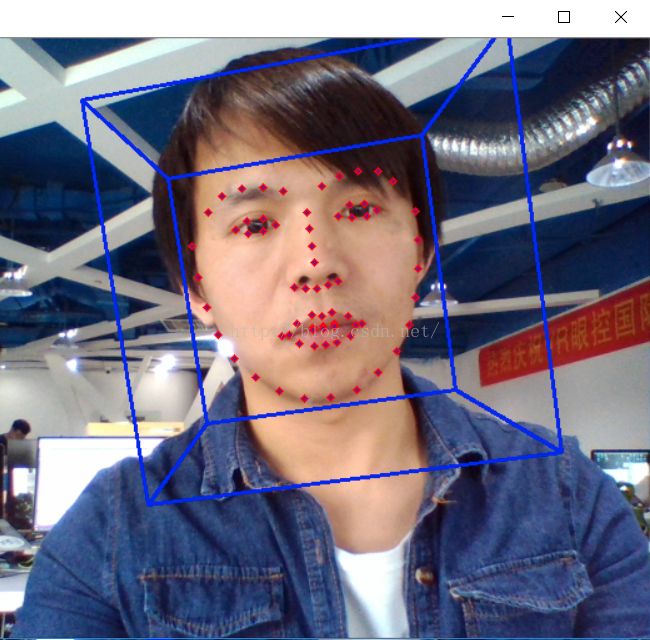
人脸识别之人脸关键点
深度学习人脸关键点检测方法----综述
转自人脸关键点检测综述
不知道为什么在ubuntu下知呼中的图片无法显示
人脸关键点检测是人脸识别和分析领域中的关键一步,它是诸如自动人脸识别、表情分析、三维人脸重建及三维动画等其它人脸相关问题的前提和突破口。因此,本文针对深度学习方法进行了人脸关键点检测的研究。

一、人脸关键点数据集
传统人脸关键点检测数据库为室内环境下采集的数据库,比如 Multi-pie、Feret、Frgc、AR、BioID 等人脸数据库。而现阶段人脸关键点检测数据库通常为复杂环境下采集的数据库.LFPW 人脸数据库有 1132 幅训练人脸图像和 300 幅测试人脸图像,大部分为正面人脸图像,每个人脸标定 29 个关键点。AFLW 人脸数据库包含 25993 幅从 Flickr 采集的人脸图像,每个人脸标定 21 个关键点。COFW 人脸数据库包含 LFPW 人脸数据库训练集中的 845 幅人脸图像以及其他 500 幅遮挡人脸图像,而测试集为 507 幅严重遮挡(同时包含姿态和表情的变化)的人脸图像,每个人脸标定 29 个关键点。MVFW 人脸数据库为多视角人脸数据集,包括 2050 幅训练人脸图像和 450 幅测试人脸图像,每个人脸标定 68 个关键点。OCFW 人脸数据库包含 2951 幅训练人脸图像(均为未遮挡人脸)和 1246 幅测试人脸图像(均为遮挡人脸),每个人脸标定 68 个关键点。

