卷积神经网络实例 —— 实现手写数字识别
1、卷积神经网络的基本结构
卷积神经网络是一种多层、前馈型神经网络。从功能上来说,可以分为两个阶段,特征提取阶段和分类识别阶段。
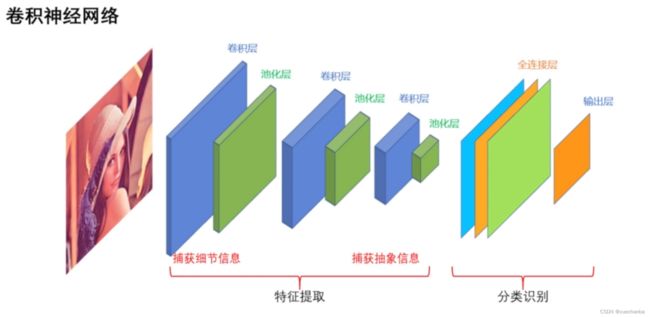
特征提取阶段能够自动提取输入数据中的特征作为分类的依据,它由多个特征层堆叠而成,每个特征层又由卷积层和池化层组成。处在前面的 特征层捕获图像中局部细节的信息,而后面的特征层能够捕获到图像中更加高层、抽象的信息。
分类识别阶段通常是一个简单的分类器,例如全连接网络或者支持向量机。它更加提取出的特征完成分类或识别任务。
2、使用 Keras 构建和训练卷积神经网络
在这节课中,我们以手写数字识别为例,介绍如何使用 Keras 构建和训练卷积神经网络。
2.1、构架卷积神经网络的结构
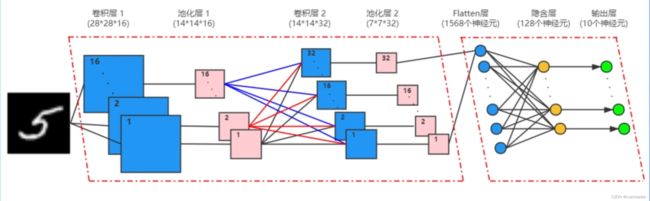
输入为手写数字图片,每张图片表示为 28 x 28 的二维张量,通道数为 1 。
这里,有两个特征层,其中,卷积核的尺寸均为 3 x 3,

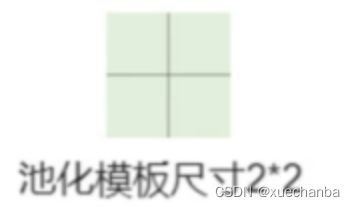
池化层均采用最大池化,池化模板的尺寸为 2 x 2,
在卷积层 1 中,一共有 16 个卷积核。每个卷积核提取出图像中的一种特征,得到一张 28 x 28 的特征图。所有卷积运算的结果构成一个28 x 28 x 16 的三维张量。
由于使用 2 x 2 的池化模板,所有这 16 张特征图的尺寸都缩小为原来的 1/4 ,成为 14 x 14 的二维张量。所以这 16 张特征图就构成了一个 14 x 14 x 16 的三维张量。可以看成是有 16 个通道的、大小为 14 x 14 的图像。
卷积层 2 接收来自池化层 1 的输出,使用 32 个卷积核得到 32 个特征图。
这里要注意的是,由于上一步的输出结果有 16 个通道,因此,这里的每一个卷积核都有 16 个通道,经过池化层 2 ,得到 32 个 7 x 7 的特征图,依然是一个三维张量。
特征提取阶段结束。
下面,进入分类识别阶段。由于全连接网络只能接收一维的输入,因此,首先采用一个 flatten 层将池化层 2 输出的三维张量转化为一维张量后再传递给后面的隐含层,隐含层有一层,其中,有 128 个神经元。
手写数字识别是一个 10 分类的任务,因此输出层中有 10 个结点,分别对应 0~9 这十个数字。
2.2 使用 Keras 构建这个卷积神经网络
2.2.1 创建卷积层
在 Keras 中,使用下面这个函数来创建卷积层。

