前言
现代的前端开发,不再是刀耕火种的 JQ 时代,而是 MVVM ,组件化,工程化,承载着日益复杂的业务逻辑。内存消耗和性能问题,成为当代开发者必须要考虑的问题。
本文从堆栈内存讲起,让大家理解JS中变量的内存使用以及变动情况 。
初步了解堆栈
先初步了解JS中的堆和栈,内存空间分为 堆和栈 两个区域,代码运行时,解析器会先判断变量类型,根据变量类型,将变量放到不同的内存空间中(堆和栈)。
如图所示
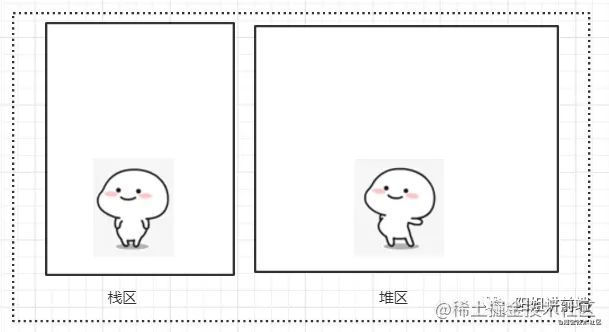
堆栈和类型的关系
基本的数据类型(String,Number,Boolean,Null,Undefined, Symbol)都会分配栈区。它的值是存放在栈中的简单数据段,数据大小确定,内存空间大小可以分配;按值存放,所以可以按值访问。
引用数据类型 Object (对象)的变量都放到堆区。它在栈内存中保存的实际上是对象在堆内存中的引用地址, 通过这个引用地址可以快速查找到保存在堆内存中的对象。存放在堆内存中的对象,每个空间大小不一样,要根据情况进行特定的配置。
如下代码示例:
var a = 12;
var b = false;
var c = 'string'
var obj = { name: 'sunshine' }
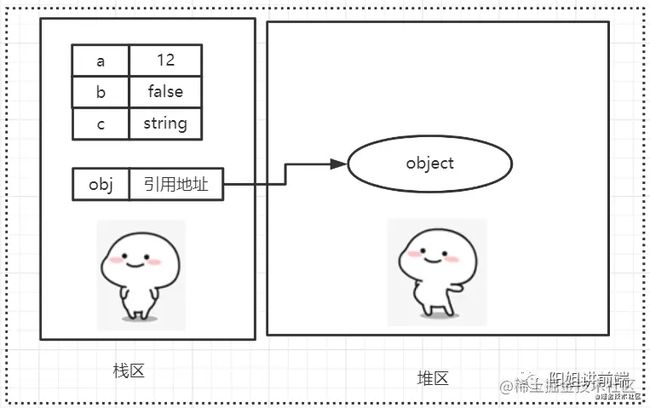
特点
栈区的特点:空间小,数据类型简单,读写速度快,一般由JS引擎自动释放
堆区的特点:空间大,数据类型复杂,读写速度稍逊,当对象不在被引用时,才会被周期性的回收。
了解了内存的栈区和堆区后, 接下来,来看看变量如何在栈区和堆区“愉快的玩耍”。
变量赋值
下面来看一组基本类型的变量传递的例子:
let a = 100 let b = a a = 200 console.log(b) // 100
初始栈中 a 的值为100;其次栈区中添加 b,并且将a复制了一份给b;最后 a保存了另外一个值 200,而b的值不会改变。
再来看一组引用类型传递的例子:
let obj1 = { name: 'a' }
let obj2 = obj1
obj2.name = 'b'
console.log(obj1.name) // b
以上代码中,obj1 和 obj2 指向了同一个堆内存,obj1 赋值给 obj2,实际上这个堆内存对象在栈内存的引用地址复制了一份给了 obj2,所以 obj1 和 obj2 指针都指向堆内存中的同一个。
图解如下:
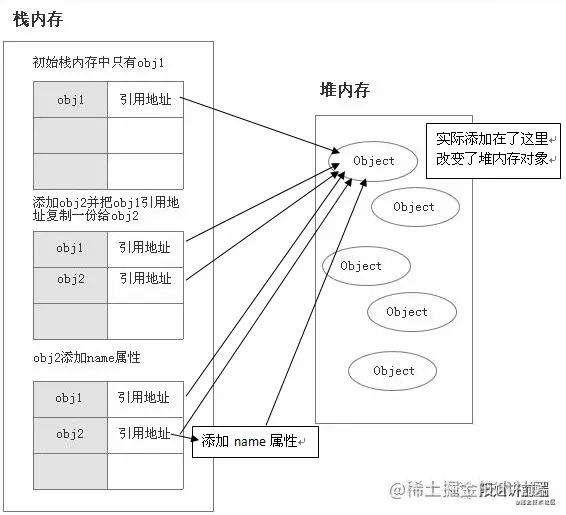
综合案例:
var a = [1, 2, 3, 4] var c = a[0] // 这时变量c是基本数据类型,存储在栈内存中;改变栈中的数据不会影响堆中的数据 c = 5 console.log(c) // 5 console.log(a[0]) // 1 let b = a // b是引用数据类型,栈内存指针和 a一样都指向同一个堆内存,改变数值后,会影响堆中的数据 b[2] = 6 console.log(a[2]) // 6
划重点:在JS的变量传递中,本质上都可以看成是值传递,只是这个值可能是基础数据类型,也可能是一个引用地址,如果是引用地址,我们通常就说为引用传递。JS中比较特殊,不能直接操作对象的内存空间,必须通过指针(所谓的引用)来访问。
所以,即使是所有复杂数据类型(对象)的赋值操作,本质上也是值传递。在往下看一下不同的值在参数中是如何传递的。
参数传递
由上可知,ECMAScript中所有函数的参数都是按值传递的。这意味着函数外的值会被复制到函数内部的参数中,就像从一个变量赋值到另一个变量一样。在按值传递参数时,值会被复制到一个局部变量(arguments对象中的一个槽位)。在按引用传递参数时,值在内存中的位置会被保存在一个局部变量,这意味着对本地变量的修改会反映到函数外部。