1.1 传统方法
1.1.1 ASM(Active Shape Model)
An Introduction to Active Shape Models
人脸Pose检测:ASM、AAM、CLM总结 - wishchin - 博客园 (详细说明)
ASM(Active Shape Model)算法介绍
ASM(Active Shape Model)主动形状模型通俗易懂讲解一:理论
搜索ASM有很多。
ASM(Active Shape Model) 是由 Cootes 于 1995 年提出的经典的人脸关键点检测算法,主动形状模型即通过形状模型对目标物体进行抽象,ASM 是一种基于点分布模型(Point Distribution Model, PDM)的算法。在 PDM 中,外形相似的物体,例如人脸、人手、心脏、肺部等的几何形状可以通过若干关键点(landmarks)的坐标依次串联形成一个形状向量来表示。ASM 算法需要通过人工标定的方法先标定训练集,经过训练获得形状模型,再通过关键点的匹配实现特定物体的匹配。
ASM 主要分为两步:
第一步:训练。
首先,构建形状模型:
- 搜集 n 个训练样本(n=400);
- 手动标记脸部关键点(68个);
- 将训练集中关键点的坐标串成特征向量;
- 对形状进行归一化和对齐(对齐采用 Procrustes 方法);
- 对对齐后的形状特征做 PCA 处理。
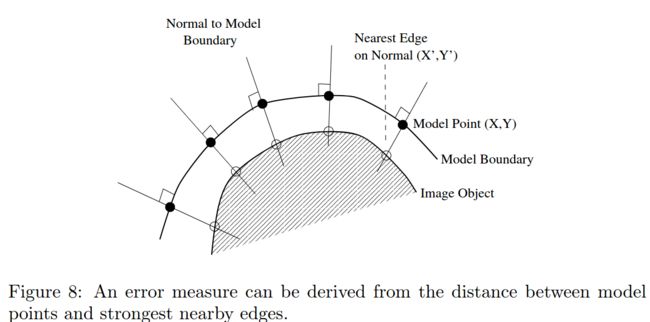
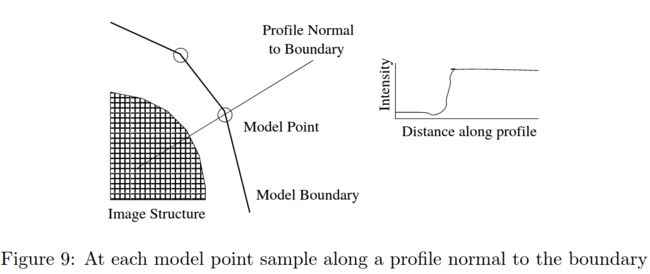
接着,为每个关键点构建局部特征。目的是在每次迭代搜索过程中每个关键点可以寻找新的位置。局部特征一般用梯度特征,以防光照变化。有的方法沿着边缘的法线方向提取,有的方法在关键点附近的矩形区域提取。
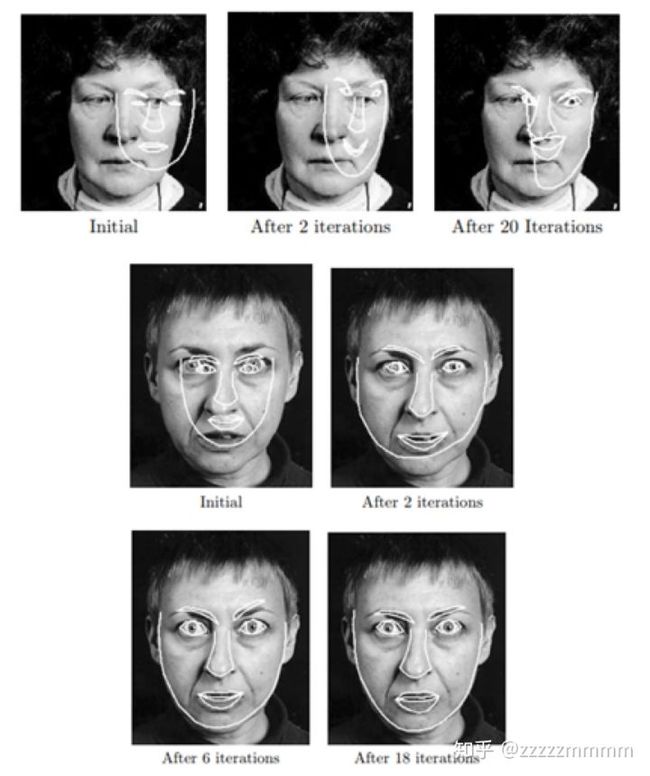
第二步:搜索。
首先:计算眼睛(或者眼睛和嘴巴)的位置,做简单的尺度和旋转变化,对齐人脸;
接着,在对齐后的各个点附近搜索,匹配每个局部关键点(常采用马氏距离),得到初步形状;
再用平均人脸(形状模型)修正匹配结果;迭代直到收敛。
ASM 算法的优点在于模型简单直接,架构清晰明确,易于理解和应用,而且对轮廓形状有着较强的约束,但是其近似于穷举搜索的关键点定位方式在一定程度上限制了其运算效率。
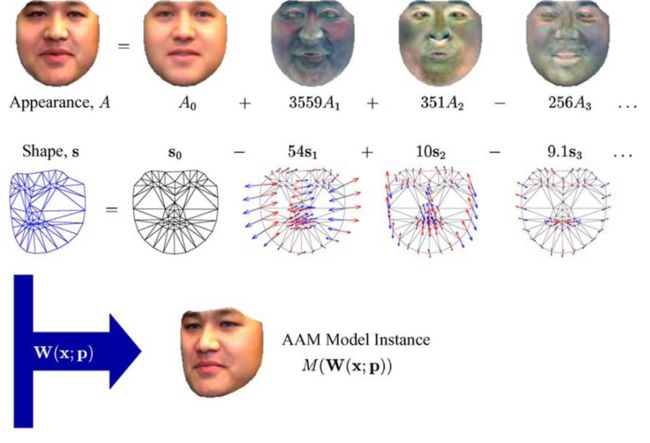
1.1.2 Active Appearance Models
主动外观模型(AAM) - OpenCV China
AAM(Active Appearance Model)算法介绍
AAM算法简介
1998 年,Cootes 对 ASM 进行改进,不仅采用形状约束,而且又加入整个脸部区域的纹理特征,提出了 AAM 算法。AAM 于 ASM 一样,主要分为两个阶段,模型建立阶段和模型匹配阶段。其中模型建立阶段包括对训练样本分别建立形状模型 (Shape Model) 和纹理模型 (Texture Model),然后将两个模型进行结合,形成 AAM 模型。
1.1.3 Cascaded pose regression
Cascaded pose regression 介绍说明
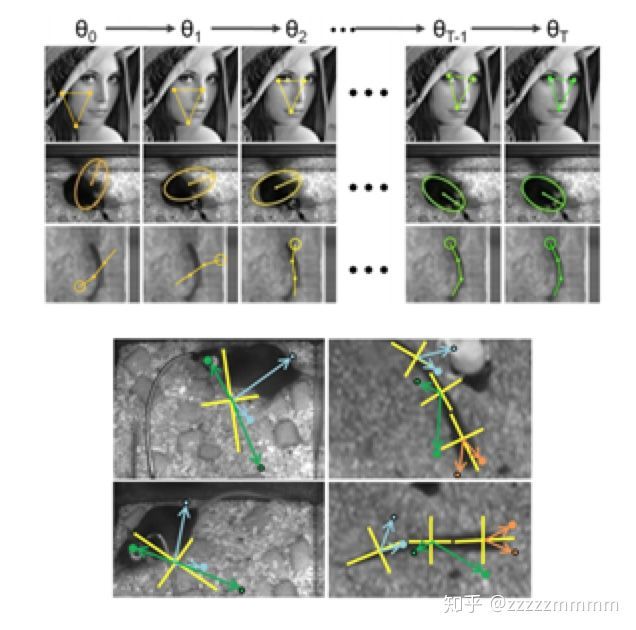
2010 年,Dollar 提出 CPR(Cascaded Pose Regression, 级联姿势回归),CPR 通过一系列回归器将一个指定的初始预测值逐步细化,每一个回归器都依靠前一个回归器的输出来执行简单的图像操作,整个系统可自动的从训练样本中学习。
所谓的线性回归,其实就是一个不断迭代的过程,对于每一个stage中,用上一个stage的状态作为输入来更新,产生下一个stage的输入,以此类推,直到达到最底层stage。
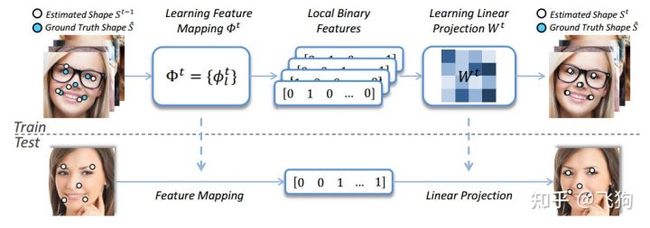
训练过程中,先初始化一个shape ,用一种特征映射方法Φt生成局部二值特征。根据特征和目标shape的增量生成最终shape。权值通过线性回归进行更新。在测试阶段,直接预测形状增量,并应用于更新当前估计的形状。形状增量:
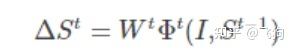
如上公式所示,I为输入图像,St-1为第t-1 stage的形状,Φt为t stage的特征匹配函数,W为线性回归矩阵。
人脸关键点检测的目的是估计向量,其中 K 表示关键点的个数,由于每个关键点有横纵两个坐标,所以 S 的长度为 2K。CPR 检测流程如图所示,一共有 T 个阶段,在每个阶段中首先进行特征提取,得到ft, 这里使用的是 shape-indexed features,也可以使用诸如 HOG、SIFT 等人工设计的特征,或者其他可学习特征(learning based features),然后通过训练得到的回归器 R 来估计增量ΔS( update vector),把ΔS 加到前一个阶段的 S 上得到新的 S,这样通过不断的迭代即可以得到最终的 S(shape)。
1.1.4 人脸关键点定位3000fps的LBF方法
人脸识别经典算法二:LBP方法
人脸检测(七)--LBP特征原理及实现
人脸对齐(八)--LBF算法_Eason.wxd的博客-CSDN博客_lbf算法
计算机视觉基础-图像处理: LBP特征描述算子 - 知乎
LBP特征及其一些变种
基于LBP纹理特征计算GLCM的纹理特征统计量+SVM/RF识别纹理图片
基于LBF方法的人脸对齐,出自Face Alignment at3000 FPS via Regressing Local Binary Features,由于该方法提取的是局部二值特征(LBF),论文作者的LBF fast达到了3000fps的速度,网上热心网友分享的程序也达到了近300fps的速度,绝对是人脸对齐方面速度最快的一种算法。因此,好多网友也将该方法称为,3000fps。
该算法的核心工作主要有两部分,总体上采用了随机森林和全局线性回归相结合的方法,相对于使用卷积神经的深度学习方法,LBF采用的算法是传统的机器学习方法。
1、LBF特征的提取
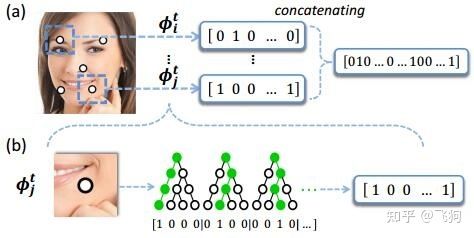
LBF算法,将随机森林的输出组成一种特征(这里也就是LBF),并用LBF来做预测,除了采用随机森林的结构做预测,LBF还针对每个关键点给出一个随机森林来做预测,并将所有关键点对应的随机森林输出的局部特征相互联系起来,称作为局部二值特征,然后利用这个局部二值特征做全局回归,来预测形状变化量。
在特征点附近,随机选择点做残差来学习LBF特征,每一个特征点都会学到由好多随机树组成的随机森林,因此,一个特征点就得用一个随机森林生成的0,1特征向量来表示,将所有的特征点的随机森林都连接到一起,生成一个全局特征,后续过程就可以使用该全局特征做全局线性回归了
其中
![]()
表示在第t次级联回归中,第j个特征点所对应的随机森林,所有的关键点的随机森林一起组成了,它的输出为LBF特征。然后利用LBF特征来训练全局线性回归或者预测形状变化量。
上图描述生成局部二值特征LBF的过程,图的下半部分描述了单个关键点上随机森林输出了一个局部二值特征,然后把所有随机森林的输出前后连接起来组成一个非常大但又十分稀疏的LBF特征。第一颗树遍历后来到了最左边的叶子节点所以记为[1,0,0,0],对于第一课树访问到的叶子节点记为1,其他的记为0,把所有的结果串联起来就是=[1,0,0,0,0,1,0,0,0,0,1,0.....],其中这个特征只有0,1组成,且大部分是0,特征非常的稀疏。真正的局部 二值特征就是将所有的landmark的特征串联起来,即是
![]()
2、形状索引特征(shape-indexed)
每一个关键点对应一个随机森林,而随机森林是由多个独立的随机树组成。论文中的随机树采用的特征是形状索引特征,ESR(CVPR‘12)和RCPR(ICCV'13)也是采用了类似的特征,这个特征主要是描述人脸区域中两个点的像素差值。关于两个像素点的选取,三个方法都使用了不同的策略。
ESR方法采用的是在两个关键点附近随机出两个点,做这两个点之间的差值作为形状索引特征。
RCPR方法采用的选取两个关键点的中点,外加一个随机偏置来生成特征点,用两个这样的特征点的差值作为形状索引特征。
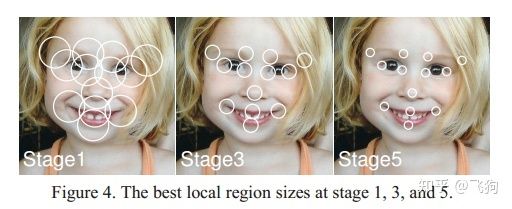
在LBF算法中,由于随机森林是针对单个关键点的,所有随机树使用到的特征点不会关联到其他关键点,3000fps的做法是在当前关键点的附近区域随机产生两个特征点,用这两个点的像素差值来作为形状索引特征。下图是每个特征点的局部区域面积变化,索引面积从大到小逐渐变小,目的是为了获得更加准确的局部索引特征。
3、随机森林训练
在LBF算法中,由于随机森林是针对单个关键点的,所有随机树种使用到的特征点不会关联到其他关键点,只有在当前关键点的附近区域随机产生两个特征点,做像素差值来作为形状索引特征。
计算每一张图片的这两个点处的像素值的像素差,从事先随机生成的形状索引特征集合F中选取一个,作为分裂特征,之后随机产生一个分裂阈值,如果一幅图像的像素差小于这个阈值,就往左分裂,否则往右分裂,将所有图片都这样判断一次,就将所有图片分成了两部分,一部分在左,一部分在右。我们重复上面这个过程若干次,看看哪一次分裂的好(判断是否分裂的好的依据是方差,如果分在左边的样本的方差小,这说明它们是一类,分的就好),就把这个分裂的好的选择保存下来,即保存下这两个点的坐标值和分裂阈值。这样一个节点的分裂就完成了。然后每一个节点的分裂都按照这个步骤进行,直到分裂到叶子节点。
分配的目的是希望左右子树的样本点的Y具有相同的模式。论文实现中,特征选取可以采用如下的方式进行。
信息增益
![]()
上式中f表示选取到的特征函数(即利用随机采样到的特征点计算形状索引特征(这里用的像素差值), Δ表示随机生成的阈值,S用来刻画样本点之间的相似度或者样本集合的熵(论文中,采用的是方差)。针对每一个几点,训练数据(X,Y)被分成两部分,(X1,Y1)和(X2,Y2),我们期望左右字数的样本数据具有相同的模式,论文中采用了方差刻画,所以选择特征函数f时,我们希望方差减小最大。
权值学习:使用的双坐标下降方法,使下公式最小:
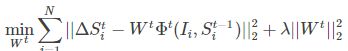
λ是控制Wt长度,即让Wt尽量稀疏。测试的时候,先对一幅图像提取形状索引特征, 然后使用随机森林进行编码,最后使用w估计shape增量。
from:人脸对齐 - ERP 和 LBF
from:LBF特征_zhou894509的专栏-CSDN博客_lbf特征
github上热心网友的程序,
matab版本:jwyang/face-alignment
c++版本:yulequan/face-alignment-in-3000fps
1.2 深度学习方法
1.2.1 Deep Convolutional Network Cascade for Facial Point Detection
2013 年,Sun 等人首次将 CNN 应用到人脸关键点检测,提出一种级联的 CNN(拥有三个层级)——DCNN(Deep Convolutional Network),此种方法属于级联回归方法。作者通过精心设计拥有三个层级的级联卷积神经网络,不仅改善初始不当导致陷入局部最优的问题,而且借助于 CNN 强大的特征提取能力,获得更为精准的关键点检测。
如图所示,DCNN 由三个 Level 构成。Level-1 由 3 个 CNN 组成;Level-2 由 10 个 CNN 组成(每个关键点采用两个 CNN);Level-3 同样由 10 个 CNN 组成。
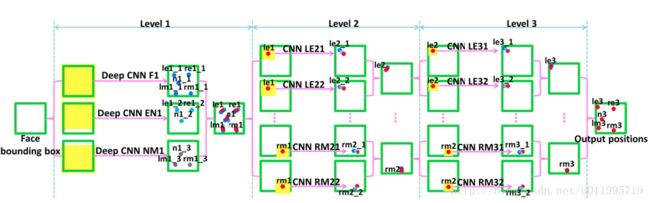
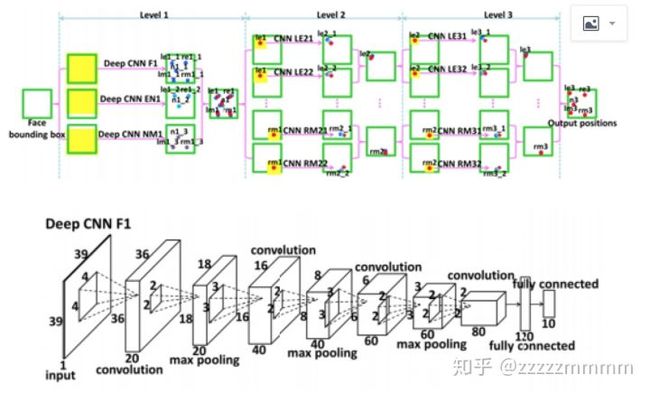
evel-1 分 3 个 CNN,分别是 F1(Face 1)、EN1(Eye,Nose)、NM1(Nose,Mouth);F1 输入尺寸为 39*39,输出 5 个关键点的坐标;EN1 输入尺寸为 39*31,输出是 3 个关键点的坐标;NM11 输入尺寸为 39*31,输出是 3 个关键点。Level-1 的输出是由三个 CNN 输出取平均得到。
Level-2,由 10 个 CNN 构成,输入尺寸均为 15*15,每两个组成一对,一对 CNN 对一个关键点进行预测,预测结果同样是采取平均。Level-3 与 Level-2 一样,由 10 个 CNN 构成,输入尺寸均为 15*15,每两个组成一对。Level-2 和 Level-3 是对 Level-1 得到的粗定位进行微调,得到精细的关键点定位。
Level-1 之所以比 Level-2 和 Level-3 的输入要大,是因为作者认为,由于人脸检测器的原因,边界框的相对位置可能会在大范围内变化,再加上面部姿态的变化,最终导致输入图像的多样性,因此在 Level-1 应该需要有足够大的输入尺寸。Level-1 与 Level-2 和 Level-3 还有一点不同之处在于,Level-1 采用的是局部权值共享(Lcally Sharing Weights),作者认为传统的全局权值共享是考虑到,某一特征可能在图像中任何位置出现,所以采用全局权值共享。然而,对于类似人脸这样具有固定空间结构的图像而言,全局权值共享就不奏效了。因为眼睛就是在上面,鼻子就是在中间,嘴巴就是在下面的。所以作者借鉴文献 [28] 中的思想,采用局部权值共享,作者通过实验证明了局部权值共享给网络带来性能提升。
DCNN 采用级联回归的思想,从粗到精的逐步得到精确的关键点位置,不仅设计了三级级联的卷积神经网络,还引入局部权值共享机制,从而提升网络的定位性能。最终在数据集 BioID 和 LFPW 上均获得当时最优结果。速度方面,采用 3.3GHz 的 CPU,每 0.12 秒检测一张图片的 5 个关键点。

