深度学习之学习(3-5)YOLOV5
五、YOLOv5
5.1 简介
YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升,具体包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作;基准端的Focus结构与CSP结构;Neck端的SPP与FPN+PAN结构;输出端的损失函数GIOU_Loss以及预测框筛选的DIOU_nms。除此之外,YOLOv5中的各种改进思路仍然可以应用到其它的目标检测算法中。
YOLOv5是YOLO系列的一个延申,您也可以看作是基于YOLOv3、YOLOv4的改进作品。YOLOv5没有相应的论文说明,但是作者在Github上积极地开放源代码,通过对源码分析,我们也能很快地了解YOLOv5的网络架构和工作原理。
Github源码地址:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
5.2 网络结构
YOLOv5官方代码中,一共给出了5个版本,分别是 YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLO5x 五个模型。这些不同的变体使得YOLOv5能很好的在精度和速度中权衡,方便用户选择。
本文中,我们以较为常用的YOLOv5s进行介绍,下面是YOLOv5s的整体网络结构示意图:
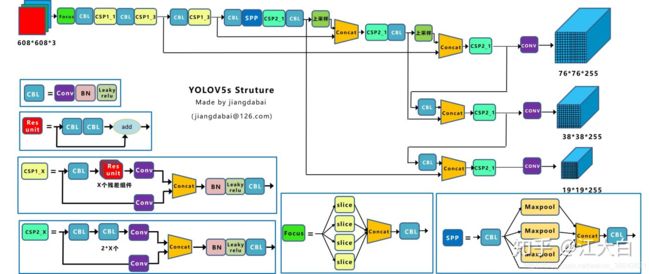
- CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成,如上图中的模块1所示。
- Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块,如上图中的模块2所示。
- CSP1_X-借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成而成,如上图中的模块3所示。
- CSP2_X-借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成,如上图中的模块4所示。
- Focus-如上图中的模块5所示,Focus结构首先将多个slice结果Concat起来,然后将其送入CBL模块中。
- SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,如上图中的模块6所示。
1、Input
和YOLOv4一样,对输入的图像进行Mosaic数据增强。Mosaic数据增强的作者也是来自Yolov5团队的成员,通过随机缩放、随机裁剪、随机排布的方式对不同图像进行拼接,如下如所示:
采用Mosaic数据增强方法,不仅使图片能丰富检测目标的背景,而且能够提高小目标的检测效果。并且在BN计算的时候一次性会处理四张图片!
2、Backbone
骨干网路部分主要采用的是:Focus结构、CSP结构。其中 Focus 结构在YOLOv1-YOLOv4中没有引入,作者将 Focus 结构引入了YOLOv5,用于直接处理输入的图片。Focus重要的是切片操作,如下图所示,4x4x3的图像切片后变成2x2x12的特征图。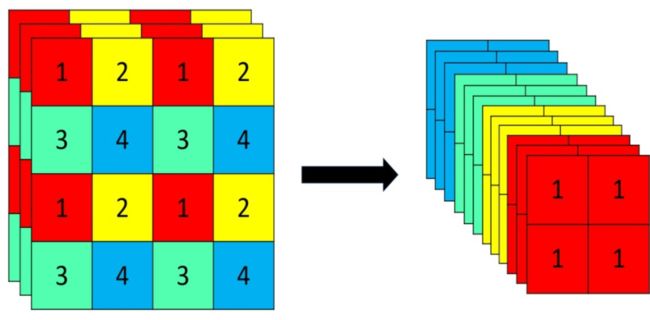
以YOLOv5s的结构为例,原始608x608x3的图像输入Focus结构,采用切片操作,先变成304x304x12的特征图,再经过一次32个卷积核的卷积操作,最终变成304x304x32的特征图。
Focus结构
-该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个304*304*32大小的特征映射


Focus是Yolov5新增的操作,右图就是将4 * 4 * 3的图像切片后变成2 * 2 * 12的特征图。
以Yolov5s的结构为例,原始608 * 608 * 3的图像输入Focus结构,采用切片操作,先变成304 * 304 * 12的特征图,再经过一次32个卷积核的卷积操作,最终变成304 * 304 * 32的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加。
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。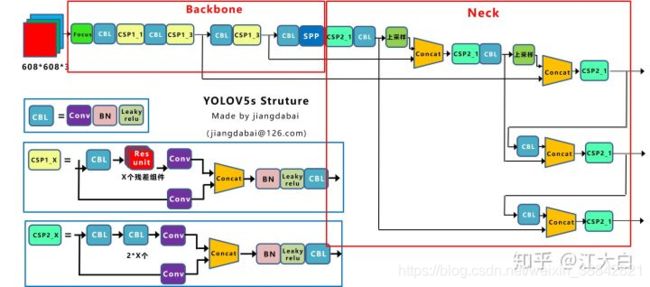
CSPNet(Cross Stage Partial Network):跨阶段局部网络,以缓解以前需要大
量推理计算的问题。
- 增强了CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈。
- 降低内存成本。
CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。
CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate
3、Neck
在网络的颈部,采用的是:FPN+PAN结构,进行丰富的特征融合,这一部分和YOLOv4的结构相同。详细内容可参考:
- 目标检测算法 YOLOv4 解析
- YOLO系列算法精讲:从yolov1至yolov4的进阶之路
Yolov5的Neck和Yolov4中一样,都采用FPN+PAN的结构。
FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递。PAN就是针对这一点,在FPN的后面添加一个自底向上的金字塔,对FPN补充,将低层的强定位特征传递上去,又被称之为“双塔战术”。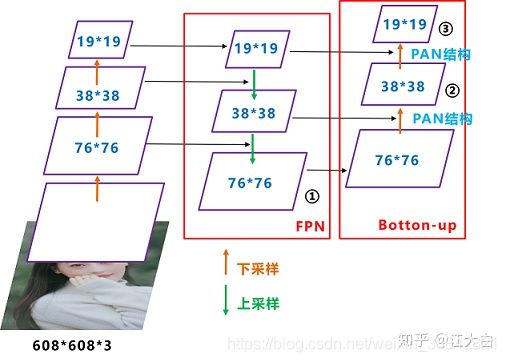
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
4、Head
对于网络的输出,遵循YOLO系列的一贯做法,采用的是耦合的Head。并且和YOLOv3、YOLOv4类似,采用了三个不同的输出Head,进行多尺度预测。详细内容可参考:
- 目标检测算法 YOLOv4 解析
- YOLO系列算法精讲:从yolov1至yolov4的进阶之路
Yolov5四种网络的深度

