【LSTM介绍】LSTM变种、常用架构以及相关文献梳理
文章目录
- 写在前面
- LSTM变种
-
- peephole connection
- coupled forgetting
- GRU(Gated Recurrent Units)
- SRU(Simple Recurrent Units)
- ConvLSTM
- ST-LSTM
- LSTM网络架构
-
- Vanilla LSTMs
- Stacked LSTMs
- CNN LSTMs
- Encoder-Decoder LSTMs
- Bidirectional LSTMs
- Attention LSTMs
- 多种LSTM架构混合
- 推荐文献(有开源代码的)
- 其他比较新的推荐的LSTM相关文献
写在前面
现在网上关于LSTM原理介绍的文章非常多,但却很少有文章对LSTM的整个脉络进行系统的梳理。笔者阅读了大量的文章,对LSTM的变种以及常用的架构进行了系统的梳理,包括每种方法的主要改进点、应用领域、文献出处等,供各位参考学习。当然还有很多不足之处,后续如有其他内容还会继续补充。
LSTM变种
peephole connection
- 增加“peephole connection"(窥探孔结构)
- 让门层也接受细胞状态的输入

论文:Gers, F. A. (1999): Learning to forget: continual prediction with LSTM. In : 9th International Conference on Artificial Neural Networks: ICANN '99. 9th International Conference onArtificial Neural Networks: ICANN '99. Edinburgh, UK, 7-10 Sept. 1999: IEE, pp. 850–855.
- 缺点:一种启发式的改进方法,没有经过严谨的数学推导论证
coupled forgetting
- 使用coupled忘记机制
- 原始LSTM是分开确定需要忘记和添加的信息,这里是一同做出决定
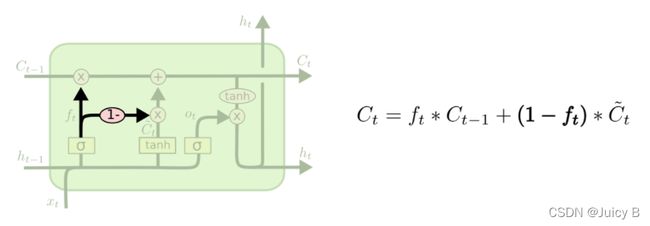
论文:Gers, F. A. (1999): Learning to forget: continual prediction with LSTM. In : 9th International Conference on Artificial Neural Networks: ICANN '99. 9th International Conference on Artificial Neural Networks: ICANN '99. Edinburgh, UK, 7-10 Sept. 1999: IEE, pp. 850–855.
GRU(Gated Recurrent Units)
- 应用最广泛的LSTM变体之一
- 门控数量减少到两个:复位门和更新门
- 复位门:用于控制上一个时间戳的状态 进入GRU的量
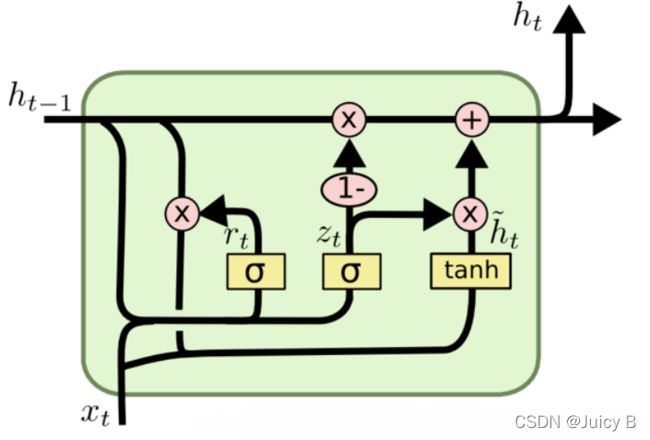
- 更新门:用于控制上一时间戳状态 h t − 1 \bold h_{t-1} ht−1和新输入 h ~ t − 1 \widetilde {\bold h}_{t-1} h t−1对新状态向量的影响程度
- 复位门:用于控制上一个时间戳的状态 进入GRU的量
论文:Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun; Bengio, Yoshua (2014): Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. Available online at http://arxiv.org/pdf/1412.3555v1.