1.2.2 Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade
2013 年,Face++在 DCNN 模型上进行改进,提出从粗到精的人脸关键点检测算法,实现了 68 个人脸关键点的高精度定位。该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计 51 个关键点,轮廓关键点包含 17 个关键点。
针对内部关键点和外部关键点,该算法并行的采用两个级联的 CNN 进行关键点检测,网络结构如图所示。
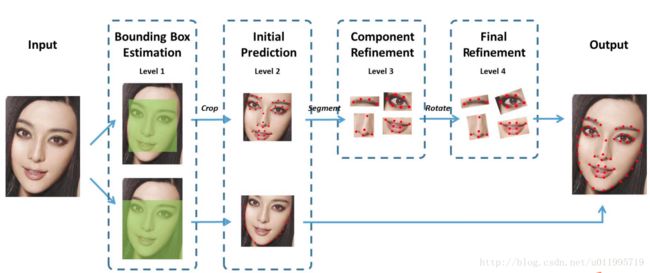 针对内部 51 个关键点,采用四个层级的级联网络进行检测。其中,Level-1 主要作用是获得面部器官的边界框;Level-2 的输出是 51 个关键点预测位置,这里起到一个粗定位作用,目的是为了给 Level-3 进行初始化;Level-3 会依据不同器官进行从粗到精的定位;Level-4 的输入是将 Level-3 的输出进行一定的旋转,最终将 51 个关键点的位置进行输出。针对外部 17 个关键点,仅采用两个层级的级联网络进行检测。Level-1 与内部关键点检测的作用一样,主要是获得轮廓的 bounding box;Level-2 直接预测 17 个关键点,没有从粗到精定位的过程,因为轮廓关键点的区域较大,若加上 Level-3 和 Level-4,会比较耗时间。最终面部 68 个关键点由两个级联 CNN 的输出进行叠加得到。
针对内部 51 个关键点,采用四个层级的级联网络进行检测。其中,Level-1 主要作用是获得面部器官的边界框;Level-2 的输出是 51 个关键点预测位置,这里起到一个粗定位作用,目的是为了给 Level-3 进行初始化;Level-3 会依据不同器官进行从粗到精的定位;Level-4 的输入是将 Level-3 的输出进行一定的旋转,最终将 51 个关键点的位置进行输出。针对外部 17 个关键点,仅采用两个层级的级联网络进行检测。Level-1 与内部关键点检测的作用一样,主要是获得轮廓的 bounding box;Level-2 直接预测 17 个关键点,没有从粗到精定位的过程,因为轮廓关键点的区域较大,若加上 Level-3 和 Level-4,会比较耗时间。最终面部 68 个关键点由两个级联 CNN 的输出进行叠加得到。
算法主要创新点由以下三点:(1)把人脸的关键点定位问题,划分为内部关键点和轮廓关键点分开预测,有效的避免了 loss 不均衡问题;(2)在内部关键点检测部分,并未像 DCNN 那样每个关键点采用两个 CNN 进行预测,而是每个器官采用一个 CNN 进行预测,从而减少计算量;(3)相比于 DCNN,没有直接采用人脸检测器返回的结果作为输入,而是增加一个边界框检测层(Level-1),可以大大提高关键点粗定位网络的精度。
Face++版 DCNN 首次利用卷积神经网络进行 68 个人脸关键点检测,针对以往人脸关键点检测受人脸检测器影响的问题,作者设计 Level-1 卷积神经网络进一步提取人脸边界框,为人脸关键点检测获得更为准确的人脸位置信息,最终在当年 300-W 挑战赛上获得领先成绩。

