元强化学习初步
元强化学习
- 如有错误,欢迎指正
-
- 所引用内容链接
- 元学习
-
- 元学习方法
-
- HyperNetwork 生成参数
- Conditional Neural Network 条件神经网络
- MAML 基于梯度的做法
- 优缺点
- 元强化学习概念
- 元强化学习背景
- 元强化学习内容
-
- 元参数
- 基于模型的元强化学习
- 基于优化的元强化学习
- 个人感想
如有错误,欢迎指正
本篇为自我学习过程中的要点记录,仅作学习使用。
所引用内容的链接将全部粘贴于下方,如有侵权,请与本人联系。
所引用内容链接
让机器像人类一样学习? 伯克利 AI 研究院提出新的元强化学习算法: https://www.leiphone.com/news/201906/hF46xpHkFrSVXilN.html.
元强化学习研究笔记: https://huangwang.github.io/2019/01/27/%E5%85%83%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E7%A0%94%E7%A9%B6%E7%AC%94%E8%AE%B0/.
元强化学习: https://blog.csdn.net/qq_27465499/article/details/105101772.
下面这个文章是重点!!!
元强化学习简介: https://www.cnblogs.com/lucifer1997/p/13603979.html.
元学习
Meta Learning研究Task!Meta Learning的目的是希望学习很多很多的task,然后有了这些学习经验之后,在面对新的task的时候可以游刃有余,学的快又学的好!那为什么叫Meta呢?Deep Learning是在Task里面研究,现在Meta Learning是在Task外面,更高层级来研究。也就是在Meta Learning的问题上,Task是作为样本来输入的。
Meta RL(Meta Reinforcement Learning)是Meta Learning应用到Reinforcement Learning的一个研究方向,核心的想法就是希望AI在学习大量的RL任务中获取足够的先验知识Prior Knowledge然后在面对新的RL任务时能够 学的更快,学的更好,能够自适应新环境!
这应该类似于知识迁移
从目标上看元学习和迁移学习并无本质区分,都是增加学习器在多任务的范化能力,但元学习更偏重于任务和数据的双重采样,任务和数据一样是需要采样的,而学习到的F(x)可以帮助在未见过的任务f(x)里迅速建立映射关系。而迁移学习更多是指从一个任务到其它任务的能力迁移,不太强调任务空间的概念。
机器学习学习某个数据分布X到另一个分布Y的映射。而元学习学习的是某个任务集合D到每个任务对应的最优函数f(x)的映射(任务到学习函数的映射)。
元学习方法
-
学习有效的距离度量方式,即事物背后的关联(基于度量的方法);
基于度量的元学习的核心思想类似于最近邻算法(k-NN分类、k-means聚类)和核密度估计。 -
使用带有显式或隐式记忆储存的RNN,学习如何建模(基于模型的方法);
最直观的方法,使用基于RNN的技术记忆先前任务中的表征等,这种表征将有助于学习新的任务。 -
训练以快速学习为目标的模型,学会如何学习(基于优化的方法)。
深度学习模型通过反向传播梯度进行学习。然后基于梯度的优化方法并不适用于仅有少量训练样本的情况,也很难在短短几步之内达到收敛。
HyperNetwork 生成参数
HyperNetwork是一个蛮有名的网络,简单说就是用一个网络来生成另外一个网络的参数。
Conditional Neural Network 条件神经网络
MAML 基于梯度的做法
MAML的核心步骤就是
- 采集Task,得到D_train和D_test。
- 使用D_train对神经网络f训练少数几步,得到新的参数。
- 利用新的参数训练D_test,然后使得梯度下降更新一开始的参数。
优缺点
先说HyperNetwork生成参数的做法。这种做法最大的问题就在于参数空间是很大的,所以要生成合适的参数特别是巨量的参数其实是比较困难的,所以目前绝大多数生成参数的做法都是只生成少量参数,比如一层的MLP,或者对于参数的空间进行一定的限制,比如就在[-1,1]之间,否则空间太多,有无数种选择输出一样的结果,就很难训了。但是采样HyperNetwork又有其灵活性,意味着我们可以只更新少部分参数,而不用全部。
接下来就是条件神经网络了。这又有什么问题呢?我觉得在性能上绝对会是最好的,很直接,但是不好看,一直要拖着一个条件,网络很大。不管是生成参数还是MAML,他们的模型网络就是独立的,之后只要输入x就行了,而条件神经网络每次都要输入条件,很烦啊。
