Chromium网页渲染机制简要介绍和学习计划
作为一个浏览器,快速地将网页渲染出来是最重要的工作。Chromium为了做到这一点,费尽了心机,做了大量优化工作。这些优化工作是卓有成效的,代表了当今最先进的网页渲染技术。值得一提的是,这些渲染技术不仅适用于网页渲染,也可以应用在原生系统的UI渲染上。例如,在Android系统上,我们就可以看到两者在渲染技术上的相似之处。本文接下来就对Chromium的网页渲染机制进行简要介绍,并且制定学习计划。
老罗的新浪微博:http://weibo.com/shengyangluo,欢迎关注!
《Android系统源代码情景分析》一书正在进击的程序员网(http://0xcc0xcd.com)中连载,点击进入!
Chromium的网页渲染机制可以用八个字来描述:纵向分层,横向分块。其中,分层是由WebKit完成的,就是把网页抽象成一系列的Tree。Tree由Layer组成,Layer就是我们所说的层。从前面Chromium网页加载过程简要介绍和学习计划这个系列的文章可以知道,WebKit为网页依次创建了DOM Tree、Render Object Tree、Render Layer Tree和Graphics Layer Tree四棵Tree。其中,与渲染相关的是后面三棵Tree。将网页进行分层,好处有两个。一是减少不必要的绘制操作,二是利用硬件加速渲染动画。
第一个好处得益于WebKit将网页一帧的渲染分为绘制和合成两个步骤。绘制是将绘图操作转化为图像的过程,合成是将所有图像混合在一起后显示在屏幕上的过程。注意,对于屏幕来说,不管它某一个区域的内容是否发生变化,在它的下一帧显示中,总是需要进行刷新的。这意味着系统总是需要给它一个完整的屏幕内容。考虑这样的一个网页全屏显示的场景,并且网页被抽象为两个层。在下一帧显示中,只有一个层的内容发生了变化。这时候,只需要对内容发生变化的层执行绘制操作即可,然后与另一个层上一帧已经绘制得到的图像进行合成就可以得到整个屏幕的内容。这样就避免了不必要的绘制操作,额外付出的代价是一个合成操作。但是请注意,相对于绘制来说,合成是一个很轻量级的操作,尤其是对硬件加速渲染来说,它仅仅就是一个贴纹理的过程,并且纹理内容本身已经是Ready好了的。第二个好处将某些动画单独放在一层,然后对这个层施加某种变换,从而形成动画。某些变换,例如平移、旋转、缩放,或者Alpha渐变,对硬件加速来说,是轻易实现的。
与分层相比,分块是一个相对微观的概念,它是针对每一个层而言的。一般来说,一个网页的内容要比屏幕大很多,因此,用户会经常性地进行滚动或者缩放浏览。这种情况在移动设备上表现尤其特出。如果所有内容都是可见的一刻再进行绘制,那么就会让用户觉得很卡顿。另一方面,如果一开始就对网页所有的内容,不管可见还是不可见,都进行绘制,那么就会让用户觉得网页加载很慢,而且会非常耗费资源。这两种方案都不合适。最理想的方式是尽快显示当前可见的内容,并且在有富余劳动力的时候,预先绘制那些接下来最有可能可见的内容。这意味着要赋予一个层的不同区域赋予不同的绘制优先级。每一个区域就是一个块(Tile),每一个层都由若干个块组成。其中,位于当前可见区域中的块的优先级最高的,它们需要最优先进行绘制。