1.2.3 TCDCN-Facial Landmark Detection by Deep Multi-task Learning
优点是快和多任务,不仅使用简单的端到端的人脸关键点检测方法,而且能够做到去分辨人脸的喜悦、悲伤、愤怒等分类标签属性,这样跟文章的标题或者说是文章的主题贴合——多任务。
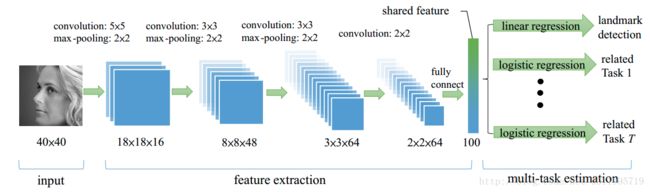 我们可以从下图看到,缺点容易漂移,也就是对于人脸关键点的检测上面,并不能做到很好的精度或者很高的精度,因此有待进一步修改网络的雏形。另外一点是对于人脸关键点的检测上,检测关键点小,如果增加其人脸关键点的检测,或降低精度,这是神经网络模型的通病。
我们可以从下图看到,缺点容易漂移,也就是对于人脸关键点的检测上面,并不能做到很好的精度或者很高的精度,因此有待进一步修改网络的雏形。另外一点是对于人脸关键点的检测上,检测关键点小,如果增加其人脸关键点的检测,或降低精度,这是神经网络模型的通病。

