卷积网络重新反超 Transformer,ConvNeXt:A ConvNet for the 2020s
A ConvNet for the 2020s
Paper: https://arxiv.org/pdf/2201.03545.pdf
Code: https://github.com/facebookresearch/ConvNeXt
本文的主要思想是,将 Swin-Transformer 中使用的方方面面的技术使用在传统 ConvNet 上,来探讨这些技术是否能够在 ConvNet 上 work。结果发现是肯定的。
目录
Abstract
1. 背景介绍
2. ConvNeXt 设计思路
2.1 Training Techniques 训练技术
2.2. Macro Design: 宏观设计
2.3. ResNeXt-ify:ResNeXt 化设计
2.4. Inverted Bottleneck:逆瓶颈
2.5. Large Kernel Sizes:大卷积核
2.6. Micro Design:微观设计
Abstract
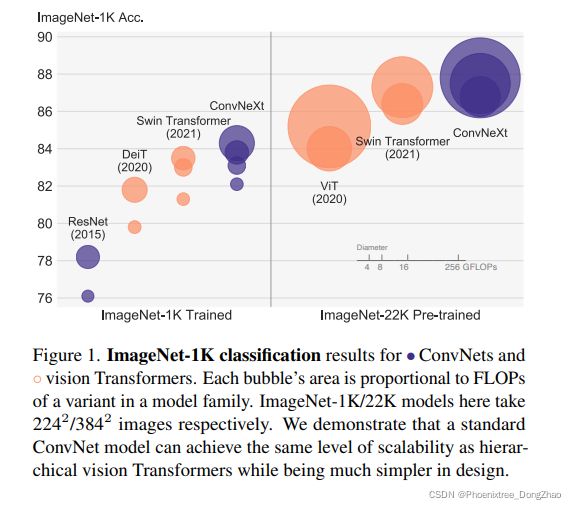
The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
背景:视觉识别的 “咆哮的20年代” 始于 Vision Transformer (ViTs) 的引入,它很快取代了卷积神经网络(ConvNets),成为最先进的图像分类模型。另一方面,普通的 ViT 在应用于一般的计算机视觉任务 (如对象检测和语义分割) 时面临困难。正是分层的 Transformer (例如 Swin Transformer ) 重新引入了几个 ConvNet 先验,使得 Transformer 实际上可以作为通用的视觉主干,并在各种各样的视觉任务中表现出显著的性能。然而,这种混合方法的有效性在很大程度上仍然归功于 Transformer 的内在优势,而不是卷积的固有归纳偏差。
方法:本文重新审视了设计空间,并测试了纯粹的 “卷积神经网络” 所能达到的极限。本文逐渐将标准ResNet “现代化”,以实现 Transformer 的设计,并发现了几个关键的组件,这些组件有助于实现性能差异。这一探索的结果是一系列被称为 ConvNeXt 的纯 ConvNet 模型。
性能:完全由标准 ConvNet 模块构建,ConvNeXts 在准确性和可扩展性方面优于 Transformer ,实现了 87.8% 的 ImageNet 准确度,在 COCO 检测和 ADE20K 分割方面优于 Swin transformer,同时保持了标准 ConvNet 的简单性和效率。
1. 背景介绍
本文的 Introduction 非常清晰的描述了这几年,CNN 和 Transformer 的发展过程和相互关系,并描述了作者的心路历程。
Introduction
回顾 21 世纪 10 年代,深度学习取得了巨大的进步,产生了巨大的影响。主要的驱动力是神经网络的复兴,特别是卷积神经网络 (ConvNets)。十年来,视觉识别领域成功地从工程特征转变为设计 (ConvNet) 架构。尽管反向传播训练卷积神经网络的发明可以追溯到 20 世纪 80 年代的 [ Yann LeCun, et al. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989 ],但直到 2012 年底,才看到它的真正的视觉功能学习潜力。AlexNet 的推出促成了 “ImageNet时刻” 的诞生,开启了计算机视觉的新时代。自那以后,这一领域的发展速度很快。典型的卷积神经网络如 VGGNet [61],Inception [64]、ResNe(X)t [26,82]、DenseNet [33]、MobileNet [32]、EfficientNet [67] 和 RegNet [51],这些工作分别关注准确性、效率和可伸缩性的不同方面,并推广了许多有用的设计原则。
