2020李宏毅机器学习笔记——25. GAN(生成对抗网络)
Generative Adversarial Network(生成对抗网络)
文章目录
- 摘要
- 0引言
- 1. Basic Idea of GAN(GAN的基本思想)
-
- 1.1 Generation(生成)
- 1.2 Discriminator(判别器)
- 1.3 生成器和判别器的关系
- 1.4 Algorithm
- 2. GAN as structured learning
-
- 2.1 什么是Structured Learning?
- 2.2 Why Structured Learning Challenging?
- 2.3 Structured Learning Approach
- 3. Can Generator learn by itself?(生成器能否自己学习)
-
- 3.1 Generator通过auto-encoder
- 3.2 VAE vs GAN(VAE方法的缺陷)
- 4. Can Discriminator generate?(判别器能否自己生成图片)
- 4.1 Discriminator
-
- 4.2 Discriminator - Training
- 5. Generator v.s. Discriminator
- 6. Generator + Discriminator
- 7. 总结与展望
摘要
本章主要是在讲解GAN技术,一是GAN的基本思想是:GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。随机输入一个向量,Generator 将输出一个高维向量(图片、语句);而Discriminator去判别生成的高维向量(数据)的好坏;二者的训练则是处于一种对抗博弈状态。
二是GAN的训练过程:先固定住生成器G,更新判别器D,根据真实图片和生成图片训练判别器的参数,从而训练得到一个好的Discriminator;之后是固定判别器D,更新生成器G,用已经训练好的判别器去训练生成器的参数,使生成的图片尽可能真实,给生成的样本打出高分;再其次不断迭代训练生成器和判别器。
三是从概念上介绍GAN:将GAN看作一种结构化学习,以及介绍了GAN在实际生活中应用非常广泛,比如机器翻译(machine translation),语音识别(speech recognition)以及聊天机器人(chat-bot)。
以及后面介绍了单独的生成器能否自己学习,单独的判别器能否自己生成图片,这两个都是存在着很大问题。只有将Generator与Discriminator 结合起来,其优缺点互补,这也便是GAN的优势所在。
0引言
自2014年Ian Goodfellow 提出了GAN(Generative Adversarial Network)以来,对GAN的研究可谓是如火如荼。针对不同的应用场景提出了各种GAN的变体,不断涌现,近年来更是在论文中爆发增长,可见GAN这项新技术的活力与优势是不一般的。顶尖大佬对GAN技术的评价都是颇高的,那究竟什么是GAN,它又好在哪里,具有怎样的优势?
本章主要从下面几个方面去展开:
- Basic ldea of GAN
- GAN as structured learning
- Can Generator learn by itself ?
- Can Discriminator generate?
1. Basic Idea of GAN(GAN的基本思想)
