入门篇——解析Python机器学习中三类无监督学习算法和两个应用实例
欢迎喜欢编程语言知识和机器学习算法等科技类文章,以及经济和历史等文史类文章的朋友们关注公众号:CodingFarmer2019,我们一起格物致知和学史悟道,实现人生辉煌!
https://mp.weixin.qq.com/s/ZNmFOxBoIteCKyl4uYqymA
目录
一、基本概念
二、无监督学习的三种算法
1.数据预处理方法
1.1 对样本数据的特征变量的取值进行预处理
1.2 对样本数据的特征变量的取值类型进行转换
2.数据的特征变量的降维和升维方法
2.1 对样本数据的特征变量进行降维处理
2.2 对样本数据的特征变量进行升维处理
3.聚类算法
3.1 K均值聚类算法
3.2 凝聚聚类算法
3.3 DBSCAN算法
三、两个应用于现实生活的机器学习算法实例
1.建立算法管道模型的股票分析实例
1.1 建立包含预处理和MLP神经网络的管道模型
1.2 使用管道模型进行特征选择
1.3 使用管道模型进行算法模型选择和参数调优
2.数据爬虫实例
2.1 网页爬虫进行本地保存
2.2 文本爬虫进行话题提取
一、基本概念
无监督学习是在没有训练数据集的情况下,对没有标签的数据进行分析并建立合适的模型以给出问题解决方案的机器学习方法,它本质上是一种统计手段,具备三个显著的特点,一是不像有监督学习那样有明确的学习目的;二是不像有监督学习那样要给训练数据标注标签;三是无法量化学习的效果。无监督学习算法常见的应用场景包括样本数据预处理、样本数据特征转换和聚类分析。
其中,样本数据预处理的作用是用预处理之后的样本数据训练有监督学习算法所构建的模型,能使模型的训练效果更好,能大大提高分类或回归任务的准确率,比如,常见的样本数据预处理方法之一就是对样本数据的取值范围进行缩放,使各特征值的取值在同一个数量级上,更有利于有监督学习模型的训练;样本数据特征转换的作用就是把原本特征比较复杂的数据集通过无监督学习算法转换成特征比较简单和容易理解的数据集,比如,常见的样本数据特征转换方法之一就是数据降维,也就是无监督学习算法通过对特征变量维数较多的数据集进行分析,剔除无关紧要的特征变量,降低特征变量的维数从而只保留下较为关键的特征变量;而聚类分析则是通过无监督学习算法把样本数据划归到不同的分组,使得每个分组中的数据元素都具有比较接近的特征。
本次入门篇重点介绍无监督学习中对样本数据的特征变量的取值范围进行处理和取值类型进行转换的数据预处理方法、对样本数据的特征变量进行降维的特征提取和特征选择方法、对样本数据的特征变量进行升维的交互式特征和多项式特征添加方法以及包含K均值聚类、凝聚聚类和DBSCAN在内的三种聚类算法的原理、用法和核心代码。此外,还额外介绍了两个应用于现实生活中的机器学习算法实例,一个是用训练好的管道模型预测中国A股市场自2021年2月21日收盘之后的股价涨幅走势,另一个则是实现一个爬虫程序来爬取目标网页上的内容并保存为本地文件来进行话题提取。
二、无监督学习的三种算法
1.数据预处理方法
对数据集中的样本数据进行第一种预处理就是对样本数据的特征变量的取值范围进行处理,这样做的意义就在于用预处理之后的样本数据再去训练有监督学习算法所构建的模型,能使模型的训练效果更好,能大大提高分类或回归任务的准确率。
对数据集中的样本数据进行第二种预处理就是对样本数据的特征变量的取值类型进行转换,这样做的意义同样是便于有监督学习算法对模型进行训练,从而纠正模型过拟合和欠拟合的问题。
1.1 对样本数据的特征变量的取值进行预处理
(1)StandardScaler算法
StandardScaler算法的基本原理是将所有样本数据的特征变量的取值转换成均值为0,方差为1的状态,这样能保证样本数据的特征变量的取值“大小”基本一致,更有利于有监督学习模型的训练,其用法为:
在Jupyter notebook中输入图1所示代码便可手动生成一个样本数量为40,分类数量为2,随机状态为50,标准差为2,特征变量数为2的数据集,并赋值给X和y。其中,X为二维特征向量,存储以上生成的具有2个特征变量的样本数据,y为一维向量,存储以上每个样本数据所属的分类 。

图1 生成样本数量为40,分类数量为2,特征变量数为2的数据集的代码
运行代码,将得到如图2所示的结果:
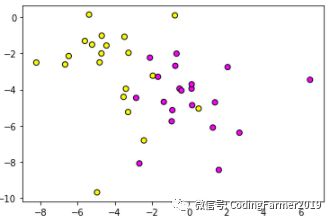
图2 手工生成的数据集
StandardScaler算法用于预处理任务时,需要先从scikit-learn库的preprocessing模块导入StandardScaler,再通过函数fit_transform( )对样本数据X进行预处理即可。整个过程的核心代码如下:

图3 StandardScaler算法用于数据预处理任务的核心代码
运行图3的代码,使用StandardScaler算法对图2手动生成的40个样本数据进行预处理,其结果如图4所示:

图4 StandardScaler算法对40个样本数据进行预处理的结果图
对比图2和图4,我们可以看出,最初手动生成的样本数据的特征1对应于x轴,取值大约在-8到7之间,特征2对应于y轴,取值大约在-10到0之间,特征的取值范围有些大;而经过StandardScaler预处理后的样本数据的分布情况与原始样本数据的分布一模一样,不同的只是特征变量的取值,经过预处理后的样本数据的特征1取值在-2到3之间,特征2取值在-3到2之间,这样能保证样本数据的特征的“大小”基本一致。
(2) MinMaxScaler算法
MinMaxScaler算法的基本原理是将所有样本数据的特征变量的取值转换至0到1之间,尤其对于特征变量维数为2的样本数据而言,MinMaxScaler算法的预处理方式就相当于是把这些数据压进了长和宽均为1的方格子当中,这个做法同样能让有监督学习模型的训练速度更快且准确率更高。
MinMaxScaler算法用于预处理任务时,需要先从scikit-learn库的preprocessing模块导入MinMaxScaler,再通过函数fit_transform( )对样本数据X进行预处理即可。整个过程的核心代码如下:

图5 MinMaxScaler算法用于数据预处理任务的核心代码
运行图5的代码,使用MinMaxScaler算法对图2手动生成的40个样本数据进行预处理,其结果如图6所示:
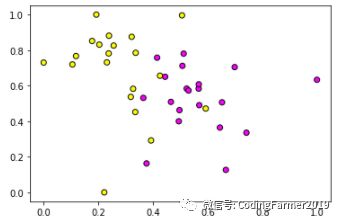
图6 MinMaxScaler算法对40个样本数据进行预处理的结果图
对比图2和图6,我们同样可以看出,经过MinMaxScaler预处理后的样本数据的分布情况与原始样本数据的分布也是一模一样,不同的只是特征变量的取值,经过预处理后的样本数据的两个特征变量的取值都被转换至0到1之间。
(3) RobustScaler算法
RobustScaler算法的基本原理与StandardScaler算法基本一致,所不同的是StandardScaler算法在转换特征变量的取值时用到的是均值和方差,而RobustScaler算法用到的是中位数和四分位数,而且它还会直接把一些异常值剔除。
RobustScaler算法用于预处理任务时,需要先从scikit-learn库的preprocessing模块导入RobustScaler,再通过函数fit_transform( )对样本数据X进行预处理即可。整个过程的核心代码如下:

图7 RobustScaler算法用于数据预处理任务的核心代码
运行图7的代码,使用RobustScaler算法对图2手动生成的40个样本数据进行预处理,其结果如图8所示:
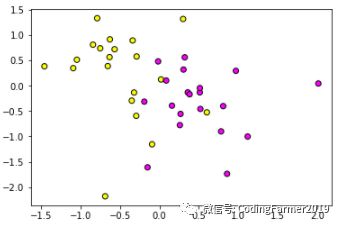
图8 RobustScaler算法对40个样本数据进行预处理的结果图
对比图2和图8,我们同样可以看出,经过RobustScaler预处理后的样本数据的分布情况与原始样本数据的分布也是一模一样,不同的只是特征变量的取值,经过预处理后的样本数据的特征1取值在-1.5到2之间,特征2取值在-2到1.5之间,这样能保证样本数据的特征的“大小”基本一致。
(4) Normalizer算法
Normalizer算法的基本原理是将所有样本数据的特征向量的模转换为欧几里得距离为1的状态,也就是说,它会把数据的分布转换成一个半径为1的圆,或一个球亦或是一个超球体。Normalizer算法通常是在只想保留样本数据的特征向量的方向而忽略其数值的场景下使用。
Normalizer算法用于预处理任务时,需要先从scikit-learn库的preprocessing模块导入Normalizer,再通过函数fit_transform( )对样本数据X进行预处理即可。整个过程的核心代码如下:

图9 Normalizer算法用于数据预处理任务的核心代码
运行图9的代码,使用Normalizer算法对图2手动生成的40个样本数据进行预处理,其结果如图10所示:
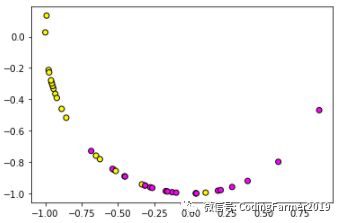
图10 Normalizer算法对40个样本数据进行预处理的结果图
对比图2和图10,我们可以看出,经过Normalizer预处理后的样本数据的分布情况与原始样本数据的分布完全不一样,Normalizer是把原始样本数据转换得最“面目全非”的算法了。
(5) 对样本数据的特征变量的取值进行预处理的意义
这样进行预处理的意义是想提高有监督学习算法所训练出的模型的准确率,究竟是否真如我们所愿,那就用scikit-learn库中内置的收集于真实世界的酒数据集来验证一下对样本数据的特征变量的取值进行预处理的效果。
首先在没有经过预处理的情况下,用酒数据集来训练一个MLP神经网络模型,再看一下该模型在测试集中的得分,其核心代码如下:

图11 MLP神经网络算法用于未经预处理的酒数据集分类任务的核心代码
运行图11的代码,使用MLP神经网络算法对未进行预处理的酒数据集进行训练所得到的模型在测试集上的评分结果如下:
![]()
图12 未进行训练数据预处理的MLP神经网络模型评分结果图
接下来对训练和测试数据分别进行预处理,用预处理之后的酒数据集来重新训练一个MLP神经网络模型,再看一下该模型在测试集中的得分,其核心代码如下:

图13 MLP神经网络算法用于预处理后的酒数据集分类任务的核心代码
运行图13的代码,使用MLP神经网络算法对预处理之后的酒数据集进行训练所得到的模型在测试集上的评分结果如下:
![]()
图14 对训练数据预处理之后的MLP神经网络模型评分结果图
对比图12和图14,我们可以看出,在没有对训练数据进行预处理的情况下,MLP神经网络训练出的模型在测试集上的准确率只有0.6;而在对训练数据进行预处理之后,MLP神经网络训练出的模型在测试集上的准确率竟然达到了0.98,这完全能验证对样本数据的特征变量的取值进行预处理的意义,也就是,用预处理之后的样本数据再去训练有监督学习算法所构建的模型,能大大提高模型的准确率。
1.2 对样本数据的特征变量的取值类型进行转换
在现实世界中,我们将那些取值类型为字符串类型的特征变量称为“类型特征”,把取值类型为数值类型的特征变量称为“连续特征”,接下来重点介绍如何将类型特征转换为二值型连续特征,以及将连续特征转换为类型特征。
(1)使用哑变量将类型特征转换为二值型连续特征
所谓哑变量(Dummy Variables),也称为虚拟变量,常常用来把类型变量转换为二值变量,这里采用了pandas的get_dummies哑变量函数将类型特征转换为用0和1表达的二值型连续特征。
首先生成一个既有数值特征也有类型特征的样本数据集,其核心代码为:

图15 生成既有数值特征也有类型特征的样本数据集的核心代码
运行图15的代码,会得到图16所示的样本数据集。
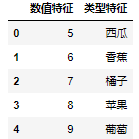
图16 手动生成的水果数据集
get_dummies()哑变量函数将类型特征转换为二值型连续特征时,需要先导入pandas库,再通过函数get_dummies( )对样本数据的类型特征进行转换即可。整个过程的核心代码如下:

图17 使用哑变量将类型特征转换为二值型连续特征的核心代码
运行图17的代码,会得到图18所示的转换之后的样本数据集。

图18 经过get_dummies转换之后的水果数据集
对比图16和18,可以看出,使用get_dummies()函数将之前的类型特征全部转换成了只有0和1的二值型连续特征,从图18可以看出是一个稀疏矩阵,而数值特征并没有发生任何变化。
(2)使用装箱处理将连续特征转换为类型特征
所谓装箱处理就是将连续特征离散化处理成类型特征。首先随机生成特征变量维度为1的样本数据集,其核心代码为:

