Kmeans算法实现
文章目录
- 前言
- KMeans流程
- 距离公式
- 代码
- 运行效果
- 可能存在问题
-
- 猜想
- 分析
前言
废话不多说,咱们开始吧,看牛皮的标题应该就知道我想干什么了,嘿嘿~
在开始之前咧,我们先来简单的来看看咱们的Kmeans,这样我们就能够知道我们今天的玩意能够干嘛了。
KMeans流程
这个算法咧,其实我以前玩过,不过当时是使用sklearn直接调包的。那么今天呢,我们就先来简单复习。
KMeans 就分几步嘛。
- 随机选择中心点
- 计算每一个点离中心点的位置,选择最近的一个点(如果这个点理两个以上的中心的距离一样,那么无法分类)
- 根据每一个分类的点,重新计算中心,然后再次让所有的点去计算距离(中心点移动了,点要重新划分)
- 等到中心点不在移动后,我们停止算法
距离公式
由于咱们是使用距离的,所以这里我们有好几个距离公式可以选择(我这里复现是直接使用欧式距离的)



dist = |x1−x2|+|y1−y2|
这几个距离公式无所谓,到时候其实把代码改一下就好了。
代码
ok,现在我们直接来看看我们的代码。
我们的复现是做一个四分类的,四个颜色对应不同分类,还有一个分类是说那个点无法被那四个类分出来。
因为我们我们是分类属于那个类别是看你这个点距离那个中心点的距离来的,离得最近的中心的假设是A,那么此时这个点就是属于A的,但是如果最近的点有两个A,B的话,那么这个点是无法分类的。
import numpy as np
import math
import matplotlib.pyplot as plt
import random
#我们设计一个四分类的玩意儿,是一个二维的,因为二维的图像好画
K = 4
ECPHO = 300
Classfiy = ['red','blue','green','black']
OverClass =['cyan']
NUMBERS = 200
DIM = 2
SIZEPoint=(NUMBERS+int(NUMBERS),DIM)
MinRange = 1
MaxRange = 10
FRESH = 10
FRESHTIME = 1/FRESH
BUFFERTIME = 1
plt.ion()
def CreateData(k):
#返回初始化的点和随机选取的中心点
dataset = np.array([random.sample(range(MinRange,MaxRange),2) for _ in range(NUMBERS)])
# dataset = np.random.rand(400).reshape(200,2)*10
centers_init = np.random.choice(np.arange(len(dataset)),k,replace=False)
return dataset,dataset[centers_init]
def CompareDist(point,centers)->int:
#距离计算
#center:[[x1,y1],[x2,y2]]
#返回当前点理哪一个中心点最近
x,y = point[0],point[1]
dist = []
for center in centers:
dis = math.sqrt(math.pow(x-center[0],2)+math.pow(y-center[1],2))
dist.append(dis)
if(dist.count(min(dist)))>1:
return K
else:
return dist.index(min(dist))
def CompareClassfiy(dataset,centers):
#这个函数的作用很简单,计算每一个点到中心的距离,然后分类
#分完类之后,我们再重新计算新的centers
#并且返回当前新的中心和原来的中心的差值,以及当前分好类的点,以及无法分类的玩意
ClassPoints = {'red':[],'blue':[],'green':[],'black':[]}
OverPoints = {'cyan':[]}
for point in dataset:
classfiy = CompareDist(point,centers)
if(classfiy<K):
ClassPoints[Classfiy[classfiy]].append(point)
else:
OverPoints[OverClass[0]].append(point)
newCenters = []
for key in ClassPoints.keys():
temp = np.array(ClassPoints.get(key))