1.2.4 Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
2016 年,Zhang 等人提出一种多任务级联卷积神经网络(MTCNN, Multi-task Cascaded Convolutional Networks)[9] 用以同时处理人脸检测和人脸关键点定位问题。作者认为人脸检测和人脸关键点检测两个任务之间往往存在着潜在的联系,然而大多数方法都未将两个任务有效的结合起来,本文为了充分利用两任务之间潜在的联系,提出一种多任务级联的人脸检测框架,将人脸检测和人脸关键点检测同时进行。
MTCNN 包含三个级联的多任务卷积神经网络,分别是 Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。网络结构如图所示:


MTCNN 实现人脸检测和关键点定位分为三个阶段。首先由 P-Net 获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。然后将 P-Net 得出的候选框作为输入,输入到 R-Net,R-Net 同样通过边界框回归和 NMS 来去掉那些 false-positive 区域,得到更为准确的候选框;最后,利用 O-Net 输出 5 个关键点的位置。
为了提升网络性能,需要挑选出困难样本(Hard Sample),传统方法是通过研究训练好的模型进行挑选,而本文提出一种能在训练过程中进行挑选困难的在线挑选方法。方法为,在 mini-batch 中,对每个样本的损失进行排序,挑选前 70% 较大的损失对应的样本作为困难样本,同时在反向传播时,忽略那 30% 的样本,因为那 30% 样本对更新作用不大。
实验结果表明,MTCNN 在人脸检测数据集 FDDB 和 WIDER FACE 以及人脸关键点定位数据集 LFPW 均获得当时最佳成绩。在运行时间方面,采用 2.60GHz 的 CPU 可以达到 16fps,采用 Nvidia Titan Black 可达 99fps。
1.2.5 TCNN(Tweaked Convolutional Neural Networks)
2016 年,Wu 等人研究了 CNN 在人脸关键点定位任务中到底学习到的是什么样的特征,在采用 GMM(Gaussian Mixture Model, 混合高斯模型)对不同层的特征进行聚类分析,发现网络进行的是层次的,由粗到精的特征定位,越深层提取到的特征越能反应出人脸关键点的位置。针对这一发现,提出了 TCNN(Tweaked Convolutional Neural Networks)[8],其网络结构如图所示
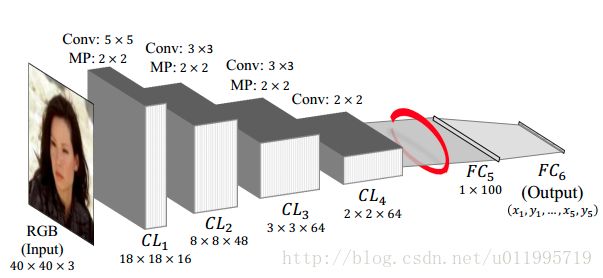
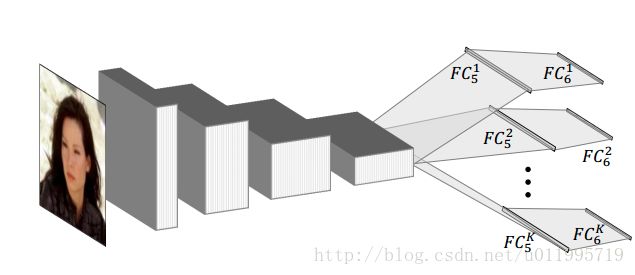
上图为 Vanilla CNN,针对 FC5 得到的特征进行 K 个类别聚类,将训练图像按照所分类别进行划分,用以训练所对应的 FC6K。测试时,图片首先经过 Vanilla CNN 提取特征,即 FC5 的输出。将 FC5 输出的特征与 K 个聚类中心进行比较,将 FC5 输出的特征划分至相应的类别中,然后选择与之相应的 FC6 进行连接,最终得到输出。
作者通过对 Vanilla CNN 中间层特征聚类分析得出的结论是什么呢?又是如何通过中间层聚类分析得出灵感从而设计 TCNN 呢?
作者对 Vanilla CNN 中间各层特征进行聚类分析,并统计出关键点在各层之间的变化程度。越深层提取到的特征越紧密,因此越深层提取到的特征越能反应出人脸关键点的位置。作者在采用 K=64 时,对所划分簇的样本进行平均后绘图如下


从图上可发现,每一个簇的样本反应了头部的某种姿态,甚至出现了表情和性别的差异。因此可推知,人脸关键点的位置常常和人脸的属性相关联。因此为了得到更准确的关键点定位,作者使用具有相似特征的图片训练对应的回归器,最终在人脸关键点检测数据集 AFLW,AFW 和 300W 上均获得当时最佳效果。

