深度学习--第8篇: Pytorch数据读取DataLoader与Dataset
Pytorch数据读取DataLoader与Dataset
- 1. 数据模块
- 2. DataLoader
-
- 2.1 Epoch、Iteration、Batchsize
- 3. Dataset
- 4. torchvision
-
- 4.1 图像预处理torchvision.transforms
- 4.2 transforms.ToTensor
- 4.2 数据标准化transforms.normalize
- 4.3 transforms方法总结
- 5. 实例展示
-
- 5.1 数据集划分
- 5.2 自定义数据集Dataset
- 5.3 人民币二分类实例
1. 数据模块
数据包含以下四个子模块:
- 数据收集: img,label 原始数据和标签
- 数据划分: train训练集,valid验证集,test测试集
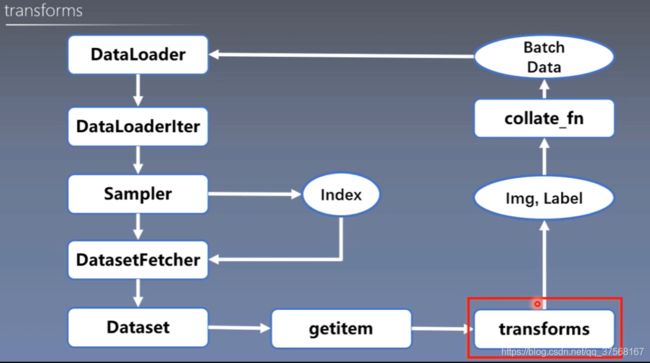
- 数据读取: DataLoader
1) Sampler(生成index);
2) Dataset(读取Img,Label);
- 数据预处理:transforms

2. DataLoader
torch.utils.data.DataLoader 功能:构建可迭代的数据装载器
参数:
- dataset:Dataset类,决定数据从哪里读取及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据

2.1 Epoch、Iteration、Batchsize
Epoch、Iteration、Batchsize关系
- Epoch:所有训练样本都已输入到模型中,称为一个epoch
- Iteration:一批样本输入到模型中,称之为一个Iteration
- Batchsize:批大小,决定一个Epoch有多少个iteration
实例1:
样本总数:80 batchsize:8
1 epoch = 10 iteration 一次iteration输入8个样本,所以一次的epoch=8
实例2:
样本总数:87 batchsize:8
if drop_last = true 1 epoch = 10 iteration
else drop_last = false 1 epoch = 11 iteration

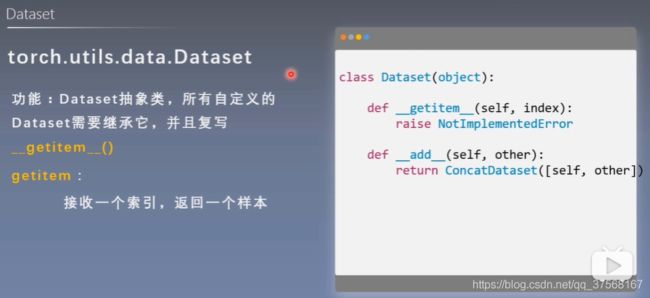
3. Dataset
torch.utils.data.Dataset 功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且要复写函数 __getitem__()
- __getitem__() :接收一个索引,返回一个样本及标签
4. torchvision
torchvision是计算机视觉工具包,有三个主要模块:
- torchvision.transforms:常用的图像预处理方法(这节课的主要学习对象)
- torchvision.datasets:常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等
- torchvision.model:常用的模型预训练,AlexNet,VGG,ResNet,GoogLeNet等