其中,
参数 filters 表示卷积核的数量,
参数 kernel_size 表示卷积核的大小。
参数 padding 表示扩充图像边界的方式,取值可以是 same 和 valid ,same 表示用 0 来扩充图像边界,valid 表示使用边界本来的值进行扩充。
参数 activation 用来设置激活函数,
参数 input_shape 表示输入卷积层的数据形状,是一个四维张量,分别是 samples(样本数),rows(行数),cols(列数),channels (通道数)。一般只需要给出后面三维即可。第一个维度是由 batch_size 自动指定。和全连接层一样,只有第一层卷积层需要设置输入数据的形状,后面的卷积层接收上一层的输出作为输入。
下图中的代码为创建卷积层 1 ,一共有 16 个卷积核,每个卷积核的大小为 3 x 3 ,

在进行卷积运算时,使用全 0 来扩充图像边界 ,采用 relu 函数作为激活函数,输入图像是 28 x 28 的。
因为 Mnist 数据集中的数据是灰度图像,所以通道数为 1 。
2.2.2 创建最大池化层
Keras 中使用

函数来创建最大池化层。
由参数 pool_size 来指定池化窗口的大小。
例如,

表示创建尺寸为 2 x 2的最大池化层。
2.2.3 构建卷积神经网络
# 首先创建一个 Sequential 对象 model, 添加卷积层 1 ,
model = tf.keras.Sequential([
# unit 1
# 添加卷积层 1 , 卷积核数量为 16, 卷积核的大小为 3 x 3,
tf.keras.layers.Conv2D(16, kernel_size=(3, 3), padding="same", activation=tf.nn.relu, input_shape=(28, 28, 1)),
# 添加池化层 1, 采用最大池化, 池化模板尺寸为 (2, 2)
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
# unit 2
# 添加卷积层 2 , 卷积核数量为 32, 卷积核的大小为 3 x 3, 由于直接接收上一层的输出, 所以这里无需对输入形状进行设置
tf.keras.layers.Conv2D(32, kernel_size=(3, 3), padding="same", activation=tf.nn.relu),
# 添加池化层 2, 采用最大池化, 池化模板尺寸为 (2, 2)
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
# 至此, 特征层构建完成.
# unit 3
# 添加 Flatten 层, 将池化层的输出的三维张量转化为一维张量
tf.keras.layers.Flatten(),
# unit 4
# 最后, 再添加一个隐含层核一个输出层, 隐含层中的结点个数为 128 ,
tf.keras.layers.Dense(128, activation="relu"),
# 输出层中的结点个数为 10
tf.keras.layers.Dense(10, activation="softmax")
])
2.2.4 查看构建的卷积神经网络结构和参数信息
model.summary()
输出结果如下,
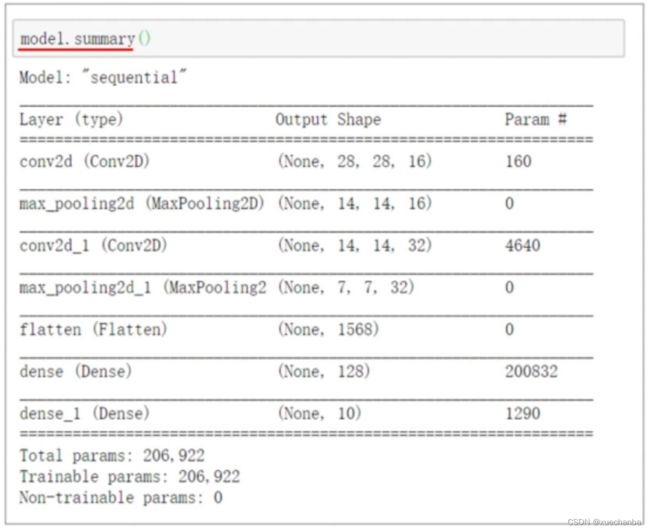
可以看到每一层的名称、输出的形状以及每一层的参数个数。
其中,卷积层参数个数的计算公式如下:
![]()
(加的那个1是偏置项)
所以
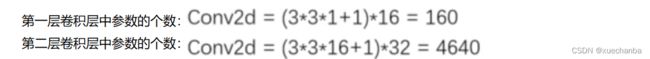
池化层只比较大小,没有引入新的参数。参数个数为 0 .
全连接层的参数个数的计算公式如下:
![]()
所以,
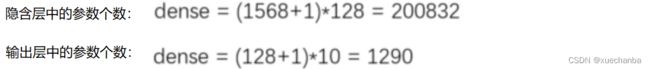
最终,总共参数个数为:160 + 4640 + 200832 + 1290 = 206922.
2.2.5 完整代码如下:
# 一:导入库函数
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
print(train_x.shape) # (60000, 28, 28)
print(train_y.shape) # (60000,)
print(test_x.shape) # (10000, 28, 28)
print(test_y.shape) # (10000,)
# 四:数据预处理
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
Y_train, Y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 由于卷积函数中的参数 input_shape 要求输入为四维张量, 最后一维是通道数
# 而 mnist 数据集是灰度图像, 是三维数据, 没有表示通道的维度, 因此, 需要
# 将其转化为四维数据.增加一个通道维度.
X_train = train_x.reshape(60000, 28, 28, 1)
X_test = test_x.reshape(10000, 28, 28, 1)
print(X_train.shape) # (60000, 28, 28, 1)
print(X_test.shape) # (10000, 28, 28, 1)
# 五:建立模型
# 首先创建一个 Sequential 对象 model, 添加卷积层 1 ,
model = tf.keras.Sequential([
# unit 1
# 添加卷积层 1 , 卷积核数量为 16, 卷积核的大小为 3 x 3,
tf.keras.layers.Conv2D(16, kernel_size=(3, 3), padding="same", activation=tf.nn.relu, input_shape=(28, 28, 1)),
# 添加池化层 1, 采用最大池化, 池化模板尺寸为 (2, 2)
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
# unit 2
# 添加卷积层 2 , 卷积核数量为 32, 卷积核的大小为 3 x 3, 由于直接接收上一层的输出, 所以这里无需对输入形状进行设置
tf.keras.layers.Conv2D(32, kernel_size=(3, 3), padding="same", activation=tf.nn.relu),
