神经网络学习笔记与TensorFlow实现MLP
前馈神经网络
每一层的神经元只接受前一层神经元的输入,并且输出到下一层。
BP神经网络
一种按照误差逆向传播算法训练的多层前馈神经网络。BP即Back Propagation,就是常用的反向传播算法。
激活函数
激活函数是对输入做的一种非线性的转换。转换的结果输出,并当作下一个隐藏层的输入。激活函数又称为非线性映射函数,讲神经元的输入映射到输出。常用的激活函数包括:Sigmoid型函数、tanh(x)型函数、ReLU(修正线性单元)、Leaky ReLU、参数化ReLU、随机化ReLU和ELU(指数化线性单元)。
Softmax
通常被用在网络中的最后一层,用来进行最后的分类和归一化,Softmax 函数取任意实数向量作为输入,并将其压缩到数值在0到1之间,总和为1的向量。它的输出结果是每个类的概率,这些概率总和为1。
tanh

sigmoid

ReLU

Leaky ReLU
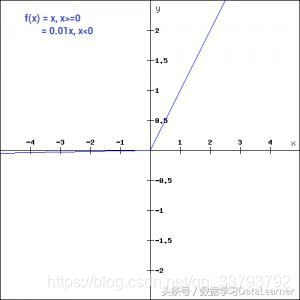
损失函数
常用的有:L1损失(偏差的绝对值)、L2损失(均方差损失)和交叉熵损失。
分类任务的损失函数包括:交叉熵损失函数、合页损失函数、坡道损失函数、大间隔交叉熵损失函数、中心损失函数。
回归任务的损失函数包括:L1损失函数、L2损失函数、Tukey’s biweight损失函数。
优化算法
常用的网络模型优化算法包括:随机梯度下降法、基于动量的随机梯度下降法、Nesterov型动量随机下降法、Adagrad法、Adadelta法、RMSProp法、Adam法。
超参
神经网络主要超参数包括:输入图像像素、学习率、正则化参数、神经网络层数、批处理大小、卷积层参数(卷积核大小、卷积操作步长、卷积核个数)、汇合层参数(汇合核大小、汇合步长)、目标函数、优化算法、激活函数、学习周期等。
多层感知机(MLP)
- 多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构。
- 多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
TensorFlow实现MLP
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 屏蔽警告日志
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 手写数字数据集
x_train, y_train = mnist.train.images, mnist.train.labels
x_test, y_test = mnist.test.images, mnist.test.labels
n_input, n_hidden, n_output = 784, 300, 10 # 各层的结点数目
samples = len(x_train) # 样本数
lr = tf.Variable(0.001, dtype=tf.float32) # 学习率
epochs = 20 # 迭代次数
batch_size = 100 # 批处理数量
# 定义占位符
x = tf.placeholder(dtype=tf.float32, shape=[None, n_input])
prob = tf.placeholder(dtype=tf.float32)
y = tf.placeholder(dtype=tf.float32, shape=[None, n_output])
# 输入层到隐层的权重与偏置
# 权重(输入层与隐层之间的连线),因为是全连接,所有有n_input * n_hidden条线
w1 = tf.Variable(tf.truncated_normal([n_input, n_hidden], stddev=0.1, dtype=tf.float32))
# 偏置,也是全连接的,但不与输入有关系,所以有n_hidden个(这个偏置要和隐层的每个节点连接)
b1 = tf.Variable(tf.zeros([n_hidden], dtype=tf.float32))
# 隐层,激活函数采用ReLU,为了防止过拟合采用了dropout正则化(它会以prob概率关闭神经元,即暂不更新)
hidden = tf.nn.dropout(tf.nn.relu(tf.add(tf.matmul(x, w1), b1)), prob)
# 隐层到输出层的权重与偏置
w2 = tf.Variable(tf.truncated_normal([n_hidden, n_output], stddev=0.1, dtype=tf.float32))
b2 = tf.Variable(tf.zeros([n_output], dtype=tf.float32))
# 输出层
out = tf.add(tf.matmul(hidden, w2), b2)
# 返回交叉熵(损失函数)
crossEntropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=out))
# 比SGD更快的Adam优化算法(迭代优化)
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(crossEntropy)
prediction = tf.equal(tf.argmax(y, 1), tf.argmax(out, 1)) # 是否预测准确
accuracy = tf.reduce_mean(tf.cast(prediction, dtype=tf.float32)) # 计算准确率
with tf.Session() as sess:
# tensor初始化
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(epochs):
avg_cost = 0.0
batches = int(samples / batch_size) # 总批次
for batch in range(batches): # 分批处理样本数据
batch_x, batch_y = mnist.train.next_batch(batch_size)
_, cost = sess.run([optimizer, crossEntropy], {x: batch_x, y: batch_y, prob: 0.75})
avg_cost += cost / batches
if (epoch + 1) % 5 == 0: # 隔5次输出迭代结果
acc = sess.run(accuracy, {x: batch_x, y: batch_y, prob: 0.75})
print('Epoch ', epoch + 1, 'cost=', '{:.5f}'.format(avg_cost), 'acc=', '{:.3f}'.format(acc))
print('the accuracy of train set: {:.3f}'.format(
sess.run(accuracy, {x: mnist.train.images, y: mnist.train.labels, prob: 0.75})))
print('the accuracy of test set: {:.3f}'.format(
sess.run(accuracy, {x: mnist.test.images, y: mnist.test.labels, prob: 0.75})))