一: 基本使用:
1:环境的安装:
pip install flask-sqlalchemy pip install pymysql
2:组件初始化:
2.1: 基本的配置
1: 首先先安装两个依赖的包。
2:配置数据库的连接:app.config[‘SQLALCHEMY_DATABASE_URI’] = “mysql://root:[email protected]:3306/test39”
3:关闭数据库的跟踪:app.config[‘SQLALCHEMY_TRACK_MODIFICATIONS’] = False
4:开启输出sql语句:app.config[‘SQLALCHEMY_ECHO’] = True
5:两种处理python2和python3的名字不一致问题。
from flask import Flask from flask_restful import Api, Resource from flask_sqlalchemy import SQLAlchemy import pymysql pymysql.install_as_MySQLdb() """ python2中数据库客户端: MySqldb python3中数据库客户端:pymysql 解决方案一:让python2和python3的包进行转换。 import pymysql pymysql.install_as_MySQLdb() 方案二:表示只使用python3的包,不使用python2的包 app.config['SQLALCHEMY_DATABASE_URI'] = "mysql+pymysql://root:[email protected]:3306/test39" """ app = Flask(__name__) db = SQLAlchemy(app) # app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://账号:密码@数据库ip地址:端口号/数据库名" app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test39" # app.config['SQLALCHEMY_BINDS'] = {} # 关闭数据库修改跟踪操作[提高性能]: app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 开启输出底层执行的sql语句 app.config['SQLALCHEMY_ECHO'] = True # 开启数据库的自动提交功能[一般不使用] app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True @app.route('/') def hello_word(): return "hello, word" if __name__ == '__main__': print(app.url_map) app.run(host='0.0.0.0', port= 8000, debug=True)
2.2:结合工厂方法进行配置:
1: 数据库配置信息存放在环境类中加载。
2:由于数据库对象和app对象不一定谁先创建,所以可以先创建数据库对象,等app对象创建之后再进行关联。
3:进行关联的函数是:数据库对象调用自己的init_app()方法。需要传入app对象。
settings中配置:
# 开发环境
class DevelopmentConfig(BaseConfig):
"""开发环境配置类"""
DEBUG = True
# SQL数据库连接信息
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:[email protected]:3306/test39"
# 关闭数据库修改跟踪操作 【提高性能】
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 开启输出底层执行sql语句
SQLALCHEMY_ECHO = True
主模块:
from flask import Flask, make_response, Response, request, current_app
from settings import config_dict
from flask_sqlalchemy import SQLAlchemy
# 延后加载
# 创建了数据库,此时数据库对象还没有跟app关联
db = SQLAlchemy()
# 定义一个工厂方法:
def create_app(config_name):
app = Flask(__name__)
config_class = config_dict[config_name]
app.config.from_object(config_class)
app.config.from_envvar('CONFIG', silent=True)
# 懒加载
db.init_app(app)
return app
app = create_app("dev")
@app.route('/login')
def login():
return ""
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000, debug=True)
3:构建模型类:
- 模型类必须继承 db.Model, 其中 db 指对应的组件对象
- 表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
- 类属性对应字段, 必须是通过 db.Column() 创建的对象
- 可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表
- 注意点: 如果没有给对应字段的类属性设置default参数, 且添加数据时也没有给该字段赋值, 则 sqlalchemy会给该字段设置默认值 None
<模型类创建案例>