SRU(Simple Recurrent Units)
- 去掉了对前后时刻输出 的计算依赖,实现多个时间步并行计算,相比原始的LSTM训练速度快若干倍
Lei, Tao, et al. Training RNNs as Fast as CNNs. 2017. https://github.com/stefbraun/sru/blob/master/readme.md
ConvLSTM
- 与CNN LSTM在LSTM层的前面堆叠CNN层不同,ConvLSTM实现的卷积内置的操作。
- 为了构建时空序列预测模型,同时掌握时间和空间信息,将LSTM中的全连接权重改为卷积。
- 用LSTM单元中每个门的卷积运算代替矩阵乘法。这样,它通过在多维数据中进行卷积操作来捕获基础空间特征。ConvLSTM和LSTM之间的主要区别在于输入维数。
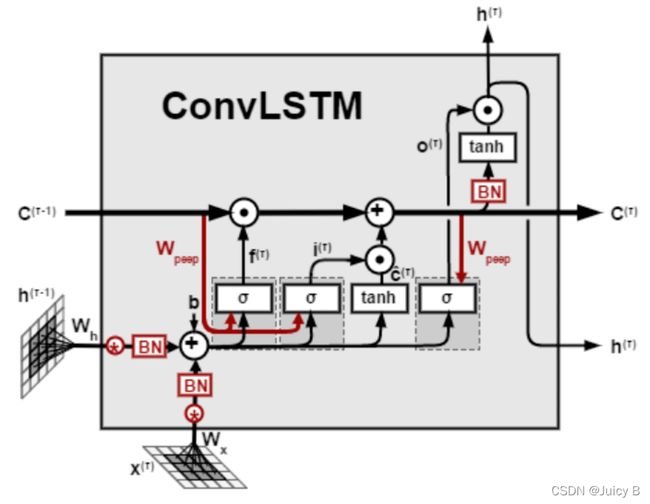
ConvLSTM设计用于三维数据作为其输入,解决了传统LSTM单元不适用于视频,卫星,雷达图像等空间序列数据集的问题。
论文: Shi, Xingjian; Chen, Zhourong; Wang, Hao; Yeung, Dit-Yan; Wong, Wai-kin; Woo, Wang-chun(2015): Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Available online at http://arxiv.org/pdf/1506.04214v2.
ST-LSTM
- 传统的ConvLSTM堆叠结构,层与层之间是独立的, t t t 时刻的最底层cell会忽略 t − 1 t-1 t−1 时刻最顶层cell的时空信息,并且层与层各cell之间的时空特征也没法传递。
- 每一层与每一层之间,只是单纯的一步一步的往上抽象特征, cell states只在水平方向上进行传递。 也就是同层的不同时间步中会有记忆流的传递,同一时间步不同层之间的这些单元是相互独立的,并没有记忆流传递,那么这时候的空间信息只在hidden state上向上传递,假设万一 t t t 时刻最底层这个空间信息特别重要, 也没法把这一个单元的空间信息传递到 t t t 时刻最顶层的单元中去,因为垂直方向上的单元是独立的,不存在记忆。
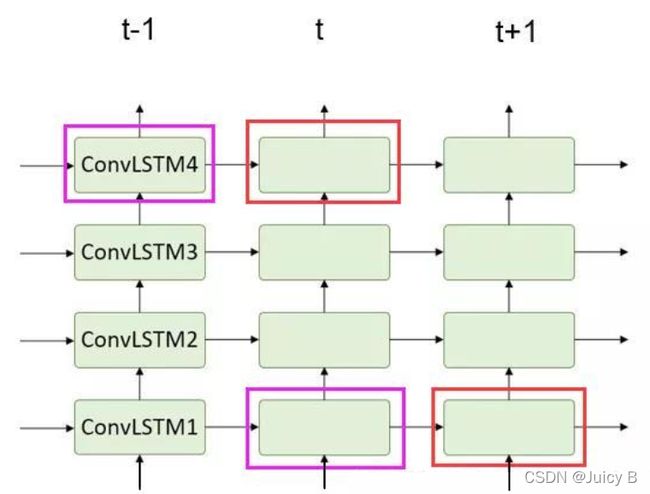
