CUDA实例系列一: 矩阵乘法优化
CUDA实例系列一----矩阵乘法优化
很多朋友在学习CUDA的时候都会面临一个题目----矩阵乘法, 这也是CUDA最广泛的应用之一. 本文将详细讲解如何利用GPU加速矩阵乘法的计算.
话不多说, 先上代码, 再解释:
#include
#include
#include "error.cuh"
#define BLOCK_SIZE 16
__managed__ int a[1000 * 1000];
__managed__ int b[1000 * 1000];
__managed__ int c_gpu[1000 * 1000];
__managed__ int c_cpu[1000 * 1000];
__global__ void gpu_matrix_mult(int* a, int* b, int* c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if (col < k && row < m)
{
for (int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
__global__ void gpu_matrix_mult_shared(int* d_a, int* d_b, int* d_result, int M, int N, int K)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub <= N/BLOCK_SIZE; ++sub)
{
int r = row;
int c = sub * BLOCK_SIZE + threadIdx.x;
idx = r * N + c;
if (r >= M || c >= N)
{
tile_a[threadIdx.y][threadIdx.x] = 0;
}
else
{
tile_a[threadIdx.y][threadIdx.x] = d_a[idx];
}
r = sub * BLOCK_SIZE + threadIdx.y;
c = col;
idx = r * K + c;
if (c >= K || r >= N)
{
tile_b[threadIdx.y][threadIdx.x] = 0;
}
else
{
tile_b[threadIdx.y][threadIdx.x] = d_b[idx];
}
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if (row < M && col < K)
{
d_result[row * K + col] = tmp;
}
}
void cpu_matrix_mult(int* a, int* b, int* h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += a[i * n + h] * b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const* argv[])
{
int m = 1000;
int n = 300;
int k = 1000;
cudaEvent_t start, stop_cpu, stop_gpu;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop_cpu));
CHECK(cudaEventCreate(&stop_gpu));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
a[i * n + j] = 0*rand() % 1024+1;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
b[i * k + j] = 0 * rand() % 1024 +1;
}
}
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult_shared << > > (a, b, c_gpu, m, n, k);
CHECK(cudaEventRecord(stop_gpu));
CHECK(cudaEventSynchronize(stop_gpu));
cpu_matrix_mult(a, b, c_cpu, m, n, k);
CHECK(cudaEventRecord(stop_cpu));
CHECK(cudaEventSynchronize(stop_cpu));
float elapsed_time_cpu, elapsed_time_gpu;
CHECK(cudaEventElapsedTime(&elapsed_time_gpu, start, stop_gpu));
CHECK(cudaEventElapsedTime(&elapsed_time_cpu, stop_gpu, stop_cpu));
printf("GPU Time = %g ms.\n", elapsed_time_gpu);
printf("CPU Time = %g ms.\n", elapsed_time_cpu);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop_cpu));
CHECK(cudaEventDestroy(stop_gpu));
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
//printf("GPU: % d; CPU: %d; ", h_c[i * k + j], h_cc[i * k + j]);
if (fabs(c_gpu[i * k + j] - c_cpu[i * k + j]) > (1.0e-10))
{
ok = 0;
}
//printf("\n");
}
}
if (ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
return 0;
}
看到这里, 我相信有基础的朋友,已经OK了. 如果,上述代码对你有用, 欢迎复制粘贴.
接下来, 为了能更好的讲解, 我只做了一份PPT来详细解释每一步. 因为写blog无法将文字放在图片里相应的位置, 所以我在下面将PPT的每一页以图片的形式贴出来, 方便大家理解.
__global__ void gpu_matrix_mult_shared(int* d_a, int* d_b, int* d_result, int M, int N, int K)
上面这个核函数为利用shared memory来优化矩阵的方法
- 首先, 我们假设我们要优化的矩阵乘为
M[16][16] * N[16][16] = P[16][16]

- 我们申请线程
gridDim(2,2); blockDim(8,8);, 保证每一个线程,负责求出P矩阵中一个位置的值
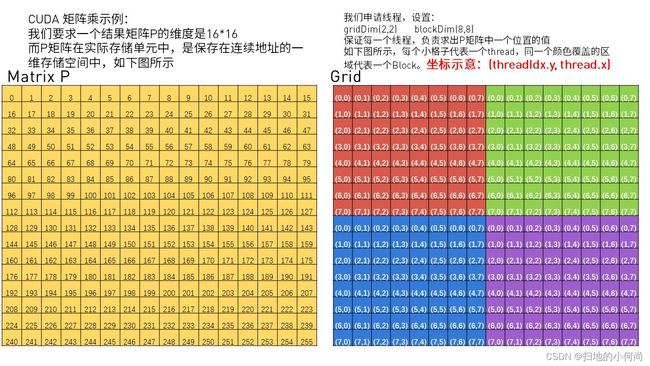
- 那么,下面右图中紫色区域覆盖的block就会负责求出P矩阵中相对应的位置的值(下面左图中紫色区域覆盖的位置)