GAN的核心思想是“生成”与“对抗”,GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。生成器是负责凭空捏造数据出来,而判别器是负责判断数据是不是真数据,二者的训练则是处于一种对抗博弈状态,一代代博弈,直到一个理想的状态。
1.1 Generation(生成)
Generation做的事情主要分为如下两种:
- Image Generation:训练一个NN生成器,随机输入一个vector,输出一张图片。
- Sentence Generation:也是训练一个NN生成器,随机输入一个vector ,即可输出一个句子。
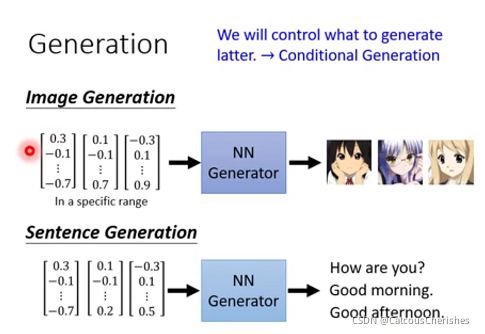
Generator生成器,它是一个深度神经网络,输入一个低维vector,输出高维vector(图片或文本或语音)。
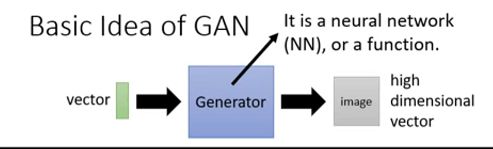
实际上上述生成器有什么作用呢? 答案是没有,但是如果不是随机输入,而是输入一些我们可以了解的东西(比如文字,图片影像等),使机器产生对应的东西。这个就是条件生成了,它的作用就很广泛了。
1.2 Discriminator(判别器)
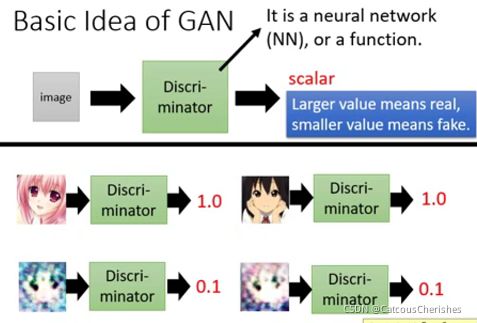
训练GAN时,同时也会训练一个Discriminator,Discriminator判别器,它也是一个深度神经网络,输入一个高维vector(图片或文本或语音),输出一个标量。标量越大,代表输入图片(或文本语音)越真实。
1.3 生成器和判别器的关系
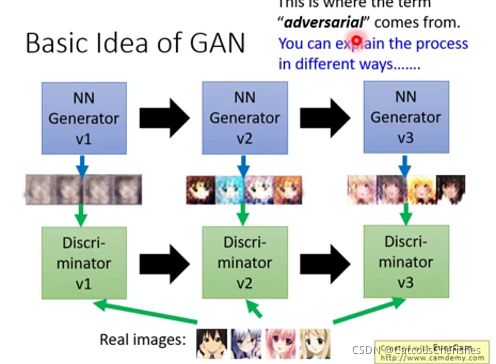
Generation和Discriminator就像捕食者和被捕食者一样,即生成器和判别器二者进行对抗学习,生成器不断迭代进化,努力生成假的图片,从而可以骗过判别器。判别器也在不断迭代进化,努力识别越来越接近真实的假图片。通过二者对抗学习,最终生成器生成的假图片越来越像真实图片,而判别器越来越能区分和真实图片很接近的假图片。二者能力在迭代过程中,都可以得到大幅提升。
其训练过程就是一个Generator和Discriminator不断进化完善的过程:
但是呢,也可以将Generator和Discriminator比作是学生和老师的关系(和平):
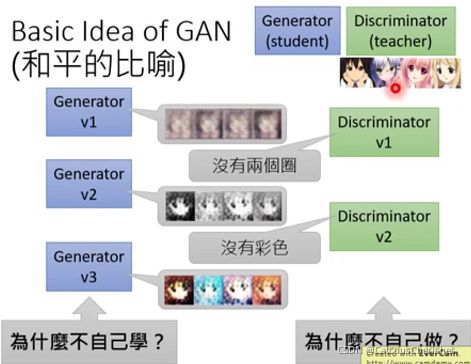
提问:
- Generator为什么不自己学,还需要Discriminator来指导?
- Discriminator为什么不自己直接做?
答案将在后面讲解!
1.4 Algorithm
Generator和Discriminator是怎样训练出来的,是如何实现GAN的呢?
首先G和D都是NN,它们具体是什么框架,则取决于具体的任务。
准备阶段:随机初始化生成器和判别器的参数。
GAN的通用步骤如下:
1.固定住生成器G,update判别器D。从真实图片中随机sample一些样本。然后利用一些随机sample的vector,通过生成器得到一些假样本。真样本标注为1,假样本标注为0。构建完监督数据后就可以训练判别器了。判别器可以用MSE(均方误差)作为loss。它的目标是真实图片得高分,假图片得低分。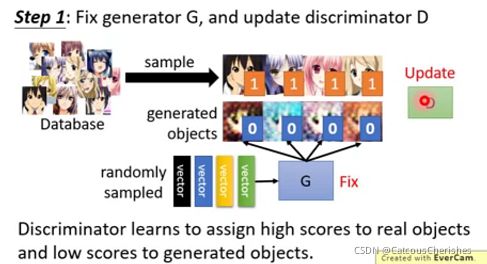
2. 固定住判别器D,update生成器G。利用随机sample的vector,通过生成器得到一些假样本。然后再通过判别器(已经训练好的Discriminator)进行打分。它的目标是假图片得分也要高(即生成更好的样本,骗过判别器)。