有时候,即使只绘制那些优先级最高的块,也要耗费不少的时间。这里面有一个很关键的因素是纹理上传。这里我们只讨论硬件加速渲染的情况。与一般的GPU命令相比,纹理上传操作是一个很慢的过程。为了解决这个问题,Chromium首先按照一定的比例绘制网页的内容,例如0.5的比例。这样就可以减少四分之三的纹理大小。在将0.5比例的内容显示出来的同时,继续绘制正常比例的网页内容。当正常比例的网页内容绘制完成后,再替换掉当前显示的低分辨率内容。这种方式尽管让用户在开始时看到的是低分辨率的内容,但是也比用户在开始时什么也看不到要好。
以上就是网页分层和分块的概念。概念上是不难理解的,但是在实现上,它们是相当复杂的,而且会掺杂其它的优化点。例如,每一个网页会有两个线程一起协作完成整个渲染过程。这样就可以充分利用现代CPU的多核特性。不过这也会给网页的渲染过程带来复杂性,因为这会涉及到线程同步问题。这种渲染方式也因此称为线程化渲染。我们回过头来看Android应用程序UI的渲染方式,也是从单线程逐渐演变为多线程渲染。在5.0之前,一个Android应用程序进程只有一个线程是负责UI渲染的,这个线程就是主线程,也称为UI线程。到了5.0,增加了一个线程,称为Render线程,它与UI线程一起完成Android应用程序UI的渲染。这一点可以参考前面Android应用程序UI硬件加速渲染技术简要介绍和学习计划这一系列的文章。
为了更好地支持线程化渲染,Chromium中负责渲染网页的CC(Chromium Compositor)模块,会创建三棵Tree,与WebKit创建的Graphics Layer Tree相对应,如图1所示:
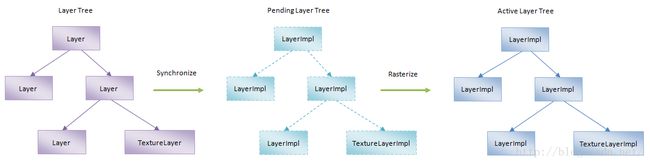
图1 CC模块中的Layer Tree、Pending Layer Tree和Active Layer Tree
其中,Layer Tree由Render进程中的Render Thread(也称为Main Thread)维护,Pending Layer Tree和Active Layer Tree由Render进程中的Compositor Thread(也称为Impl Thread)维护。在需要的时候,Layer Tree会与Pending Layer Tree进行同步,也就是在Render Thread与Compositor Thread之间进行UI相关的同步操作。这个操作由Compositor Thread执行。在执行期间,Render Thread处于等待状态。执行完成后,Compositor Thread就会对Pending Layer Tree中的Layer进行分块管理,并且对块进行光栅化操作,也就是将绘制命令变成一张图像。当Pending Layer Tree完成光栅化操作之后,它就会变成Active Layer Tree。Active Layer Tree是Chromium当前正在显示给用户浏览的Tree。
我们通过图2可以更直观地看到Render进程中的Render Thread和Compositor Thread的协作过程,如下所示:
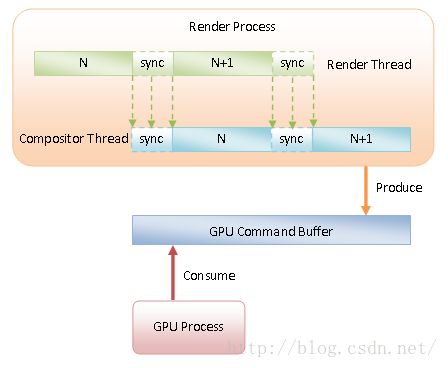
图2 Render Thread和Compositor Thread的协作过程