ConvNets 在计算机视觉中的完全主导地位并非巧合:在许多应用场景中,滑动窗口策略是视觉处理的固有特性,特别是在处理高分辨率图像时。卷积神经网络有几个内置的归纳偏差,使其非常适合各种计算机视觉应用。最重要的一个是 translation equivariance,这对于一些视觉任务来说是一个理想的性质,如目标检测。卷积神经网络本身也是高效的,因为当以滑动窗口的方式使用时,计算是共享的。几十年来,这一直是卷积神经网络的默认使用,通常用于有限的对象类别,如数字、人脸和行人。进入 2010 年代,基于区域的探测器(region-based detectors,如 Fast R-CNN,Mask R-CNN)进一步证明了卷积神经网络已经成为视觉识别系统的基本组成部分。
大约在同一时间,为自然语言处理 (NLP) 设计神经网络的漫长历程走上了一条截然不同的道路,Transformer 取代了循环神经网络,成为了主导的 backbone。尽管语言和视觉领域在兴趣任务上存在差异,但随着 vision transformer (ViT) 的引入,这两种潮流在 2020 年出人意料地融合在一起,完全改变了网络架构设计的格局。除了最初的 “patchify” 层,它将图像分割成一系列的 patch, ViT 没有引入图像特异性的感应偏差,并且对原始的 NLP transformer 进行了最小的改变。ViT 的一个主要关注点是 scaling 行为:在更大模型和数据集尺寸的帮助下,transformer 可以显著超过标准ResNets。这些图像分类任务的结果是鼓舞人心的,但计算机视觉并不局限于图像分类。正如前面所讨论的,在过去的十年中,许多计算机视觉任务的解决方案很大程度上依赖于滑动窗口、全卷积范式。由于没有 ConvNet 的归纳性偏见,普通的 ViT 模型在被采用为通用视觉主干时面临许多挑战。最大的挑战是 ViT 的全局注意力设计,它与输入大小相比具有二次复杂度。这对于 ImageNet 分类可能是可以接受的,但是对于高分辨率的输入很快就变得难以处理。
Hierarchical Transformers 采用了一种混合方法来弥补这一差距。例如,滑动窗口策略 (例如在局部窗口内的注意力) 被重新引入到 transformer 中,使得它们的行为更类似于 ConvNets。Swin Transformer[42] 是这一方向上的里程碑式工作,首次证明 Transformer 可以作为通用的视觉 backbone,并在图像分类之外的一系列计算机视觉任务中实现最先进的性能。Swin Transformer的成功和迅速采用也揭示了一件事:卷积的本质并没有变得无关紧要; 相反,它仍然很受欢迎,从未退出历史。
从这个角度来看,Transformer 在计算机视觉方面的许多进步都旨在恢复卷积。然而,这些尝试是有代价的:滑动窗口自注意的简单实现可能是计算量大的;采用循环变速 [42] 等先进方法,可以优化速度,但系统在设计上变得更加复杂。另一方面,具有讽刺意味的是,卷积神经网络已经满足了许多这些期望的性质,尽管是以一种简单、无多余的方式。ConvNets 似乎失去动力的唯一原因是(分级) transformer 在许多视觉任务上超过了它们,而性能差异通常归因于 transformer 的卓越 scaling 行为,其中多头自注意是关键的组成部分。
与过去十年中逐步改进的 ConvNets 不同,Vision transformer 的采用是一个阶段性的改变。在最近的文献中,比较两者时通常采用系统级的比较 (例如,Swin Transformer 和 ResNet)。卷积神经网络 (ConvNets) 和分层视觉 transformer (hierarchical vision transformer) 在不同的同时也变得相似:它们都具有相似的归纳偏差,但在训练过程和宏观/微观层次架构设计上存在显著差异。在本研究中,研究了卷积神经网络和变形神经网络的架构区别,并尝试在比较网络性能时识别混淆变量。本文的研究旨在弥补前 ViT 和后 ViT 时代卷积神经网络之间的差距,并测试纯卷积神经网络能够达到的极限。
