大数据学习路线
一,题记
要说当下IT行业什么最火?ABC无出其右。所谓ABC者,AI + Big Data + Cloud也,即人工智能、大数据和云计算(云平台)。每个领域目前都有行业领袖在引领前行,今天我们来讨论下大数据Big Data这个方向。
二,大数据里面的角色
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙: 740041381,即可免费领取套系统的大数据学习教程
角色一:大数据工程
大数据工程需要解决数据的定义、收集、计算与保存的工作,因此大数据工程师们在设计和部署这样的系统时首要考虑的是数据高可用的问题,即大数据工程系统需要实时地为下游业务系统或分析系统提供数据服务;
角色二:大数据分析
大数据分析角色定位于如何利用数据——即从大数据工程系统中接收到数据之后如何为企业或组织提供有产出的数据分析,并且确实能够帮助到公司进行业务改善或提升服务水平,所以对于大数据分析师来说,他们首要解决的问题是发现并利用数据的价值,具体可能包括:趋势分析、模型建立以及预测分析等。
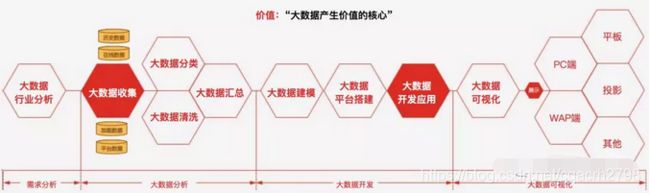
这两类角色相互依存但又独立运作,何意?没有大数据工程,大数据分析便无从谈起;但倘若没有大数据分析,我也实在想不出大数据工程存在的理由。这就类似于结婚和谈恋爱——恋爱的目的是为了结婚,且不以结婚为目的的谈恋爱都是耍流氓。
简单总结一下,大数据工程角色需要考虑数据的收集、计算(或是处理)和保存;大数据分析角色则是执行数据的高级计算。
三,大数据工程师
针对角色一:大数据工程说,对应的工作岗位就叫大数据工程师,对于大数据工程师而言,您至少要掌握以下技能:
linux基础
因为大数据体系,基本都是开源软件,这些开源软件都是在开源的linux系统上运行的,所以你必须会基本的linux操作,比如用户管理,权限,shell编程之类的
一门JVM系语言:
当前大数据生态JVM系语言类的比重极大,某种程度上说是垄断也不为过。这里我推荐大家学习Java或Scala,至于Clojure这样的语言上手不易,其实并不推荐大家使用。另外,如今是“母以子贵”的年代,某个大数据框架会带火它的编程语言的流行,比如Docker之于Go、Kafka之于Scala。
因此笔者这里建议您至少要精通一门JVM系的语言。值得一提的,一定要弄懂这门语言的多线程模型和内存模型,很多大数据框架的处理模式其实在语言层面和多线程处理模型是类似的,只是大数据框架把它们引申到了多机分布式这个层面。
笔者建议:学习Java或Scala
计算处理框架:
严格来说,这分为离线批处理和流式处理。流式处理是未来的趋势,建议大家一定要去学习;而离线批处理其实已经快过时了,它的分批处理思想无法处理无穷数据集,因此其适用范围日益缩小。事实上,Google已经在公司内部正式废弃了以MapReduce为代表的离线处理。
因此如果要学习大数据工程,掌握一门实时流式处理框架是必须的。当下主流的框架包括:Apache Samza, Apache Storm, Apache Spark Streaming以及最近一年风头正劲的Apache Flink。当然Apache Kafka也推出了它自己的流式处理框架:Kafka Streams
笔者建议:学习Flink、Spark Streaming或Kafka Streams中的一个
熟读Google大神的这篇文章:《The world beyond batch: Streaming 101》,地址是https://www.oreilly.com/ideas/th ... batch-streaming-101
分布式存储框架:
虽说MapReduce有些过时了,但Hadoop的另一个基石HDFS依然坚挺,并且是开源社区最受欢迎的分布式存储,绝对您花时间去学习。如果想深入研究的话,Google的GFS论文也是一定要读的([url=]https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf[/url])。当然开源世界中还有很多的分布式存储,国内阿里巴巴的OceanBase也是很优秀的一个。
笔者建议:学习HDFS
资源调度框架:
Docker可是整整火了最近一两年。各个公司都在发力基于Docker的容器解决方案,最有名的开源容器调度框架就是K8S了,但同样著名的还有Hadoop的YARN和Apache Mesos。后两者不仅可以调度容器集群,还可以调度非容器集群,非常值得我们学习。
笔者建议:学习YARN
分布式协调框架:
有一些通用的功能在所有主流大数据分布式框架中都需要实现,比如服务发现、领导者选举、分布式锁、KV存储等。这些功能也就催生了分布式协调框架的发展。最古老也是最有名的当属Apache Zookeeper了,新一些的包括Consul,etcd等。学习大数据工程,分布式协调框架是不能不了解的, 某种程度上还要深入了解。
笔者建议:学习Zookeeper——太多大数据框架都需要它了,比如Kafka, Storm, HBase等
KV数据库:
典型的就是memcache和Redis了,特别是Redis简直是发展神速。其简洁的API设计和高性能的TPS日益得到广大用户的青睐。即使是不学习大数据,学学Redis都是大有裨益的。
笔者建议:学习Redis,如果C语言功底好的,最好熟读源码,反正源码也不多
列式存储数据库:
笔者曾经花了很长的时间学习Oracle,但不得不承认当下关系型数据库已经慢慢地淡出了人们的视野,有太多的方案可以替代rdbms了。人们针对行式存储不适用于大数据ad-hoc查询这种弊端开发出了列式存储,典型的列式存储数据库就是开源社区的HBASE。实际上列式存储的概念也是出自Google的一篇论文:Google BigTable,有兴趣的话大家最好读一下:[url=]https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf[/url]
笔者建议:学习HBASE,这是目前应用最广泛的开源列式存储
消息队列:
大数据工程处理中消息队列作为“削峰填谷”的主力系统是必不可少的,当前该领域内的解决方案有很多,包括ActiveMQ,Kafka等。国内阿里也开源了RocketMQ。这其中的翘楚当属Apache Kafka了。Kafka的很多设计思想都特别契合分布流式数据处理的设计理念。这也难怪,Kafka的原作者Jay Kreps可是当今实时流式处理方面的顶级大神。
笔者建议:学习Kafka,不仅仅好找工作(几乎所有大数据招聘简历都要求会Kafka:-) ),还能触类旁通进一步理解基于备份日志方式的数据处理范型
四,大数据分析师Or数据科学家
针对角色二:大数据分析,对应的工作岗位就叫大数据分析师或者数据科学家,作为数据科学家的我们必须要掌握以下技能:
数学功底:
微积分是严格要掌握的。不一定要掌握多元微积分,但一元微积分是必须要熟练掌握并使用的。另外线性代数一定要精通,特别是矩阵的运算、向量空间、秩等概念。当前机器学习框架中很多计算都需要用到矩阵的乘法、转置或是求逆。虽然很多框架都直接提供了这样的工具,但我们至少要了解内部的原型原理,比如如何高效判断一个矩阵是否存在逆矩阵并如何计算等。
重温同济版《高等数学》,有条件可以去Coursea学习宾夕法尼亚大学的微积分课程
推荐学习Strang的线性代数:《Introduction to Linear Algebra》——这是最经典的教材,没有之一!