from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # 相关配置 app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test39" app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False app.config['SQLALCHEMY_ECHO'] = True # 创建组件对象 db = SQLAlchemy(app) # 构建模型类 类->表 类属性->字段 实例对象->记录 class User(db.Model): __tablename__ = 't_user' # 设置表名, 表名默认为类名小写 id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增 name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束 age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引 if __name__ == '__main__': # 删除所有继承自db.Model的表 db.drop_all() # 创建所有继承自db.Model的表 db.create_all() app.run(host="0.0.0.0", port=8000, debug=True)
二:数据操作:
1:增加数据:
1:给模型对象设置数据 可以通过 初始化参数 或者 赋值属性 两种方式
2:session.add(模型对象) 添加单条数据到会话中, session.add_all(列表) 添加多条数据到会话中
3:sqlalchemy 会 自动创建事务, 并将数据操作包含在事务中, 提交会话时就会提交事务,事务提交失败会自动回滚。
from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # 相关配置 app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test39" app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False app.config['SQLALCHEMY_ECHO'] = True # 创建组件对象 db = SQLAlchemy(app) # 构建模型类 class User(db.Model): __tablename__ = 't_user' id = db.Column(db.Integer, primary_key=True) name = db.Column('username', db.String(20), unique=True) age = db.Column(db.Integer, index=True) @app.route('/') def index(): """增加数据""" # 1.创建模型对象 user1 = User(name='zs', age=20) # user1.name = 'zs' # user1.age = 20 # 2.将模型对象添加到会话中 db.session.add(user1) # 添加多条记录 # db.session.add_all([user1, user2, user3]) # 3.提交会话 (会提交事务) # sqlalchemy会自动创建隐式事务 # 事务失败会自动回滚 db.session.commit() return "index" if __name__ == '__main__': db.drop_all() db.create_all() app.run(host="0.0.0.0", port=8000, debug=True)
2:查询数据:
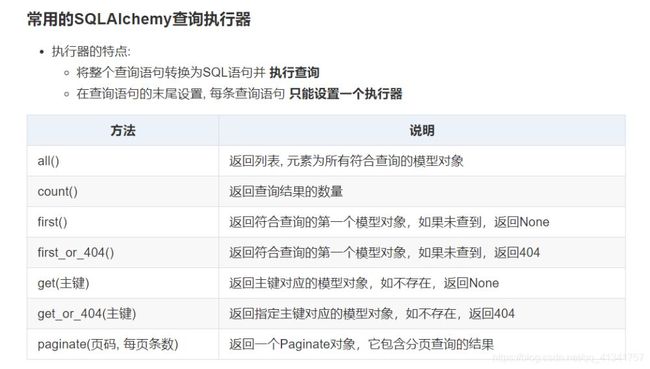
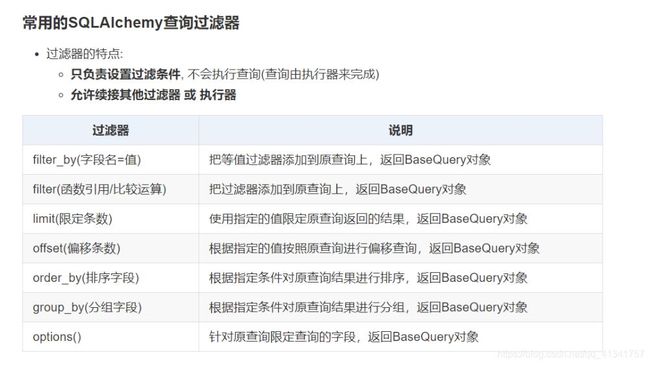
1:数据的准备工作:
from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # 配置数据库连接 app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test39" # 配置取消数据库跟踪 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 配置数据库输出SQL语句 app.config['SQLALCHEMY_ECHO'] = True # 创建数据库对象 db = SQLAlchemy(app) class User(db.Model): # 指定表名:默认使用类名小写 __tablename__ = "users" id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(64)) email = db.Column(db.String(64)) age = db.Column(db.Integer) def __repr__(self): return "(%s, %s, %s, %s)"%(self.id, self.name, self.email, self.age) if __name__ == '__main__': # 删除所有表 # db.drop_all() # # 创建所有表 # db.create_all() # # 添加测试数据 # user1 = User(name='wang', email='[email protected]', age=20) # user2 = User(name='zhang', email='[email protected]', age=33) # user3 = User(name='chen', email='[email protected]', age=23) # user4 = User(name='zhou', email='[email protected]', age=29) # user5 = User(name='tang', email='[email protected]', age=25) # user6 = User(name='wu', email='[email protected]', age=25) # user7 = User(name='qian', email='[email protected]', age=23) # user8 = User(name='liu', email='[email protected]', age=30) # user9 = User(name='li', email='[email protected]', age=28) # user10 = User(name='sun', email='[email protected]', age=26) # # # 一次添加多条数据 # db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10]) # db.session.commit() app.run(host="0.0.0.0",port=8000, debug=True)