为了做到这一点,本文从标准 ResNet (如 ResNet50) 开始,训练一个改进的程序。本文逐步将架构现代化,以构建一个分层的视觉 Transformer (例如 Swin-T)。本文的探索是由一个关键问题指导的:Transformer 中的设计决策如何影响卷积神经网络的性能? 在此过程中,本文发现了导致性能差异的几个关键因素。因此,本文提出了一组称为 ConvNeXt 的纯 ConvNets。本文评估了 ConvNeXts 在各种视觉任务上的表现,如 ImageNet 分类、在COCO 上的对象检测/分割以及在 ADE20K 上的语义分割。令人惊讶的是,完全由标准 ConvNet 模块构建的 ConvNeXts,在所有主要基准上的准确性、可伸缩性和鲁棒性都优于 transformer。ConvNeXt 保持了标准 ConvNets 的效率,而且训练和测试都是完全卷积的,这使得它的实现非常简单。
本文的观察和讨论能够挑战一些普遍的信念,并鼓励人们重新思考卷积在计算机视觉中的重要性。
2. ConvNeXt 设计思路
本文最原始的动机,是为了探索和研究一种结构,这种结构能够遵循 Swin Transformer 的不同层次的设计,同时保持网络作为标准 ConvNet 的简单性。
为此,作者的起点是 ResNet-50 模型。
首先, 在训练 vision Transformers 相同的训练技术上训练 ResNet-50。注意,这里的 ‘训练技术’ (Training Techniques) 与原始 ResNet-50 论文提出的训练技术是不同的。作者发现,新训练的结果要比原先的结果要好很多。
因此,作者以这个新的训练技术为 baseline,又训练了 5 种设计理念,总结为:
1) macro design, # 宏观设计
2) ResNeXt,
3) inverted bottleneck, # 逆瓶颈 (ResNet 的瓶颈结构中,通道数在中间层会缩小,而逆瓶颈指的是通道数在中间层增多,就像 Transformer 中的 MLP 一样)
4) large kernel size, # 大卷积核
5) various layer-wise micro designs # 微观设计
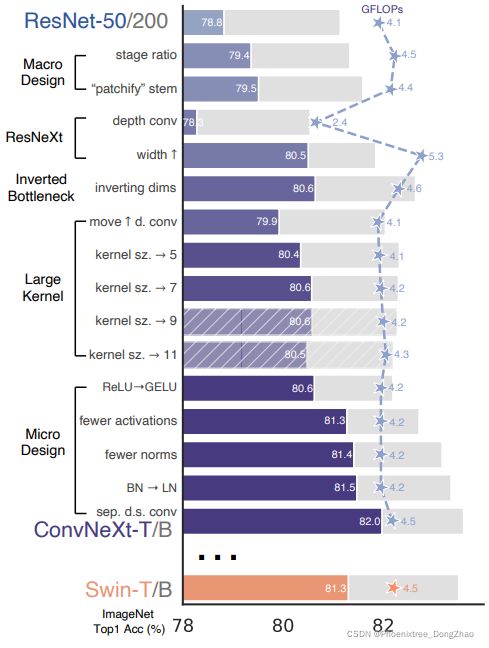
下图 2 展示了作者研究过程,每个步骤所能实现的过程和结果。
由于网络复杂性与最终性能密切相关,在上述的研究探索过程中,每种模型的 FLOPs 尽可能保持一致,尽管在中间步骤中 FLOPs 可能高于或低于参考模型。
上述所有的模型都在 ImageNet-1K 上进行训练和评估。
Figure 2. We modernize a standard ConvNet (ResNet) towards the design of a hierarchical vision Transformer (Swin), without introducing any attention-based modules. The foreground bars are model accuracies in the ResNet-50/Swin-T FLOP regime; results for the ResNet-200/Swin-B regime are shown with the gray bars. A hatched bar means the modification is not adopted. Detailed results for both regimes are in the appendix. Many Transformer architectural choices can be incorporated in a ConvNet, and they lead to increasingly better performance. In the end, our pure ConvNet model, named ConvNeXt, can outperform the Swin Transformer.