Render Thread绘制完成Layer Tree的第N帧之后,就同步给Compositor Thread的Pending Layer Tree。同步完成之后,Render Thread就去绘制Layer Tree的第N + 1帧了。与此同时,Compositor Thread也在抓紧时间对第N帧进行光栅化等操作。从这里就可以看到,第N+1帧的绘制操作与第N帧的光栅化操作是同步进行的,因此它们可以充分利用CPU的多核特性,从而提高网页渲染效率。
Compositor Thread完成光栅化操作之后,就会得到一系列的纹理,这些纹理最终会在GPU进程中进行合成。合成之后用户就可以看到网页的内容了。Render进程是通过Command Buffer请求GPU进程执行GPU命令,以及传递纹理资源等信息的,这些可以参考前面Chromium硬件加速渲染机制基础知识简要介绍和学习计划这个系列的文章。
从图3我们就可以看到,网页的一次渲染,实际上涉及到的核心线程有三个,除了Render进程中的Render Thread和Compositor Thread外,还有GPU进程中的GPU Thread,并且这三个线程是可以做到并行执行的,又进一步地利用了CPU的多核特点。
为了更好地管理Layer Tree,Render Thread创建了一个LayerTreeHost对象。同样,为了更好地管理Pending Layer Tree和Active Layer Tree,Compositor Thread创建了一个LayerTreeHostImpl对象。LayerTreeHost对象和LayerTreeHostImpl对象之间的通信就代表了Render Thread与Compositor Thread之间的协作。
LayerTreeHost对象和LayerTreeHostImpl对象并不是直接地进行通信的,而是通过一个Proxy对象进行,如图3所示:
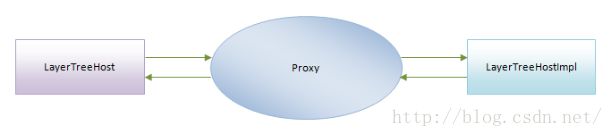
图3 LayerTreeHost对象和LayerTreeHostImpl对象通过Proxy对象通信
LayerTreeHost对象和LayerTreeHostImpl对象之所以要通过Proxy对象进行通信,是为了能够同时支持线程化渲染和单线程渲染两种机制。对于单线程渲染机制,使用的Proxy对象实际上是一个Single Thread Proxy对象,如图4所示:
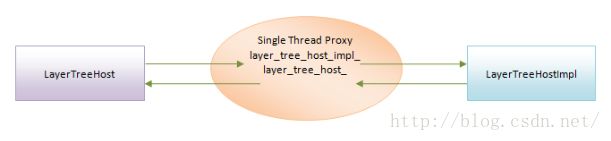
图4 单线程渲染
在单线程渲染机制中,LayerTreeHost对象和LayerTreeHostImpl对象实际上都是运行在Render Thread中,因此Single Thread Proxy的实现就很简单,它通过layer_tree_host_和layer_tree_host_impl_两个成员变量分别引用了LayerTreeHost对象和LayerTreeHostImpl对象。在LayerTreeHost对象和LayerTreeHostImpl对象需要相互通信的时候,就通过这两个成员变量进行直接调用即可。
对于线程化渲染机制,使用的Proxy对象实际上是一个Threaded Proxy对象,如图5所示:
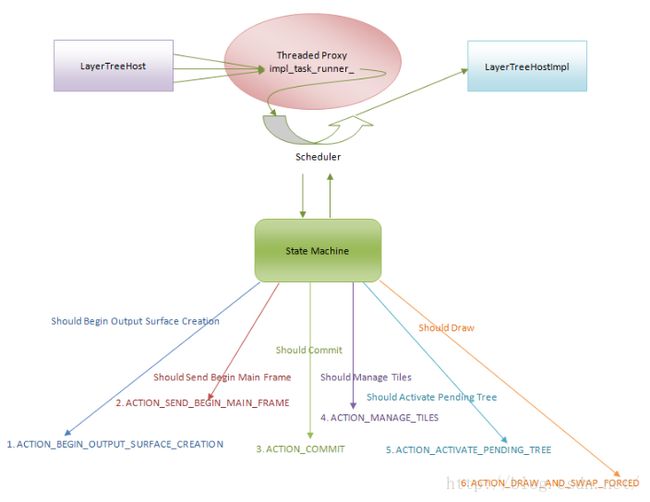
图5 线程化渲染
