Coursera自动驾驶课程第20讲:Mission Planning in Driving Environments
在第19讲《Coursera自动驾驶课程第19讲:Mapping for Planning》 我们学习了自动驾驶中两种环境建图方法:占用网格图(occupancy grid map) 和 高清地图(high-definition road map)。
在本讲中,我们将详细讨论自动驾驶中的任务规划问题以及如何解决它。正如在第18讲中介绍的,任务规划在整个规划问题中处于最高层,它对于如何将自动驾驶汽车导航到目的地至关重要。我们在本讲将首先介绍图这一概念以及如何在我们的任务规划器中使用它。此外,我们将讨论如何使用有向图来表示我们需要穿过的道路网络。最后,我们将讨论广度优先搜索算法以及如何将其应用于任务规划。
文章目录
-
-
- 20.1 Creating a Road Network Graph
-
- 20.1.1 Graphs
- 20.1.2 Breadth First Search
- 20.2 Dijkstra's Shortest Path Search
-
- 20.2.1 Unweighted/Weighted Graph
- 20.2.2 Dijkstra's Algorithm
- 20.3 A-Star Shortest Path Search
-
20.1 Creating a Road Network Graph
20.1.1 Graphs
让我们回顾一下自动驾驶任务。其目标是在导航地图中,找到自车从当前位置到给定目的地的最佳路径。在本课程中,我们将根据汽车到达目的地所需的时间或距离来考虑最优性。对于自动驾驶,任务规划被认为是最高一级的规划问题。

在自动驾驶中,任务规划的空间规划规模往往是公里级的,在任务规划中往往并不关注障碍物或动力学等低级规划约束。相反,任务规划时将关注道路网络的各个方面,例如速度限制和道路长度、交通流量和道路封闭与否。基于地图给我们带来的这些限制,任务规划时需要找到到达我们所需目的地的最佳路径。关于道路网络需要注意的一点是,它是高度结构化的,我们可以在规划过程中利用这一点来简化问题。通过利用该结构,我们可以根据提供给我们的地图有效地找到到达目的地的最佳路径。 为此,我们将需要使用一种称为图的数据结构,我们已将其覆盖在此处的道路网络上。
那么什么是图呢? 图是由以 V V V 表示的顶点集合和以 E E E 表示的边集合而组成的(如下图所示)。在任务规划中, V V V 中的每个顶点将对应于道路网络上的某个点, E E E 中的每条边将对应于连接道路网络中任意两个点的路段。从某种意义上来说,图中的一系列连接的边对应于道路网络中从一个点到另一个点的路径。在下图中我们假设了每个路段的长度是相等的,因此该图的边都是未加权的。
但是,在后面的课程中,我们会介绍加权的图。注意,图的边通常是有向的,我们通过在图中的边上使用箭头来显示它们的方向。现在我们有了有向图,我们如何找到到达目的地的最佳路径呢?首先,我们在图中已知我们当前自车位置(表示为 S S S)和我们希望的目的地(表示为 t t t)的顶点。这两个顶点显示在此处的图上。
一旦我们有了这两个顶点,我们就可以使用高效的图搜索算法来找到到达目的地的最优或最短路径。由于我们的图形公式目前没有加权,一个好的候选算法是广度优先搜索或 BFS。

20.1.2 Breadth First Search
在BFS 算法中我们常用到三种数据结构:Queue()、Set()、Dict(),分表存储未遍历的顶点、已经遍历过的顶点和用来存储节点之间连接关系的字典。队列是一种先进先出(FIFO)的数据结构,因此第一个入队的顶点也是第一个出队的顶点。字典是一组无序的键值对,对于字典种的每个节点,我们可以很容易找到在此节点之前的顶点。