2:进行查询操作:
# 1:查询所有的用户数据:
users = User.query.all()
print(type(users))
print(users)
# 2:查询一共有多少个用户:
count = User.query.count()
print("一共有{}个人".format(count))
# 3:查询第一个用户信息:
user1 = User.query.first()
print("第一个用户的信息是:{}".format(user1))
# 4:查询id为4的三种方式:
#<方案一>:根据id查询,返回模型类对象
user4 = User.query.get(4)
print("第四个用户的信息是{}".format(user4))
# <方案二>:等值过滤器 关键字实参设置字段值 返回BaseQuery对象
user4 = User.query.filter_by(id=4).first()
print("第四个用户的信息是{}".format(user4))
# <方案三>:使用复杂过滤器,返回BaseQuery对象
user4 = User.query.filter(User.id == 4).first()
print("第四个用户的信息是{}".format(user4))
# 5:查询用户名字,开始,结尾,包含n的用户
user = User.query.filter(User.name.startswith('n')).all()
print("名字以n开头的用户{}".format(user))
user = User.query.filter(User.name.endswith("n")).all()
print("名字以n结尾的用户{}".format(user))
user = User.query.filter(User.name.contains("n")).all()
print("名字中包含n的用户:{}".format(user))
# 6:查询名字和邮箱都以li开头的所有用户[2种方式]
users = User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
print("查询名字和邮箱都以li开头的所有用户:{}".format(users))
users = User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()
print("查询名字和邮箱都以li开头的所有用户:{}".format(users))
# 7:查询age是25或者email以com结尾的所有用户
users = User.query.filter(or_(User.age==25, User.email.endswith('com'))).all()
print("age是25或者email以com结尾的所有用户 : {}".format(users))
# 8: 查询名字不等于wang的所有用户
users = User.query.filter(User.name != "wang").all()
print("名字不等于wang的所有用户: {}".format(users))
users= User.query.filter(not_(User.name=="wang")).all()
print("名字不等于wang的所有用户: {}".format(users))
# 9: 查询id是[1, 3, 5, 7, 9]的用户
users = User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
print("id是[1, 3, 5, 7, 9]的用户: {}".format(users))
# 10:所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
users = User.query.order_by(User.age, User.id.desc()).limit(5).all()
print("所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个: {}".format(users))
# 11:查询年龄从小到大第2-5位的数据
users = User.query.order_by(User.age).offset(1).limit(4).all()
print("查询年龄从小到大第2-5位的数据: {}".format(users))
# 12: 分页查询, 每页3个, 查询第2页的数据 paginate(页码, 每页条数)
pn = User.query.paginate(2, 3)
print("总页数是:", pn.pages)
print("当前页:", pn.page)
print("当前页的数据:", pn.items)
print("当前页的总条数", pn.total)
# 13: 查询每个年龄段的人数:(分组聚合)
data = db.session.query(User.age, func.count(User.id)).group_by(User.age).all()
for item in data:
print(item[0], item[1])
# 注意可以给列起别名,但是windows下会报错,linux下不会报错。
# data = db.session.query(User.age, func.count(User.id).label("count")).group_by(User.age).all()
# for item in data:
# # print(item[0], item[1])
# print(item.age, item.count) # 建议通过label()方法给字段起别名, 以属性方式获取数据
# 14:只查询所有人的姓名和邮箱,这种相当于全表查询,效率非常低。
data = db.session.query(User.name, User.email).all()
