机器学习初探:(一)机器学习绪论
(一)机器学习绪论
文章目录
- (一)机器学习绪论
-
- 什么是机器学习?
- 数据科学、人工智能、机器学习、深度学习
-
-
- 人工智能(Artificial Intelligence, AI)
- 机器学习(Machine Learning, ML)
- 深度学习(Deep Learning,DL)
- 数据科学(Data Science, DS)
-
- 机器学习是怎么学习的?
- 机器学习的分类
-
- 有监督学习(Supervised Learning)
-
- 回归(Regression)
- 分类(Classification)
- 无监督学习
- 弱监督学习
- 强化学习
- 小结
- 参考资料
什么是机器学习?
作为开场,我们先大致了解一下什么是“机器学习”(machine learning)。
既然名为“学习”,那自然与我们人类的学习过程有某种程度的相似性。
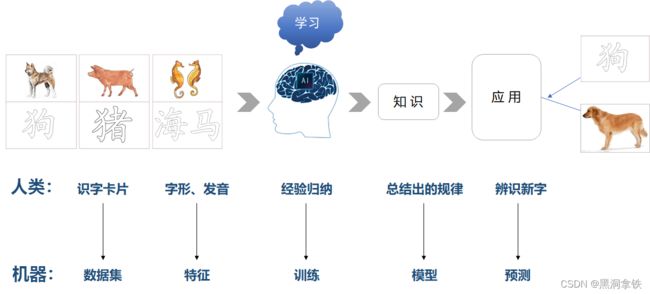
回想一下,我们小时候是如何学习识字的呢?家长会为我们准备很多图文并茂的识字卡片,小朋友的大脑在接受许多遍相似图像的刺激后,为每个汉字总结出了某种规律性的东西,下次大脑再看到符合这种规律的图案,就知道是什么字了。要教计算机认字,差不多也是同样的道理1。
机器学习正是这样一门学科,它致力于研究计算机如何模拟或实现人类的学习行为,以获取经验,并用之不断改善自身的性能。在计算机系统中,“经验”通常以“数据”形式存在。
人类通过看、听、经历等获取信息,然后使用归纳、演绎等方法进行学习,最后总结形成知识和智慧;而机器学习是通过数据训练,使用算法挖掘事物背后隐藏的规律和本质,得到模型,用于预测或推断。
模型 = 数据 + 算法
下图1将“小朋友的识字过程”与“机器学习”过程做了一个类比,我们学习使用的“识字卡片”在机器学习领域相当于训练使用的“数据集”,我们根据“字形、发音”等的差异来辨识不同字,这在机器学习领域被称为“特征”,根据特征的差异总结、归纳的过程对应于“训练”,总结出的规律表现为“模型”,人类将总结出的知识应用于辨识新字的过程,即对应于机器学习领域使用训练好的模型进行"预测或推理"。
数据科学、人工智能、机器学习、深度学习
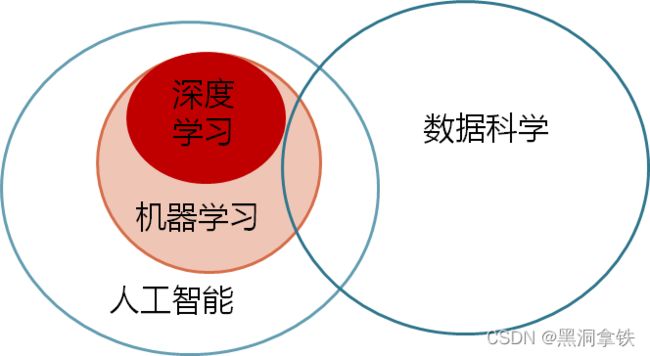
当我们开始关注这个领域之后,耳边经常会充斥着 “数据科学”、“人工智能”、“机器学习”、“深度学习”等术语,这些可谓是人工智能时代的流行语了,在某些场合中经常被不加区分的混合使用。