Threaded Proxy内部有一个成员变量impl_task_runner_,它指向一个SingleThreadTaskRunner对象。这个SingleThreadTaskRunner对象描述的是Compositor Thread的消息循环。当LayerTreeHost对象需要与LayerTreeHostImpl对象通信时,它就会通过上述Threaded Proxy中的SingleThreadTaskRunner对象向Compositor Thread发送消息,以请求LayerTreeHostImpl对象在Compositor Thread中执行某一个操作。但是Threaded Proxy并不会马上将该请求发送给LayerTreeHostImpl对象执行,而是会根据LayerTreeHostImpl对象的当前状态决定是否要向它发出请求。这样可以获得一个好处,就是CC模块可以平滑地处理各项渲染工作。例如,如果当前LayerTreeHostImpl对象正在光栅化上一帧的内容,这时候LayerTreeHost对象又请求绘制下一帧的内容,那么绘制下一帧内容的请求就会被延后,直到上一帧内容光栅化操作完成之后。这样就会避免状态混乱。
Threaded Proxy是通过一个调度器(Scheduler)来安排LayerTreeHostImpl对象什么时候该执行什么操作的。调度器又是通过一个状态机(State Machine)来记录LayerTreeHostImpl对象的状态流转的,从而为调度器提供调度安排。典型地,在一个网页的浏览期间,调度器会被依次调度执行以下操作:
1. 如果还没有创建绘图表面,那么调度器就会发出一个ACTION_BEGIN_OUTPUT_SURFACE_CREATE的操作,这时候LayerTreeHostImpl对象就会为网页创建一个绘图表面。关于网页的绘图表面及其创建过程,可以参考前面Chromium硬件加速渲染的OpenGL上下文绘图表面创建过程分析一文。
2. 当Layer Tree发生变化需要重绘时,调度器就会发出一个ACTION_SEND_BEGIN_MAIN_FRAME操作,这时候LayerTreeHost对象就会对网页进行重绘。这里有两点需要注意。第一点是这里所说的绘制,实际上只是将绘图命令记录在了一个命令缓冲区中。第二点是绘制操作是在Render Thread中执行的。
3. LayerTreeHost对象重绘完Layer Tree之后,Render Thread会处于等待状态。接下来调度器会发出一个ACTION_COMMIT操作,通知LayerTreeHostImpl对象将Layer Tree的内容同步到Pending Layer Tree中去。这个同步操作是在Compositor Thread中执行的。同步完成之后,Render Thread就会被唤醒,而Compositor Thread继续对Pending Layer Tree中的分块进行更新,例如更新分块的优先级。
4. 对Pending Layer Tree中的分块进行更新之后,调度器发出一个ACTION_MANAGE_TILES操作,通知LayerTreeHostImpl对象对Pending Layer Tree中的分块进行光栅化。
5. Pending Layer Tree完成光栅化操作之后,调度器继续发出一个ACTION_ACTIVATE_PENDING_TREE操作,这时候Pending Layer Tree就变成Active Layer Tree。