那么MAML呢?可能最烦人的就是二次梯度了,这意味着MAML的训练会很慢,那么就很难hold住大网络了。实际上MAML目前对于大的网络结构比如Resnet效果并不好。然后MAML是使用D_train的Loss来更新整个网络,对比HyperNetwork缺少灵活性。这个Loss就是最好的吗?不见得。如果D_train是无监督数据,那怎么办?所以MAML是有局限性的。
元强化学习概念
元强化学习渐渐回归视线,即将基础强化学习方法中手动设定的超参数设定为元参数,通过元学习方法学习和调整元参数,进一步指导底层的强化学习过程。
元强化学习背景
假设要使智能体来完成诸如人类这样的学习能力,元学习则是一种可以参考的方法。使用这一范式,智能体可以通过充分利用在执行相关任务中积累的丰富经验,以这些有限的数据为基础去适应新的任务。针对这类既需要采取行动又需要积累过往经验的智能体来说,元强化学习可以帮助其快速适应新的场景。
深度强化学习系统存在的缺点:
- 它的样本利用率非常低。
- 最终表现很多时候不够好。
- DRL成功的关键离不开一个好的奖励函数(reward function),然而这种奖励函数往往很难设计。
- 局部最优/探索和剥削(exploration vs. exploitation)的不当应用。
- 对环境的过拟合。
- 不稳定性。
元强化学习内容
目前主流的元强化学习方法主要可以分为两类:
- 基于模型的元强化学习(当下比较火热的类脑方法,利用RNN可以与大脑的前额叶皮层建立对应)
- 基于优化的元强化学习(用于元强化学习的元学习算法,例如MAML)
元参数
学习率 α: α控制训练速度,过小导致学习缓慢,过大则导致学习过程振荡。
逆温度系数 β: 在依概率随机选取动作的设定下,往往采用
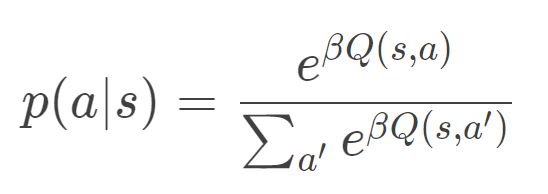
其中 Q为状态-动作值函数。此时逆温度系数 β控制着探索-利用之间的权衡。理想情况下,β在学习的初始阶段应该较小,因为此时agent还不能将动作很好地映射到其长期回报,应该鼓励更多的探索;并且随着agent获得越来越大的奖励而逐渐增大。
折扣因子 γ:指示agent应该将未来多远的奖励纳入考虑范围。如果 γ 较小,则agent只考虑短期收益,如果 γ = 1 则意味着agent要将未来长期所有的收益都纳入考虑。但在实际中有几个原因阻碍了这一点:其一,任何agent都有有限的寿命,无论是人工的还是生物的,一个有折扣的价值函数 = 一个无折扣的价值函数 + 一个有固定死亡率 1 − γ的agent。其二,agent所能接受的奖励延迟是有限度的,如动物必须在饿死之前找到食物。其三,如果环境转移动态是随机不平稳的,那么长期预测注定不可靠。其四,学习价值函数的复杂度 ∝ 1 / ( 1 − γ )
基于模型的元强化学习
基于模型的元RL的总体配置与普通的RL算法非常相似,不同之处在于,除了当前状态st之外,最近奖励rt-1和最近动作at-1也被合并到策略观察中。
- RL:πθ(st) → A上的一个分布
- 元RL:πθ(at-1, rt-1, st) → A上的一个分布
此设计的目的是将历史记录馈入模型,以便策略可以内化当前MDP中状态,奖励和动作之间的动态,并相应地调整其策略。这与Hochreiter系统中的设置非常吻合。Meta-RL和RL都实施了LSTM策略,而LSTM的隐含状态充当了跟踪轨迹特征的记忆。由于该策略是周期性的,因此无需明确地将最近状态作为输入提供。
训练过程如下:
- 采样得到一个新的MDP,Mi ~ M;
- 重置模型的隐含状态;
- 收集多个轨迹并更新模型权重;
- 从步骤1开始重复。
元RL中包含三个关键组件:
- A Model with Memory:RNN保持隐含状态。因此,它可以通过在部署期间更新隐含状态来获取并记住有关当前任务的知识。没有记忆,元RL将无法工作。
- Meta-learning Algorithm:元学习算法是指我们如何更新模型权重以进行优化,以便在测试时快速解决看不见的任务。在Meta-RL和RL2论文中,元学习算法都是LSTM的普通梯度下降更新,其中MDP的切换之间具有隐含状态重置。
- A Distribution of MDPs:尽管智能体在训练期间面临各种环境和任务,但它必须学习如何适应不同的MDP。
重要例子:Discovering Reinforcement Learning Algorithms
基于优化的元强化学习
基于优化的元强化学习是更新模型参数的方法,以便在新任务上实现良好的泛化性能。
个人感想
元强化学习的初衷是拓展强化学习的应用场景,使其不必要为单独环境进行单独的设计。基于优化的方法是学习参数,生成网络。基于模型的方法是学习MDP的变化,提高泛化性能。