下面介绍本工作中, Training Techniques 以及上述 5 个设计理念。
2.1 Training Techniques 训练技术
除了网络架构的设计,训练过程也会影响最终性能。
Vision Transformers 不仅带来了一套新的模块和架构设计决策,而且在视觉应用中,引入了不同的训练技术 (如 AdamW 优化器) 。这主要涉及优化策略和相关的超参数设置。
因此,作者探索的第一步是用 vision Transformer 训练程序训练一个 baseline 模型,在本例中是ResNet50/200。
最近的一篇论文 [ResNet strikes back: An improved training procedure in timm] 阐述了一组现代训练技术如何显著提高简单 ResNet-50 模型的性能。
作者在本文使用了一个接近 DeiT [68] 和 Swin Transformer [42] 的训练方法,包括:
1. 训练 ResNets 从最初的 90 个 epoch 扩展到 300 个 epoch;
2. 训练过程使用 AdamW 优化器 [43];
3. 数据增强技术 (如 Mixup [85]、Cutmix [84]、RandAugment [12]、Random Erasing [86]) ;
4. 正则化方案 (包括 Random Depth [33] 和 Label Smoothing [65])。
【注】使用的整套超参数可以在原文的附录 A.1 中查看。
就其本身而言,这种增强训练方法将 ResNet-50 模型的性能从 76.1%[1] 提高到 78.8%(+2.7%),这意味着传统卷积神经网络和 vision Transformers 之间的性能差异很大一部分可能是由于训练技术。
在后面的整个研究过程中(作者称之为 “modernization” 过程),都将使用这个固定的训练配方,使用相同的超参数。ResNet-50 方法的每一个报告的准确性都是由三种不同的随机种子(random seeds)训练获得的平均值(我的理解是,由于 CNN 中参数的初始化对网络性能是有影响的,为了准确地、客观地说明每种改进技术和设计真正的作用,相同的实验做三次,结果取平均,这样更合理)。
2.2. Macro Design: 宏观设计
作者分析了 Swin transformer 的宏网络设计。Swin transformer 遵循 ConvNets [26,62],采用多阶段设计,其中每个阶段都有不同的特征图分辨率。在本宏观设计中,作者从两个有趣的设计考虑改进:stage compute ratio 和“stem cell” 结构。
1. Changing stage compute ratio
stage compute ratio 是指网络结构在每次下采样后 block 个数的比例。举个例子,原来的 ResNet-50 结构中,每次特征下采样后,ResNet block 的个数是 (3, 4, 6, 3)。
ResNet 中的这种跨阶段的计算分布最初的设计很大程度上是基于经验的。
在 Swin-T 中,也遵循了 stage 结构的原理,但阶段计算比例略有不同,为 1:1:3:1。对于更大的 Swin Transformer,比例是1:1:9:1。
本文提出的 ConvNeXts 将每个阶段的块数从 ResNet-50 中的 (3,4,6,3) 调整为 (3,3,9,s3),这也将FLOPs 与 Swin-T 对齐。
这个改进,将模型的精度从 78.8% 提高到 79.4%。
值得注意的是,研究人员已经对计算的分布进行了深入的研究 [50,51],可能存在更优化的设计。
本文后续的研究中,将使用 (3,3,9,s3) 这个阶段计算比率。
2. Changing stem to “Patchify”
stem cell 的设计,是考虑在网络开始时如何处理输入的图像。
在标准 ResNet 中,stem cell 包含一个 7×7 卷积层,stride 2,然后是一个最大池化层,其结果是输入图像的 向下采样 4 倍。
