 就是对MD的改进。这两个方法的基本思路都是从D的中间层(一般都是最后几层)的 feature map作为输入x,然后对x进行处理,找到多样性的度量y,然后concat(x,y) 作为下一层的输入。
不同的地方就是如何衡量多样性。MD是对feature map进行处理,得到对应单个样本的matrix,然后分别计算各个样本之间的matrix L1 distance。最后对一个minibatch中所有的样本做个sum。这个加和的结果就是上文提到的y。
MD方法是需要训练参数的。PG-GAN的MSD就更为简单,不需要训练参数。它根据feature map求出 对应每个位置的minibatch的 标准差。然后,对标准差reduce_mean求一个均值。这个均值就是上文提到的y。
所以,为了衡量多样性其实就是衡量minibatch中样本之间的差异。PG-GAN的论文中说MD方法没有自己的方法效果好。当然这一点除了从作者给出的评估外无从证明。这也是我要提到的PG-GAN很优秀,但也避免不了机器学习黑盒,缺乏严格证明的缺点。
(3) WGAN的使用以及保持G和D capacity 一致的重要性
WGAN 可以作为一个trick 用在PG-GAN来保证训练的稳定。WGAN-GP是WGAN的一个改进的版本,更适合使用。一般情况下,我们使用的WGAN-GP 作为model的GAN loss。原始的WGAN-GP训练比较慢的一个原因是 先训练 D多次(一般为5次,也就是n=5)保证拟合Wasserstein 距离,再去训练G。当然PG-GAN的设置 n=1,也就是交替训练D和G。这样设定也是有理由了。我们知道GAN的训练不稳定,一方面由于G和D capacity 有太大的差异。在学习率相同的情况下,G或者D一方太强都会造成model训练不出来。所以为了保证G和D的capacity一致,PG-GAN设置 n=1的同时,保证 G和D的训练参数数量一直基本相同。
我们来看不同的分辨率下G和D的训练参数的对比:
| 分辨率 | G(单位:M) | D(单位:M) |
|---|---|---|
| 4x4 | 6.56 | 6.55 |
| 8x8 | 11.2 | 11.2 |
| 16x16 | 13.05 | 14.04 |
| 32x32 | 13.49 | 13.48 |
| 64x64 | 13.59 | 13.60 |
| 128x128 | 13.62 | 13.62 |
从表格上看,G和D的参数数量基本保持一致。
(4)其他trick
- PG-GAN移除了deconv 网络,改用了conv + upsample。https://distill.pub/2016/deconv-checkerboard/ 提到了deconv会让生成模型遭受checkerboard效应。关于什么时候是checkerboard,可以参考链接的介绍。所以,我认为能用conv+unsample就不要用deconv。
- 非线性到线性: PG-GAN的G网络移除了tanh函数。论文并没有给出解释,但是在我们自己的实验总,认为这个是提升效果的。
- 移除到各种BN层:
关于原因,Improved GAN的原话解释: it causes the output of a neural network for an input example x to be highly dependent on several other inputs in the same minibatch. 毕竟BN是基于整个minibatch计算的均值和方差,然后归一化的。所以,正因为次,在风格转化的应用,相关论文使用Instance normalization(IN)代替了BN。PG-GAN的解释是: BN本身是为了移除covariate shift 问题,但是他们在GAN中并没有发现这个问题。
PG-GAN没有BN,IN。但是PG-GAN提出了Pixel Norm去约束由于G和D不健康的竞争造成的信号范围越界的问题,而且提出了一个基于He’s init 的动态的初始化方式来平衡学习率。
尽管论文证明这个这些方法能提升样本质量,但是实际上,这些方法很难被广泛认可和使用。
3. 总结
G-GAN的核心部分基本已经介绍完。原始论文将论文用到了大量的数据集,包括CIFAR-10数据集下,达到了最高的Inception score。结果也说明了PG-GAN的强大能力。
很多人可能会问,能生成高质量的样本有什么用吗?
一方面,基于强大的生成能力,可以被用做扩展数据集。另一方面,通过对GAN的模型的改造,可以被应用到很多领域,这时候,PG-GAN没准可以提高这些领域的效果,比如Image translation.
最后,一句话总结:
深度学习并不是画大饼就完事,要讲究细节。细节真的决定成败。
Ref
[1]DCGAN(https://arxiv.org/abs/1511.06434)
[2]WGAN(https://arxiv.org/abs/1701.07875)
[3]LS-GAN(https://arxiv.org/abs/1611.04076)
[4]WGAN-GP(https://arxiv.org/abs/1704.00028)
[5]Image-to-Image Translation with Conditional Adversarial Networks
[6]Improved Techniques for Training GANs
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013139259/article/details/78885815