数理统计:
概率论和各种统计学方法要做到基本掌握,比如贝叶斯概率如何计算?概率分布是怎么回事?虽不要求精通,但对相关背景和术语一定要了解
找一本《概率论》重新学习下
交互式数据分析框架:
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙: 740041381,即可免费领取套系统的大数据学习教程
这里并不是指SQL或数据库查询,而是像Apache Hive或Apache Kylin这样的分析交互框架。开源社区中有很多这样类似的框架,可以使用传统的数据分析方式对大数据进行数据分析或数据挖掘。
笔者有过使用经验的是Hive和Kylin。不过Hive特别是Hive1是基于MapReduce的,性能并非特别出色,而Kylin采用数据立方体的概念结合星型模型,可以做到很低延时的分析速度,况且Kylin是第一个研发团队主力是中国人的Apache孵化项目,因此日益受到广泛的关注。
首先学习Hive,有时间的话了解一下Kylin以及背后的数据挖掘思想。
机器学习框架:
机器学习当前真是火爆宇宙了,人人都提机器学习和AI,但笔者一直认为机器学习恰似几年前的云计算一样,目前虽然火爆,但没有实际的落地项目,可能还需要几年的时间才能逐渐成熟。
不过在现在就开始储备机器学习的知识总是没有坏处的。说到机器学习的框架,大家耳熟能详的有很多种, 信手拈来的就包括TensorFlow、Caffe8、Keras9、CNTK10、Torch711等,其中又以TensorFlow领衔。
笔者当前建议大家选取其中的一个框架进行学习,但以我对这些框架的了解,这些框架大多很方便地封装了各种机器学习算法提供给用户使用,但对于底层算法的了解其实并没有太多可学习之处。因此笔者还是建议可以从机器学习算法的原理来进行学习,比如:
目前机器学习领域最NB的入门课程:吴恩达博士的Machine Learning

五,大数据必备技能详细
因为笔者本身是偏Java应用方向的,所以整理的大数据必备技能详细,也是偏向于大数据工程师方向。总共分为五大部分,分别是:
-
大数据技术基础
-
离线计算Hadoop
-
流式计算Storm
-
内存计算Spark
-
机器学习算法
大数据技术基础
linux操作基础
-
linux系统简介与安装
-
linux常用命令–文件操作
-
linux常用命令–用户管理与权限
-
linux常用命令–系统管理
-
linux常用命令–免密登陆配置与网络管理
-
linux上常用软件安装
-
linux本地yum源配置及yum软件安装
-
linux防火墙配置
-
linux高级文本处理命令cut、sed、awk
-
linux定时任务crontab
shell编程
-
shell编程–基本语法
-
shell编程–流程控制
-
shell编程–函数
-
shell编程–综合案例–自动化部署脚本
内存数据库redis
-
redis和nosql简介
-
redis客户端连接
-
redis的string类型数据结构操作及应用-对象缓存
-
redis的list类型数据结构操作及应用案例-任务调度队列
-
redis的hash及set数据结构操作及应用案例-购物车
-
redis的sortedset数据结构操作及应用案例-排行榜
布式协调服务zookeeper
-
zookeeper简介及应用场景
-
zookeeper集群安装部署
-
zookeeper的数据节点与命令行操作
-
zookeeper的java客户端基本操作及事件监听
-
zookeeper核心机制及数据节点
-
zookeeper应用案例–分布式共享资源锁
-
zookeeper应用案例–服务器上下线动态感知
-
zookeeper的数据一致性原理及leader选举机制
java高级特性增强
-
Java多线程基本知识
-
Java同步关键词详解
-
java并发包线程池及在开源软件中的应用
-
Java并发包消息队里及在开源软件中的应用
-
Java JMS技术
-
Java动态代理反射
轻量级RPC框架开发
-
RPC原理学习
-
Nio原理学习
-
Netty常用API学习
-
轻量级RPC框架需求分析及原理分析
-
轻量级RPC框架开发
离线计算Hadoop
hadoop快速入门
-
hadoop背景介绍
-
分布式系统概述
-
离线数据分析流程介绍
-
集群搭建
-
集群使用初步
HDFS增强
-
HDFS的概念和特性
-
HDFS的shell(命令行客户端)操作
-
HDFS的工作机制
-
NAMENODE的工作机制
-
java的api操作
-
案例1:开发shell采集脚本
MAPREDUCE详解
-
自定义hadoop的RPC框架
-
Mapreduce编程规范及示例编写
-
Mapreduce程序运行模式及debug方法
-
mapreduce程序运行模式的内在机理
-
mapreduce运算框架的主体工作流程
-
自定义对象的序列化方法
-
MapReduce编程案例
MAPREDUCE增强
-
Mapreduce排序
-
自定义partitioner
-
Mapreduce的combiner
-
mapreduce工作机制详解
MAPREDUCE实战
-
maptask并行度机制-文件切片
-
maptask并行度设置
-
倒排索引
-
共同好友
federation介绍和hive使用
-
Hadoop的HA机制