为了帮助我们理解 BFS 算法,让我们来看一个具体的例子。
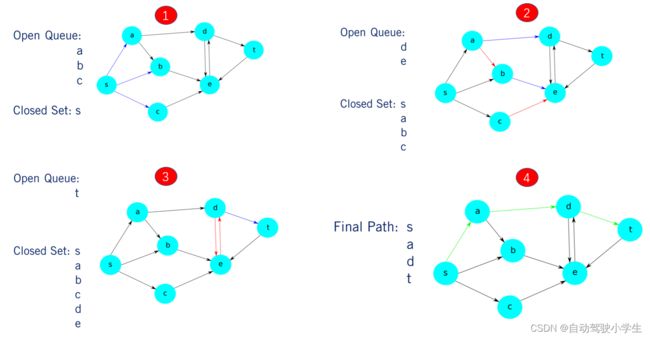
- 假设我们的任务规划器需要通过我们图中现在标记的顶点集找到从点 s s s 到目的地 t t t 的最佳路径,第一步是处理原点 s s s 并将所有相邻顶点添加到我们的队列中并设置他们的前任节点为 s s s。相邻顶点的边以蓝色显示。一旦我们将这些相邻点添加到我们的队列中,我们就会将 s s s 添加到我们的闭集中。
- 接下来,我们弹出顶点 a a a。 a a a 有两条边分别指向 d d d 和 b b b,但 b b b 已经在我们的队列中,因此,我们只将 d d d 添加到队列中并将 a a a 标记为它的前任节点。我们用红色突出显示了这个重复的路径,以表明我们没有将 b b b 添加到队列中两次。我们现在已经处理了来自 a a a 的所有相邻顶点并将其添加到闭集。我们对 b b b 重复相同的过程,将 e e e 添加到队列中,其中 b b b 作为其前任节点,而 c c c 没有新的相邻顶点(其顶点仍然是 e e e)。
- 接下来,我们从队列中弹出 d d d,它只将 t t t 添加到队列中,其中 d d d 作为其前任节点(因为 e e e 已经添加)。当 e e e 被弹出时,它不会将 c c c 或 d d d 添加到队列中,因为这两个顶点都已被处理并存在于闭集中且对应的边是单向的(从 e e e 到达不了 b b b 或 t t t)。
- 最后,我们从队列中弹出 t t t,这是我们的
目标顶点。所以我们现在通过从 t t t 到 s s s 的前任链来重构从 s s s 到 t t t 的路径。完成此操作后,我们就找到了到达目的地的最佳路径,该路径以绿色突出显示。然后可以使用我们的地图将对应于图中最佳路径的边序列转换为道路网络的边序,将其用于在我们的规划层次结构的后续层中处理更详细的运动规划。
 我们应该注意,除了广度优先搜索还有深度优先搜索算法。
我们应该注意,除了广度优先搜索还有深度优先搜索算法。深度优先搜索使用后进先出堆栈而不是先进先出的队列。此更改意味着评估最近添加的顶点而不是最旧的顶点。结果是搜索在图中快速移动更深,然后最终回溯到更早添加的顶点。
在下一小节,我们将通过向图中的边添加不同的权重来使图更复杂,以更好地反映使用不同路段的不同成本,我们将介绍 Dijkstra 算法。
20.2 Dijkstra’s Shortest Path Search
20.2.1 Unweighted/Weighted Graph
在本小节,我们将修改上一小节中的无权重图来给图中的边加上权重,为我们的任务规划问题提供更合适的表示。然后,我们将讨论这会如何影响我们的算法,以及我们如何在有效规划的同时克服这一挑战。特别地,我们应该能够理解加权图和未加权图之间的区别,以及为什么加权图对任务规划更有用。同时我们应该牢牢掌握 Dijkstra 算法,对加权图非常有用的图搜索算法。
回顾一下,在上一小节,我们介绍了广度优先搜索算法。然而在这个过程中,我们假设所有路段的长度都相等,这是一个过于简单的假设。根据道路长度、交通、速度限制和天气等因素,不同路段的通过成本可能会有很大差异。为简单起见,我们最初仅关注图中的距离。为了反映这一点,我们将为图中的每条边添加权重,对应于相应路段的长度(权重的单位是任意的,只要它们对所有边都是通用的就可以。对于这种情况,假设边的权重是通过该路段所需的公里数)。
下图左边为无权重图,右边为加了权重后的图。和之前一样,我们的目标还是找到从自车当前位置 s s s 到最终目的地 t t t 的最优路径。不幸的是,我们的 BFS 算法没有考虑边的权重。所以不能保证在这种情况下找到最优路径。为此,我们需要使用更强大的算法。

20.2.2 Dijkstra’s Algorithm
Dijkstra 算法,荷兰计算机科学家 Edsger Dijkstra 于 1956 年首次构想出。在 2001 年的一次采访中,他解释说当时他正在和未婚妻一起购物,累了就坐了下来喝杯咖啡。他一直在思考最短路径问题,在 20 分钟内,他在没有纸笔的情况下完成了他的算法。他又花了三年时间写了一篇关于这个主题的论文,但他将这个想法的简单和优雅归功于被迫完全在他的脑海中完成解决方案。
Dijkstra 算法的整体流程与 BFS 非常相似。主要区别在于处理顶点的顺序。下图用蓝色突出显示了与 BFS 算法的区别。关键区别在于,我们将使用最小堆,而不是使用队列。最小堆是一种存储键和值的数据结构,并根据键的值从小到大对键进行排序。在我们的例子中,图中每个边的权重的将对应于从一个顶点到达另一个顶点所需的距离。