4.1 图像预处理torchvision.transforms

4.2 transforms.ToTensor
transforms.ToTensor()
功能:
将PILImage或者numpy的ndarray转化成Tensor
- 把一个取值范围是[0,255]的PIL.Image 转换成 (0,1.0)的Tensor
- 对于PILImage转化的Tensor,其数据类型是torch.FloatTensor
- 对于ndarray的数据类型没有限制,但转化成的Tensor的数据类型是由ndarray的数据类型决定的。
4.2 数据标准化transforms.normalize
transforms.Normalize 数据标准化
功能:逐channel的对图像进行标准化, 通过标准化后,实现了数据中心化,数据中心化符合数据分布规律,能增加模型的泛化能力
公式:output=(channel-mean)/std
也就是说,如果channel的范围是(0,1)
那么公式: ( (0,1) - 0.5 ) / 0.5 = (-1,1)
参数:
- mean:各通道的均值
- std:各通道的标准差
- inplace:是否原地操作
实例:
norm_mean = [0.485, 0.456, 0.406] # 设置标准化的均值
norm_std = [0.229, 0.224, 0.225] # 设置标准化的方差
train_transform = transforms.Compose([
transforms.Resize( (32,32) ), # 图像缩放
transforms.RandomCrop(32, padding=4), # 图像裁剪
transforms.ToTensor(), # range [0, 255] -> [0.0,1.0]
transforms.Normalize(norm_mean, norm_std) # 图像标准化
])