1.2.6 DAN(Deep Alignment Networks)
2017 年,Kowalski 等人提出一种新的级联深度神经网络——DAN(Deep Alignment Network)[10],以往级联神经网络输入的是图像的某一部分,与以往不同,DAN 各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN 可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以 DAN 能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的主要创新点。DAN 基本框架如图所示:
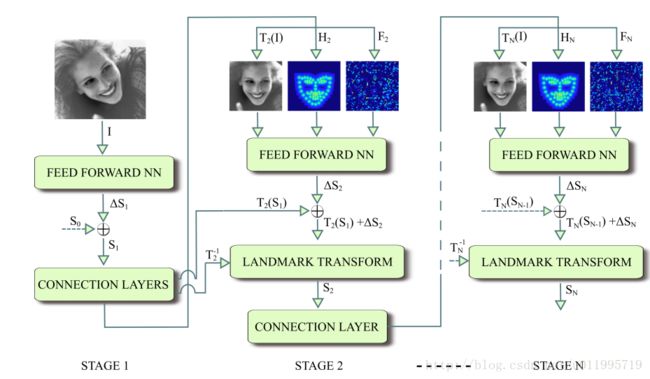 DAN 包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(Face Shape)。其中,CONNECTION LAYER 的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示:
DAN 包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(Face Shape)。其中,CONNECTION LAYER 的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示:
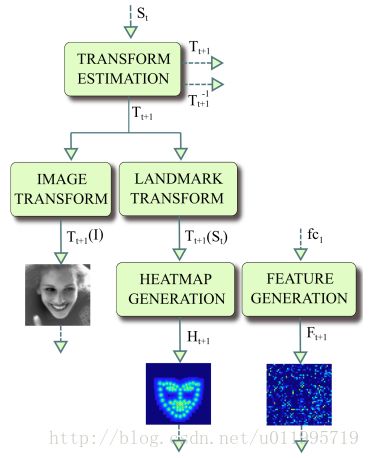
从第一阶段开始讲起,第一阶段的输入仅有原始图片和 S0。面部关键点的初始化即为 S0,S0 是由所有关键点取平均得到,第一阶段输出 S1。对于第二阶段,首先,S1 经第一阶段的 CONNECTION LAYERS 进行转换,分别得到转换后图片 T2(I)、S1 所对应的热图 H2 和第一阶段 fc1 层输出,这三个正是第二阶段的输入。如此周而复始,直到最后一个阶段输出 SN。文中给出在数据集 IBUG 上,经过第一阶段后的 T2(I)、T2(S1)和特征图,如图所示:
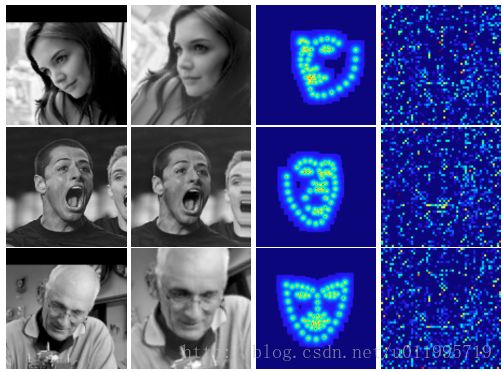
从图中发现,DAN 要做的「变换」,就是把图片给矫正了,第一行数据尤为明显,那么 DAN 对姿态变换具有很好的适应能力,或许就得益于这个「变换」。至于 DAN 采用何种「变换」,需要到代码中具体探究。
接下来看一看,St 是如何由 St-1 以及该阶段 CNN 得到,先看 St 计算公式:
其中是由 CNN 输出的,各阶段 CNN 网络结构如图所示:
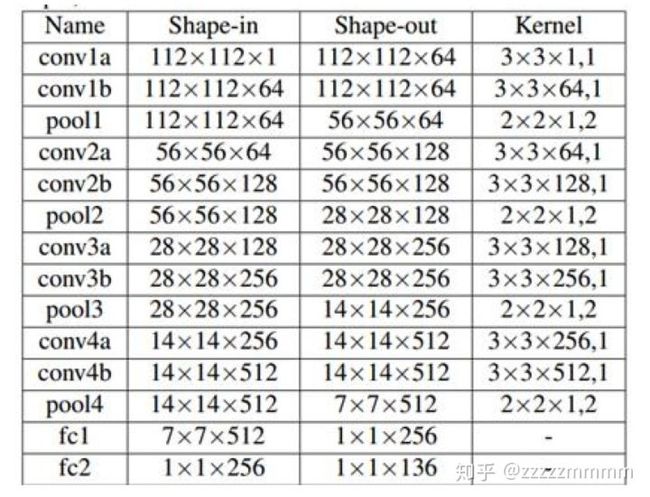
该 CNN 的输入均是经过了「变换」——的操作,因此得到的偏移量是在新特征空间下的偏移量,在经过偏移之后应经过一个反变换还原到原始空间。而这里提到的新特征空间,或许是将图像进行了「矫正」,使得网络更好的处理图像。
关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,公式如下:
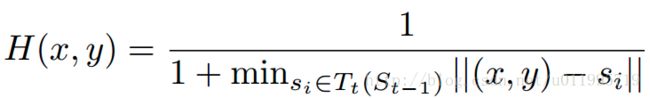
总而言之,DAN 是一个级联思想的关键点检测方法,通过引入关键点热图作为补充,DAN 可以从整张图片进行提取特征,从而获得更为精确的定位。

1.2.7 Robust Facial Landmark Detection via a Fully-Convolutional Local-Global Context Network
网络的设计思路特别,非常特别。下面在CVPR中的一篇论文Look at Boundary: A Boundary-Aware Face Alignment Algorithm具有相同的思路,都是利用heatmap作为引导进行神经网络的监督信号进行引导。不过这里需要preprocess进行热图的产生,即根据标记的数据和高斯模型产生heatmap,然后利用heatmap作为引导进行卷积神经网络的监督学习去逼近人脸关键点。

问题是根据产生的人脸关键点是无差的,只是根据函数的映射关系找到相对应的标记点,缺点是人脸关键点之间并不具有可区别性,也就是不知道哪里是眼睛,哪里是嘴巴,哪里是轮廓,与分层(或者说是级联)的神经网络具有本质性的差异。虽然说设计思路或者概念具有本质性的差异,但是并不妨碍这种方法具有很高的精度。

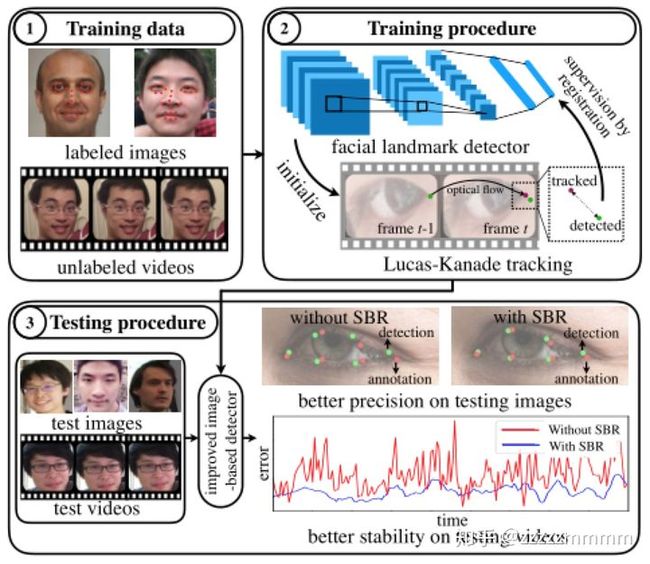
1.2.8 Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
这篇文章一开始看标题觉得非常有意思,通过非监督学习去提升人脸检测关键点的精确率,非监督学习?just kidding?后来细看了一下,确实有意思的是使用CNN模型去检测人脸关键点位置,然后使用光流(flow tracking)跟踪视频流的下一帧图片人脸关键点位置作为融合信息给CNN检测器去作为人脸关键点的辅助信息。
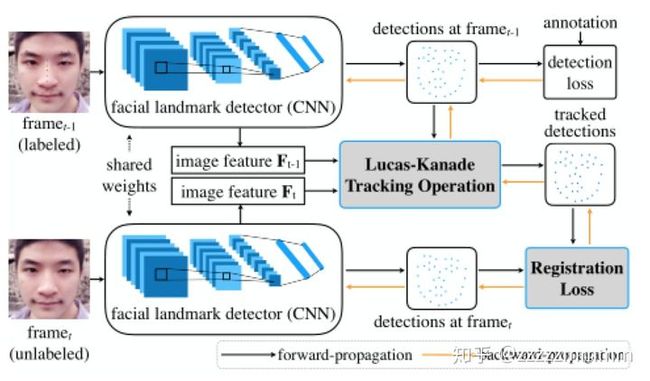
最后对于连续视频帧的检测效果如下所示:

1.2.9 2018 最新研究
ICCV在下一次举行时间为19年,上一次举行时间为17年,因此不太具有参考性。CVPR在2018年刚举行完毕,因此参考CVPR大量的文献,其中关于人脸的有56篇,32篇与2D人脸图像相关,其中与人脸关键点检测相关的只有6篇。因此在这里做简单的文献阅读综述。
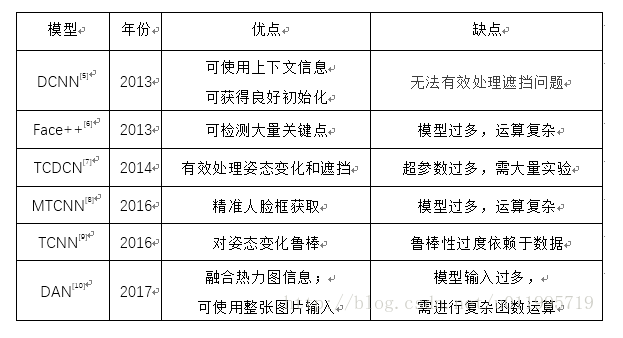
CVPR: Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy
参考FCN和SSD网络模型,利用多层FCN特征层对大小不一的人脸进行检测,并且添加有SSCU算法层(基本原理是基于NMS非极大值抑制算法)作为FCN人脸热图判断,然后利用不同层检测的结果进行合并,对于背景中小人脸有较好的检测效果。文中并没有给出时间效率,并且SAP层的实现具有一定难度。
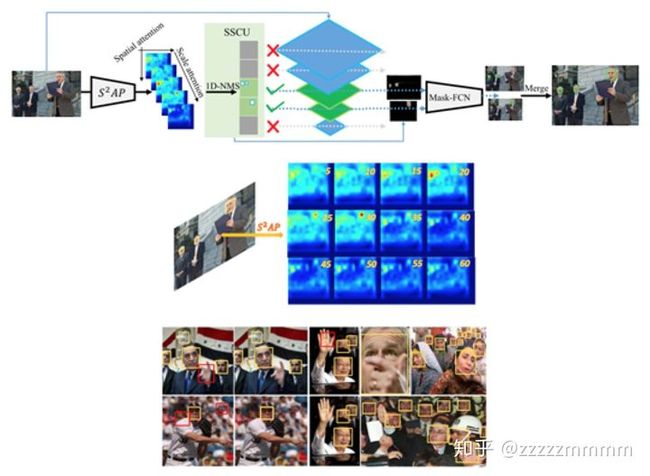
CVPR:Direct Shape Regression Networks for End-to-End Face Alignment
使用Doubly convolutional neural networks提出的卷积层进行卷积,然后将得到的特征图经过该论文提出的傅里叶池化层,损失函数使用normalized mean error。对比TCDCN精度有所提高,但是并没有给出时间效率。特点是简单易懂,实现成本客观。

Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
旋转人脸检测,利用自定义的PCN网络模型,每一次检测旋转角度、boundingbox、分类得分进行判断,通过级联的方式对boundingbox和分类进行过滤,旋转角度作为下一层的输入信息进行累加,从粗到精的一个过程,该文章之前已经见过一次在neurcomputting2017上发表的。


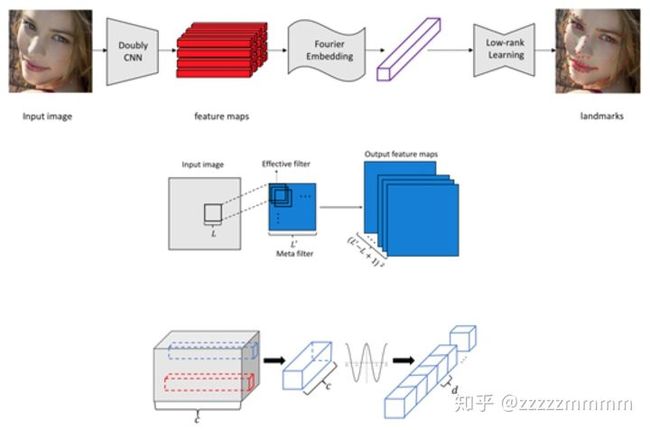
CVPR:Look at Boundary: A Boundary-Aware Face Alignment Algorithm
直接对关键点进行预测会存在过拟合问题,特别是对一些具有具有扭曲表情,夸张表情,遮挡表情的人脸关键点检测使用现有的算法是非常不准确的。为了更好地解决这个问题,这篇文章提出了使用boundary边界的检测方法融合人脸关键点检测方法,使得人脸关键点检测更加精准(特殊情况下),在论文实验部分给出的精确度进步并不是很大。
对于网络模型是把人脸关键点转换成为连接的人脸边界,然后网络同时训练关键点和人脸边界(注意是有顺序的),然后把人脸边界获得Heatmaps信息往下传递给人脸关键点检测作为FMF层融合参考信息,最终使得人脸关键点被控制在人脸边界heatmap上,从原理上可以看出对于关键点漂移的情况会减少,更好地拟合人间关键点。
CVPR:A Prior-Less Method for Multi-Face Tracking in Unconstrained Videos
为了解决在视频流中人脸变化复杂,黑暗情况变化差异大的问题,文章并没有直接使用一个大统一的模型去解决这个问题,而是结合三个模块分别使用不同的数学模型去检测人脸。对于第一阶段使用一个Co-occurentce model对人体姿态和人脸进行估计,因为人体基本姿态和人脸是相互作用的关系,特别是对于连续帧来说,因此使用Co-occurentce模型作为第一阶段;第二阶段使用VGG特征作为强关联信息进行聚类提取人脸特征出来;最后阶段使用高斯处理模型对深度特征进行补充和提取精细化的结果。因为设计到的数学理论和模型较多,因此如果想要细节理解需要阅读原论文。