3. 迭代步骤1和步骤2,即可迭代训练生成器和判别器。
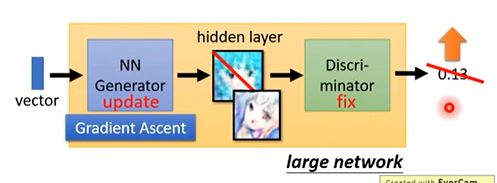
网络架构
实际上我们输入vector时,我们会将G和D串在一起看为一个 large network,可以是一个end2end的模型.
- 前面几个layer可以作为生成器。需要固定时直接freeze这些参数,让他们不参与模型训练即可。
- 后面几个layer可以作为判别器。
- 中间某一层输出一个高维的feature map,它可以看做是生成的图片或文本。
具体算法——目标函数
原始论文的做法:
先从database中抽取m个图片,另从一个(高斯)分布中随机抽取m个vector,使用m个vector产生m个image。
判别器D的目标是真实样本高分,假样本低分,其目标函数如下,我们需要最大化这个目标函数。其中xi为真实样本,x ̃i为假样本。

使function越大:真样本的分数越大,假样本分数很小,则 V V V会最大化。因此使用梯度上升的方法,调节判别器参数。
(两次随机sample的z不需要是一样的)
生成器G的目标是假样本也得高分。zi为一个随机vector,它通过G()得到一个假样本,然后再通过D()进行判别。我们的目标是让判别平均分尽量高。

就是说生成器G要想办法骗过判别器D,即是使生成的假样本也会得到D的高分。
2. GAN as structured learning
2.1 什么是Structured Learning?
从概念上介绍GAN:将GAN看作一种结构化学习
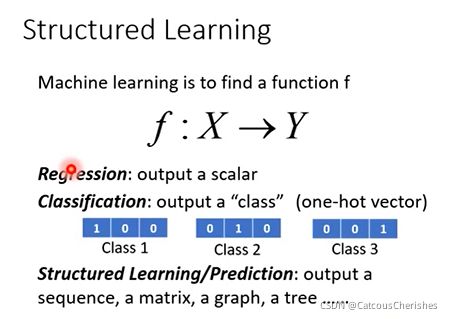
首先我们了解下什么叫做stuctured learning, 机器学习本质上是学习数据集到目标的映射函数 F:X->Y, 对比下机器学习下其他的场景,如回归、分类:
- Regression: 输出为连续变量
- Classification: 输出为类别(one-hot vector)
- Structured Learning: 输出为序列、矩阵(图像)、图(graph),树(tree)等等
Structured Learning的输出是彼此有前后依赖关系的, 比如一个好的系统输出一张生成的图像,图像有蓝天,天空中通常有鸟,但是不会有人,当我们把图像中每一个像素点看做一个components,我们知道这些components之间会有若干联系。
GAN的应用就十分广泛:机器翻译(machine translation),语音识别(speech recognition)以及聊天机器人(chat-bot):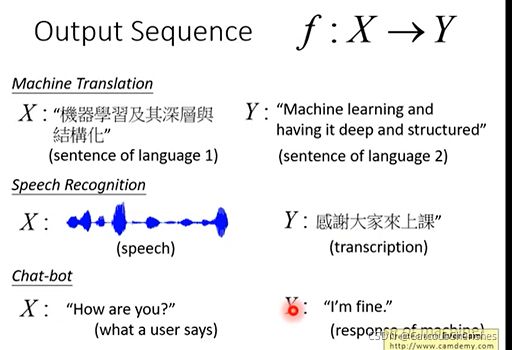
输出结果是图片,也就是矩阵,如下图,可以做虚拟图像转图像(image-to-image),彩色化(colorization),还有文本转图像(text-to-image):
2.2 Why Structured Learning Challenging?
Structured Learning 主要有这几个方面的挑战:
- One-shot/Zero-shot Learning: 在分类任务中,每一个类别有若干个examples,而在Structured Learning,假如我们把components的某一种组合即生成的结果看做一个类别,你会发现类别特别大,大多数类别没有任何训练数据,不可能有如此多的数据来覆盖,Structured Learning,生成的图像可能在训练数据集中完全没有出现。因此,Structured Learning需要机器更加"智能",需要学会创造,才能完成相应场景的任务;

