文章解读 -- Self-Supervised Pillar Motion Learning for Autonomous Driving
文章解读 – Self-Supervised Pillar Motion Learning for Autonomous Driving
1. 摘要
当高度动态环境下,与多样交通参与者进行互动时,自动驾驶能够从中进行运动行为理解。最近,有人们对直接从点云估计与类别无关的运动越来越感兴趣。当前运动估计方法通常需要来自自动驾驶场景的大量带注释的训练数据。然而,手动标记点云是出了名的困难、容易出错并且耗时的。本文中,我们试图回答大量未标记数据的集合是否可用于准确高效的运动学习。为此,我们提出了一个学习框架,纯粹通过自监督方式,利用来自点云的自监督信号和配对的相机图像。我们的模型涉及的点云,是基于结构一致性增强且带有概率运动遮蔽,以及交叉传感器运动正则化,来实现理想的自监督。实验表明,我们的方法与监督方法相比具有竞争力,并且在将我们的自监督模型与微调监督模型相结合,取得了最先进的结果。
2. 介绍
如何表征和提取时序间运动关系是研究难点,主要有以下挑战:
- 某场景下,存在众多物体类别,每个类别都表现出特定的运动行为;
- 点云是稀疏的,且连续帧之间缺乏精确对应关系;
- 估计过程受算力影响,难以达到实时性。
大多数识别模型只被训练来分类和定位对象,难以在未知类别的开放场景下进行理想地估计。BEV鸟瞰图的方式可以将运动信息进行二维矢量化,GPU上2D卷积速度更快。
我们的框架是将点云进行BEV投影,每一个pillar中的运动我们称作pillar motion,利用从相机图像提取的光流,来提供自监督和跨传感器正则化。
- 点云有助于,从光流中将自运动分解出来;
- 图像运动提供辅助正则化, 用于学习点云中的pillar运动;
- 反投影光流形成的概率运动遮蔽,促进点云的结构一致性。
相机组件只用于训练,推理时并不需要。
3. 相关工作
运动估计。传统方式是进行3D目标的检测与追踪,对相关模块依赖性较高,缺乏处理未知类别能力。另一类做法进行3D场景流估计,当前做法一般需要下采样,且用于监督训练的真值数据较难获取。BEV方式可以简化运动估计,常见网络MotionNet,图像光流辅助的监督网络。
自监督学习。主要涉及领域有特征表示学习,几何或颜色变换,对比学习、帧插值和序列排序等。点云自监督网络主要有PointContrast等基于点的方式。
雷达与相机融合。
4. 方法
下图阐明了我们的方法。
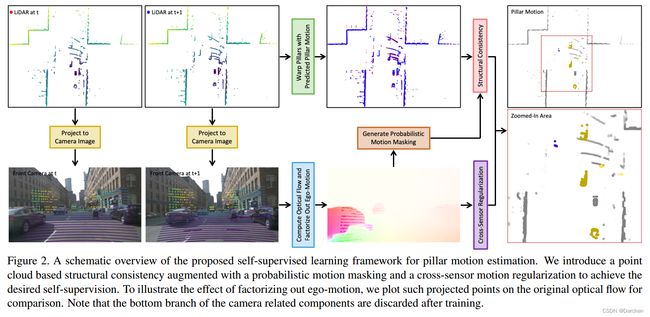
4.1 问题描述
Pt代表t时刻点云,It代表t时刻图像。所需要求解的是Mt,即t时刻每个pillar的运动位移。
4.2 基于运动一致性的雷达
首先将垂直方向置0,Lconsisit代表一直性损失,具体公式如下:
L c o n s i s t = ∑ m i n ∥ P i ~ − P j ∥ + ∑ m i n ∥ P j − P i ~ ∥ L_{consist}=\sum min\lVert \tilde{P_i} -P_j \rVert + \sum min\lVert P_j -\tilde{P_i} \rVert Lconsist=∑min∥Pi~−Pj∥+∑min∥Pj−Pi~∥
此loss利用转换后的点云与真实的点云之间,每一个点的最近距离。
显然,这种结构一致性依赖于两个连续帧对应点的存在。但对于激光雷达原始点云,这种假设通常不适用于许多情况,例如下一帧对应点没扫描到,超出传感器范围,远处点云稀疏等,这种方式必然引入噪声。
4.3 跨传感器运动正则化
利用带有稠密信息的图像,用更准确且成熟的光流法来辅助,将pillar motion投影到图像平面,进行跨传感器的运动正则化。
首先从光流中分解出ego-motion(自运动),Ft代表It和It+1两帧图像之间的光流估计。Ft可以分解为两部分:Fego+Fobj。其中Fego按照如下公式进行计算:
F e g o = K × T L − > C × T t − > t + 1 × P − K × T L − > C × P F_{ego} = K×T_{L->C}×T_{t->t+1}×P - K×T_{L->C}×P Fego=K×TL−>C×Tt−>t+1×P−K×TL−>C×P
其中含义:
K:表示相机内参, T_{L->C}代表雷达到相机的外参, T_{t->t+1}代表t时刻到t+1时刻的旋转矩阵。
一个pillar中的所有点集共享同一个预测的运动向量,然后我们将每一个点投影到图像平面,我们希望投影预测的光流F与Fobj越接近越好,故有下面的Lregular:
L r e g u l a r = ∑ ∥ F ~ − F o b j ∥ 1 L_{regular}=\sum \lVert \tilde{F}-F_{obj} \rVert _{1} Lregular=∑∥F~−Fobj∥1
这种跨传感器的loss作为辅助和重要的正则化来补充结构一致性,并减轻由于稀疏点云导致的歧义。光流引导的正则化主要作用是为了学习运动知识。