6. Pending Layer Tree就变成Active Layer Tree之后,调度器再发出一个ACTION_DRAW_AND_SWAP_FORCED,这时候LayerTreeHostImpl对象就会将已经光栅化好的分块信息收集起来,并且发送给Browser进程,以便Browser进程可以将这些分块合成在浏览器窗口中显示。这一点可以参考前面Chromium硬件加速渲染的UI合成过程分析一文。
其中,第2到第6个操作就是网页一帧的完整渲染过程,这个过程在网页的浏览期间不断地重复进行着。
在网页的渲染过程中,最重要的事情就是对分块的管理。分块是以层为单位进行管理的。这里涉及到两个重要的术语:Tile和Tiling。它们的关系如图6所示:
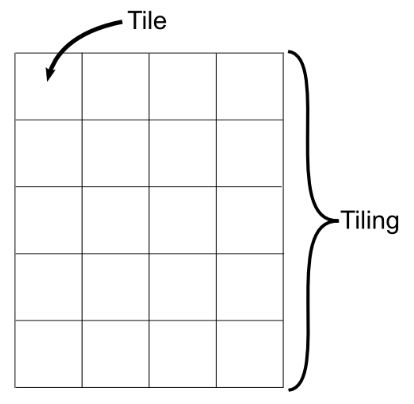
图6 Tile和Tiling
Tiling是由具有相同缩放比例因子的Tile组成的一个区域。在Chromium源代码中,Tiling通过类PictureLayerTiling描述。一个层可能会按照不同的缩放因子进行分块,如图7所示:
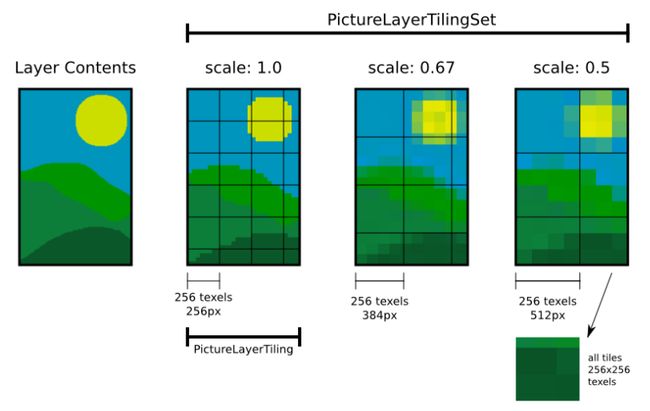
图7 不同缩放因子的Tiling
在图7中,分块的大小设定为256x256px。对于缩放因子为1.0的Tiling,分块中的1个像素就对应于层空间的1个像素。对于缩放因子为0.67的Tiling,分块中的1个像素就对应于层空间的1.5个像素。同理可以知道,对于缩放因子为0.5的Tiling,分块中的1个像素就对应于层空间的2个像素。
为什么一个层要按照不同的缩放因子进行分块呢?前面提到,主要是为了在滚动或者缩放网页时,可以尽快地将网页内容显示出来,尽管显示出来的内容是低分辨率的,如图8所示:
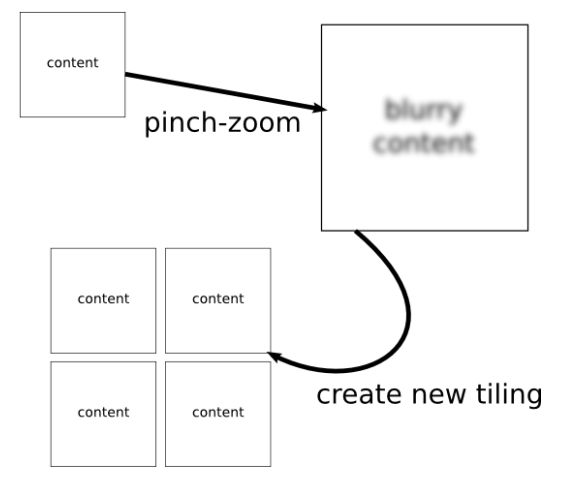
图8 网页放大过程
图8显示的是一个网页被放大的过程。开始的时候,较低缩放因子的分块会被放大,用来填充可见区域。这时候与实际放大因子相同的分块正在背后悄悄地进行创建以及光栅化。等到这些操作完成之后,它们就会替换掉较低缩放因子的分块显示在可见区域中。因此,我们在放大网页的时候,首先会看到模糊的内容,接着很快又会看到清晰的内容。
一个层的内容占据的区域可能是非常大的,超过了屏幕的大小。这时候我们不希望对整个层的内容都进行分块,因为这会浪费资源。同时,我们又希望对尽可能多的内容进行分块,这样当当前不可见的分块变为可见时,就会快速得到显示。CC模块将一个层的内容大致分为三个区域,如图9所示:
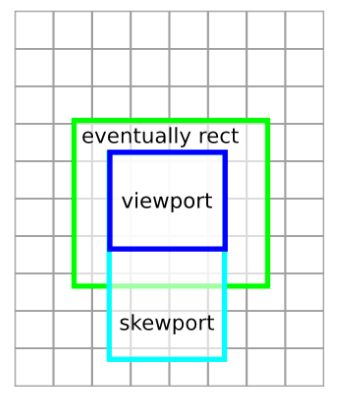
图9 层区域划分
从图9可以看到,有Viewport、Skewport和Eventually Rect三个区域,CC模块只对它们进行分块。其中,Viewport描述的是当前可见的区域,Skewport描述的是顺着用户的滑动方向接下来可见的区域,Eventually Rect是在Viewport的四周增加一个薄边界形成的一个区域,这个区域的内容我们认为最终会有机会得到显示。很显然,从重要程度来看,Viewport > Skewport > Eventually Rect。因此,CC模块优先光栅化Viewport中的分块,接着是Skewport中的分块,最后是Eventually Rect中的分块。