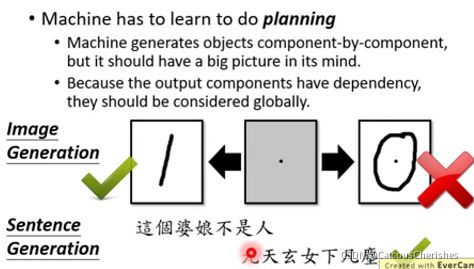
- Machine has to learn to do planning:机器需要有大局观,机器生成时是一个个components,但是这些components需要能合成一张有意义的图片,最重要的是这些components之间有依赖关系。Structured Learning必须要有这样的能力,才能完成相应场景的任务;
2.3 Structured Learning Approach
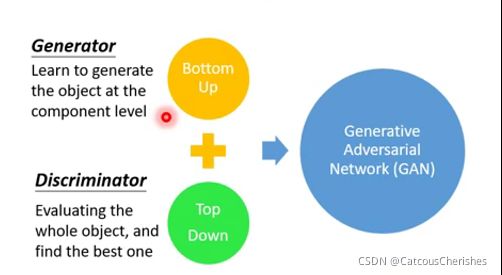
传统的在Structure Learning上相关的工作,主要集中在两部分:
- Bottom Up: 要产生一个完整的对象,如图像,需要从component一个一个分别产生,这种方法会失去大局观;
- Top Down: 从整体考虑,生成多个对象,然后找到最好的对象;
而GAN中,Generator就属于Bottom Up的方法,Discriminator属于Top Down的方法。
3. Can Generator learn by itself?(生成器能否自己学习)
即生成器为什么需要判别器的帮助。广义来说,生成器和判别器二者不是敌人,他们不是对抗关系。他们其实是在对方帮助下,不断提升了自己,成就了彼此。那现在有个问题,我们利用Auto-Encoder等技术,不是就已经可以生成还不错的图片了吗。貌似生成器不需要判别器,就可以搞定生成的问题。
3.1 Generator通过auto-encoder
假设我们想通过一个向量来生成一张图片,我们一般会如何做呢 ?很容易,我们一般第一印象会想到Auto-encoder的技术。
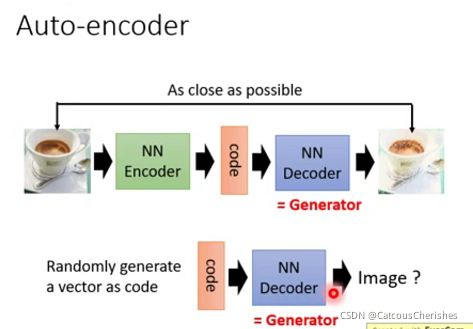
再拿到图片,我们通过一个NN来encoding为一段vector, 然后再通过一个NN来decode这段vector,设置loss函数保证decode出来的图像与原始图像尽可能类似,这样我们把decode的部分拿出来。训练完Auto-Encoder后,decoder网络就可以作为生成器了。
那么Auto-encoder会有什么样的问题呢?
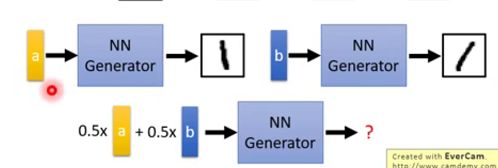
比如code a 能生成1的图像,code b 也能生成1的图像,比较右向,那么0.5a+0.5b呢 ,我们可能希望它也有相应的方向变化,但是Auto-encoder可能连1这张图像也无法生成。
如何解决?VAE(变分自编码器)也是我们在学习GAN经常会拿来对比的。
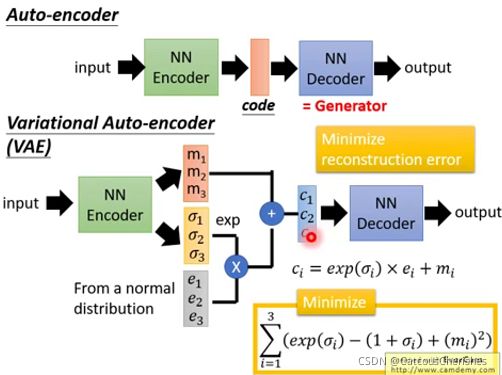
3.2 VAE vs GAN(VAE方法的缺陷)
VAE不仅产生一个code(m1,m2,m3)还会产生每一个维度的方差;然后将方差和正态分布中抽取的噪声进行相乘,之后加上code上去,相当于加上noise的code;之后输入的decoder中就得到图片;这样情况下,decoder不只是看到a或b产生一些数字,当看到a或b加上一些noise也要产生数字;这样可以使decoder更加具有鲁棒性。
结合去噪自编码器,变分自编码器VAE等技术,可以大大提升生成器的鲁棒性,提升图片生成质量。看起来Generator就可以做到很好的Structure Learning的问题,看到这里,可能会问,前面不是说Bottom Up的方法有缺失大局观的问题吗?如何理解呢?
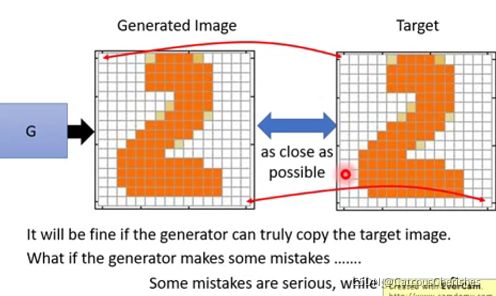
问题就在于As close as possible判别这一步,直接在pixel级别上,对输入输出图片进行对比,是一个很不科学的行为。因为pixel级别对比,特征实在是太低阶了。我们对比两个物体相似度,要尽量在高阶特征上进行对比。
现在问题是生成的图片总是会和真实图片有一些差异,在计算差异的时候就会出现问题:

我们的目标是要生成右上角的图片,但是实际上肯定会有一些mistake。
可以看到,虽然上面两个按差异计算来说比下面的图片的计算结果要好,但是从图片整体来看,反而下面的图片符合手写图片的规律。
也就是说模型的优化目标不是单纯的让你的生成结果与真实结果越接近越好。而是要使得component与component之间的关系符合现实规律。例如:
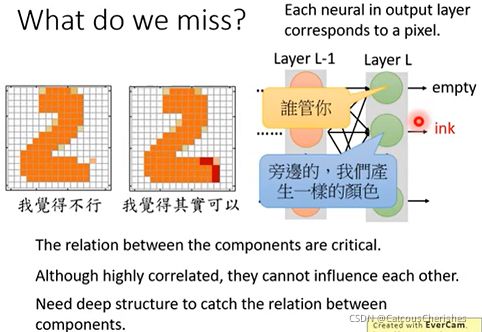
生成图片中,不同的components之间的关系是非常严格的,但是这种关系是很难表现在神经网络之中,每个神经元都是独立的。
想要解决这个问题,就需要VAE有更深的结构去联系不同像素之间的关系。所以如果不用判别器D,只单纯的用auto-encoder技术去做Generation这件事。如果有同样的NN,根据经验,一个用GAN去training,一个用auto-encoder,用GAN的那个可以产生图片,而auto-encoder去train的那个需要更大的NN结构才能和GAN较为接近的结果。
4. Can Discriminator generate?(判别器能否自己生成图片)
4.1 Discriminator
Discriminator要做的事情就是给真样本打出高分,给假样本打出低分:

对于单纯的Generator,每一个component之间都是独立产生的,所以想要去判别不同像素之间的关联是很困难的。但Discriminator的优势在于它可以很轻易地捕捉到元素之间的相关性,因为Discriminator是要产生完一张完整的图片,然后丢个Discriminator去打分。
Discriminator相对Generator很容易去建模components之间的关系,比如:

下面假如说已经有了一个判别器,它能够鉴别一个图片是好的还是不好的,我们就可以用这个判别器去生成图片。Discriminator 用来生成是穷举所有的x,然后找出分数最高的,就是生成的结果。

原理很简单,我们只需要遍历所有的数据X然后找到生成得分值最好的,即可解决Structured Learning的问题,这里先假设我们能够收集"所有数据"这部分不是问题,那么要想得到一个这样的工具,如何去训练呢?
4.2 Discriminator - Training
我们需要得到好和不好的图像,比如在绘画场景下,我们需要得到画的好与画的不好的情况,这个其实就存在一个悖论了。好的训练数据是需要正确的data和错误的data都是合适的,正确的data是容易找的,而合适的错误data则比较难找,怎么产生合适的错误data,这又变成了一个死循环的问题。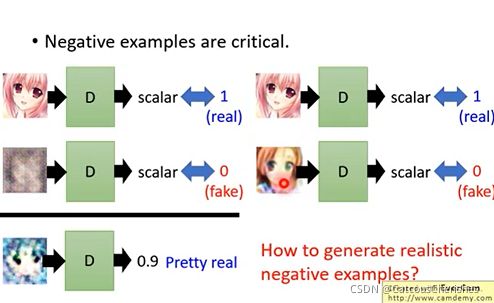
那怎么去解决这个死循环问题:正确的算法过程

我们需要好的负样本才能训练处一个判别器,我们需要一个好的判别器才能找出好的负样本
需要一个迭代的算法:
- 开始的时候有一堆正样本和负样本:正样本是真实图片,负样本是加了噪声后的图片;
- 将其样本放入Discriminator进行训练,Discriminator要做的事情就是给真样本高分,给假样本低分;
- 用训练好的Discriminator生成一组它认为好的图片。将该组图片作为假样本重新进行第二步的做法。循环训练。
5. Generator v.s. Discriminator
生成器和判别器的对比:
- 生成器的优点是很容易做生成,缺点是不考虑component之间的联系,在学习的时候,只是模仿目标的表象,没有学到目标的精神。
- 判别器的优势就是可以考虑到大局,但是缺陷是很难去生成一个东西。需要去解一个argmax的问题,这个问题其实是个大麻烦。

6. Generator + Discriminator
GAN就是取代了这个argmax的过程;现在我们用生成器去得到好的负样本来取代argmax D(x);因为生成器在训练的时候就是去学一些image,是可以骗过判别器的(就是可以打出高分)。
Generator与Discriminator 的优缺点是可以互补的,这也就是GAN的优势:

- 针对Discriminator,我们能够利用G很好地解决负样本的问题,这个是Discriminator缺乏的能力,G可以进化地去产生更好的负样本,去保证Discriminator更精准;也就是相当于求解了argmax的问题。
- 针对Generator,尽管还是每一个component每一个component地去生成对象,但是他会学到Discriminator的大局观。
7. 总结与展望
本章讲解单独的生成器能否自己学习,先是联系Auto-encoder的技术,可以做生成,但是会有问题,然后结合去噪自编码器,变分自编码器VAE等技术,可以得到较好的生成图片。仍然是存在没有大局观的问题,并且要VAE比GAN的网络结构更深才行。
以及单独的判别器能否自己生成图片,其做法是将真样本与随机假样本丢给D,去训练出真样本高分,假的低分;再用训练好的D去找出一个它认为好的假样本,用这个新的假样本去退换之前的假的,就这样一直训练。但是它的求解过程是有很大困难的(argmax问题)。
将生成器与判别器结合,GAN就是取代了上述argmax的过程;用生成器去得到好的负样本来取代argmax D(x),这样就很好的解决了它的难求解问题。
GAN的应用范围是十分广泛的,再近年来的论文中也是常常被引用的一项热门技术。实际上呢,只有那些有条件的生成器,而不是输入随机一个向量去做的,因为这样是没有办法得到我们想要的结果。之后的GAN都会有进一步的改善,才可以得到很多更有实际意义的应用。