Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
-
- 常用激活函数
-
- Sigmoid 激活函数
- Tanh 激活函数
- ReLU 激活函数
- 线性激活函数
- Softmax 激活函数
- 损失函数
-
- 均方误差
- 平均绝对误差
- 分类交叉熵
- 系列链接
常用激活函数
使用激活函数可以实现网络的高度非线性,这对于建模输入和输出之间的复杂关系非常关键。如果没有非线性激活函数,那么该网络将仅仅能够表达简单的线性映射,即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的,只有加入了非线性激活函数之后,深度神经网络才具备了令人惊异的非线性映射学习能力。 可以在网络中的多个层中应用激活函数。
Sigmoid 激活函数
sigmoid 是使用范围最广的一类激活函数,其取值范围为 [0, 1],它可以将一个实数映射到 [0, 1] 的区间,可以将其用于二分类问题。
Sigmoid 函数公式定义如下所示:
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\frac 1 {1+e^{-x}} sigmoid(x)=1+e−x1
使用 Python 实现此函数:
def sigmoid(x):
return 1/(1+np.exp(-x))
函数图像如下所示,可以看到函数的形状如 S 曲线,因此也称为 S 型生长曲线:
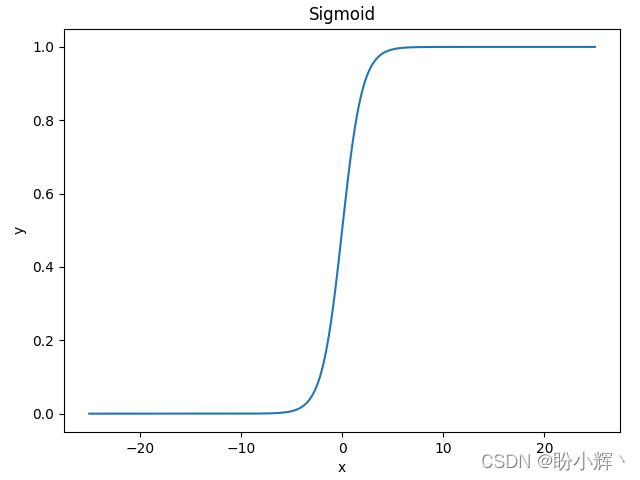
sigmoid函数优点:平滑、易于求导。sigmoid函数缺点:反向传播求导涉及除法,因此计算量大;反向传播时,很容易就会出现梯度消失的情况,从而限制了深层网络的训练。
Tanh 激活函数
Tanh 是双曲函数的一种,其是 Sigmoid 激活函数的改进,是以零为中心的对称函数,其取值范围为 [-1, 1]。Tanh 激活函数计算公式如下:
t a n h ( x ) = e x − e − x e x + e − x = 2 s i g m o i d ( 2 x ) − 1 tanh(x) =\frac {{e^x} -e^{-x}} {{e^x} +e^{-x}}=2sigmoid(2x)-1 tanh(x)=ex+e−xex−e−x=2sigmoid(2x)−1
使用 Python 实现此函数:
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
函数图像如下所示,它在开区间 (-1, 1) 内是单调递增的奇函数,函数图形关于原点对称:
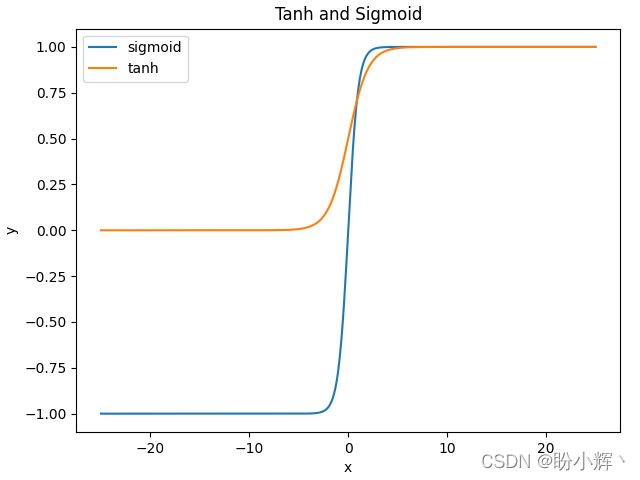
-
tanh函数优点:tanh函数是sigmoid函数的改进,收敛速度快,不易出现loss值晃动。 -
tanh函数缺点:无法解决梯度弥散的问题,函数的计算量同样是指数级的,计算相对复杂。
ReLU 激活函数
修正线性单元 (Rectified Linear Units, ReLU) 激活函数是 sigmoid 和 tanh 激活函数的完美替代激活函数,是深度学习领域最重要的突破技术之一。ReLU 激活函数计算公式如下:
r e l u ( x ) = { 0 , x < 0 x , x ≥ 0 relu(x) = \begin{cases} 0, & {x<0} \\ x, & {x\ge0} \end{cases} relu(x)={0,x,x<0x≥0
使用 Python 实现此函数:
def relu(x):
return np.where(x>0, x, 0)
函数图像如下所示,当输入值 大于等于 0 时,则 ReLU 函数按原样输出。如果输入小于 0,则 ReLU 函数值为 0。因为 ReLU 函数的大于等于 0 的线性分量具有固定导数,而对另一个线性分量导数为 0。因此,使用 ReLU 函数训练模型要快得多。
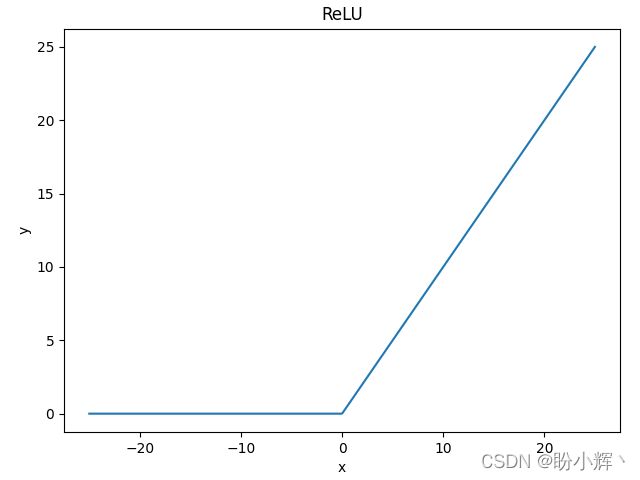
ReLU函数优点:不存在梯度消失问题,计算成本很低,收敛速度比sigmoid和tanh函数快得多。ReLU函数缺点:当梯度值过大时,其权重更新后为负数,在ReLU函数中导数恒为零,导致后面的梯度也不再更新,也被称为dying ReLU问题。
线性激活函数
线性激活的输出是输入值本身,按原样输出输入值:
l i n e a r ( x ) = x linear(x) = x linear(x)=x