那么它们究竟指什么呢,之间又有怎样的区别和联系呢?在正式介绍机器学习的学习过程和算法之前,有必要对这几个概念进行辨析。
如果用一张图来表示它们之间的联系的话,可参考下图22:
人工智能(Artificial Intelligence, AI)
IOT For All 解释说,人工智能描述的是能模仿人类行为执行任务的机器。因此,人工智能意味着人工地模仿人类智能的机器。
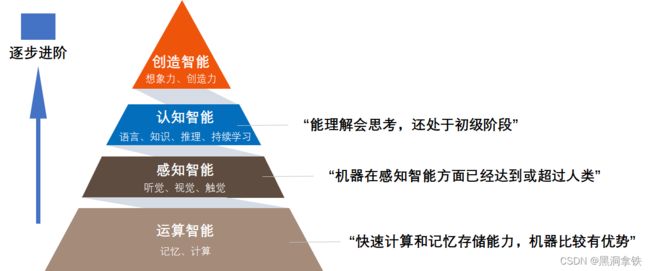
那么什么是人类智能呢?人类智能可以理解为,与人类思维相关的认知功能(如感知、推理、学习和解决问题)的能力,包括一系列通过人工智能解决业务问题的能力。相对应的,人工智能的主要发展方向包括:运算智能、感知智能、认知智能、创造智能,如下图3所示。这一观点如今也得到业界广泛的认可。
机器学习(Machine Learning, ML)
机器学习是一种实现人工智能的技术。 通过机器学习,我们教会了机器如何执行特定的任务,比如识别图像中的猫狗(图像识别)、为用户推荐其感兴趣的电影(推荐系统)、通过设备运行数据检测是否存在异常(异常检测)等等。
ML算法有许多类型,包括线性回归、逻辑回归、支持向量机、朴素贝叶斯、决策树等等。
深度学习(Deep Learning,DL)
深度学习是许多ML方法中的一种,以深度神经网络算法为代表。 DL算法受人脑神经系统处理复杂信息进行决策判断的启发,构建了一个人工神经网络(Artifical Neural Network, ANN),在它的输入层和输出层之间有多个层,用于抽象和刻画不同维度的信息。深度学习中的“深度”指的就是这个网络的层数,众多的层使得刻画复杂规律成为可能。
谷歌的AlphaGo就是深度学习技术的一个例子,通过从上千万人类棋谱、几十万盘围棋高手之间的对弈数据训练,最终先后击败了世界围棋冠军李世石、柯洁。
数据科学(Data Science, DS)
数据科学是一个更广泛的领域,从数据中总结规律、形成数据洞察(探索性数据分析),或基于大型数据集进行分析预测等(预测性分析)。 DS涵盖了大规模数据的采集、管理、分析和解释等过程,具有广泛的应用。可以认为,它集成了以上所有领域,并包括了其他更多范畴,涉及许多不同的学科和工具,比如统计推理、领域知识(专家知识)、数据可视化、实验设计和通信。
题外话:关于这些术语的边界其实是比较模糊的,即便是专业人士也是众说纷坛、互不信服,感兴趣的可以参见文末“大数据挖掘、机器学习、人工智能的维恩图战争”3。
机器学习是怎么学习的?
我们前面提到了,机器学习即是解析数据、从数据中学习背后的规律,并将之用于预测或推断的过程。那么机器究竟是如何实现学习的呢?