在 vision transformer 中,使用了一种更激进的 “patchify” 策略作为 stem cell,它对应于较大的核大小 (例如核大小= 14 或16) 和非重叠卷积。
Swin Transformer 使用了类似的 “patchify” 层,但 patch 的大小更小,为 4,以适应体系结构的多阶段设计。
本文提出的 ConvNeXts,将 ResNet 类型的 stem cell 替换为一个 “patchify” 层,该层使用 4×4, stride 4 卷积层实现。
这个改进,将网络的准确率从 79.4% 提高到 79.5%。
这表明 ResNet 中的 stem cell 可以被一个更简单的 “patchify” 层取代
本文后续的研究中,将使用 “patchify stem” (4×4 non-overlap convolution)。
2.3. ResNeXt-ify:ResNeXt 化设计
作者在这部分考虑了 ResNeXt 的思想,它比普通的 ResNet 相比,更好地平衡了 FLOPs 与准确性(FLOPs/accuracy trade-off)。
ResNeXt 的核心部分是分组卷积,其中卷积滤波器被分成不同的组,扩大宽度。更准确地说,ResNeXt 对瓶颈块中的 3x3 conv 层使用了分组卷积。因此,可以通过扩大网络宽度来弥补容量损失。
作者在提出的 ConvNeXts 使用深度卷积(Depth-wise Conv.),这是分组卷积的一种特殊情况,分组的数量等于通道的数量。Depth-wise conv 在 MobileNet [32] 和 Xception [9] 的工作中得到推广。
作者注意到,深度卷积类似于自注意力中的加权和操作,其操作基于每个通道,即只在空间维度上混合信息。
深度卷积的使用有效地减少了网络的 FLOPs ,但精度也减少了。
在 ResNeXt 中,为了弥补上述 depth-wise conv. 带来的精度降低,提出的策略是将原来的 ResNet 第一层通道数从 64 增加到 96。
为了弥补上述 depth-wise conv. 带来的精度降低问题,作者在提出的 ConvNeXts 中,网络宽度增加到与 Swi-T 相同,即通道数从 64 个增加到 96 个。
这使得网络性能达到 80.5%,FLOPs 增加 (5.3G)。
本文后续的研究中,将采用 ResNeXt 设计。
2.4. Inverted Bottleneck:逆瓶颈
在 Transformer block 中,一个重要的设计是在其中的 MLP block 中,使用了 Inverted Bottleneck,维度比输入扩大的 4 倍。
这种逆瓶颈的思路,是在 MobileNetV2 中提出的。这种结构的有效性在工作 [66,67] 中也得到了证实。
因此,作者在提出的 ConvNeXts 中使用了逆瓶颈的设计。
图 3 (a) 到 (b) 展示了这种结构。尽管深度卷积层的 FLOPs 增加了,但这一变化使整个网络 FLOPs 减少到 4.6G,因为下采样 residual blocks 的 shortcut 1×1 conv 层的 FLOPs 显著减少(图 3(b)紫色模块)。
这种改进,略微提高了网络性能 (从80.5%提高到80.6%)。
在 ResNet-200 / Swin-B 模式中,这一步带来了更多的收益 (81.9%至82.6%),同时也减少了 FLOPs。
本文后续的研究中,将采用逆瓶颈的设计。
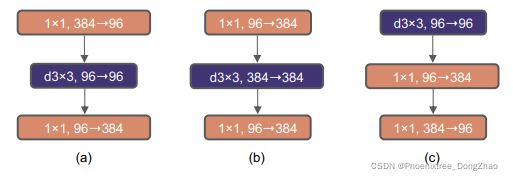
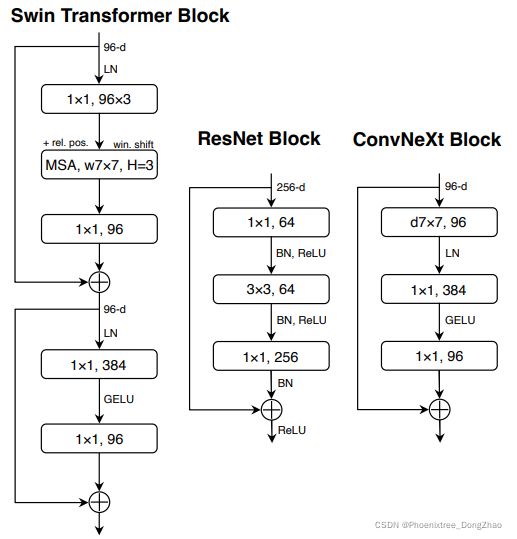
Figure 3. Block modifications and resulted specifications. (a) is a ResNeXt block; in (b) we create an inverted bottleneck block and in (c) the position of the spatial depthwise conv layer is moved up.