for item in data:
print(item.name, item.email)
# 15:优化查询
data = User.query.options(load_only(User.name, User.email)).all()
for item in data:
print(item.name, item.email)
return "index"
3:修改数据:
1: 推荐采用方案二:
2: 一条语句, 被网络IO影响程度低, 执行效率更高
3:查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
4:会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
方案一:先查询再更新:
from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # 相关配置 app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test39" app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False app.config['SQLALCHEMY_ECHO'] = True # 创建组件对象 db = SQLAlchemy(app) # 构建模型类 商品表 class Goods(db.Model): __tablename__ = 't_good' # 设置表名 id = db.Column(db.Integer, primary_key=True) # 设置主键 name = db.Column(db.String(20), unique=True) # 商品名称 count = db.Column(db.Integer) # 剩余数量 @app.route('/') def purchase(): """购买商品""" # 更新方式1: 先查询后更新 # 缺点: 并发情况下, 容易出现更新丢失问题 (Lost Update) # 1.执行查询语句, 获取目标模型对象 goods = Goods.query.filter(Goods.name == '方便面').first() # 2.对模型对象的属性进行赋值 (更新数据) goods.count = goods.count - 1 # 3.提交会话 db.session.commit() return "index" if __name__ == '__main__': # 删除所有继承自db.Model的表 db.drop_all() # 创建所有继承自db.Model的表 db.create_all() # 添加一条测试数据 goods = Goods(name='方便面', count=1) db.session.add(goods) db.session.commit() app.run(host="0.0.0.0", port=8000, debug=True)
方案二:配合查询过滤器filter() 和 更新执行器update() 进行数据更新
Goods.query.filter(Goods.name == '方便面').update({'count': Goods.count - 1})
db.session.commit()
4:删除数据:
方案一:
# 方式1: 先查后删除
goods = Goods.query.filter(Goods.name == '方便面').first()
# 删除数据
db.session.delete(goods)
# 提交会话 增删改都要提交会话
db.session.commit()
方案二:
# 方式2: delete子查询
Goods.query.filter(Goods.name == '方便面').delete()
# 提交会话
db.session.commit()
三:高级机制:
1:刷新数据:
1:Session 被设计为数据操作的执行者, 会先将操作产生的数据保存到内存中。
2: 在执行 flush刷新操作 后, 数据操作才会同步到数据库中。
3:隐式刷新操作:1:提交会话 2:查询操作(包括更新和删除中的子查询)。
4:手动刷新:session.flush()
刷新机制的理解:
答:刷新机制就是通过事务,将SQl语句执行一遍,然后将执行结果存储在变量中,但是数据库做回滚操作。导致变量中有了新值,但是数据库却没有改变。
goods = Goods(name='方便面', count=20)
db.session.add(goods)
# 主动执行flush操作, 立即执行SQL操作(数据库同步)
print(goods.id) # 此时是None
db.session.flush()
print(goods.id) # 此时是1
# Goods.query.count() # 查询操作会自动执行flush操作
db.session.commit() # 提交会话会自动执行flush操作
2:多表查询:
2.1:外键关联查询:
生成主表对象后,必须刷新数据库,否则后面无法使用主表对象的属性。
1:主从表的定义:
# 用户表 一 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
2:添加关联数据:
def index():
"""添加并关联数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush() # 必须刷新,不然后面的user1.id是None
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
return "index"
3:关联查询:
# 1.先根据姓名查找到主表主键
user1 = User.query.filter_by(name='张三').first()
# 2.再根据主键到从表查询关联地址
adrs = Address.query.filter_by(user_id=user1.id).all()
for adr in adrs:
print(adr.detail)
到此这篇关于Flask-Sqlalchemy的基本使用详解的文章就介绍到这了,更多相关Flask-Sqlalchemy 使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!