机器学习运作机理如下图4:
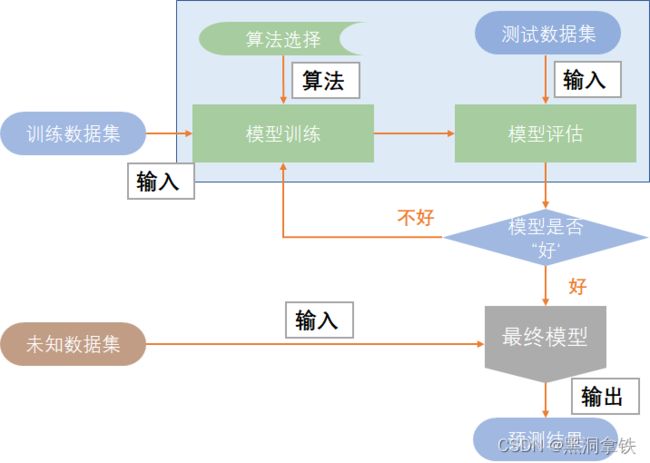
- 训练数据集:从数据集中划分出一部分作为训练数据集,用来进行模型训练。
- 算法选择:一般要从业务场景出发,综合考虑问题的特点、数据的情况,根据经验选择一种合适的算法。
- 模型训练及评估:使用算法在训练数据集上进行训练(学习过程),在测试数据集上评估模型是否是一个”好“的模型,并以此为依据,决定是否结束训练过程。类似于我们小时候的学习过程,一次次的课后作业、随堂测验、期中期末考都是用来检查我们是否掌握了所学的知识,哪些知识掌握的不好,需要巩固加强。
- 模型使用:将需要预测的数据输入至训练好的模型,得到最终的预测结果。所有的课程、作业、测验都是为了应对最终的中高考,中高考会出什么题我们事先是不知道的,但基本知识点应该是跑不出我们之前学过的内容、刷过的习题册,我们希望学习的结果可以自如应对这些未知的题目,机器学习也是同样的道理。
机器学习的分类
从学习方式来说,机器学习还可分为有监督学习、无监督学习、弱监督学习、强化学习,学习过程和上图4类似,主要区别在于训练数据集里告不告诉机器正确答案。训练集给定了正确答案的叫有监督学习,训练集未指定正确答案的为无监督学习,训练集给了部分正确答案的叫弱监督学习。
有监督学习(Supervised Learning)
有监督学习是机器学习任务的一种。它从有标记的训练数据中推导出预测函数。有标记的训练数据是指每个训练实例都包括输入 x x x 和期望的输出 y y y(即,正确答案)。有监督学习又分为回归和分类两大任务类型。
一句话概括有监督学习:给定数据集 ( x , y ) (x,y) (x,y),能够基于 x x x 预测 y y y
回归(Regression)
回归这个词的意思是,我们在试着推测出一系列连续值属性。
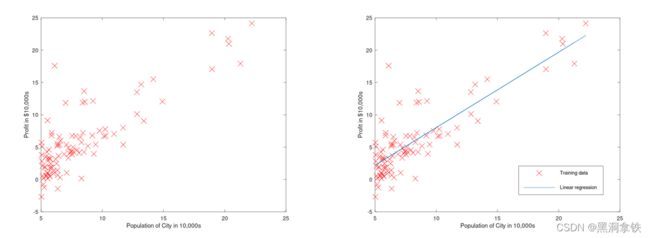
假设您是一家餐饮连锁店的 CEO,并且正在考虑在不同城市开设新的门店,您可以获得各个城市的人口数据和利润数据。如何依据这组数据决定在哪个城市开设分店呢?4
那要先看看数据是否呈现了某种规律?下图5所示横坐标为城市人口数,纵坐标为利润数据。可以发现,人口越多的城市,餐厅的利润也普遍越高。最直观的想法就是,我能不能拟合一条直线来刻画这种关系,这条直接应该能穿过大多数的数据点,这样对于一个新的城市,我就可以根据城市人口数,大致估计餐厅的利润额了,这就是一个典型的回归任务。
分类(Classification)