为了解决这一问题,提出以下改进结构:Spatiotemporal memory flow。这种结构基于ConvLSTM单元应用了一个统一的时空记忆池,并改变了RNN的连接, 所有的LSTM共享一个统一的记忆流,并沿着"之"字形方向进行更新。具有时空记忆流的卷积LSTM单元的关键方程如下所示:

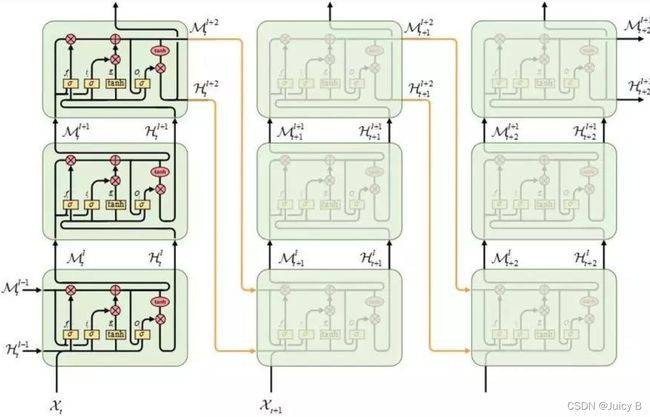
作者说这种时间记忆流在时空监督学习中是合理的,因为根据对叠加卷积层的研究,从底层向上隐藏的表示可以越来越抽象,越来越具有类特异性(监督学习中只需要预测类标签,越抽象越容易隐藏细节,越容易得到最终属于哪一类)。然而,我们在时空预测学习中,应该保持原始输入序列中的详细信息。如果我们想看到未来,我们需要学习在不同层次的卷积层中提取的表示。
以上的初步改进中,时空记忆单元以之字形方向更新,信息首先向上跨层传递,然后随着时间向前传递。但是这种结构仍然有缺点:
- 去掉了水平方向的时间流, 会牺牲时间上的一致性,因为在同一层的不同时间没有时间流了
- 记忆需要在遥远的状态之间流动更长的路径,更容易造成梯度消失。
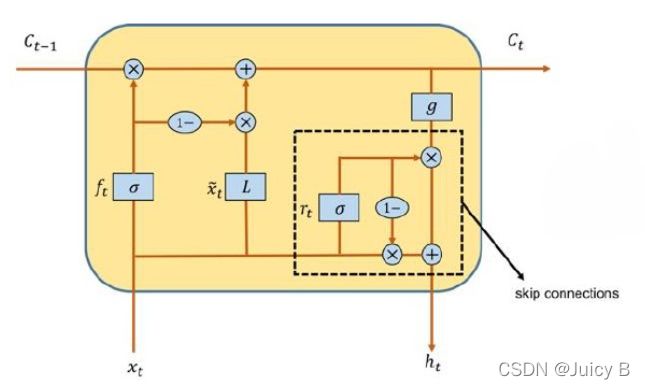
所以作者想知道如果记忆流同时在水平和垂直两个方向传递会发生什么,就改进了传统的LSTM内部构造,引入了一个新的单元,称为ST-LSTM:

左边这个就是上面的ST-LSTM单元结构,右边的是普通的LSTM,你发现了吗?其实左图红框里面是两个完全一样的LSTM结构,只是下面的cell output和hidden state都由M代替了,其他的输出部分其实就相当于把两个LSTM结构的输出整合在一起分别输出计算了。 文中称左图的上半部分"Standard Temporal Memory", 下半部分称"Spatiotemporal Memory"。基于这个单元,形成了一个新的架构 PredRNN:
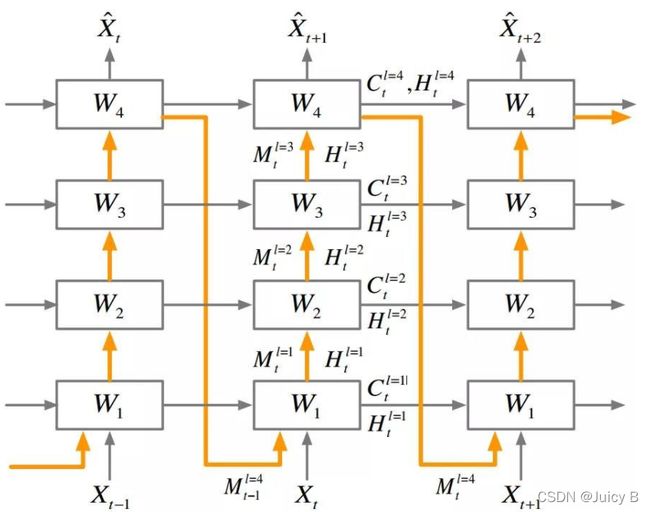
论文:Wang, Yunbo, et al. “PredRNN: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal LSTMs.” NIPS’17 Proceedings of the 31st International Conference on Neural Information Processing Systems, vol. 30, 2017, pp. 879–888.