图19 随机生成特征变量维度为1的样本数据集的核心代码
运行图19所示的代码,会得到图20所示的随机样本数据集。

图20 随机生成的特征变量维度为1的样本数据集
接下来使用OneHotEncoder方法对这些数据进行装箱处理,OneHotEncoder算法用于装箱处理时,需要先将数据进行装箱操作,再从scikit-learn库的preprocessing模块导入OneHotEncoder,最后通过拟合函数fit()和转换函数transform()进行处理即可。整个过程的核心代码如下:

图21 使用OneHotEncoder进行装箱处理的核心代码
运行图21的代码,会得到图22所示装箱后的样本数据形态。由于我们在生成这个特征变量维度为1的样本数据集时,是在-5到5之间随机生成50个数据点。因此在生成“箱子”的时候,也指定范围是从-5~5之间,生成11个元素的等差数列,这样每两个数值之间就形成一个箱子,一共10个箱子。从图22所示的结果中可以看出,第一个箱子是-5~-4之间,第二个箱子是-4~-3之间,以此类推;第1个数据点-1.1522688所在的箱子是第4个,第2个数据点3.59707847所在的箱子是第9个,以此类推。这样一来,我们使用OneHotEncoder就把原始数据集的连续特征转换为类型特征。虽然样本数据个数为50,但特征变量维度却由1变成了10,这是由于我们生成的箱子数目为10,而新数据点的特征是用其所在的箱子编号来表示的。例如,第1个数据点在第4个箱子中,则其特征变量中第4个维度为1,其他维度为0,其他数据点以此类推。

图22 装箱处理之后样本数据形态的结果图
最后用MLP算法来验证一下使用装箱处理后的样本数据在模型训练中的优势,尤其是针对大规模高维度的数据集使用线性模型的时候,装箱处理可以大幅提高线性模型的预测准确率。使用MLP算法来拟合图20中的原始样本数据和图22中装箱处理后的样本数据时,整个过程的核心代码如下:

图23 使用MLP算法拟合原始样本数据和装箱处理后样本数据的核心代码
运行图23所示的代码,会得到图24所示的拟合结果图。从图中可以看出,使用装箱处理之后的样本数据来训练MLP神经网络模型,会让MLP回归模型变得更加复杂,这样可以纠正模型欠拟合的问题。
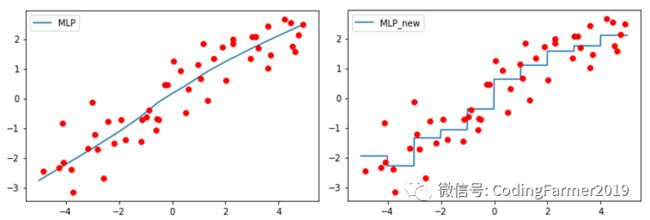
图24 使用MLP算法拟合原始样本数据和装箱处理后样本数据的结果图
2.数据的特征变量的降维和升维方法
现实世界中,样本数据往往具有很多特征,但并不是每一个特征都对预测结果起着同样关键的作用,所以这些不重要的特征是冗余的,而且在机器学习中还有可能增加模型的复杂度。因此,有必要通过一种方式来降低样本数据的特征变量的维度。对样本数据的特征变量进行降维处理就是减少样本数据的特征变量的维度,这样做的意义就在于一方面将那些特征变量具有成千上万维度的数据集进行降维后有利于加速机器学习的训练过程,另一方面将那些特征变量之间有强烈相关性的数据集进行降维后有利于降低机器学习模型的复杂度。其中,用于样本数据的特征变量降维的方式主要有两种,分别是特征提取和特征选择。特征选择这一概念很容易理解,就是从样本数据的原始特征中选择最关键、最重要的特征,并且直接舍去其他特征,从而达到将样本数据的特征变量进行降维的目的。然而,特征提取并非是简单地从原始特征中选取主要的特征,而是将所有原始特征经过“加权求和”后生成新的特征来达到对特征变量进行降维的目的。
对样本数据的特征变量进行升维处理就是增加样本数据的特征变量的维度,这样做的意义就在于扩充了低维样本数据的特征变量的维度之后,再去训练有监督学习算法所构建的模型,能够让原本容易出现欠拟合现象的模型有更好的性能。
2.1 对样本数据的特征变量进行降维处理
(1)特征提取
用于特征提取任务的无监督学习算法主要有主成分分析法和非负矩阵分解法两种。
(1-1)主成分分析法
假设有人在只考虑汽车动力和外观这两个因素的情况下去买车,如图25所示,可以直观地看出汽车外观对这个人的喜好影响比较大,而动力性能影响相对较小。
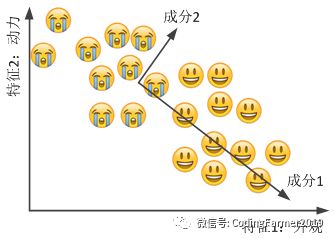
图25 在数据集添加主成分标注
我们可以在图25中添加一下主成分标注,把数据点分布最“长”的方向标注为“成分1”,而与之成90度角的方向标注为“成分2”,重新画这个图,就是图26。对比图25和图26,我们可以看出,经过这样处理之后,数据集就从一个散点组成的面变成了一条直线,也就实现了样本数据的特征变量从二维降低为一维的目标,而这里我们所用到的数据降维的方法就是主成分分析法(Principal Component Analysis, PCA),它是一种无监督学习算法。当然,为了便于展示,这里用到了一个二维数据降到一维数据的例子,其实在现实世界中,可以利用PCA主成分分析法对特征变量具有成千上万维度的样本数据进行降维处理。

图26 只考虑主成分的数据集
这里仍然以酒数据集为例,演示一下PCA主成分分析算法的使用。首先,我们来看未经PCA主成分分析算法处理的酒数据集的形态,其核心代码和结果如图27所示:

图27 原始的酒数据集的样本数和特征变量维度
PCA主成分分析算法用于特征提取任务时,需要先从scikit-learn库的decomposition模块导入PCA,再通过函数fit( )对样本数据进行拟合,最后通过函数transform( )对样本数据进行转换即可。整个过程的核心代码以及结果如下:

图28 PCA算法用于特征提取任务的核心代码以及结果图
对比图27和28,可以看出,未经PCA主成分分析算法处理的酒数据集合中的样本数量为178个,每个样本数据的特征变量的维度为13,而经过PCA主成分分析算法处理后的酒数据集合中的样本数量仍然为178个,每个样本数据的特征变量的维度却降为了2。以前为了进行可视化,只能取酒数据集的前两个特征,砍掉了其余的11个特征,这当然是不科学的。现在可以使用PCA主成分分析算法将数据集的特征变量的维度降为二维,既可以轻松进行可视化处理,又不会丢失太多信息。那么,原来的13个特征和经过PCA算法降维后的2个主成分之间是什么关系呢?这里绘制出主成分和原始特征的热度图,其核心代码如下:

图29 绘制主成分和原始特征的热度图的核心代码
运行图29的代码,得到经过PCA算法降维后的2个主成分和原始特征的热度图如下:

图30 PCA算法生成的主成分和原始特征的热度图
从图30可以看出,用于特征提取的PCA算法并非是从13个特征中简单地取出两个特征作为主成分,而是在两个主成分中,分别涉及了所有的13个特征,也就是说主成分是所有原始特征经过“加权求和”后所生成的新特征。而且,从热度图中可以看出,如果某个原始特征对应的数字是正数,说明该特征和主成分之间是正相关的关系,反之就是负相关的关系。
在PCA主成分分析算法中,需要特别注意的参数就是n_components,该参数既可以设置为整数,代表所要设置的主成分的个数,也可以设置为0~1之间的小数,表示将特征变量降维之后所保留信息的百分比,假如我们希望降维之后保留原始特征90%的信息,则可以将n_components设置为0.9。另外,在神经网络的训练数据的特征变量降维过程中,常常用到PCA主成分分析算法的数据白化功能,因为训练数据在未处理之前,其特征变量之间往往是冗余的,白化的目的就是为了降低冗余性,所以数据白化的过程会让训练数据的特征变量之间的相关度降低。PCA主成分分析算法的数据白化的用法示例为:pca = PCA( whiten = True, n_components = 0.9, random_state = 62 ) 。
(1-2)非负矩阵分解法
另外一种用于数据降维的特征提取方法就是非负矩阵分解(Non-Negative Matrix Factorization, NMF),它也是一种无监督学习算法。所谓非负矩阵分解就是,把所有元素数值大于或等于0的原始矩阵拆解成所有元素数值仍大于或等于0的n个新矩阵的乘积。为了便于展示,这里仍然用到一个二维数据的例子,如图31所示,可以想象有一堆特征值杂乱无章地堆放在二维空间中,而NMF算法就可以看成是从坐标原点引出一个或几个向量来尽可能地把原始特征值的信息全部表达出来。
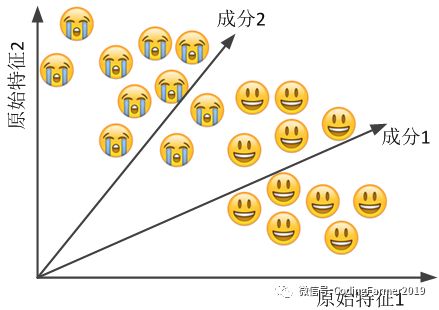
图31 NMF非负矩阵分解算法的示意图
NMF非负矩阵分解算法用于特征提取任务时,需要先从scikit-learn库的decomposition模块导入NMF,再通过函数fit( )对样本数据进行拟合,最后通过函数transform( )对样本数据进行转换即可。仍然采用图17生成的原始酒数据集进行特征提取,整个过程的核心代码如下:

图32 NMF算法用于特征提取任务的核心代码
运行图32的代码,得到经过NMF算法降维后的2个主成分和原始特征的热度图如下:

图33 NMF算法生成的主成分和原始特征的热度图
从热度图33可以看出,用于特征提取的NMF算法同样是将所有原始特征经过“加权求和”后生成新的主成分。而且,NMF算法生成的主成分与原始特征之间只存在正相关关系或没有关系,这是因为NMF算法只能对非负矩阵进行处理。值得注意的是,与PCA算法不同,NMF算法的n_components参数不支持0~1之间的小数,只能设置为正整数,表示所要设置的主成分的个数。
(2)特征选择
用于特征提取任务的无监督学习算法主要有基于单一变量法的特征选择、基于模型的特征选择和迭代式特征选择。
(2-1)基于单一变量法的特征选择
所谓单一变量法指的是只选择那些置信度比较高的特征进行分析,也就是说只选择那些和预测目标有明显相关性的特征进行分析,其他不重要的特征均可忽略,这里主要通过feature_selection模块的SelectPercentile函数来实现基于单一变量法的特征选择。
接下来,采用现实世界的酒数据集来验证SelectPercentile函数进行特征选择的效果,首先利用数据集拆分工具train_test_split将酒数据集拆分成训练集和测试集两部分,然后再通过StandardScaler算法对训练数据和测试数据进行取值预处理,也就是将这些数据进行缩放使其取值更集中、更易于有监督学习算法进行模型的训练,最后采用MLP神经网络模型来预测测试集中酒的分类,整个过程的核心代码以及结果如下:

图34 验证SelectPercentile函数特征选择效果的酒数据集的生成核心代码和结果图
SelectPercentile函数用于特征选择任务时,需要先从scikit-learn库的feature_selection模块导入SelectPercentile,再通过函数fit( )对样本数据进行拟合,最后通过函数transform( )对样本数据进行特征选择即可。整个过程的核心代码如下:

图35 SelectPercentile函数用于特征选择任务的核心代码
运行图35所示的代码,得到特征选择之后的样本数据的形态、被选择保留后的特征(下图中黄色区域)以及利用特征选择之后的数据集训练得到的MLP神经网络模型在测试集中对酒进行分类的准确性,如图36所示:

图36 SelectPercentile函数用于特征选择任务的结果图
从图35的代码中可以看出,我们指定了SelectPercentile函数的百分比参数percentile为50,也就是只选择保留一半左右的原始特征,所以酒数据集由原始的13个特征变量降为了6个特征变量。此外,进行特征选择之后,我们看到MLP神经网络模型的准确率轻微地降低了,这是由于酒数据集并不包括噪声,对于噪声特别多的数据集来说,进行特征选择之后再去训练有监督学习算法所构建的模型,其准确率肯定会提高,而非降低。
(2-2)基于模型的特征选择
所谓基于模型的特征选择指的是先使用一个有监督学习算法所构建的模型对样本数据的特征变量的重要性进行判断,然后选择较为重要的特征进行保留,其他不重要的特征均可舍去,这里主要通过SelectFromModel方法来实现基于模型的特征选择。当然,这里选择的有监督学习算法和最终用来进行预测分析的有监督学习算法不一定是同一个。
接下来仍然采用图34生成的酒数据集来验证SelectFromModel方法的特征选择效果。SelectFromModel方法用于特征选择任务时,需要先从scikit-learn库的feature_selection模块导入SelectFromModel,再选择一个有监督学习算法所构建的模型来评判特征变量的重要性,最后通过函数fit( )对样本数据进行拟合和通过函数transform( )对样本数据进行特征选择即可。整个过程的核心代码如下:

图37 SelectFromModel方法用于特征选择任务的核心代码
运行图37所示的代码,得到特征选择之后的样本数据的形态、被选择保留后的特征(下图中黄色区域)以及利用特征选择之后的数据集训练得到的MLP神经网络模型在测试集中对酒进行分类的准确性,如图38所示:

图38 SelectFromModel方法用于特征选择任务的结果图
从图37的代码中可以看出,我们选择了随机森林分类算法这个有监督学习算法所构建的模型来评判样本数据的特征变量的重要性,同时指定了threshold阀值参数为median中位数,这也意味着该方法会选择一半左右的特征变量。对比图38和36可以看出,基于模型的特征选择方法保留的特征为7个,比单一变量法选择保留的特征多了一个;同时,通过基于模型的特征选择之后,我们看到MLP神经网络模型的准确率升高到了0.98,比使用单一变量法进行特征选择后训练出的MLP神经网络模型的准确率高了一些,与使用原始酒数据集训练的MLP神经网络模型的准确率一样高。因此,基于模型的特征选择方法的特征选择效果是相当好的。
(2-3)迭代式特征选择
所谓迭代式特征选择指的是基于若干个有监督学习算法所构建的模型进行特征选择,在最开始,迭代式特征选择方法会用某个模型对特征变量进行选择,之后再建立两个模型,其中一个对已被选择的特征进行筛选,另外一个对已被剔除的特征再次进行筛选,就这样一直重复这个步骤,直到达到指定保留的特征数量为止。这里主要通过递归特征剔除法(Recurise Feature Elimination, RFE)方法来实现迭代式特征选择。
接下来仍然采用图34生成的酒数据集来验证RFE方法的特征选择效果。RFE方法用于特征选择任务时,需要先从scikit-learn库的feature_selection模块导入RFE,再选择一个有监督学习算法通过先后构建多个模型来评判特征变量的重要性,最后通过函数fit( )对样本数据进行拟合和通过函数transform( )对样本数据进行特征选择即可。整个过程的核心代码如下:

图39 RFE方法用于特征选择任务的核心代码
运行图39所示的代码,得到特征选择之后的样本数据的形态、被选择保留后的特征(下图中黄色区域)以及利用特征选择之后的数据集训练得到的MLP神经网络模型在测试集中对酒分类的准确性,如图40所示:

图40 RFE方法用于特征选择任务的结果图
从图39的代码中可以看出,我们仍然选择了随机森林分类算法这个有监督学习算法,通过先后构建多个模型来评判样本数据的特征变量的重要性,同时指定了n_features_to_select参数为7,这也意味着该方法会选择与基于模型的特征选择方法一样多的特征变量。对比图40和38可以看出,迭代式特征选择方法与基于模型的特征选择方法选择保留的特征变量一模一样;同时,通过迭代式特征选择之后,我们看到MLP神经网络模型的准确率仍然是0.98,与使用基于模型的特征选择方法得到的样本数据训练出的MLP神经网络模型的准确率一样高,因此,可以看出迭代式特征选择方法的特征选择效果也是相当好的。这也能说明,不同的方法并没有绝对的好与不好,只是适用的场景不同罢了。
2.2 对样本数据的特征变量进行升维处理
在现实世界中,有时会遇到样本数据特征不足的情况,这时就需要对样本数据的特征变量进行升维处理,也就是需要对样本数据的特征进行扩充,这样能让容易出现欠拟合现象的模型有更好的性能。这里主要介绍两种对特征变量进行升维的方法,一种是向样本数据添加交互式特征,另一种就是向样本数据添加多项式特征。
(1)向样本数据添加交互式特征
所谓交互式特征,指的是在样本数据的原始特征中添加交互项,使特征变量的维度增加。这里主要通过Numpy库的hstack函数来实现对样本数据添加交互项,仍然采用装箱处理之后的图22中样本数据集X_in_bin来进行特征变量升维操作,其核心代码以及结果如下:

图41 hstack函数向样本数据添加交互式特征的核心代码和结果图
从以上的结果可以看出,我们把样本数据的原始特征和装箱处理后的特征堆叠在一起,形成了特征变量升维后的新样本数据X_stack,X_stack的数量仍然是50个,而特征变量的维度升至了11。接下来用新样本数据X_stack来重新训练MLP神经网络模型,并与之前用装箱处理后的样本数据训练得到的MLP神经网络模型拟合的结果图24进行对比,其核心代码如下:

图42 利用新样本数据X_stack来重新训练MLP神经网络模型的核心代码
运行图42所示的代码,新样本数据X_stack重新训练MLP神经网络模型得到的拟合结果如图43所示。对比图24和43可以看出,在仅仅用装箱处理后的样本数据X_in_bin训练出的MLP神经网络模型所得到的拟合结果图24中,模型在每一个箱子中都是水平的,而用经过添加交互式特征升维后的样本数据X_stack训练出的MLP神经网络模型所得到的拟合结果图43中,模型在每一个箱子中都是有斜率的,这说明相比于图24中的模型,图43中的模型复杂度有所提高。
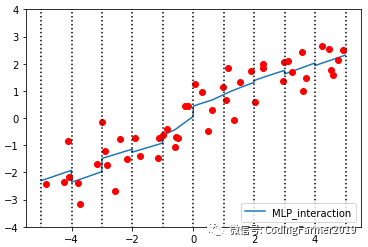
图43 利用新样本数据X_stack来重新训练MLP神经网络模型得到的拟合结果图
但是图43中每个箱子的斜率都是一样的,而我们想要的效果是每个箱子中都有各自的截距和斜率,所以还要对样本数据的特征变量继续进行升维,整个过程的核心代码如下:

图44 利用继续升维后的样本数据X_stack_new来重新训练模型的核心代码
运行图44所示的代码,利用继续升维后的样本数据X_stack_new重新训练MLP神经网络模型得到的拟合结果如图45所示。对比图43和45可以看出,新样本数据X_stack_new的特征变量的维度更高了,由原先的11维升至了20维,并且所训练出的MLP神经网络模型拟合出的效果更好,每个箱子中的模型都有了自己的截距和斜率。这说明在低维样本数据中,我们有时需要对其特征变量进行升维处理,进而提升有监督学习算法所构建模型的准确率。
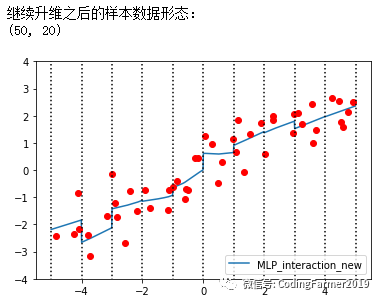
图45 利用继续升维后的样本数据X_stack_new来重新训练模型得到的拟合结果图
(2)向样本数据添加多项式特征
所谓多项式特征,指的是在样本数据的原始特征X中添加它的乘方,如X^2、X^3、X^4、X^5和X^6等等,使特征变量的维度增加。这里主要通过preprocessing库的PolynomialFeatures函数来实现对样本数据添加多项式,需要先从scikit-learn库的preprocessing模块导入PolynomialFeatures,再通过函数fit_transform( )对样本数据的特征变量进行升维即可,仍然采用图20中随机生成的样本数据集X来进行特征变量升维操作,其核心代码以及结果如下:

图46 PolynomialFeatures函数向样本数据添加多项式特征的核心代码和结果图
从图中可以看出,PolynomialFeatures对样本数据处理之后,第一个特征确实就是样本数据的原始特征,第二个特征是样本数据的原始特征的2次方,第三个特征是样本数据的原始特征的3次方,以此类推。因此,对于低维数据集来说,线性模型往往会出现欠拟合的问题,而在进行特征变量扩充之后,可以在一定程度上解决线性模型欠拟合的问题。
3.聚类算法
无监督学习中的聚类任务与有监督学习中的分类任务有一定的相似之处,但分类是有监督学习算法基于已有标签的数据进行学习并对新数据进行分类,而聚类则是在完全没有标签的情况下,用无监督学习算法去“猜测”哪些数据应该“堆”在一起,并且给不同的“堆”里的数据打好标签。这里重点介绍K均值聚类、凝聚聚类和DBSCAN三种聚类算法。
3.1 K均值聚类算法
K均值(K-Means)聚类算法的原理是,样本数据因为特征不同而散布在空间中,K均值算法会不断循环计算出具有相似特征值的样本所形成数据堆的均值,直到达到终止条件为止,其中,参数K的值就是最终聚类的样本数据堆的个数。
接下来,用手工生成的数据集来演示一下K均值(K-Means)聚类算法的工作过程,手工生成数据集的核心代码以及结果图如下:

图47 手工生成样本数和分类数均为1的数据集的核心代码和结果图
然后使用K均值聚类算法对这些数据进行聚类分析,K均值聚类算法用于聚类任务时,需要先从scikit-learn库的cluster模块导入KMeans,再指定聚类中心的个数K的值,最后通过拟合函数fit()进行拟合和预测函数predict()进行聚类打标签即可。整个过程的核心代码如下:

图48 K均值聚类算法的核心代码
运行图48所示的代码,得到图49所示的K均值聚类算法对手工生成样本数和分类数均为1的数据集的聚类结果。从图中可以看出,K均值聚类算法是按照我们指定的聚类中心的个数来进行聚类处理的,并且在图上标注出了每个样本数据堆的聚类中心的位置。从图49还可以看出,K均值聚类算法对样本数据进行聚类的方式和分类方法有些类似,是用0、1和2等一些数字来标注样本数据所属的类别,并且存储在labels_属性中。K均值聚类算法看起来比较简单和容易理解,但它的局限性在于它认为每个样本数据点到聚类中心的方向是同等重要的,如果对于“形状”复杂的数据集来说,K均值聚类算法就不能很好地工作。
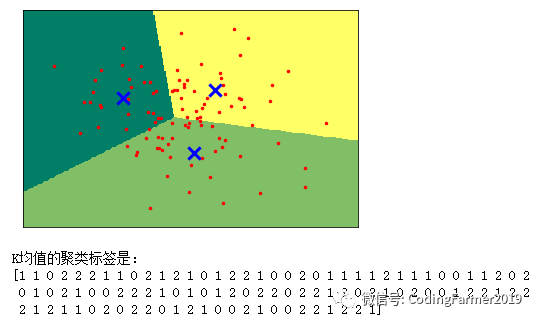
图49 K均值聚类算法的结果图
3.2 凝聚聚类算法
凝聚聚类算法的原理是,首先将每个样本数据点看成一个聚类中心,然后自下而上地不断合并相似的聚类中心,让聚类的类别越来越少,同时每个聚类中心的距离也越来越远,不断重复这个过程,直至剩下的聚类中心达到了当初设定的数目为止。
接下来,仍然用图47手动生成的样本数和分类数均为1的数据集来演示一下凝聚聚类算法的工作过程,凝聚聚类算法用于聚类任务时,需要先从scipy库的cluster.hierarchy模块导入dendrogram和ward,再通过函数ward()进行拟合,最后通过函数dendrogram()进行聚类打标签即可。整个过程的核心代码如下:

图50 凝聚聚类算法的核心代码
运行图50所示的代码,得到图51所示的凝聚聚类算法对手工生成样本数和分类数均为1的数据集的聚类结果。从图中可以看出,凝聚聚类算法是采取这种逐级合并具有相似特征取值的样本数据点所构成的数据堆,最终完成整个聚类过程。当然,和K均值聚类算法类似,凝聚聚类算法也无法对“形状”复杂的样本数据进行正确的聚类分析。

图51 凝聚聚类算法的结果图
3.3 DBSCAN算法
DBSCAN算法的中文全称为“基于密度的有噪声应用空间聚类”(Density-based spatial clustering of applications with noise),其工作原理就如同它名字的含义一样,也就是通过对特征空间内样本数据的分布密度进行检测,密度大的地方会被认为是一个聚类类别,而密度小的地方会被认为是相邻两个聚类类别的分界线。这样的工作机制使得DBSCAN算法不需要像K均值聚类算法那样在最开始就要指定聚类中心的数量。
接下来,仍然用图47手动生成的样本数和分类数均为1的数据集来演示一下DBSCAN算法的工作过程,DBSCAN算法用于聚类任务时,需要先从scikit-learn库的cluster模块导入DBSCAN,再通过函数fit_predict()进行聚类打标签即可。整个过程的核心代码如下:

图52 DBSCAN算法的核心代码
运行图52所示的代码,得到图53所示的DBSCAN算法对手工生成样本数和分类数均为1的数据集的聚类结果。从图中可以看到,DBSCAN算法得到的聚类标签中出现了-1,代表该样本数据点为噪声。我们可以看到中间深色的数据点的密度比较大,因此DBSCAN算法将它们划归为“一坨”,而外围的浅色数据点的密度相对较小,DBSCAN算法认为它们根本不属于任何一类,所以放进了“噪声”中。
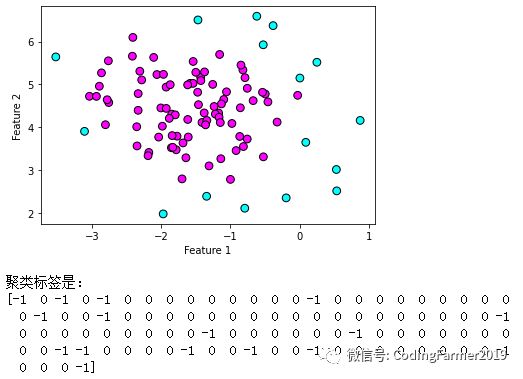
图53 DBSCAN算法的结果图
图53的聚类结果是DBSCAN算法中两个重要的参数eps和min_samples都采用默认值的情况下得到的。其中,eps参数表示的是划归到同一堆的样本数据点的距离,eps值设置的越大,则聚类过程中每一类别所覆盖的数据点就越多,反之则越少;min_samples参数表示的是聚类核心点的个数,min_samples值设置的越大,则核心数据点就越少,噪声数据点就越多,反之则噪声数据点越少。
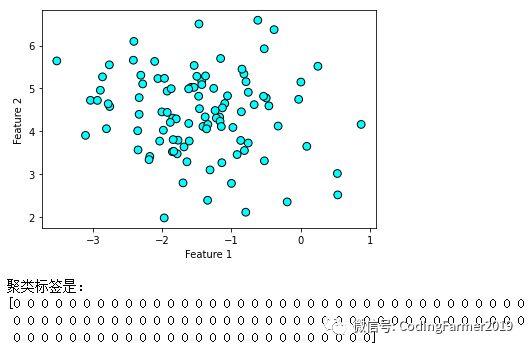
图54 eps设置为2时DBSCAN算法的聚类结果图