分类和回归最大的区别在于,我们在试着推测出几个离散值(类别)属性。
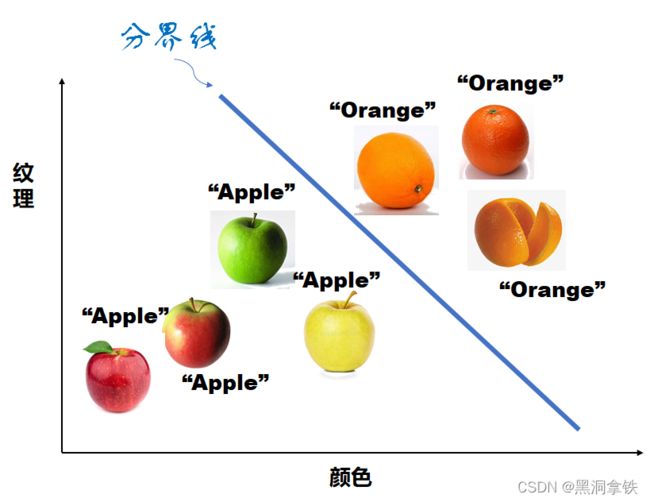
还是举个例子来说明,桌子上放了一个水果,我们一眼就能分辨出是苹果还是橘子。那么如何让机器进行识别呢?如果我们有一个水果传感器,能观测并输出水果的特征,如:纹理(表面是否粗糙)、颜色、形状和重量等等,将这些水果特征输入机器,并告诉它这是苹果还是橘子。慢慢地,机器就学会了:橘子的表面一般是粗糙的,颜色一般是橘黄色的;苹果的表面一般是光滑的,颜色有红色、绿色、黄色等等…
如下图6所示,基于“纹理”和“颜色”两个特征,机器找到了区分两种水果的标准(表示在图中即为,分界线)。接下来,对于一个不明类别的水果,机器通过判断它是处于分界线的上方还是下方,就可以自己分辨苹果和橘子了。这就是一个典型的分类任务。
在图5餐厅连锁店利润预测的例子中,如果我们人为地将利润额划分为几个区间,比如低、中、高三档,根据每个城市人口数预测分店的利润处于哪个档,这样一个回归问题就转化为了分类问题。此外,判断是否为垃圾邮件,预测明天的天气是晴、多云、还是有雨,识别图像中的猫狗等,都是分类问题。
无监督学习
无监督学习是机器学习任务的一种。它从无标记的训练数据中推断结论。无标记的训练数据是指每个训练实例都包括输入 x x x ,但不包括期望的输出 y y y(即,正确答案)。最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。
一句话概括无监督学习:给定数据集 ( x , ) (x, \quad) (x,),寻找隐藏的结构。
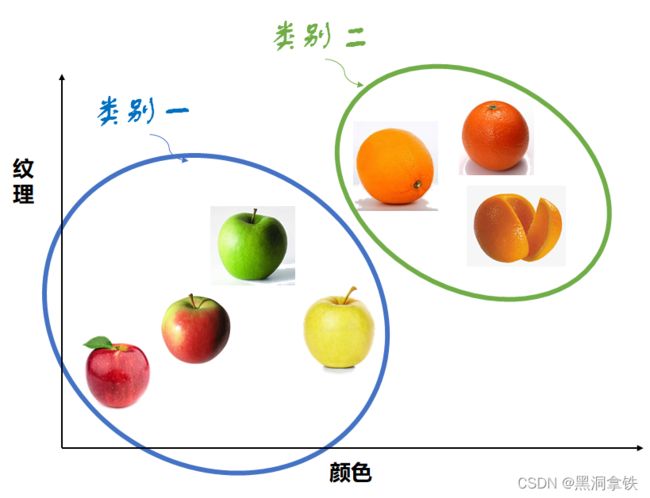
在图6区分苹果和橘子的例子中,我们明确地告诉了机器它“看到”的是什么水果(也即,我们反复提及的正确答案),那如果我们不告诉机器正确答案,机器能从传感器采集到的水果特征中学习出什么信息呢?
机器仍能通过水果颜色、纹理特征识别出两个类别:一类相对表面比较粗糙、颜色为橘色;另一类相对表面比较光滑、颜色很少有橘色,只不过机器不知道这两类分别对应什么而已。这便是无监督学习中的一类典型问题——聚类问题(如下图7所示)。
无监督学习解决的主要是以下问题:
* 没有标签,如何查找隐藏在数据集里面的内在结构?
* 没有标签,如何总结出规律形成最有用的组合?
弱监督学习
大多数成功的技术,如深度学习,都需要含有真值标签的大规模训练数据集。然而,在许多任务中,由于数据标注过程的成本极高,很难获得强监督信息,那我们该怎么办呢?