2.5. Large Kernel Sizes:大卷积核
作者继续将重点关注在卷积核的尺度上。Vision Transformers 最与众不同的一个方面是其非局部自注意力,这使得每一层都有一个全局的接收域。
虽然过去 ConvNets 已经使用了大的卷积核,但黄金标准 (由 VGGNet 推广的) 是堆叠 3x3 卷积核的卷积层,这在目前的 GPU 上具有高效的硬件实现。虽然 Swin transformer 重新将局部窗口引入到自注意力模块中,但窗口的大小至少是 7x7,明显大于 ResNe(X)t 的 3x3。
因此,作者在提出的 ConvNets 中使用大卷积核的卷积。具体地包括以下两个技术:
1. Moving up depthwise conv layer
使用大卷积核,作者首先上移了深度卷积层的位置,即从图 3 (b) 的位置,移到 (c)。
这种技术在 Transformer 中也很明显:多头注意力(MSA)模块被放置在 MLP 层之前。由于 ConvNeXts 有一个逆瓶颈模块,这自然的要求深度卷积层上移:因为,复杂、低效的模块 (如 MSA,大卷积核) 将有更少的通道,而高效、密集的 1×1 层将完成繁重的工作。
这个中间步骤将 FLOPs 降低到 4.1G,但导致性能暂时下降到 79.9%。
2. Increasing the kernel size
作者指出,采用更大的卷积核的好处是显著的。
实验包括 3、5、7、9 和 11 大小的卷积核。网络的性能从 79.9% (3x3) 提高到 80.6%(7x7),但网络的 FLOPs 基本保持不变。
此外,作者观察到较大卷积核的好处在 7x7 达到饱和点。
在大容量模型中验证了这一发现:当将卷积核大小增加到 7 时,ResNet-200 机制模型不会显示出进一步的增益。
本文后续的研究中,将采用 7x7 的深度卷积。
2.6. Micro Design:微观设计
本节将在微观尺度上研究其他几个架构差异。这些设计大多数都是在层级别上完成的,重点是激活函数和规范化层的特定选择。
1. Replacing ReLU with GELU
NL P和 视觉架构之间的一个差异是使用哪种激活函数的细节。
目前有许多激活函数,但 ReLU [46] 由于其简单和高效,仍然广泛应用于卷积神经网络。
在原 Transformer 论文中,ReLU 也被用作激活函数 [72]。
高斯误差线性单元,即 GELU [30],可以被认为是 ReLU 的平滑变体,在最新的 Transformer 结构中被使用,包括谷歌的 BERT [16] 和 OpenAI 的 GPT-2 [49],以及最近的 ViT。
作者发现,在ConvNet 中,ReLU 也可以被 GELU 代替,但精度没有变化 (80.6%)。
2. Fewer activation functions
Transformer 和 ResNet 块之间的一个小区别是 Transformer 有更少的激活功能。Transformer 包含一个具有 Q/K/V 的 linear embedding 层、projection 层 以及 MLP block 中有两个线性层。而 MLP block 中只有一个激活函数。
相比之下,ConvNets 通常是在每个卷积层后加一个激活函数,包括 1x1 卷积。
因此,作者尝试减少激活函数使用次数,观察其性能是如何变化的。
如图 4 所示,作者在提出的 ConvNeXts 中,复制了 Transformer block 中的样式,在 Residul block 中,除了两个 1x1 层之间保留了 GELU 层,其余层均消除了 GELU 层。
该改进方法将结果精度提高了0.7%,达到81.3%,与 Swin-T 的性能相当。
本文后续的研究中,将使用一个 GELU 激活。
3. Fewer normalization layers
Transformer blocks 通常也有较少的规范化层。
作者在提出的 ConvNeXts 中,去掉了两个 BatchNorm (BN) 层,在 conv 1 × 1 层之前只留下一个BN 层。
这进一步提升了其 81.4% 的精度,已经超过了 Swi-T。
值得注意的是,在 提出的 ConvNeXts 中每个 block 的规范化层甚至比 transformer 还要少,因为,作者发现在块的开始添加一个额外的 BN 层并不能改善性能。