下面看一个例子:在 bar 函数中,当参数为基本数据类型时,函数体内会赋值一份参数值,而不会影响原参数的实际值。
let foo = 1
const bar = value => {
// var value = foo
value = 2
console.log(value)
}
bar(foo) // 2
console.log(foo) // 1
如果将函数参改为引用类型,结果就不一样了:
let foo = { bar: 1}
const func = obj => {
// var obj = foo
obj.bar = 2
console.log(obj.bar)
}
func(foo) // 2
console.log(foo.bar) // 2
从以上代码中可以看出,如果函数参数是一个引用类型的数据,那么当在函数体内修改这个引用类型参数的某个属性时,也将对原来的参数进行修改,因为此时函数体内的引用地址指向了原来的参数。
但是,如果在函数体内直接修改对参数的引用,则情况又会不一样:
let foo = { bar: 1}
const func = obj => {
// var obj = 2
obj = 2
console.log(obj)
}
func(foo) // 2
console.log(foo) // { bar: 1 }
这是因为如果我们将一个已经赋值的变量重新赋值,那么它将包含新的数据或引用地址。这时函数体内新创建了一个引用,任何操作都不会影响原参数的实际值。
如果一个对象没有被任何变量指向,JavaScript引擎的垃圾回收机制会将该对象销毁并释放内存。
小结
- 函数参数为基本数据类型时,函数体内赋值了一份参数值,任何操作都不会影响原参数的实际值
- 函数参数是引用类型时,当函数体内修改这个值的某个属性时,将会对原来的参数进行修改
- 函数参数是引用类型时,如果直接修改这个值的引用地址,则相当于在函数体内新创建了一个新的引用,任何操作都不会影响原参数的实际值。
面试题
- 参数多次赋值问题
function func (person) {
person.age = 25
person = {
age: 50
}
return person
}
var person1 = {
age: 30
}
var person2 = func(person1);
console.log(person1)
console.log(person2)
答案:{ age: 25 },{ age: 50 }。因为函数内部,person 第一次修改,相当于 复制了 person1 的内存地址给person,第二次修改是创建一个新的 person 变量。所以 person1 在堆内存中的值会被修改,person 也是新的 person 变量返回的值
- 变量干扰问题
let obj1 = { x: 100, y: 200}
let obj2 = obj1
let x1 = obj1.x
obj2.x = 101
x1 = 102
console.log(obj1)
答案:{ x: 101, y: 200 },x1是干扰项,因为obj.x是原始类型值,所以修改后不会影响原数据的引用地址。
两者的区别就是:
举个例子:
值传递:A觉得B的房子装修风格很好,于是借用了B的装修风格。但是过了段时间A给房子里面又添加了点别的风格,但是B的房子风格还是原来的。
引用传递:A喜欢B的房子风格,借用了人家的风格,过了段时间A给家里添加了新的风格,但是A觉得自己的风格比B的好,于是通过B给A的地址,去B的家硬是把人家的风格改成和自己一样的了。
总结
到此这篇关于JS中"值传递"和"引用传递"的文章就介绍到这了,更多相关JS 值传递和引用传递内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!