推荐算法之Deep&Cross模型
前言
这算是Wide&Deep模型的一个补充吧,前面写了一篇文章推荐算法之Wide&Deep模型,本想着这两个模型合在一起写的,结果Deep&Cross模型都快写完了,断网了,没保存,只有前面的W&D模型(万字长文啊,心态炸裂)。休息了一会打算重开一个继续写吧,真的是难熬,关于前面总结的其余模型优劣点在这里就不说了,可以参考我前面的文章。还是老规矩,先上一下总体框架图吧。

关于这个模型其实就是对W&D中Wide部分进行改进的模型,前文中我们说过,W&D模型原理很简单,但是最主要的是要掌握W&D这种线性和非线性,处理高维稀疏向量和embedding稠密向量的方式,能够使得模型同时具有泛化能力和记忆能力。能够根据最新数据在最短时间内以最小的代价做出回应(更新参数)。
一、Deep&Corss模型
Deep&Cross模型是2017年由斯坦福大学和谷歌在ADKDD会议上联合提出的,该模型是对Wide&Deep模型的一种改进。由于Wide&Deep模型的Wide部分的特征交互需要特征工程,而手工设计特征工程非常的繁琐。2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。所以作者对Wide部分进行更改,提出了一个Cross Network来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。模型的结构也非常简洁,从下往上依次为:Embedding和Stacking层、Cross网络层与Deep网络层并列、输出合并层,得到最终的预测结果。
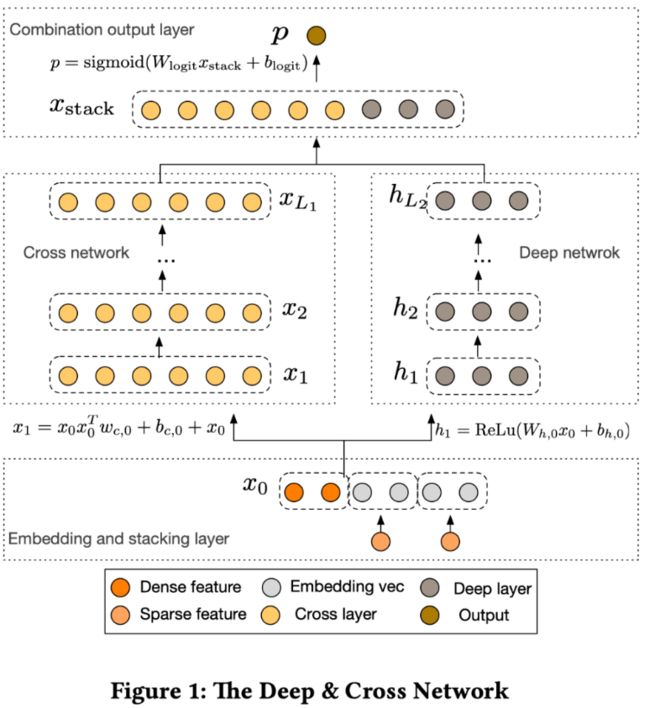
可以看到,和W&D模型不同的是在embedding部分和Cross部分,在本文中也是着重讲一下这两部分。其中我打算先讲一下Cross层再讲embedding,原因后面再说(wink
二、Cross Network
这是本文最大的创新点---Cross网络(Cross Network),设计该网络的目的是增加特征之间的交互力度。交叉网络由多个交叉层组成,假设第l层的输出向量是![]() ,那么对于第l+1层的输出向量
,那么对于第l+1层的输出向量![]() 表示为:
表示为:
![]()
可以看到, 交叉层的操作的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量![]() , 以及原输入向量
, 以及原输入向量![]() 和偏置向量
和偏置向量![]() 。 交叉层的可视化如下:
。 交叉层的可视化如下:

其实看到这里,Cross模型的基本思想就被讲完了,但是并没有讲清楚。接下里我会盘点一下这样做的好处,并且从我的理解角度一一进行解析,希望能给小伙伴们带来一个全新的理解。首先上一个大佬总结的例子来进行分析。

