【GCN-RS】Deep GCN with Hybrid Normalization for Accurate and Diverse Recommendation (DLP-KDD‘21)
Deep Graph Convolutional Networks with Hybrid Normalization for Accurate and Diverse Recommendation (DLP-KDD’21)
一句话总结这篇文章就是在LR-GCCF和LightGCN的基础上,同时结合了 left normalization (给不同的邻居分配相等的归一化,PinSAGE)和 symmetric normalization (degree大的邻居分配小权重,LightCGN)。
Abstract
摘要完全概括了文章的内容:
现有的GCN RS模型在浅层就达到了最佳性能,这就没有用到高阶信号;现有的GCN模型对邻居信号聚合时,使用相同的归一化规则,要么PinSAGE那样同等重要,要么是LightGCN那样根据degree分配重要性。
但是同一套归一化规则肯定不能适配所有节点,所以提出了一个新的模型Deep Graph Convolutional Network with Hybrid Normalization (DGCN-HN)。
首先设计了一个residual connection 和 holistic connection**(LR-GCCF和LightGCN的混合版)**,以解决over-smoothing,可以训练深层GCN(8层)。
然后设计了hybrid normalization layer。通过一个简化的attention**(正常的attention没用)**实现hybrid 两种正则化。
实验结果还证明了这种做法有利于degree低的user。
Intro
又强调了一边现在的GCN RS都不深、使用了固定的归一化规则,使用相同的归一化规则会导致局部最优。
文章用一个例子解释了上述缺点:

- 浅层GCN不能利用高阶信号,给喜欢电子产品的U2推荐无人机就需要高阶信号。
- 给所有节点使用 left normalization ,流行度很高的IPhone就会严重影响U1的兴趣,U1买IPhone只是刚需,兴趣并不在电子产品,因为U1经常购买纸质文具。
- 给所有节点使用 symmetric normalization,流行度很高的IPhone就无法提供”电子产品“这一兴趣,U2和U3的兴趣就难以被刻画出来。
Model
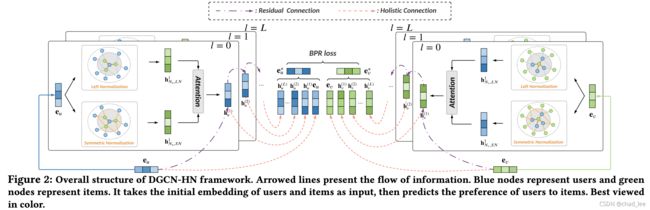
所谓Residual就是在LightGCN的基础上加一个Residual:
h u ( l + 1 ) = ∑ v ∈ N u A ~ u v h v ( l ) + h u ( l ) , h u ( 0 ) = e u h v ( l + 1 ) = ∑ u ∈ N v A ~ v u h u ( l ) + h v ( l ) , h v ( 0 ) = e v \begin{aligned} \mathbf{h}_{u}^{(l+1)} &=\sum_{v \in N_{u}} \tilde{\mathrm{A}}_{u v} \mathbf{h}_{v}^{(l)}+\mathbf{h}_{u}^{(l)}, \quad \mathbf{h}_{u}^{(0)}=\mathbf{e}_{u} \\ \mathbf{h}_{v}^{(l+1)} &=\sum_{u \in N_{v}} \tilde{\mathrm{A}}_{v u} \mathbf{h}_{u}^{(l)}+\mathbf{h}_{v}^{(l)}, \quad \mathbf{h}_{v}^{(0)}=\mathbf{e}_{v} \end{aligned} hu(l+1)hv(l+1)=v∈Nu∑A~uvhv(l)+hu(l),hu(0)=eu=u∈Nv∑A~vuhu(l)+hv(l),hv(0)=ev
A ~ u v \tilde{\mathrm{A}}_{u v} A~uv 是Hybrid Normalization,混合了left normalization 和 symmetric normalization。一个简单的想法肯定两种正则化平均嘛,那进一步的想法就是做一个加权平均,上Attention:
h N u , L N ( l + 1 ) = ∑ v ∈ N u 1 ∣ N u ∣ h v ( l ) h N u , S N ( l + 1 ) = ∑ v ∈ N u 1 ∣ N u ∣ ∣ N v ∣ h v ( l ) h u ( l + 1 ) = h u ( l ) + α u , L N ( l + 1 ) h N u , L N ( l + 1 ) + α u , S N ( l + 1 ) h N u , S N ( l + 1 ) \begin{aligned} \mathbf{h}_{N_{u}, L N}^{(l+1)} &=\sum_{v \in N_{u}} \frac{1}{\left|N_{u}\right|} \mathbf{h}_{v}^{(l)} \\ \mathbf{h}_{N_{u}, S N}^{(l+1)} &=\sum_{v \in N_{u}} \frac{1}{\sqrt{\left|N_{u}\right|} \sqrt{\left|N_{v}\right|}} \mathbf{h}_{v}^{(l)} \\ \mathbf{h}_{u}^{(l+1)} &=\mathbf{h}_{u}^{(l)}+\alpha_{u, L N}^{(l+1)} \mathbf{h}_{N_{u}, L N}^{(l+1)}+\alpha_{u, S N}^{(l+1)} \mathbf{h}_{N_{u}, S N}^{(l+1)} \end{aligned} hNu,LN(l+1)hNu,SN(l+1)hu(l+1)=v∈Nu∑∣Nu∣1hv(l)=v∈Nu∑∣Nu∣∣Nv∣1hv(l)=hu(l)+αu,LN(l+1)hNu,LN(l+1)+αu,SN(l+1)hNu,SN(l+1)
怎么算 Attention score?作者设计了一个Attention Layer:
z u , ∗ ( l + 1 ) = W 1 ( l ) σ ( W 2 ( l ) ( h N u , ∗ ( l + 1 ) + h N u , ∗ ( l + 1 ) ⊙ h u ( l ) ) ) z_{u, *}^{(l+1)}=\mathrm{W}_{1}^{(l)} \sigma\left(\mathrm{W}_{2}^{(l)}\left(\mathrm{h}_{N_{u}, *}^{(l+1)}+\mathrm{h}_{N_{u}, *}^{(l+1)} \odot \mathrm{h}_{u}^{(l)}\right)\right) zu,∗(l+1)=W1(l)σ(W2(l)(hNu,∗(l+1)+hNu,∗(l+1)⊙hu(l)))
结果实验上训不起来无法收敛,换了一个简单的:
z u , ∗ ( l + 1 ) = ave ( h N u , ∗ ( l + 1 ) + h N u , ∗ ( l + 1 ) ⊙ h u ( l ) ) z_{u, *}^{(l+1)}=\operatorname{ave}\left(\mathbf{h}_{N_{u}, *}^{(l+1)}+\mathbf{h}_{N_{u}, *}^{(l+1)} \odot \mathbf{h}_{u}^{(l)}\right) zu,∗(l+1)=ave(hNu,∗(l+1)+hNu,∗(l+1)⊙hu(l))
α u , ∗ ( l ) = exp ( z u , ∗ ( l ) ) ∑ k ∈ { L N , S N } exp ( z u , k ( l ) ) \alpha_{u, *}^{(l)}=\frac{\exp \left(z_{u, *}^{(l)}\right)}{\sum_{k \in\{L N, S N\}} \exp \left(z_{u, k}^{(l)}\right)} αu,∗(l)=∑k∈{LN,SN}exp(zu,k(l))exp(zu,∗(l))
Loss就是BPR loss,负采样比例1
实验结果

提出的模型可以训到八层:

从Recall上看left normalization 和 symmetric normalization结合起来性能最好:

文章从实验结果分析,对degree低的user提升更大:

我觉得是正常现象强行分析,因为degree低的user recall本来就低,基数小,所以显得提升大。