确定了哪些区域需要分块,以及分块的光栅化顺序之后,接下来最核心的操作就是执行光栅化操作,如图10所示:
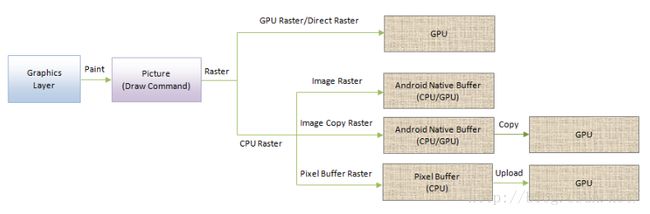
图10 分块光栅化过程
网页按照Graphics Layer进行绘制,它们被绘制一个Picture中。这个Picture实际上只是保存了绘制命令。将这些绘制命令变成像素就是光栅化所做的事情。光栅化可以通过GPU完成,也可以通过CPU完成。
如果是通过GPU完成,那么保存在Picture的绘制命令就会转化为OpenGL命令执行,最终绘制出来的像素就直接保存在一个GPU纹理中。因此这种光栅化方式又称为Direct Raster。
如果是通过CPU完成光栅化,那么保存在Picture的绘制命令就会转化为Skia命令执行。Skia是一个2D图形库,它通过CPU来执行绘制操作。最终绘制出来的像素保存在一个内存缓冲区中。在Android平台上,CC模块提供了三种CPU光栅化方式。
第一种方式称为Image Raster,光栅化后的像素保存Android平台特有的一种Native Buffer中。这种Native Buffer即可以被CPU访问,也可以被GPU当作纹理访问。这样就可以在光栅化操作完成之后避免执行一次纹理上传操作,可以很好地解决纹理上传速度问题。因此这种光栅化方式又称为Zero Copy Texture Upload。
第二种方式称为Image Copy Raster,光栅化后的像素同样是保存在Android Native Buffer中。不过,保存在Android Native Buffer中的像素会被拷贝到另外一个标准的GPU纹理中去。为什么要这样做呢?因为Android Native Buffer资源有限,因此在光栅化完成之后就释放,可以降低资源需求。因此这种光栅化方式又称为One Copy Texture Upload。
第三种方式称为Pixel Buffer Raster,光栅化后的像素保存在OpenGL中的Pixel Buffer中,然后这种Pixel Buffer再作为纹理数据上传到GPU中。与前面两种CPU光栅化方式相比,它的效率是最低下的,因为涉及到臭名昭著的纹理上传问题。
为什么光栅化的像素最终都要上传到GPU里面去呢?因为我们只讨论硬件加速渲染的情况,因此无论是GPU光栅化,还是CPU光栅化,光栅化后的像素都要保存在GPU中,后面才可以通过硬件加速将它们渲染在屏幕上。
以上就是Chromium在渲染网页的时候涉及到的重要概念以及关键流程。在实现过程中,这些概念和流程要更加复杂。接下来,我们就按照以下七个情景更详细地对Chromium的网页渲染机制进行分析:
1. Layer Tree创建过程;
2. 调度器的执行过程;
3. Output Surface创建过程;
4. 网页绘制过程;
5. Layer Tree与Pending Layer Tree同步过程;
6. Tile光栅化过程;
7. Pending Layer Tree激活为Active Layer Tree过程;
理解了上述七个情景之后,我们对Chromium的网页渲染机制就会有深刻的理解了,敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。