4.3 transforms方法总结

5. 实例展示
下面是一个完整的人民币二分类问题, 数据集和程序请到下列地址下载: 人民币二分类: 程序与数据集
5.1 数据集划分
一般图像数据集将划分为三部分:
- 训练集:70%
- 验证集:20%
- 测试集10%
import os
import random
import shutil
random.seed(1) # 设置随机数种子,保证每次运行的随机数都相同
# 判读路径下是否存在文件夹,没有则创建
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == "__main__":
dataset_dir = os.path.join("..", "data", "RMB_data") # 原始数据存放路径
split_dir = os.path.join(".", "split_data") # 划分后数据集的李静
train_dir = os.path.join(split_dir, "train_data")
vaild_dir = os.path.join(split_dir, "vaild_data")
test_dir = os.path.join(split_dir, "test_data")
train_pct = 0.7
vaild_pct = 0.2
test_pct = 0.1
# os.walk(), 会获取文件夹的路径, 以及路径下的文件夹目录名, 文件名
for root, dirs, files in os.walk( dataset_dir ):
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir)) # 返回文件夹下的文件名列表
imgs = list( filter( lambda x: x.endswith('.jpg'), imgs ) ) # 过滤掉不是以.jpg结尾的文件
random.shuffle(imgs) # 随机打乱列表的顺序
img_count = len(imgs) # 统计列表中的数量
train_point = int(img_count * train_pct) # 划分训练集的数量
vaild_point = int(img_count * vaild_pct) # 划分验证集的数量
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < (train_point + vaild_point):
out_dir = os.path.join(vaild_dir, sub_dir)
else :
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
src_path = os.path.join(root, sub_dir, imgs[i]) # 原始图像文件的路径
target_path = os.path.join(out_dir, imgs[i]) # 创建copy的目标文件
shutil.copy(src_path, target_path) # 从一个路径到另一个路径copy文件
5.2 自定义数据集Dataset
利用继承原始Dataset抽象类, 自定义所需功能的Dataset类,如下所示,自定义Dataset类,用于读取图像数据.
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_lable = {"1": 0, "100": 1} # 设置标签(字典查询)
class RMBdataset(Dataset):
def __init__(self, data_dir, transform=None):
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir)
self.transform = transform
# 重写__getitem__函数
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert("RGB") # 将PIL格式的数据转换为RGB
if self.transform is not None:
img = self.transform(img) # 利用transfrorm进行图像预处理
return img, label
def __len__(self):
return len(self.data_info) # 训练集/测试集的数据个数
@staticmethod # 静态方法,封装在类内,不依赖于self
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list( filter(lambda x: x.endswith(".jpg"), img_names) )
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_lable[sub_dir]
data_info.append( (path_img, int(label)) ) # 将图像和标签存入到列表中,作为数据信息
return data_info
5.3 人民币二分类实例
import os
import random
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import numpy as np
from lenet import LeNet
from my_dataset import RMBdataset
def set_seed( seed = 1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_lable = {"1": 0, "100": 1} # 设置标签
# 训练参数
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
val_log = 2
train_log = 5
val_interval = 1
# 读取数据
split_dir = os.path.join(".", "split_data")
train_dir = os.path.join(split_dir, "train_data")
vaild_dir = os.path.join(split_dir, "vaild_data")
test_dir = os.path.join(split_dir, "test_data")
norm_mean = [0.485, 0.456, 0.406] # 设置标准化的均值
norm_std = [0.229, 0.224, 0.225] # 设置标准化的方差
# 训练数据集的预处理
train_transform = transforms.Compose([
transforms.Resize( (32,32) ),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(), # range [0, 255] -> [0.0,1.0]
transforms.Normalize(norm_mean, norm_std)
])
# 验证数据集的预处理
vaild_transform = transforms.Compose([
transforms.Resize( (32,32) ),
transforms.ToTensor(),
transforms.Normalize(norm_std, norm_std)
])
# 测试数据集的预处理
test_transform = transforms.Compose([
transforms.Resize( (32,32) ),
transforms.ToTensor(),
transforms.Normalize(norm_std, norm_std)
])
# 构建Dataset类,读取数据和标签
train_data = RMBdataset(data_dir = train_dir, transform = train_transform)
vaild_data = RMBdataset(data_dir = vaild_dir, transform = vaild_transform)
test_data = RMBdataset(data_dir = test_dir, transform = test_transform)
# 构建DataLoader, 用于加载数据, 参数: shuffle表示随机打乱顺序
train_loader = DataLoader(dataset = train_data, batch_size = BATCH_SIZE, shuffle = True)
vaild_loader = DataLoader(dataset = vaild_data, batch_size = BATCH_SIZE, shuffle = True)
test_loader = DataLoader(dataset = test_data, batch_size = BATCH_SIZE, shuffle = True)
# 设置训练模型LeNet, 输出的维度( 训练集图片总数,2 )
net = LeNet(classes=2)
net.initialize_weights()
# 构建损失函数
loss_function = nn.CrossEntropyLoss() # 交叉熵损失函数, 输入是类别的数量
# 选择优化器
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择SGD优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# 开始训练数据集,同时验证
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train() # 开始训练
for i, data in enumerate(train_loader):
inputs, labels = data # 从loader中获取数据和标签, 每次获取批大小的数据, batch_size = 16
outputs = net(inputs) # 前向传播
optimizer.zero_grad() # 每次迭代清空梯度
loss = loss_function(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 更新权重
_, predicted = torch.max(outputs.data, 1) # 获取两类中概率大的索引号
total += labels.size(0) # 统计标签总数
correct += (predicted == labels).squeeze().sum().item() # 统计预测正确的数量
loss_mean += loss.item()
if (i+1) % train_log == 0:
loss_mean /= train_log
print("loss= %.4f" % loss_mean, "correct= %.4f" % ( correct/total) )
loss_mean = 0.
scheduler.step() # 更新学习率
# 验证数据准确性
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
net.eval() # 评估模式
# torch.no_grad()表示不需要计算梯度和反向传播
with torch.no_grad():
for j, data in enumerate(vaild_loader):
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().item()
if (j+1) % val_log ==0:
print("correct_val=%.4f" % (correct_val / total_val) )
# 测试模型准确性
for i, data in enumerate(test_loader):
inputs, labels = data
outputs = net(inputs) # 前向传播
_, predicted = torch.max(outputs.data, 1) # 获取标签的索引, 结果是 torch.Size([16])的形式,一维张量
for t in range(labels.size(0)):
rmb = 1 if predicted[t].item() == 0 else 100
print("模型获得{}元".format(rmb))