4.4 概率运动掩膜
分离出自运动之后,我们可以使用物体光流运动部分来近似制作一个概率运动掩码,以指示每个pillar是静态还是动态的概率。特别地,每个投影点是静止的概率可以这样计算:
s = e x p { − α m a x ( ∥ F o b j ∥ − γ , 0 ) } s=exp \left\{-\alpha max(\lVert F_{obj}\rVert - \gamma , 0 )\right\} s=exp{−αmax(∥Fobj∥−γ,0)}
其中含义:
\alpha:平滑因子;\gamma:静止容忍偏差
我们再反向投影回点云坐标系,用一个pillar中s的均值来推断一个pillar运动的可能性。我们可以利用概率运动掩码来减轻静态pillar中点的权重。静态pillar在一个场景中通常占据主导地位,可以简单地为Lconsist增加一个权重系数。
4.5 优化
类似于光流估计的空间平滑度约束,我们对于pillar motion也应用了局部平滑度损失Lsmooth:
L s m o o t h = ∣ ▽ x M x ∣ + ∣ ▽ y M x ∣ + ∣ ▽ x M y ∣ + ∣ ▽ y M y ∣ L_{smooth}=|\bigtriangledown_xM^x|+|\bigtriangledown_yM^x|+|\bigtriangledown_xM^y|+|\bigtriangledown_yM^y| Lsmooth=∣▽xMx∣+∣▽yMx∣+∣▽xMy∣+∣▽yMy∣
直观地说,这种平滑损失鼓励模型,预测属于同一个物体的pillar的相似运动。
总的损失函数,包含以上的所有,即:
L t o t a l = λ c o n s i s t L c o n s i s t + λ r e g u l a r L r e g u l a r + λ s m o o t h L s m o o t h L_{total}=\lambda_{consist}L_{consist}+\lambda_{regular}L_{regular}+\lambda_{smooth}L_{smooth} Ltotal=λconsistLconsist+λregularLregular+λsmoothLsmooth
4.6 特征提取网络
我们首先使用了一个pillar特征编码器,将原始点云转化为BEV特征图。然后将特征图送入带有连续时间与空间卷积的U-Net,作为编码器与解码器的桥梁。
5. 实验
5.1 实验配置
A.数据集
nuScenes,包含850带标注的场景,每个场景40s。我们使用500个场景训练,100验证,250个作为测试。该数据集带有完整激光雷达,摄像头,毫米波雷达,IMU和GPS。雷达频率20HZ,摄像头频率10HZ。训练期间使用雷达和6个摄像头。
B.详细描述
实验环境:pytorch框架下,batch size为64的 8 GPUs,训练时,总共200次迭代,学习率0.0001,每20轮次衰减学习率因子设为0.9。
Loss中相关参数:
α = 0.1 ; γ = 5 ; λ c o n s i s t = 1 ; λ r e g u l a r = 0.01 ; λ s m o o t h = 1 \alpha=0.1; \gamma=5; \lambda_{consist}=1; \lambda_{regular}=0.01; \lambda_{smooth}=1 α=0.1;γ=5;λconsist=1;λregular=0.01;λsmooth=1
检测范围:[-32m, 32m]×[-32m, 32m]
pillar尺寸:0.25m
PWC-Net 作为光流估计网络
C.评估尺度
遵循MotionNet里面提到的平均误差和中误差,我们将速度分成:静止,慢速(<5m/s),快速(>5m/s)。
5.2 消融研究
独立组件的贡献
大量训练数据
训练数据量从20%提高到100%,前景与移动物体的表现都增强了。
表现vs距离
5.3 与先进结果进行比较
与MotionNet+MGDA相比,我们的表现更好,整体表现如下图所示。

5.4 运行时间分析
点云转换与体素化用了10ms,网络前向推断耗时10ms,总共20ms,达到实时性。
5.5 定性结果
与完整模型相比,仅使用结构一致性损失的模型往往会在背景中产生运动预测的误报。我们的完整模型可以成功消除大多数FP,表明基于光流的正则化和掩蔽对抑制这种噪声是有效的。与基础模型相比,完整模型还能够在运动物体,使空间运动更平滑。
6. 总结
这篇文章中,我们利用未标记的点云集合和成对的相机图像,提出了一种自监督学习的进行pilldar motion 估计的框架。 我们的模型涉及的点云,是基于结构一致性增强且带有概率运动遮蔽,以及交叉传感器运动正则化。 大量的实验证明我们的自我监督方法取得了更好的结果,并且当我们的模型进一步监督微调后,优于最先进的方法。我们希望这些发现将鼓励更多关于pillar motion 估计和基于点云的自我监督学习的研究工作。