图55 min_samples设置为20时DBSCAN算法的聚类结果图
图54和图55分别是eps参数由默认值0.5调大设置成2所得到的聚类结果以及min_samples参数由默认值2调大设置成20所得到的聚类结果。从图54可以看出,在增加了eps参数的值以后,所有的数据点均被划归到了同一个类别中,从聚类标签也可以看出此时没有噪声数据点,这是因为增加了eps参数的取值后,DBSCAN算法把距离更远的数据点也拉到了这个聚类中了。从图55可以看出,在增加了min_samples参数的值以后,浅色的噪声数据点变多了,而在聚类中被划为类别0的深色数据点变少了,这是因为增加了min_samples参数的取值后,DBSCAN算法的聚类核心点的个数变少了,噪声数据点就变多了。
因此,虽然DBSCAN算法并不需要我们在最开始就指定聚类中心的数目,但通过对参数eps和min_sample进行赋值,就相当于间接指定了聚类中心的数量,尤其是eps参数的影响最为重要,因为它会直接决定某一个聚类类别中数据堆的空间范围的大小。此外,在现实世界中,如果将样本数据的取值先用MinMaxScaler和StandardScaler进行预处理,那么DBSCAN算法的聚类效果会更好,这是因为这两种预处理方法能把样本数据的取值范围控制得更集中,更有利于聚类分析。
三、两个应用于现实生活的机器学习算法实例
1.建立算法管道模型的股票分析实例
1.1 建立包含预处理和MLP神经网络的管道模型
所谓管道模型指的是在机器学习中,把一系列算法诸如数据预处理、数据特征升维和降维、有监督学习算法、模型测试验证以及网格搜索参数调优等打包在一起,让它们各司其职,形成一个完美配合的流水线来合力求解一个问题,这就是管道模型。
首先,通过股票交易软件通达信获取一个来自真实世界的中国A股市场自2021年2月21日收盘之后的股价涨幅数据集,使用该软件的数据导出功能将这些股票数据导出到Excel表格中,只保留"涨幅%"、"现价"、"涨跌"、"买价"、"卖价"、"总量"、"现量"、"涨速%"、"换手%"、"今开"、"最高"、"最低"、"昨收"、"市盈(动)"、"总金额"、"量比"、"振幅%"、"均价"、"内盘"、"外盘"、"内外比"、"买量"、"卖量"和"流通股(亿)"共24列,其他列的信息主要是一些冗余信息,均删除后并将这个Excel表格另存为一个CSV文件,图56展示了通过以上步骤处理后的股票数据集的一部分。

图56 处理后的股票数据集的部分图
接下来,加载处理后的CSV文件并查看股票数据集的形态,其核心代码为:

图57 加载并查看股票数据集形态的核心代码
运行图57所示的代码,得到股票数据集的特征变量形态和目标标签的形态,如图58所示,可以看出,数据集中共有3996支股票,每支股票包含23个特征,其目标标签是涨幅。

图58 股票数据集的形态图
所以接下来就建立包含预处理和MLP多层感知神经网络的管道模型来对股票数据进行回归分析,期望在给定一支具体股票的23个特征的特征值后,能用训练好的模型来预测这支股票的走势,是涨还是跌,涨能涨多少,跌又会跌多少。此外,这里采用交叉验证法cross_val_score来对训练好的管道模型进行评分,看看训练好的管道模型的表现如何。整个过程的核心代码如下:

图59 建立包含预处理和MLP神经网络的管道模型的核心代码
这里建立的管道模型在交叉验证评分中,每次都会先对数据集进行预处理,再通过MLP神经网络拟合回归模型。运行图59所示的代码,得到用于预测股票涨幅的用管道模型建立的MLP神经网络模型的评分结果,如图60所示。由于在本次建立的MLP神经网络模型中,采用的都是默认参数,如MLP的隐藏层默认采用一层100个节点,并没有对这些关键参数进行调优使模型表现更好,所以对3996支股票的涨幅有75%的正确预测率已经相当不错了。
![]()
图60 用管道模型建立的MLP神经网络模型的评分结果图
1.2 使用管道模型进行特征选择
为了进一步验证以上遴选出的23个特征中有哪些才是对股票涨幅起到关键作用的,这里将上面第二节介绍过的基于随机森林模型的特征选择方法加入到管道模型中,进而对股票数据集中的23个特征变量进行选择。整个过程中的核心代码如下:

图61 使用管道模型进行特征选择的核心代码
运行图61所示的代码,得到采用默认参数的MLP神经网络模型经过SelectFromModel选择后的特征保留结果,如图62所示。从图中可以看出,这里只选择保留了3个特征(图中黄色区域),分别是"涨跌"、"卖价"和"振幅%",并且利用只保留了这3个特征的股票数据集训练出的MLP神经网络模型的评分是0.74,对比图60的未经特征选择的用管道模型建立的MLP神经网络模型的评分结果0.75,该模型的性能表现算是不错的了。

图62 使用管道模型进行特征选择的结果图
1.3 使用管道模型进行算法模型选择和参数调优
上面建立的管道模型中MLP神经网络算法都是采用默认参数设置,接下来我们进一步探索如何使用管道模型选择性能表现更好的算法模型以及找到模型更优的参数。这里我们需要定义一个参数字典params作为管道模型的模型选择和参数调优的参数。在参数字典中,提供了两种算法模型可供选择,分别是MLP神经网络算法模型和随机森林算法模型,并且指定对MLP神经网络算法模型使用StandardScaler预处理,为MLP算法的隐藏层数量以及中间节点数目这两个调优参数提供了一个取值列表进行参数设置,分别是(50,)、(100,100) 和 (500,500);然而对随机森林算法模型RandomForest不使用StandardScaler预处理,为RandomForest算法的随机森林数量这个调优参数提供了一个取值列表进行参数设置,分别是10,、50 和 100。这里采用 sklearn库的model_selection模块中GridSearchCV网格搜索方法进行算法模型选择和参数调优,整个过程的核心代码如下:

图63 使用管道模型进行算法模型选择和参数调优的核心代码
运行图63所示的代码,得到使用管道模型进行算法模型选择和参数调优的结果,如图64所示。从图中可以看出,当随机森林算法中随机森林数量为100的时候,随机森林算法模型的评分超过了MLP神经网络算法模型,达到了0,91,相比之前采用默认参数训练出的MLP神经网络模型所得到的评分0.75,这次经过算法模型选择和参数调优后的分数有了显著的提升。这也就是说,利用这个经过算法模型选择和参数调优后的管道模型在对一支具体股票进行走势预测时,能有91%的概率成功预测这支股票的涨幅,这是一个令人激动和有趣的机器学习算法应用于实际生活的例子。
![]()
图64 使用管道模型进行算法模型选择和参数调优的结果图
2.数据爬虫实例
2.1 网页爬虫进行本地保存
这里将介绍如何使用基于Python语言的Requests库、BeautifulSoup库和lxml库来实现一个爬虫程序,把目标网页上的内容爬取下来并保存为本地Excel表格,用表格呈现出每一条内容的发文单位、标题和链接。这样就可以大致浏览一下有没有我们感兴趣的内容,如果有的话再单击链接来阅读详细信息,也便于我们使用邮件与他人进行分享。
首先,需要百度搜索“UA 查询”来查询到自己本机的user agent,它的作用是向目标网站“自报家门”,告诉目标网站的服务器正在请求访问的电脑的操作系统是什么、CPU类型是什么、浏览器是哪一款以及浏览器版本是什么;因为我们要让爬虫程序假装一个正常的用户在使用浏览器对目标网站发出访问请求,不然很容易被目标网站的服务器识破身份,对于有些网站,会对访问用户的user agent 进行校验,如果没有的话,就会被服务器拒之门外。然后,通过Requests库的get( )函数向目标网站发出访问请求,这里以访问中华人民共和国中央人民政府官网中的最新政策栏目为例,其地址为:http://www.gov.cn/zhengce/zuixin.htm 。最后,使用 BeautifulSoup库和lxml库来共同解析Requests库爬取下来的HTML文件,并将解析出的每一条内容的发文单位、标题和链接输出到本地文件进行保存。整个过程的核心代码如下:

图65 对目标网页进行爬虫并保存为本地文件的核心代码
运行图65所示的代码,打开文件保存的目录,会得到一个csv文件,用Excel打开这个文件,里面的内容就是我们爬取中华人民共和国中央人民政府官网的最新政策栏目中一条条最新政策的发文单位、标题和链接,如图66所示。

图66 对目标网页进行爬虫并保存为本地文件的结果图
2.2 文本爬虫进行话题提取
尽管前面已经实现了对目标网页进行爬虫并保存为本地文件的功能,但如果程序爬取的文本内容特别多的时候,即使保存在本地,也需要我们花很长时间去阅读。那么如何快速了解一大段成千上万文字的核心内容呢?这就需要利用文本爬虫来进行话题提取了。这里将介绍如何使用基于Python语言的jieba库、sklearn库的TfidfVectorizer矢量化工具和LatentDirichletAllocation(LDA)模型来实现一个爬虫程序,先把目标网页上的正文内容爬取下来并保存为本地txt文件,再通过潜在狄利克雷分布对保存到本地的文本内容进行话题提取。
首先,仍然需要指定本机的user agent,通过Requests库的get( )函数向目标网页发出访问浏览请求,这里以浏览中华人民共和国中央人民政府官网中的最新政策《国务院关于加快建立健全绿色低碳循环发展经济体系的指导意见》为例,其地址为:http://www.gov.cn/zhengce/content/2021-02/22/content_5588274.htm ,再使用 BeautifulSoup库和lxml库来共同解析爬取下来的HTML文件并将解析出的正文内容输出到本地txt文件进行保存。然后,使用jieba库的结巴分词对保存在本地的文本进行分词处理并将分词处理后的文本内容另存为一个新的txt文件。最后,利用sklearn库的TfidfVectorizer矢量化工具将分词处理后的新文本数据转化为向量作为训练数据,并通过sklearn库的LatentDirichletAllocation模型对转化为向量的训练数据进行话题提取以及定义一个函数用来打印话题提取后的高频词。整个过程的核心代码如下:

图67 文本爬虫进行话题提取的核心代码
运行图67所示的代码,打开文件保存的目录,会得到两个txt文件,其中,一个名为content的txt文件用来保存爬取的正文内容,其部分内容如图68所示,一个名为cutcontent的txt文件用来保存分词处理后的正文内容,其部分内容如图69所示;此外,LDA模型按照我们的意愿,从在中华人民共和国中央人民政府官网爬取的《国务院关于加快建立健全绿色低碳循环发展经济体系的指导意见》一文中提取了一个话题,并且把这个话题中共同出现频率最高的30个词语提取出来了,如图70所示,从图中可以看出,在这个提取出的话题中,共同出现频率最高的词语包括"绿色"、"发展"、"体系 "、"建设 "、"推进 "、"加快 "、"推动 "、"加强 "、"利用 "、"产业 "、"清洁 "、"能源 "、"提升 "、"企业 "、"鼓励 "、"建立"、"碳循环"、"产品 "、"制度 "、"生产 "、"生活"、"标准 "、"环保 "、"循环 "、"完善 "、"开展 "、"资源 "、"水平 "、"支持 "、"积极" ,那么我们一眼就可以看出这是一条关于健全绿色发展经济体系的政策。因此,我们实现了对爬虫收集到的文本数据进行快速聚类分析,而无需全文详细阅读才能辨别分类的功能。
图68 名为content的txt文件的部分内容
图69 名为cutcontent的txt文件的部分内容
![]()
图70 文本爬虫进行话题提取的结果图
以上内容就是对无监督学习中样本数据预处理、样本数据特征转换和聚类分析算法的原理、用法和核心代码的详细讲述以及对两个应用于现实生活中的机器学习算法实例的描述,这两个实例分别实现了用训练好的管道模型预测中国A股市场自2021年2月21日收盘之后的股价涨幅走势的功能以及实现了对目标网页进行数据爬虫并保存为本地文件来进行话题提取的功能。
欢迎喜欢编程语言知识和机器学习算法等科技类文章,以及经济和历史等文史类文章的朋友们关注公众号:CodingFarmer2019,我们一起格物致知和学史悟道,实现人生辉煌!