# 添加池化层 2, 采用最大池化, 池化模板尺寸为 (2, 2)
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
# 至此, 特征层构建完成.
# unit 3
# 添加 Flatten 层, 将池化层的输出的三维张量转化为一维张量
tf.keras.layers.Flatten(),
# unit 4
# 最后, 再添加一个隐含层核一个输出层, 隐含层中的结点个数为 128 ,
tf.keras.layers.Dense(128, activation="relu"),
# 输出层中的结点个数为 10
tf.keras.layers.Dense(10, activation="softmax")
])
# 六:查看构建的卷积神经网络结构和参数信息
model.summary()
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
flatten (Flatten) (None, 1568) 0
_________________________________________________________________
dense (Dense) (None, 128) 200832
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 206,922
Trainable params: 206,922
Non-trainable params: 0
_________________________________________________________________
"""
# 七:配置模型训练方法
model.compile(optimizer='adam', # 优化器
loss='sparse_categorical_crossentropy', # 损失函数
metrics=['sparse_categorical_accuracy']) # 模型训练时, 我们希望输出的评测指标
# 八:训练模型
history = model.fit(X_train, Y_train, batch_size=64, epochs=5, validation_split=0.2)
"""
750/750 [==============================] - 11s 6ms/step - loss: 0.6558 - sparse_categorical_accuracy: 0.9245
- val_loss: 0.0965 - val_sparse_categorical_accuracy: 0.9707
Epoch 2/5
750/750 [==============================] - 5s 6ms/step - loss: 0.0753 - sparse_categorical_accuracy: 0.9772
- val_loss: 0.0769 - val_sparse_categorical_accuracy: 0.9793
Epoch 3/5
750/750 [==============================] - 5s 7ms/step - loss: 0.0484 - sparse_categorical_accuracy: 0.9855
- val_loss: 0.0642 - val_sparse_categorical_accuracy: 0.9826
Epoch 4/5
750/750 [==============================] - 5s 6ms/step - loss: 0.0337 - sparse_categorical_accuracy: 0.9891
- val_loss: 0.0618 - val_sparse_categorical_accuracy: 0.9837
Epoch 5/5
750/750 [==============================] - 5s 6ms/step - loss: 0.0313 - sparse_categorical_accuracy: 0.9901
- val_loss: 0.0790 - val_sparse_categorical_accuracy: 0.9808
"""
# 九:使用测试集中的数据来评估模型性能
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, Y_test, batch_size=64, verbose=2)
"""
157/157 - 2s - loss: 0.0706 - sparse_categorical_accuracy: 0.9811
"""
# 十:保存训练的日志文件
pd.DataFrame(history.history).to_csv("training_log.csv", index=False)
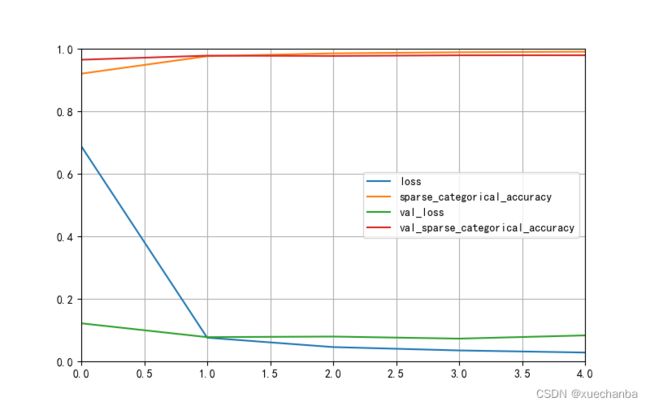
# 十一: 绘制训练曲线
# 读取保存后的训练日志文件
graph = pd.read_csv("training_log.csv")
# 绘制训练曲线
graph.plot(figsize=(8, 5))
plt.grid(1) # 网格线
plt.xlim(0, 4)
plt.ylim(0, 1)
# 十二:应用模型 -- 预测数据
# 下面再随机取出测试集中的任意 10 个数据进行识别
plt.figure()
for i in range(10):
num = np.random.randint(1, 10000)
plt.subplot(2, 5, i + 1)
plt.axis("off")
plt.imshow(test_x[num], cmap="gray")
demo = model.predict(tf.reshape(X_test[num], (1, 28, 28, 1)))
y_pred = np.argmax(demo)
plt.title("y= " + str(test_y[num]) + "\n" + "y_pred=" + str(y_pred))
plt.suptitle("随机取出测试集中的任意10个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
plt.show()
# 十三:保存模型
model.save("mnist_model_convolutional.h5")
运行结果如下,

