经典卷积神经网络——VGG16
VGG16
- 前言
- 一、VGG发展历程
- 二、VGG网络模型
- 三、VGG16代码详解
-
- 1.VGG网络架构
- 2.VGG16网络验证
- 2.读取数据,进行数据增强
- 3.训练模型,测试准确率
- 四、VGG缺点
前言
我们都知道Alexnet是卷积神经网络的开山之作,但是由于卷积核太大,移动步长大,无填充,所以14年提出的VGG网络解决了这一问题
一、VGG发展历程
VGG网络由牛津大学在2014年ImageNet挑战赛本地和分类追踪分别获得了第一名和第二名。研究卷积网络深度对其影响在大规模图像识别设置中的准确性,主要贡献是全面评估网络的深度,使用3*3卷积滤波器来提取特征。解决了Alexnet容易忽略小部分的特征。
二、VGG网络模型
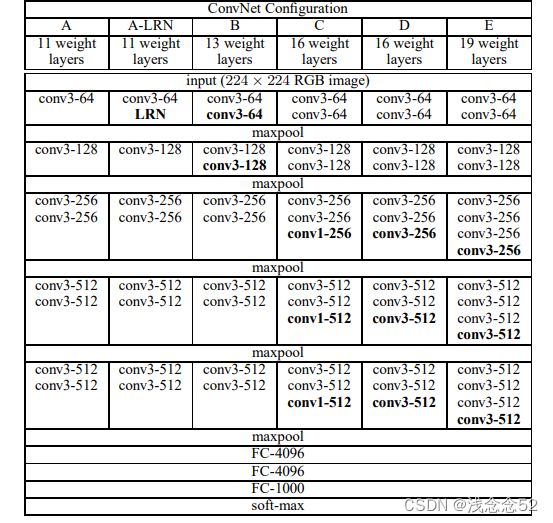
从这张图中可以看到,VGG网络有11-19层,今天我们主要了解VGG16,VGG网络有一个特点,在每一次池化之后,经过卷积通道数都会翻倍,这样的好处就是为了保留更多的特征。
VGG16一个有13个卷积层3个全连接层。
三、VGG16代码详解
1.VGG网络架构
1.通过上面表格我们可以发现,经过max池化之后,通道数会翻倍,我们可以为了减少代码量,把这一过程封装成一个类,在使用过程中,直接调用就可以了。
class tiao(nn.Module):
def __init__(self,shuru):
super(tiao, self).__init__()
self.conv1=nn.Conv2d(in_channels=shuru,out_channels=shuru*2,kernel_size=(3,3))
self.conv2=nn.Conv2d(in_channels=shuru*2,out_channels=shuru*2,kernel_size=(3,3))
self.relu=nn.ReLU()
def forward(self,x):
x1=self.conv1(x)
x2=self.relu(x1)
x3=self.conv2(x2)
x4=self.relu(x3)
return x4
这个类,很简单就是两层卷积,加两层激活函数,输出通道数翻倍
2.第二步就可以按照表格实现VGG16网络
2.1
输入三通道,输出64通道,卷积核为3
![]()
self.conv1=nn.Conv2d(in_channels=3,out_channels=64,kernel_size=(3,3))
self.conv2=nn.Conv2d(in_channels=64,out_channels=64,kernel_size=(3,3))
2.2
经过最大池化,通道数翻倍 输入64通道 经过两次卷积 输出通道128

这里直接调用上面封装好的类就行
self.tiao128=tiao(64)
2.3
经过最大池化,输入128通道 经过两次33卷积一次11卷积 输出通道256

self.tiao256=tiao(128)
self.conv1_256=nn.Conv2d(in_channels=256,out_channels=256,kernel_size=(1,1))
2.4
经过最大池化,输入256通道 经过两次33卷积一次11卷积 输出通道512

self.tiao512=tiao(256)
self.conv1_512=nn.Conv2d(in_channels=512,out_channels=512,kernel_size=(1,1))
2.5
经过最大池化,输入512通道,经过两次33卷积一次11卷积 输出通道512