使用 Python 实现此函数:
def linear(x):
return x
该函数仅用于解决回归问题的神经网络模型的输出层,注意不能在隐藏层中使用线性激活函数。
Softmax 激活函数
通常,softmax 在神经网络输出最终结果前使用。通常使用 softmax 是为了确定输入在给定场景中属于 n 个可能的输出类别之一的概率。假设我们正在尝试将数字图像分类为可能的 10 类(数字从0到9)之一。在这种情况下,有 10 个输出值,其中每个输出值代表输入图像属于某个类别的概率。Softmax 激活函数计算公式如下:
s o f t m a x ( x i ) = e i ∑ j = 0 N e j softmax(x_i)=\frac {e^i} {\sum _{j=0} ^N e^j} softmax(xi)=∑j=0Nejei
softmax 激活用于为输出中的每个类别提供一个概率值,其中 i i i 表示输出的索引。使用 Python 实现此函数:
def softmax(x):
return np.exp(x) / np.sum(np.exp(x))
softmax 函数一般作为神经网络的最后一层,接受来自上一层网络的输入值,然后将其转化为概率。例如我们要识别一张图片,其可能的标签为 [apple, banana, lemon, pear],则网络最后一层值 [1.0, 2.0, 3.0, 4.0] 经过 softmax 函数后输出为 [0.0320586, 0.08714432, 0.23688282, 0.64391426]。
损失函数
利用损失函数计算损失值,模型就可以通过反向传播去更新各个参数,通过降低真实值与预测值之间的损失,使得模型计算得到的预测值趋近于真实值,从而达到模型训练的目的,在构建神经网络时通常使用的损失函数如下。损失函数需要为非负实值函数。
均方误差
误差是网络输出的预测值与实际值之差。我们对误差取平方,是因为误差可以是正值或负值。平方确保正误差和负误差不会相互抵消。我们计算均方误差 (Mean Square Error, MSE),以便当两个数据集的大小不相同时,它们间的误差是可比较的。预测值 (p) 和实际值 (y) 之间的均方误差计算如下:
m s e ( p , y ) = 1 n ∑ i = 1 n ( p − y ) 2 mse(p,y)=\frac 1 n \sum _{i=1} ^n(p-y)^2 mse(p,y)=n1i=1∑n(p−y)2
使用 Python 实现此函数:
def mse(p, y):
return np.mean(np.square(p - y))
当神经网络需要预测连续值时,通常使用均方误差。
平均绝对误差
平均绝对误差 (Mean Absolute Error, MSE) 的工作方式与均方误差非常相似。平均绝对误差通过对所有数据点上的实际值和预测值之间的绝对差值取平均值,从而确保正误差和负误差不会相互抵消。预测值 (p) 和实际值 (y) 之间的平均绝对误差的实现方式如下:
m s e ( p , y ) = 1 n ∑ i = 1 n ∣ p − y ∣ mse(p,y)=\frac 1 n \sum _{i=1} ^n|p-y| mse(p,y)=n1i=1∑n∣p−y∣
使用 Python 实现此函数:
def mae(p, y):
return np.mean(np.abs(p - y))
与均方误差相似,平均绝对误差通常用于连续变量值的预测。
分类交叉熵
交叉熵是对两种不同分布(实际分布和预测分布)之间差异的度量。与上述两个损失函数不同,它被广泛用于离散值输出数据。两种分布之间的交叉熵计算如下:
− ( y l o g 2 p + ( 1 − y ) l o g 2 ( 1 − p ) ) -(ylog_2p+(1-y)log_2(1-p)) −(ylog2p+(1−y)log2(1−p))
y y y 是实际结果, p p p 是预测结果。预测值 (p) 和实际值 (y) 之间的分类交叉熵的 python 实现方式如下:
def categorical_cross_entropy(p, y):
return -np.sum((y*np.log2(p) + (1-y)*np.log2(1-p)))
当预测值远离实际值时,分类交叉熵损失具有较高的值,而当与实际值接近时,分类交叉熵损失具有较低的值。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——信用预测
Keras深度学习实战(8)——房价预测