2.2.6 加载模型并输出每次的预测概率:
# 一:导入库函数
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
print(train_x.shape) # (60000, 28, 28)
print(train_y.shape) # (60000,)
print(test_x.shape) # (10000, 28, 28)
print(test_y.shape) # (10000,)
# 四:数据预处理
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
Y_train, Y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 由于卷积函数中的参数 input_shape 要求输入为四维张量, 最后一维是通道数
# 而 mnist 数据集是灰度图像, 是三维数据, 没有表示通道的维度, 因此, 需要
# 将其转化为四维数据.增加一个通道维度.
X_train = train_x.reshape(60000, 28, 28, 1)
X_test = test_x.reshape(10000, 28, 28, 1)
print(X_train.shape) # (60000, 28, 28, 1)
print(X_test.shape) # (10000, 28, 28, 1)
# 五:加载模型
model = tf.keras.models.load_model("mnist_model_convolutional.h5")
# 六:使用测试集中的数据来评估模型性能
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, Y_test, batch_size=64, verbose=2)
"""
157/157 - 2s - loss: 0.0706 - sparse_categorical_accuracy: 0.9811
"""
# 七:应用模型 -- 预测数据
# 下面再随机取出测试集中的任意 10 个数据进行识别
plt.figure(figsize=(12, 8))
for i in range(10):
num = np.random.randint(1, 10000)
plt.subplot(2, 5, i + 1)
plt.axis("off")
plt.imshow(test_x[num], cmap="gray")
demo = model.predict(tf.reshape(X_test[num], (1, 28, 28, 1)))
y_pred = np.argmax(demo)
y_percent = np.round(demo[0][y_pred], 5)
plt.title("y= " + str(test_y[num]) + "\n" + "y_pred=" + str(y_pred) + "\n" + "percent=" + str(y_percent))
plt.suptitle("随机取出测试集中的任意10个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
plt.show()
运行结果如下,

(这里出现预测错误的情况了)
每次预测的概率也可以显示,由于这里的预测准确率都非常的高且保留的小数位数少,所以四舍五入之后基本都为1.0 。