4. Substituting BN with LN
BatchNorm [35] 是卷积神经网络的重要组成部分,因为它提高了收敛性并减少了过拟合。然而,BN 也有许多错综复杂的地方,会对模型的性能产生不利影响 [79]。一些工作曾多次尝试开发替代的标准化技术 [57,70,78],但 BN 仍然是大多数视觉任务的首选方法。
另一方面,在 transformer 中使用了更简单的 Layer Normalization [5] (LN),从而在不同的应用场景中获得了良好的性能。然而,直接用 LN 代替原来 ResNet 中的 BN 会导致性能下降 [78]。
但作者还是在提出的 ConvNeXts 中,用 LN 代替 BN。
作者观察到卷积神经网络模型在 LN 的训练中没有任何困难;实际上,该算法的性能略好,达到了81.5% 的精度(又提高了)。
本文后续的研究中,将使用一个 LayerNorm 作为每个 residual block 的规范化选择。
5. Separate downsampling layers
在 ResNet 中,空间下采样由每个 stage 开始时的 residual block 实现的,即使用 3×3 卷积,其中 stride=2 (在 short-cut 连接处使用 1×1 conv with stride 2)。
在 Swin transformer 中,在各个 stage 之间添加了一个单独的下采样层。
作者在提出的 ConvNeXts 中,使用 2×2 conv 层 with stride=2 进行空间下采样。
令人惊讶的是,这种改变会导致不同的训练。进一步的研究表明,在空间分辨率发生变化的地方增加归一化层有助于稳定训练。这包括几个也在 Swin transformer 中使用的 LN 层:一个是在每个下采样层之前,一个在 stem 之后,一个在最终的全局平均池之后。
这个方法可以将准确率提高到82.0%,显著超过 Swin-T 的 81.3%。
本文后续的研究中,将使用单独的下采样层。
至此, 完成了 ConvNeXt 的最终设计!
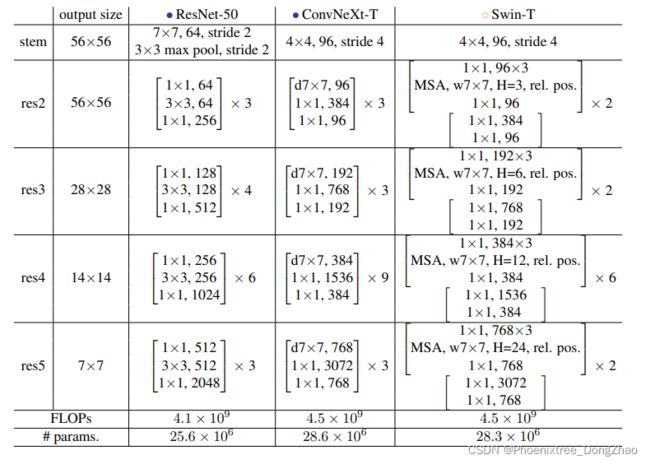
ResNet、Swin 和 ConvNeXt block 结构的比较如图 4 所示。ResNet-50、Swin-T 和 ConvNeXt-T 的详细架构规范的比较见表 9。
Figure 4. Block designs for a ResNet, a Swin Transformer, and a ConvNeXt. Swin Transformer’s block is more sophisticated due to the presence of multiple specialized modules and two residual connections. For simplicity, we note the linear layers in Transformer MLP blocks also as “1×1 convs” since they are equivalent.
Table 9. Detailed architecture specifications for ResNet-50, ConvNeXt-T and Swin-T.
6. Closing remarks 结束语
作者也指出,到目前为止讨论的设计选项都不是新颖的,它们都是单独研究的,但在过去的十年中没有集体研究。
作者提出的 ConvNeXt 模型与 Swin Transformer 有大致相同的 FLOPs, #params., throughput, 和 memory use,但不需要特殊的模块,如移动窗口注意力或相对位置偏差。
前面描述发现是令人鼓舞的,但尚未完全令人信服,作者认为自己的探索迄今为止仅限于小规模,但 vision transformer 的 scaling 行为是真正区别它和 ConvNet 的地方。
此外,卷积神经网络能否在诸如对象检测和语义分割等下游任务上与 Swin transformer 竞争,是计算机视觉从业者关注的中心问题。
因此,作者在实验部分,研究了在数据和模型大小方面扩大 ConvNeXt 模型,并在不同的视觉识别任务中评估它们。
实验部分此处略。