弱监督学习是相对于强监督学习和无监督学习来说的,当我们得到的数据集之中只有一部分数据有标签,而另一部分数据没有标签,或者数据集中标签质量较低(比如,打错的、不全的、冲突的等情况),但我们还是想训练一个不错的模型,我们称其为弱监督学习。
弱监督学习具体包括三类:
-
一是,不完全监督,即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签;
-
二是,不确切监督,即,图像只有粗粒度的标签;
-
三是,不准确的监督,即,模型给出的标签不总是正确的。
一句话概括弱监督学习:让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能。
弱监督学习在实际应用场景中具有广泛的应用价值,比如医学影像中病理切片的解读。病理图片通常很大,一张病理图片可以达到 5万 × 5 万像素,甚至更大。详细标出图像中癌细胞和正常细胞的边界工作量巨大,尤其中国医疗资源极度匮乏、病理图片标注的专业门槛又比较高,很难实现构建带详细标签的训练数据集。弱监督学习的优势为:在减少标注工作量的情况下,更充分、有效地利用数据。 具体来说,对于一张既有癌细胞又有正常细胞的病理切片图像,只需要提供这两类图片,无需勾画所有癌细胞和正常细胞的边界,系统就能学习出标注规则。
强化学习
强化学习是机器学习的另一个领域。它关注的是在没有任何标签的情况下,通过与环境的不断交互,来不断优化自身策略的算法。
下图8描述了经典的强化学习场景中,智能体与环境不断交互的过程:在 t t t 时刻,智能体获得了环境状态 S t S_t St,经过计算输出动作值 A t A_t At 并在环境中执行,环境会返回 t + 1 t+1 t+1 时刻的环境状态 S t + 1 S_{t+1} St+1 与上一个时刻产生的奖励 R t R_t Rt。
一句话概括强化学习:给定数据集 ( , ) (\quad,\quad) (,),学习如何选择一系列行动,以最大化长期收益。

打个比方,你想让一个小孩子坐下来复习考试,这是非常困难的。但是如果每次完成一个话题时都给他一块巧克力,他就会明白,如果他继续学习,他就会得到更多的巧克力棒,这样他就会有动力去复习。然而一开始,这个孩子并没有时间观念,也不知道该如何准备,他可能会花费数小时研究一个话题,而无法按时完成教学大纲内的所有复习内容。那么,如果他在1个小时内完成了一个话题,我们就给他一个大块的巧克力;如果他花了1.5个小时,就给他一小块巧克力;如果他花了更长的时间,就只给他一块太妃糖。渐渐地,这个孩子不仅知道了学习,而且会找到方法如何更快地完成任务。
在上面这个例子中,孩子即对应智能体(Agent);奖励系统和考试即对应环境(Environment);学习的话题即对应状态(States);为了获得更多奖励,孩子需要判断哪个话题更重要(即,计算每个话题的价值),这即对应于强化学习中价值函数(Value-Function)所起的作用。孩子采取的行动会获得奖惩反馈(Reward),他采用的复习方法即为策略(Policy)5。
强化学习和前面介绍的算法有着一些本质上的区别6:
- 没有“正确”的行为:监督学习有专门样本标签,而强化学习并没有类似的强监督信号,通常只有基于奖励函数的单一信号。
- 无法立刻获得反馈:强化学习场景存在延迟奖励的问题,智能体可能无法在每一步获得奖励,需要不断试错,只有在完成整个任务之后才能给予奖励,还需要平衡短期奖励与长期奖励的权重。
- 具有超人类的上限:传统的机器学习算法依赖人工标注好的数据,从中训练好的模型的性能上限是产生数据的模型(人类)的上限;而强化学习可以从零开始和环境进行不断地交互,可以不受人类先验知识的桎梏,从而能够在一些任务中获得超越人类的表现。
小结
在这篇文章中,我们主要介绍了以下三点内容:
-
首先,我们辨识了数据科学、人工智能、机器学习、深度学习的概念差异。其中,
- 人工智能泛指人工地模仿人类智能的机器;
- 机器学习是一种实现人工智能的技术,具体而言,是让计算机基于概率统计的模型对未知数据进行预测与分析;
- 深度学习是许多机器学习方法中的一种,其典型代表为深度神经网络,即通过在输入层和输出层中间构建很多层来刻画数据间的复杂规律;
- 数据科学囊括了前述三个领域,是一个更广泛的概念,涵盖了大规模数据的采集、管理、分析和解释等过程。
-
其次,我们了解了机器学习的学习过程。
-
最后,我们介绍了机器学习的四种常见类型。 其中,
- 训练集给定了正确答案的叫有监督学习;
- 训练集未指定正确答案的为无监督学习;
- 训练集给了部分正确答案的叫弱监督学习;
- 不依赖训练集,让模型通过不断试错和外界环境反馈来学习的是强化学习。
- 此外,有监督学习包括回归和分类两种方法,回归是推测出一系列连续值属性,分类是推测出几个离散值属性。
参考资料
李开复,王咏刚.人工智能[M]. 北京:文化发展出 版社,2017 . ↩︎
Explaining the Terms AI, ML, DL, DS ↩︎
大数据挖掘、机器学习、人工智能的维恩图战争 ↩︎
数据来自吴恩达机器学习网络课程. ↩︎
The very basics of Reinforcement Learning . ↩︎
强化学习问题描述 ↩︎