1、![]() 中包含了所有的
中包含了所有的![]() 的1,2阶特征的交互,
的1,2阶特征的交互,![]() 包含了所有的
包含了所有的![]() 的1, 2, 3阶特征的交互。 因此, 交叉网络层的叉乘阶数是有限的。 第l层特征对应的最高的叉乘阶数l + 1。关于这一条我觉得还是很好解释的,像最典型的FM无非也是做的二阶交互罢了,要是做更高阶的交互,就会更多的加大复杂度。
的1, 2, 3阶特征的交互。 因此, 交叉网络层的叉乘阶数是有限的。 第l层特征对应的最高的叉乘阶数l + 1。关于这一条我觉得还是很好解释的,像最典型的FM无非也是做的二阶交互罢了,要是做更高阶的交互,就会更多的加大复杂度。
2、Cross网络的参数是共享的。关于这一点,Cross网络的参数共享这句话,我觉得不是那么贴切,其实这句话容易让人误解为每一层交互都是用的同一个向量权重,其实不然,而是每一层交互都是不同的权重进行相乘。文章是将它与FM结合进行分析,认为Cross网络是FM的泛化形式。像FM模型,每一个特征向量都有着自己的一个权重,在Cross上,也是类似于这样子的,每一层交互都是对新的特征向量赋予新的权重。那么这时候就有疑问了,既然是新的向量,那这里比其他的模型参数强到那里去了么?举个很简单的例子,像深度学习的全连接层,对于两个不同的特征进行交互,就会赋予不同的权重,具体来说对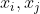 就会产生一个新的权重矩阵,而
就会产生一个新的权重矩阵,而![]() 又是一个全新的权重矩阵,而在Corss中每个特征都类似于赋予一个权重向量一样。参数共享不仅使模型更有效,而且使模型能够泛化到看不见的特征交互作用,并且对噪声更具有鲁棒性。例如对于两个稀疏特征,它们在数据中几乎从不发生交互,那么学习的权重对于预测没有任何的意义。
又是一个全新的权重矩阵,而在Corss中每个特征都类似于赋予一个权重向量一样。参数共享不仅使模型更有效,而且使模型能够泛化到看不见的特征交互作用,并且对噪声更具有鲁棒性。例如对于两个稀疏特征,它们在数据中几乎从不发生交互,那么学习的权重对于预测没有任何的意义。
3、 计算交叉网络的参数数量。 假设交叉层的数量是![]() ,特征x的维度是n, 那么总共的参数是:
,特征x的维度是n, 那么总共的参数是:
![]()
4、![]() 和resnet也有点相似,无形之中还能有效的缓解梯度消失现象。
和resnet也有点相似,无形之中还能有效的缓解梯度消失现象。
三、Embedding层
为什么会后面讲这个呢,主要是不知道大家在前面发现没有Cross层只有一个特征的输入即![]() 。我当时看的时候一直在想,输出的特征不应该是二维的么,为什么这里是一维的,那么这个一维的x是代表每一个用户的全部特征呢,还是同一特征(如ID)下所有用户的数据呢?后面才看明白,原来是同一特征(如ID)下所有用户的数据,只不过这里的
。我当时看的时候一直在想,输出的特征不应该是二维的么,为什么这里是一维的,那么这个一维的x是代表每一个用户的全部特征呢,还是同一特征(如ID)下所有用户的数据呢?后面才看明白,原来是同一特征(如ID)下所有用户的数据,只不过这里的![]() 是是将所有的特征都转化成了一维向量进行输入。用一位大佬解释的截图来说明,这里我就不多打文字解释了。
是是将所有的特征都转化成了一维向量进行输入。用一位大佬解释的截图来说明,这里我就不多打文字解释了。

后面的代码复现也会体现出这些来的。
四、其他层
Deep Network 就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
![]()
然后就是将将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
![]()
最后二分类的损失函数依然是交叉熵损失:
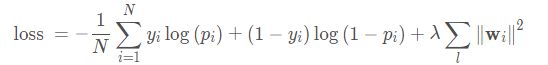
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
五、代码实现
class CrossNetwork(nn.Module):
"""
Cross Network
"""
def __init__(self, layer_num, input_dim):
super(CrossNetwork, self).__init__()
self.layer_num = layer_num
# 定义网络层的参数
self.cross_weights = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
self.cross_bias = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
def forward(self, x):
# x是(None, dim)的形状, 先扩展一个维度到(None, dim, 1)
x_0 = torch.unsqueeze(x, dim=2)
x = x_0.clone()
xT = x_0.clone().permute((0, 2, 1)) # (None, 1, dim)
for i in range(self.layer_num):
x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (None, dim, 1)
xT = x.clone().permute((0, 2, 1)) # (None, 1, dim)
x = torch.squeeze(x) # (None, dim)
return x
class DCN(nn.Module):
def __init__(self, feature_columns, hidden_units, layer_num, dnn_dropout=0.):
super(DCN, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0, len(self.dense_feature_cols) + len(self.sparse_feature_cols)*self.sparse_feature_cols[0]['embed_dim'])
self.dnn_network = Dnn(hidden_units)
self.cross_network = CrossNetwork(layer_num, hidden_units[0]) # layer_num是交叉网络的层数, hidden_units[0]表示输入的整体维度大小
self.final_linear = nn.Linear(hidden_units[-1]+hidden_units[0], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
x = torch.cat([sparse_embeds, dense_input], axis=-1)
# cross Network
cross_out = self.cross_network(x)
# Deep Network
deep_out = self.dnn_network(x)
# Concatenate
total_x = torch.cat([cross_out, deep_out], axis=-1)
# out
outputs = F.sigmoid(self.final_linear(total_x))
return outputs
参考:AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)