LSTM网络架构
Vanilla LSTMs

该架构多用做生成模型,通过利用大量现有的序列信息,一次一步地生成新序列。常用的领域有:
- 生成维基百科文章(包括标点符号)
- 生成计算机源代码
- 生成文章标题
- 生成手写字体
- 生成音乐
- 生成语音
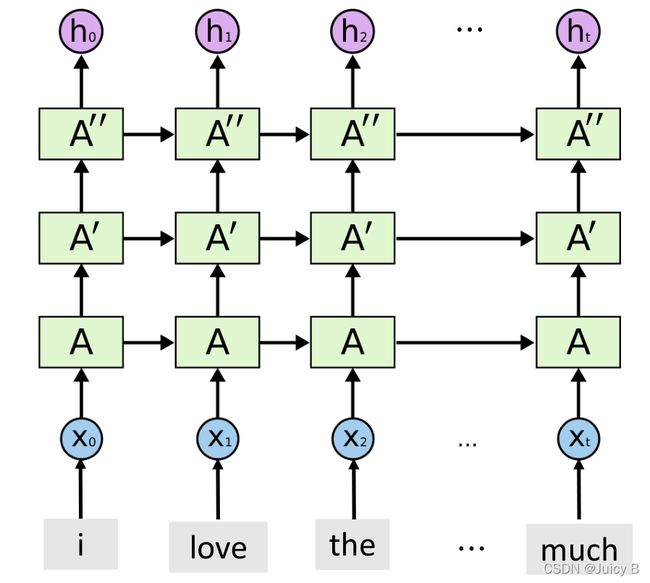
Stacked LSTMs
当一层LSTM不够提序列特征时,可以尝试将多个LSTM堆叠起来,提取更加深层次的抽象特征。

CNN LSTMs
CNN LSTM架构的原理是:使用卷积神经网络(CNN)对输入数据做特征提取,并结合LSTM来支持序列预测。
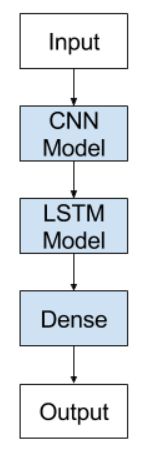
常见的应用包括:
- 活动识别:对一个序列的图片所显示的活动生成一个文本的描述。
- 图像描述:对单个图片生成一个文本的描述。
- 视频描述:对一个序列的图片生成一个文本的描述。
这种体系结构也被用于语音识别和自然语言处理问题,其中CNN被用作语音和文本输入数据上的LSTM的特征提取器。例如:

论文:Donahue, Jeff; Hendricks, Lisa Anne; Rohrbach, Marcus; Venugopalan, Subhashini; Guadarrama, Sergio; Saenko, Kate; Darrell, Trevor (2017): Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In IEEE transactions on pattern analysis and machine intelligence 39 (4), pp. 677–691.
DOI: 10.1109/TPAMI.2016.2599174.