Disentangling 3D Pose in A Dendritic CNNfor Unconstrained 2D Face Alignment
提出一个Pose Conditioned Dendritic Convolution Neu-ral Network (PCD-CNN)网络。这个网络从原理来看效果不会太好,会存在漂移问题,因为根据heatmap会存在较粗的定位,但是最后(b)阶段引入了Proposed dendritic structure进行弥补,可是这种弥补方式是根据数学公式进行结构特征点计算的方式能否真正地减少误差读者抱着一定的疑惑,如果是基于检索的方式或者搜图的方式可能会效果更好。

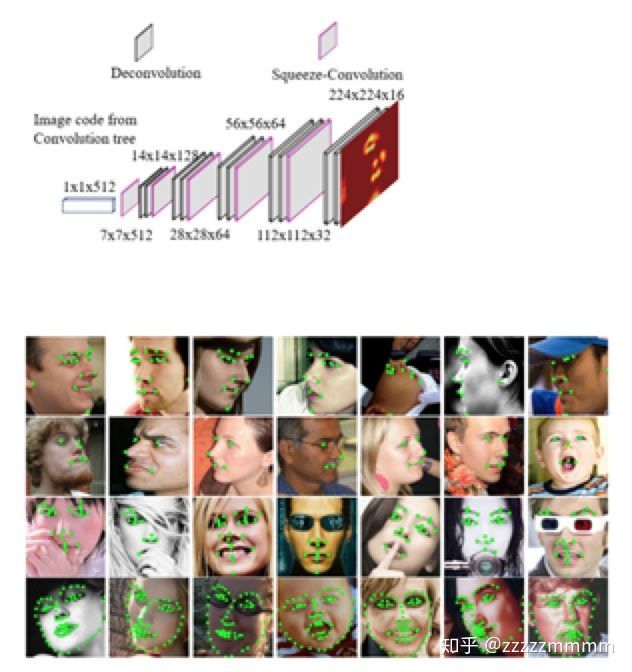
Style Aggregated Network for Facial Landmark Detection
这篇文章主要聚焦在对于不同style的图像中,人脸关键点的检测效果是不一样的,为了更好地统一检测效果或者说为了更好地更精确的提高检测效果,因此可以对样本进行一个风格聚合网络Style Aggregated Network,通过该网络模型可以产生各种不同风格的图片,然后利用这些图片融合信息一起送入CNN网络中进行检测。如下图所示,根据上面的描述,这里使用到了两个网络模型,一个是GAN网络模型,一个是CNN网络模型。

上面的style-aggregated face generation module就是使用GAN模型,具体下面的图会给出更加详细的解析。下面的facial landmark predicction module就是使用CNN网络模型。最后输出heatmap热图的位置点,通过高斯分布获得最佳预测位置。
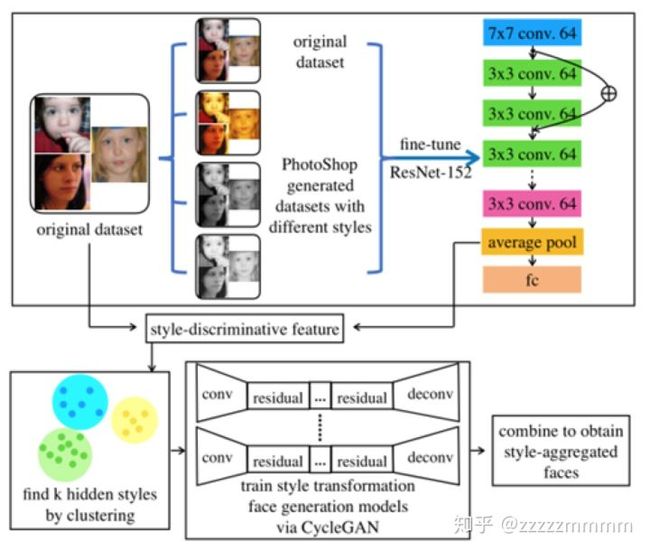
文章中使用不同的风格style主要是3哥,一个是草图sketch,一个是强光下light,另外一个是gray灰度图,合成一个[12, width, hegih]的矩阵作为网络模型的输入,增加了算法的抗敏性。

总结
深度学习技术的出现,有效促进了不同尺度和不同任务信息之间的融合,使得信息的结合方式由平面开始向立体方法发展,对于人脸关键点提取模型的发展,具有突出的实际意义。正因为如此,本文对目前人脸关键点检测任务中常用的深度学习方法进行综述。
尽管深度学习方法在人脸关键点检测任务上已经获得了长足的发展,算法性能不断提升,与实际应用的要求也越来越接近。然而,该任务的研究还远未结束,目前还有一些关键性难题亟待解决。在此总结三点:
(1)输入样本多样性问题:多变的人脸姿态和遮挡。姿态和遮挡是人脸关键点检测所面临的经典难题,近年来也出现了很多处理这两方面问题的思路和方法,但目前在实际应用中,尤其在实时低图像质量条件下,对于这两类难题的处理还难以令人满意. 尤其当姿态发生快速和剧烈改变,以及遮挡比例较大时,现有方法的精度距离实际应用的要求还有较大差距,需要进一步研究和提升。

(2)大场景小样本问题:在图像中非常多的小人脸。小人脸检测是人脸关键点检测所面临的经典难题,近年来出现了很多论文去解决小人脸检测,但是对于小人脸的关键点检测的思路和方法并不常见。主要受制于一个很严重的问题就是图像的质量不够高,小图像中的单张人脸图像质量低,一个像素包含的内容非常少,图片模糊。因此对于这类型的人脸关键点检测依然是个非常困难的话题;另外一个主要原因是受制于前一个步骤——小场景的人脸检测准确率低的问题,既然人脸检测的准确率低,那么在基于人脸检测下的人脸关键点检测问题会更加凸显和严重。

(3)方法众多但是百变不离其中:深度学习的方法百花齐放,但是在众多的方法当中没有一个非常outstanding的论文能够统一所有的方法,或则凸显出来。因为在深度学习当中,其主要思路是利用神经网络的非线性映射关系在标注的数据和输入的数据之间找到一个最优映射路径,通过这个映射关系去逼近我们的目标,但是这种方法的缺点是肯定会存在过拟合的问题。究其原因是人脸相似度很高(即使说是千人千脸,但是对比起其他动物的脸,其他物体和人脸对比其人脸与人脸之间的相识度依然非常高),在高相似度中间找到不同人脸之间的细微差别是非常困难的,因此出现了很多方法去解决这个问题,但是各论文分别去解决各自所在细分领域或者细分问题上,并没有一个很好的框架或者算法去解决这问题。
本文针对近年人脸关键点检测方法中的深度学习方法进行了综述研究。本文对人脸关键点检测任务进行了详细描述,并将具有代表性的深度学习网络模型,从模型设计思路到模型框架均进行较为深入的探究。在所面临的挑战性问题和开展相关研究所需的基础知识方面,本文亦抛砖引玉,希望本文能对相关科研人员了解人脸关键点检测问题并开展相关研究起到微薄的作用。