为了巩固我们的理解,让我们逐步将 Dijkstra 算法应用于我们的新加权图。
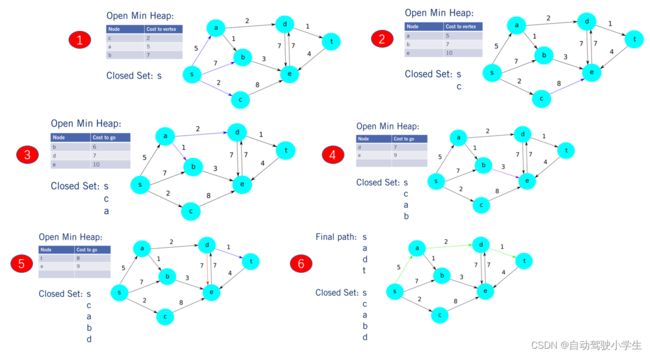
- 与
BFS一样,要处理的第一个顶点是 s s s,然后将 a 、 b 、 c a、b、c a、b、c 添加到最小堆中。因此到达 a 、 b 、 c a、b、c a、b、c 的成本分别为 5、7 和 2。由于我们使用的是最小堆而不是队列,因此最小堆中的顶点顺序现在是 c 、 a 、 b c、a、b c、a、b (成本从低到高排序),然后将 s s s 添加到闭集。 - 接下来,我们从堆中弹出 c c c。因为它是迄今为止成本最低的顶点。 c c c 只连接到顶点 e e e。因此,我们将其添加到最小堆中,成本为 2+8 为 10,同时将 c c c 作为其前任节点。我们的新堆排序是 a 、 b 、 e a、b、e a、b、e ,然后我们将 c c c 添加到闭集。
- 下一个从堆中弹出的顶点是 a a a,它连接到 d d d 和 b b b。 d d d 尚未被访问,因此我们将其添加到堆中,成本为 5+2 为 7。然而 b b b 已经被访问,它目前的累计成本为 7。边 a b ab ab 的权重为 1,因此经过 a a a 的新成本是 5+1 等于 6。由于这低于 b b b 的当前成本(当前为 7 ),我们将堆中 b b b 的成本更新为 6,并将其前任节点从 s s s 更改为 a a a。为了表明 b b b 的成本已更新,我们将新边标记为紫色,然后将 a a a 添加到闭集。
- 现在最小堆中的顶点顺序现在是 b 、 d 、 e b、d、e b、d、e。我们现在从堆中弹出 b b b,它只连接到 e e e。到目前为止到达 b b b 的成本是 6,因此我们到达 e e e 的成本是 9 。而 e e e 已经存储在最小堆中,成本为 10。因此,我们需要将 e e e 的成本更新为 9,并将其前任节点从 c c c 更改为 b b b。最后,我们将顶点 b b b 添加到闭集,我们在最小堆中的新顶点排序是 d 、 e d、e d、e。
- 接下来,我们从堆中弹出 d d d。 e e e 已经在堆中,成本为 9,从 d d d 到 e e e 的新路径的成本为 14。由于这高于 e e e 当前的成本,我们可以忽略这条新路径。为了表明我们忽略了它,我们将 e e e 的新边标记为红色而不是紫色。然后,我们将 t t t 添加到成本为 7 的堆中,加 1 后为 8,将 d d d 设置为其前任节点。最后,我们将 d d d 添加到闭集。
- 我们的新堆排序是 t t t,然后是 e e e。我们弹出的最后一个顶点是 t t t,这是我们的目标顶点。这样就完成了规划过程,我们现在通过将 t t t 的前任节点链接在一起形成了一条最佳路径,一直到原点,如图所示。
接下来,让我们看看这个任务规划问题在真实地图上的样子。在这里,我们有一张加利福尼亚州伯克利的地图。图中的顶点对应于交叉路口,边对应于我们前面讨论的路段。两个红点,对应于我们计划的起点和终点。我们必须记住,某些道路是单向道路。因此,该图是有向的。运行 Dijkstra 算法后,两个节点之间的最短路径由红色路径给出。Dijkstra 的算法非常有效,这使得它可以很好地扩展到现实世界的问题,例如此处显示的问题。