Encoder-Decoder LSTMs
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。

-
seq2seq:根据一个输入序列x,来生成另一个输出序列y。
seq2seq有很多的应用,例如:
- 翻译。输入序列是待翻译的文本,输出序列是翻译后的文本。
- 文档摘取。
- 问答系统。输入序列是提出的问题,而输出序列是答案。
该架构由两个模型组成:
- 一个用于读取输入序列并将其编码为固定长度矢量
- 第二个用于解码固定长度矢量并输出预测序列
该架构的名称为Encoder-Decoder LSTM,专门针对seq2seq问题而设计。

Bidirectional LSTMs
将前向的 LSTM 与后向的 LSTM 结合而成。
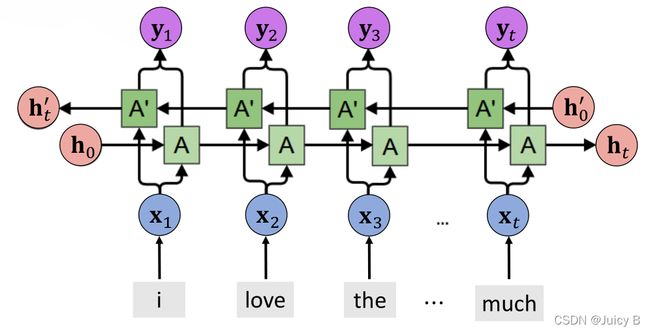
下面以识别"I love movies" 这句话为例。
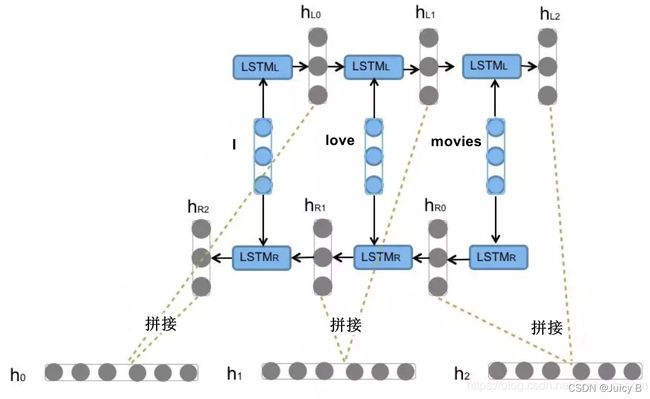
从左到右的理解这句话,每个时刻都能得到 h L i h_{L_i} hLi隐层输出,从右到左的理解这句话,每个时刻都能得到 h R i h_{R_i} hRi隐层输出,而 Bi-LSTM 将每个时刻的正向和反向隐层输出进行了拼接,变成 [ h L i h_{L_i} hLi, h R i h_{R_i} hRi] ,来表示当前时刻的特征更加丰满的隐层输出。
可以这样理解:计算机只认二进制码,所以两种方向的阅读方式都不影响它对这句话的两个方向的“语义的理解”,尽管从右往左人类一般不认为有什么语义存在,当然计算机可能会按照从右到左的顺序理解到人类无法直接理解的字符搭配等其他深层次含义。所以双向的特征更加能捕捉到代表这句话的“语义”。
Attention LSTMs
- 在输入层之间加Attention:

- 在输入层之后加Attention

多种LSTM架构混合
将上面提到的多种LSTM架构进行组合来完成更加复杂的任务是现在比较常用的方法。以动作识别任务为例:
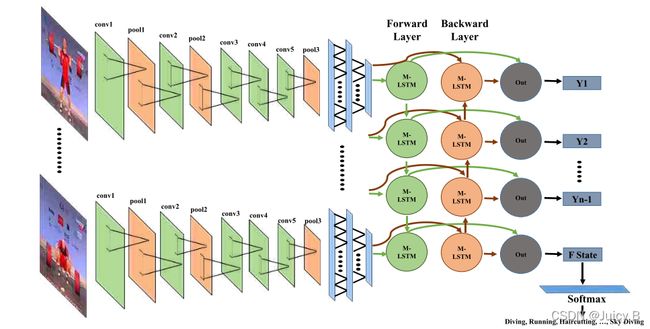
通过使用卷积神经网络 (CNN) 和深度双向 LSTM (DB-LSTM) 网络处理视频数据,提出了一种新的动作识别方法。
- 从视频的每六帧中提取深度特征,这有助于减少冗余和复杂性。
- 接下来,使用 DB-LSTM 网络学习帧特征之间的顺序信息,其中在 DB-LSTM 的前向传递和后向传递中将多个层堆叠在一起以增加其深度。
所提出的方法能够学习长期序列,并且可以通过分析特定时间间隔的特征来处理冗长的视频。
论文:Ullah, Amin; Ahmad, Jamil; Muhammad, Khan; Sajjad, Muhammad; Baik, Sung Wook (2018): Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features.
In IEEE Access 6, pp. 1155–1166.
DOI: 10.1109/ACCESS.2017.2778011.
推荐文献(有开源代码的)
-
ON-LSTM
- 简介: 设计了一个特殊的 LSTM 结构 ON-LSTM,使得模型可以将句子的层级结构给编码进去,从而增强了 LSTM 的表达能力。这篇论文也是 ICLR2019 的最佳论文。
- 论文: Shen, Yikang; Tan, Shawn; Sordoni, Alessandro; Courville, Aaron (2018): Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks. Available online at http://arxiv.org/pdf/1810.09536v6.