self.conv512 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3))
self.conv1_512=nn.Conv2d(in_channels=512,out_channels=512,kernel_size=(1,1))
2.6
最后的三层全连接,这里要注意,使用自适应池化,池化之后图片尺寸是7*7

self.zsy=nn.AdaptiveAvgPool2d(7)
self.l1=nn.Linear(512*7*7,4096)
self.l2=nn.Linear(4096,4096)
self.l3=nn.Linear(4096,10)
2.7
还有relu激活函数,dropout随机失活函数,这里为了整洁,图表没有明确指出
self.relu=nn.ReLU()
self.dropout=nn.Dropout2d(p=0.2)
2.8
最后就是前向传播
x1=self.conv1(x)
x2=self.relu(x1)
x3=self.conv2(x2)
x4=self.maxpool(x3)
x5=self.tiao128(x4)
x6=self.maxpool(x5)
x7=self.tiao256(x6)
x8=self.conv1_256(x7)
x9=self.maxpool(x8)
x10=self.tiao512(x9)
x11=self.conv1_512(x10)
x12=self.maxpool(x11)
x13=self.conv512(x12)
x14=self.conv512(x13)
x15=self.conv1_512(x14)
x16=self.zsy(x15)
x17=x16.view(x16.size()[0],-1)
x18=self.l1(x17)
x19 = self.relu(x18)
x20=self.dropout(x19)
x22 = self.l2(x20)
x23=self.relu(x22)
x24=self.dropout(x23)
x25=self.l3(x24)
return x25
到这里VGG16网络就全部完成了
2.VGG16网络验证
这里我们可以进行验证,看网络有没有什么问题
model=VGG16()
input=torch.randn(1,3,224,224)
output=model(input).cuda()
print(output)

2.读取数据,进行数据增强
transform=transforms.Compose([
#图像增强
transforms.Resize(120),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(224),
transforms.ColorJitter(brightness=0.5,contrast=0.5,hue=0.5),
#转变为tensor 正则化
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) #正则化
])
读取数据时,可以调整线程数,batch_size可以使代码跑起来更快,提高GPU利用率,这里要注意一个问题,线程数过大新手会出现页面太小报错,这时候调整虚拟内存就可以了
trainset=tv.datasets.CIFAR10(
root=r'E:\桌面\资料\cv3\数据集\cifar-10-batches-py',
train=True,
download=True,
transform=transform
)
trainloader=data.DataLoader(
trainset,
batch_size=8,
drop_last=True,
shuffle=True, #乱序
num_workers=4,
)
testset=tv.datasets.CIFAR10(
root=r'E:\桌面\资料\cv3\数据集\cifar-10-batches-py',
train=False,
download=True,
transform=transform
)
testloader=data.DataLoader(
testset,
batch_size=4,
drop_last=True,
shuffle=False,
num_workers=2
)
3.训练模型,测试准确率
数据读取完成,我们就可以训练模型,以及测试模型准确率
for i in range(3):
running_loss=0
for index,data in enumerate(trainloader):
x,y=data
x=x.cuda()
y=y.cuda()
x,y=Variable(x),Variable(y)
opt.zero_grad()
h=model(x)
loss1=loss(h,y)
loss1.backward()
opt.step()
running_loss+=loss1.item()
if index % 10 == 9:
avg_loss = running_loss/ 10.
running_loss = 0
print('avg_loss', avg_loss)
if index%1000==99:
acc=0
total=0
for data in testloader:
images,labels=data
outputs=model(Variable(images.cuda()))
_,predicted=torch.max(outputs.cpu(),1)
total+=labels.size(0)
bool_tensor=(predicted==labels)
acc+=bool_tensor.sum()
print("1000张精度为 %d %%"%(100*acc/total))
四、VGG缺点
在vgg网络中,按照道理来说,随着层数的不断提高,网络模型会越来越好,但是研究发现,随着层数的不断提高,准确率缺不断下降,为了这个问题,随后提出的残差网络,解决了这一问题。