-
HA集群的安装部署
-
集群运维测试之Datanode动态上下线
-
集群运维测试之Namenode状态切换管理
-
集群运维测试之数据块的balance
-
HA下HDFS-API变化
-
hive简介
-
hive架构
-
hive安装部署
-
hvie初使用
hive增强和flume介绍
-
HQL-DDL基本语法
-
HQL-DML基本语法
-
HIVE的join
-
HIVE 参数配置
-
HIVE 自定义函数和Transform
-
HIVE 执行HQL的实例分析
-
HIVE最佳实践注意点
-
HIVE优化策略
-
HIVE实战案例
-
Flume介绍
-
Flume的安装部署
-
案例:采集目录到HDFS
-
案例:采集文件到HDFS
流式计算Storm
Storm从入门到精通
-
Storm是什么
-
Storm架构分析
-
Storm架构分析
-
Storm编程模型、Tuple源码、并发度分析
-
Storm WordCount案例及常用Api分析
-
Storm集群部署实战
-
Storm+Kafka+Redis业务指标计算
-
Storm源码下载编译
-
Strom集群启动及源码分析
-
Storm任务提交及源码分析
-
Storm数据发送流程分析
-
Storm通信机制分析
-
Storm消息容错机制及源码分析
-
Storm多stream项目分析
-
编写自己的流式任务执行框架
Storm上下游及架构集成
-
消息队列是什么
-
Kakfa核心组件
-
Kafka集群部署实战及常用命令
-
Kafka配置文件梳理
-
Kakfa JavaApi学习
-
Kafka文件存储机制分析
-
Redis基础及单机环境部署
-
Redis数据结构及典型案例
-
Flume快速入门
-
Flume+Kafka+Storm+Redis整合
内存计算Spark
scala编程
-
scala编程介绍
-
scala相关软件安装
-
scala基础语法
-
scala方法和函数
-
scala函数式编程特点
-
scala数组和集合
-
scala编程练习(单机版WordCount)
-
scala面向对象
-
scala模式匹配
-
actor编程介绍
-
option和偏函数
-
实战:actor的并发WordCount
-
柯里化
-
隐式转换
AKKA与RPC
-
Akka并发编程框架
-
实战:RPC编程实战
Spark快速入门
-
spark介绍
-
spark环境搭建
-
RDD简介
-
RDD的转换和动作
-
实战:RDD综合练习
-
RDD高级算子
-
自定义Partitioner
-
实战:网站访问次数
-
广播变量
-
实战:根据IP计算归属地
-
自定义排序
-
利用JDBC RDD实现数据导入导出
-
WorldCount执行流程详解
RDD详解
-
RDD依赖关系
-
RDD缓存机制
-
RDD的Checkpoint检查点机制
-
Spark任务执行过程分析
-
RDD的Stage划分
Spark-Sql应用
-
Spark-SQL
-
Spark结合Hive
-
DataFrame
-
实战:Spark-SQL和DataFrame案例
SparkStreaming应用实战
-
Spark-Streaming简介
-
Spark-Streaming编程
-
实战:StageFulWordCount
-
Flume结合Spark Streaming
-
Kafka结合Spark Streaming
-
窗口函数
-
ELK技术栈介绍
-
ElasticSearch安装和使用
-
Storm架构分析
-
Storm编程模型、Tuple源码、并发度分析
-
Storm WordCount案例及常用Api分析
Spark核心源码解析
-
Spark源码编译
-
Spark远程debug
-
Spark任务提交行流程源码分析
-
Spark通信流程源码分析
-
SparkContext创建过程源码分析
-
DriverActor和ClientActor通信过程源码分析
-
Worker启动Executor过程源码分析
-
Executor向DriverActor注册过程源码分析
-
Executor向Driver注册过程源码分析
-
DAGScheduler和TaskScheduler源码分析
-
Shuffle过程源码分析
-
Task执行过程源码分析
机器学习算法
python及numpy库
-
机器学习简介
-
机器学习与python
-
python语言–快速入门
-
python语言–数据类型详解
-
python语言–流程控制语句
-
python语言–函数使用
-
python语言–模块和包
-
phthon语言–面向对象
-
python机器学习算法库–numpy
-
机器学习必备数学知识–概率论
常用算法实现
-
knn分类算法–算法原理
-
knn分类算法–代码实现
-
knn分类算法–手写字识别案例
-
lineage回归分类算法–算法原理
-
lineage回归分类算法–算法实现及demo
-
朴素贝叶斯分类算法–算法原理
-
朴素贝叶斯分类算法–算法实现
-
朴素贝叶斯分类算法–垃圾邮件识别应用案例
-
kmeans聚类算法–算法原理
-
kmeans聚类算法–算法实现
-
kmeans聚类算法–地理位置聚类应用
-
决策树分类算法–算法原理
-
决策树分类算法–算法实现