笔记——迭代法之雅可比算法
迭代法
迭代法(Iterative Method)是一种最常使用求解大型、稀疏线性方程组的方法,与直接法相比,它具有方法简单,存储空间小(迭代法通常只对系数矩阵中的非零元素进行运算)等优点,特别是在有限步内无法得到问题的解时,迭代法就可在有限的迭代步数后,停止运算而得到足够好的近似解。
雅可比迭代法
它是一种最简单的线性方程组的迭代解法。并且很适合于并行化,每次迭代均使用上次迭代的值。
SISD上雅可比迭代法:对于求解线性方程组 Ax=b,未知向量 x 的分量可写成如下形式∶
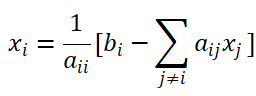
雅可比迭代原理是,使用第 k-1步所计算的变量 xi(k-1),来计算第k步的xi(k)值:
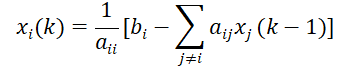
偏微分方程的差分解法——试考虑拉普拉斯方程的第一边值问题(狄利克雷问题):

(狄利克雷边界条件,为常微分方程的“第一类边界条件”,指定微分方程的解在边界处的值。求出这样的方程的解的问题被称为狄利克雷问题。)
其中,μ(x,y)为有界区域D的边界S上的已知函数。为了求解此偏微分方程,我们可以用差商代替偏导数,得到相应的差分方程,通过解差分方程就可得到偏微分方程的近似解,转化为代数问题。
试考虑在平面(x,y)上一个以 S为边界的有界区域D上定解问题。为了用差分法求解,可以分别作平行x 轴和y轴的直线簇xi=id , yj=jd (i,j=0,1,…,n;d为步距),从而构成一个等间距正方网格,面直线的诸交点(xi,yj)称为格点,记之为(i,j)。当i,j=1,2,…,n-1时的格点称为内格点,在S上的格点称为边界格点。所有内格点上,函数u(x,y)的偏导数可用差商代替∶

(差商即均差,一阶差商是一阶导数的近似值。对等步长(h)的离散函数f(x),其n阶差商就是它的n阶差分与其步长的n次幂的比值。例如n=1时,若差分取向前的或向后的,所得一阶差商就是函数的导数的一阶近似;若差分取中心的(xi+d;xi;xi-d)(中心差分法),则所得一阶差商是导数的二阶近似。)
若格点(i,j)处的函数u(x,y)记之为uij,且取d=1,则(10.12)式可简化为∶
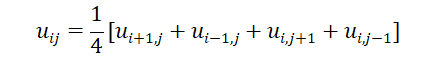
它就是有名的五点格式,即任一格点(i,j)上uij的值等于周围相邻四格点上解的值的算术平均。
使用雅可比算法求解该方程,照例使用第k-1步所计算的变量来计算第k步的变量,通过迭代计算出该方程的解。
串行实现
#include
// printf("%lf ",myRows[i*N+j]);
// }
// printf("\n");
// }
end_time=MPI_Wtime();
MPI_Finalize();
printf("chuanxing total time is %lf\n",end_time-start_time);
free(myRows);
free(myRows2);
}
// mpicc A.c -o A -lm(需链接math.h)
// mpirun ./A
MPI分行实现
将矩阵按行均分为四块,每块要增加两行分别存放与相邻两块通信交换得来的数据。将四块数据分别交于四个进程进行计算,每次计算前要进行进程间通信,交换边界数据。
#include
// for ( j = 0; j
// printf("%1.3f\t", myRows[i*N+j]);
// printf("\n");
// }
// if ( myid<3 ) {
// MPI_Send(&temp, 1, MPI_INT, myid+1, 0, MPI_COMM_WORLD);
// }
MPI_Barrier(MPI_COMM_WORLD); //保证计时
end_time=MPI_Wtime();
MPI_Finalize();
// printf("time is %lf\n",end_time-start_time); //所有进程都会执行
// if(myid==0){
// printf("Communication accounted for %lf\n",comtimeto/(comtimeto+multimeto));
// printf("Calculation accounted for %lf\n",multimeto/(comtimeto+multimeto));
// }
if(myid==0)
printf("total time is %lf\n",end_time-start_time);
}
可以通过这个程序测试计算和通信占比:(由于设备问题,只使用了一个结点)
| N=100000 | 时间 | 占比 |
|---|---|---|
| 通信 | 0.0132s | 0.008% |
| 计算 | 164.7896s | 99.992% |
MPI分块实现
虚拟拓扑:
虚拟拓扑可以用图来表示,结点代表进程,边用来连接彼此之间通信的进程。目前应用最多的是具有规则的网格形状的笛卡尔拓扑。
Jacobi解决狄利克雷问题,使用笛卡尔拓扑,划分为2*2的网格。按行列同时划分时,分块数组需要和上下左右的邻居同时通信,为此,分块数组的上下左右都预留出需要通信的部分,用来存放同各个方向邻居通信得到的数据。
#include "mpi.h"
#include 划分格式如图:

串行、分行、分块运行时间对比
| N=131072 | 时间 |
|---|---|
| 串行 | 1332.307798s |
| 分行 | 316.368530s |
| 分块 | 271.883872s |