newcenter = np.average(temp,axis=0).tolist()
newCenters.append(newcenter)
newCenters = np.array(newCenters)
changed = newCenters - centers
return newCenters,changed,ClassPoints,OverPoints
def show(ClassPoints:dict,Centers,OverPoints):
for index in range(len(Centers)):
#绘制中心点
plt.scatter(Centers[index][0],Centers[index][1],marker='o',color=Classfiy[index],s=150)
#绘制所属类别的点
Points = ClassPoints.get(Classfiy[index])
Points=np.array(Points)
sca = plt.plot(Points[:,0],Points[:,1],'--',color =Classfiy[index] )
Over = OverPoints.get(OverClass[0])
if(len(Over)>0):
Over = np.array(Over)
sca = plt.plot(Over[:, 0], Over[:, 1],'*',color=OverClass[0],marker="X")
plt.show()
def KMeans(K):
# 初始化参数
dataSet,centers = CreateData(K)
newCenters,changed,ClassPoints,OverPoints = CompareClassfiy(dataSet,centers)
show(ClassPoints,centers,OverPoints)
bufferTime = 0
for i in range(ECPHO):
centers = newCenters
newCenters,changed,ClassPoints,OverPoints = CompareClassfiy(dataSet,centers)
show(ClassPoints,centers,OverPoints)
plt.pause(FRESHTIME)
plt.cla()
if(changed.all()==0.):
bufferTime+=1
if(bufferTime>=BUFFERTIME):
break
plt.ioff()
show(ClassPoints,centers,OverPoints)
if __name__ == '__main__':
KMeans(K)
运行效果
看代码还是比较简单的
我们来看看运行图
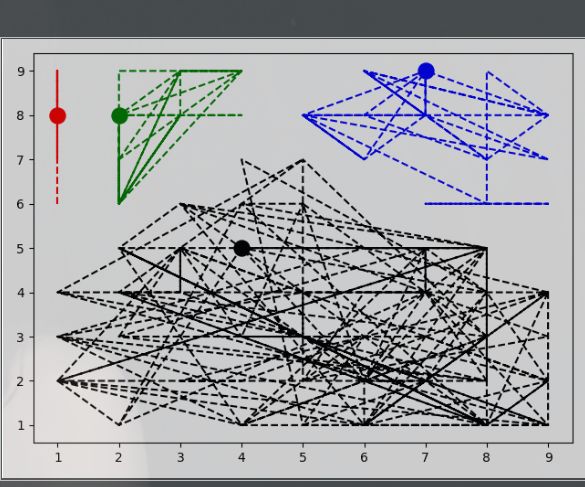
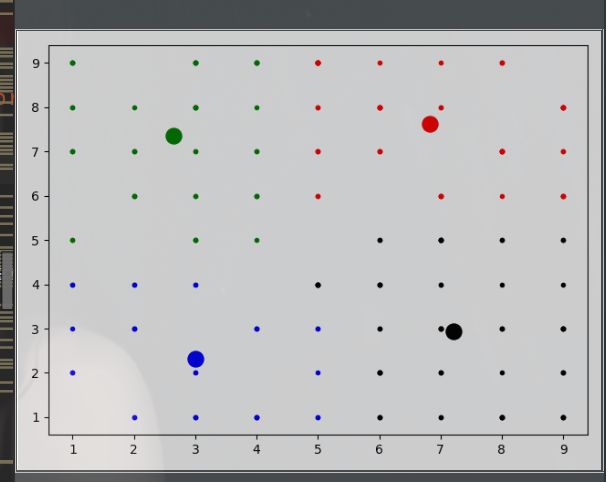
这里我为了好看出边界,所以我是使用虚线连接了点,因为接下来有个问题是我们要解决的。
(下图是用点表示的,边界不好看)
可能存在问题
ok ,我们先来看看我们的一个结果
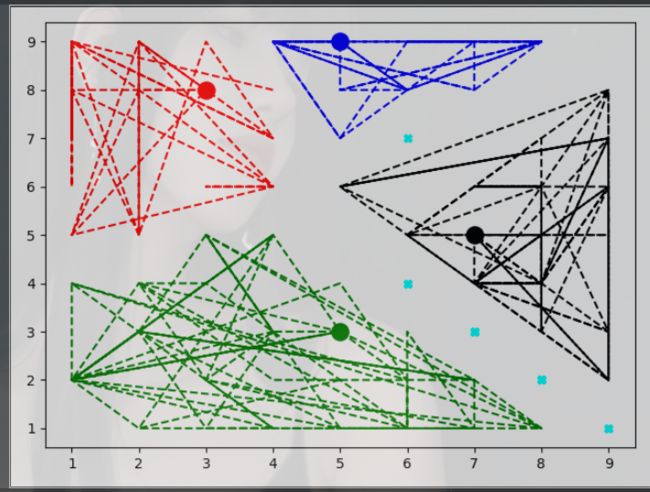
湛蓝色的点是我们无法分类的点。如果我们采用我们的距离来计算的话,那么你会发现有些点我们是压根没有办法分类的。
所以问题来了,如果我就想要实现4分类,我要求你必须要给我分个类,必须分配到所有的点,那么你如何搞。
那么在这里我的答案是使用神经网络
猜想
提出基于距离的分类的目的是期望能够找到—种基于距离的隐藏关系然后实现分类,但是有时候有些关系可能是很距离相关但不是强相关,所有可能导致部分点无法分类的问题。于是提出两个遐想。1.能否利用神经网络代替传统距离公式,利用神经网络学习隐藏关系得出—种能够特殊的隐藏关系的期望进行分类。2.能否直接利用神经网络分类,在学习距离的同时希望神经网络可以学习到与距离相关但是非强的隐藏关系。
分析
这里我分别对两个设想进行实现。—个是关于距离的,—个是关于分类的。并且在设计的时候,对第一个遐想参考DQN网络进行设计,得到结果收敛性和分类效果极差。对第二个遐想进行实现,分析了参考DQN设计的问题,采用GAN网络进行设计,提出基于距离的GANKmeans聚类算法,提出复合算法机制,我们设计了两个简单的三层神经网络使用RULE作为激活函数作为生成器和判断器,期望能够利用神经网络在学习到距离关系期望的同时还能够学习到与距离有关但非强相关的关系,从而对所有点都可以实现分类。