Yolov5四种网络的宽度

5.3 改进方法
1、自适应锚框计算
在YOLOv3、YOLOv4中,是通过K-Means方法来获取数据集的最佳anchors,这部分操作需要在网络训练之前单独进行。为了省去这部分"额外"的操作,Yolov5的作者将此功能嵌入到整体代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
-在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(’–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
2、自适应灰度填充
自适应图片缩放-针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述。
步骤1-根据原始图片大小与输入到网络图片大小计算缩放比例。
步骤2-根据原始图片大小与缩放比例计算缩放后的图片大小。
步骤3-计算黑边填充数值。
如上图所示,416表示YOLOv5网络所要求的图片宽度,312表示缩放后图片的宽度。首先执行相减操作来获得需要填充的黑边长度104;然后对该数值执行取余操作,即104%32=8,使用32是因为整个YOLOv5网络执行了5次下采样操作,即 2 5 = 32 2^{5} =32 25=32;最后对该数值除以2,即将填充的区域分散到两边。这样将416*416大小的图片缩小到416*320大小,因而极大的提升了算法的推理速度。
需要注意的是:(1)该操作仅在模型推理阶段执行,模型训练阶段仍然和传统的方法相同,将原始图片裁剪到416*416大小;(2)YOLOv3与YOLOv4中默认填充的数值是(0,0,0),而YOLOv5中默认填充的数值是(114,114,114);(3)该操作仅仅针对原始图片的短边而言,仍然将长边裁剪到416。
为了应对输入图片尺寸 不一的问题,通常做法是将原图直接resize成统一大小,但是这样会造成目标变形,如下图所示:
为了避免这种情况的发生,YOLOv5采用了灰度填充的方式统一输入尺寸,避免了目标变形的问题。灰度填充的核心思想就是将原图的长宽等比缩放对应统一尺寸,然后对于空白部分用灰色填充。如下图所示:
5.4 性能表现
在COCO数据集上,当输入原图的尺寸是:640x640时,YOLOv5的5个不同版本的模型的检测数据如下:

在COCO数据集上,当输入原图的尺寸是:640x640时,YOLOv5的5个不同版本的模型的检测数据如下:
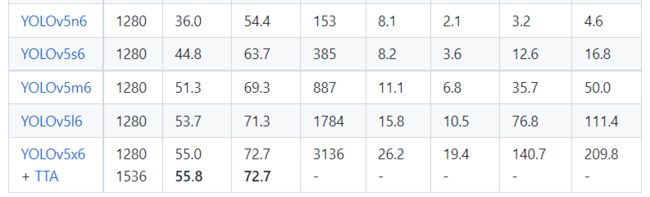
从上表可得知,从YOLOv5n到YOLOv5x,这五个YOLOv5模型的检测精度逐渐上升,检测速度逐渐下降。根据项目要求,用户可以选择合适的模型,来实现精度与速度的最佳权衡!
六、v4与v5 区别
数据增强:
v4:几何畸变,光照畸变,图像遮挡,CutMix+Mosaic,SAT,Class label smoothing
v5:几何畸变,光照畸变,Mosaic、anchors free
网络结构
Backbone:CSPDarknet53 (深度和宽度不同)
Neck:PANET+SPP
Head:三个特征层的输出
激活函数
v4:Mish
v5:Leaky RuLU+sigmoid
optim
v4:SGD
v5:较小的数据集:Adam 较大的数据集:SGD
loss
v4:CIOU
v5:GIOU+Focal loss
- IoU算法是使用最广泛的算法,大部分的检测算法都是使用的这个算法。
- GIoU考虑到,当检测框和真实框没有出现重叠的时候IoU的loss都是一样的,因此GIoU就加入了C检测框(C检测框是包含了检测框和真实框的最小矩形框),这样就可以解决检测框和真实框没有重叠的问题。但是当检测框和真实框之间出现包含的现象的时候GIoU就和IoUloss是同样的效果了。
- DIoU考虑到GIoU的缺点,也是增加了C检测框,将真实框和预测框都包含了进来,但是DIoU计算的不是框之间的交并,而是计算的每个检测框之间的欧氏距离,这样就可以解决GIoU包含出现的问题。
- CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。
参考:
教程:超详细从零开始yolov5模型训练_抛到海里的博客-CSDN博客_yolov5
yolov4的全面详解_笼中鸟-CSDN博客_yolov4
YOLOv5训练自己的数据集(超详细完整版)_深度学习菜鸟的博客-CSDN博客_yolov5训练自己的数据集
基于yolov5训练人头检测模型 - 知乎
yolov5训练自己的数据集(垃圾检测分类) - 知乎
yolov4(darknet官方)用于检测垃圾和分类 - 知乎
YOLOv5超详细的入门级教程(训练篇)(一)——训练自制数据集(识别鱼类)_“知识最大的敌人不是无知,而是错觉”-CSDN博客_yolov5数字识别
YOLOv5 Documentation
https://gitee.com/light169/yolov5