- 代码: https://github.com/bojone/on-lstm
-
LRCNs
- 简介: 将 CNN 与 LSTM 结合, 提出了一种新的架构 LRCNs, 用于活动识别、图像字幕生成和视频描述。
- 论文: Donahue, Jeff; Hendricks, Lisa Anne; Rohrbach, Marcus; Venugopalan, Subhashini; Guadarrama, Sergio; Saenko, Kate; Darrell, Trevor (2017): Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In IEEE transactions on pattern analysis and machine intelligence 39 (4), pp.ă677–691. DOI:10.1109/TPAMI.2016.2599174.
- 代码: https://github.com/MRzzm/action-recognition-models-pytorch
-
Lattice LSTM
- 简介: 使用 Lattice-LSTM 完成中文命名实体识别任务。
- 论文: Zhang, Yue, and Jie Yang. “Chinese NER Using Lattice LSTM.”Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), vol. 1, 2018, pp. 1554–1564.
- 代码: https://github.com/jiesutd/LatticeLSTM
-
Convolutional LSTM
- 简介: 首次提出了 ConvLSTM,这种结构非常擅长捕捉空间关系,对时空序列预测的研究起到了非常关键的作用。该论文被引量高达三千多。
- 论文: Shi, Xingjian, et al. “Convolutional LSTM Network: A Machine Learning Approach for Precipitation
Nowcasting.”NIPS’15 Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, vol. 28, 2015, pp. 802–810. - 代码 (TensorFlow): https://github.com/loliverhennigh/Convolutional-LSTM-in-Tensorflow
- 代码 (Torch): https://github.com/viorik/ConvLSTM
其他比较新的推荐的LSTM相关文献
- Chanti, Dawood Al; Duque, Vanessa Gonzalez; Crouzier, Marion; Nordez, Antoine; Lacourpaille, Lilian; Mateus, Diana (2021): IFSS-Net: Interactive Few-Shot Siamese Network for Faster Muscle Segmentation and Propagation in Volumetric Ultrasound. In IEEE Trans. Med. Imaging, p.ă1. DOI: 10.1109/TMI.2021.3058303.
- Pradhan, Tribikram; Kumar, Prashant; Pal, Sukomal (2021): CLAVER: An integrated framework of convolutional layer,bidirectional LSTM with attention mechanism based scholarly venue recommendation. In Information Sciences 559,pp.ă212235.DOI:10.1016/j.ins.2020.12.024. Location 1: Pradhan, Kumar et al 2021 - CLAVER An integrated framework.pdf
- Zhang, He; Nan, Zhixiong; Yang, Tao; Liu, Yifan; Zheng, Nanning (2021): A Driving Behavior Recognition Model with Bi-LSTM and Multi-Scale CNN. Available online at http://arxiv.org/pdf/2103.00801v1.
- Li, Fa; Gui, Zhipeng; Zhang, Zhaoyu; Peng, Dehua; Tian, Siyu; Yuan, Kunxiaojia et al. (2020): A hierarchical temporal attention-based LSTM encoder-decoder model for individual mobility prediction. In Neurocomputing 403, pp.ă153–166.DOI: 10.1016/j.neucom.2020.03.080.
- Lin, Zhihui; Li, Maomao; Zheng, Zhuobin; Cheng, Yangyang; Yuan, Chun (2020): Self-Attention ConvLSTM for Spatiotemporal Prediction. In AAAI 34 (07), pp.ă11531–11538. DOI: 10.1609/aaai.v34i07.6819.
- Wu, Xinyi; Wu, Zhenyao; Zhang, Jinglin; Ju, Lili; Wang, Song (2020): SalSAC: A Video Saliency Prediction Model with Shuffled Attentions and Correlation-Based ConvLSTM. In AAAI 34 (07), pp.ă12410–12417. DOI:
10.1609/aaai.v34i07.6927. - Liu, Gang; Guo, Jiabao (2019): Bidirectional LSTM with attention mechanism and convolutional layer for text
classification. In Neurocomputing 337, pp.ă325–338. DOI: 10.1016/j.neucom.2019.01.078. - Azad, Reza; Asadi-Aghbolaghi, Maryam; Fathy, Mahmood; Escalera, Sergio (2019): Bi-Directional ConvLSTM U-Net with Densley Connected Convolutions. Available online at http://arxiv.org/pdf/1909.00166v1.