- 那么,下图Grid中紫色区域的block,将会读取M矩阵中紫色区域的行 和 N矩阵中紫色区域的列。

- 因为紫色区域数据被多次读取, 为了提高效率, 我们利用CUDA中的
Shared Memory来进行优化.
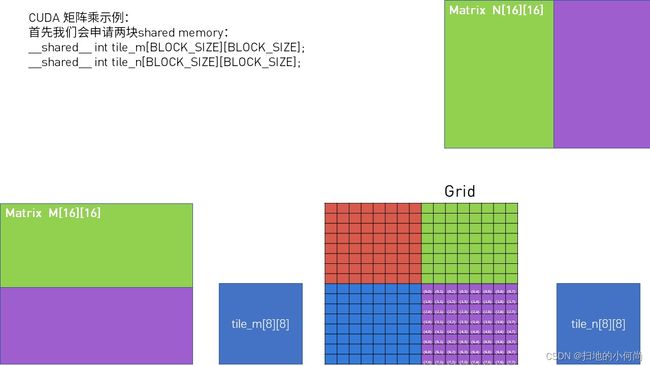
- 这里我们申请的线程将数据从global memory中读取, 放入Shared memory. 这里分块读取, 是因为每个block中的Shared memory不够大, 没法把所有紫色区域的数据都读进去. 所以先读取一小块.

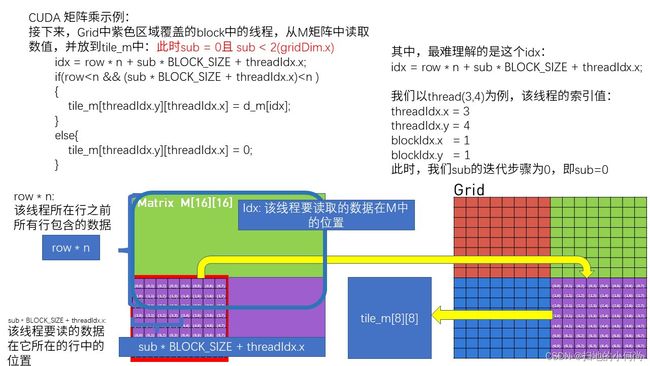
- 这里解释了对应的坐标关系, 详情请看下图. 这里还有一点很重要, 即使if中的越界判断.
- 这里读取的是N矩阵中的数据, 千万注意坐标问题
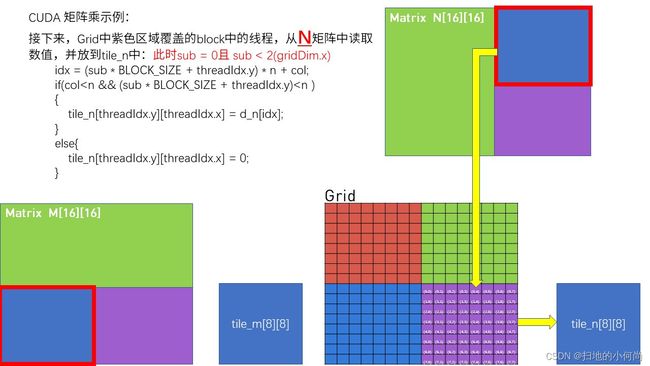
- 这里仍然是读取的N矩阵, 下图解释了为什么坐标那样写

- 这里解释了读完M和N中第一个小块之后的乘积操作
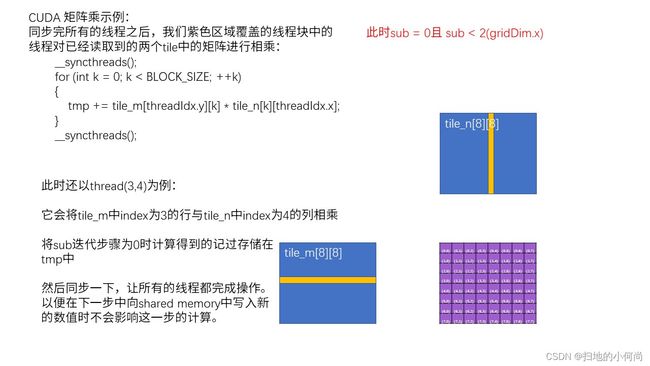
- 接下来的两张图解释了分别读取M和N矩阵的第二个小块


- 这里解释了读完第二小块之后做乘积, 并与第一小块的结果进行累加

- 将最终的结果写入global memory

总结:
利用Shared Memory优化矩阵乘是一个非常典型的分而治之的例子,也是所有CUDA初学者面临的第一个难题。同学们在学习这个案例的时候要注意:
- 越界问题:在线程访问数据和写入数据的过程中,要小心不要越界,不然会出现意想不到的错误。
- 赋零问题:在本教程6,7,8,9,11,12页中,在判断越界之后,我们会给Shared memory中相应位置赋值为零。这时候的零不会影响最终计算结果。这里赋值为零,就让第13页,第10页中的计算步骤中省去了判断越界问题的过程。
- 坐标问题:可能让所有新手同学头疼的最统一的答案就是坐标问题。二维空间的矩阵转和一维的向量相互转换,确实会让同学们感觉到压力。但是,在将来的CUDA开发中会有非常多的空间坐标转换问题。努力理解这里的坐标问题,将会为你将来的开发打下坚实的基础
希望这份教程能帮到你~~!!